 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Embeddings for Spatio-Temporal Tagging of Self-Driving Logs
Nov 12, 2020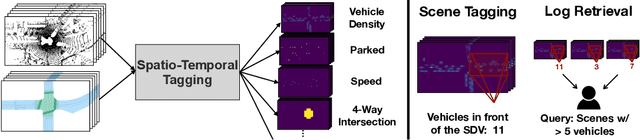
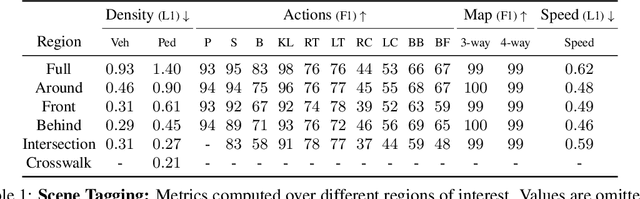
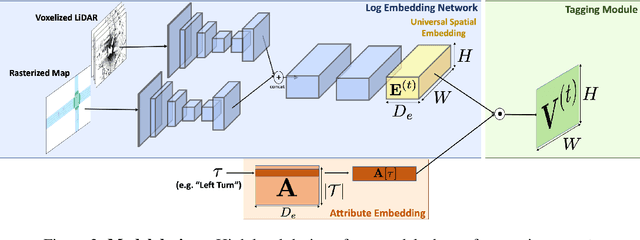

In this paper, we tackle the problem of spatio-temporal tagging of self-driving scenes from raw sensor data. Our approach learns a universal embedding for all tags, enabling efficient tagging of many attributes and faster learning of new attributes with limited data. Importantly, the embedding is spatio-temporally aware, allowing the model to naturally output spatio-temporal tag values. Values can then be pooled over arbitrary regions, in order to, for example, compute the pedestrian density in front of the SDV, or determine if a car is blocking another car at a 4-way intersection. We demonstrate the effectiveness of our approach on a new large scale self-driving dataset, SDVScenes, containing 15 attributes relating to vehicle and pedestrian density, the actions of each actor, the speed of each actor, interactions between actors, and the topology of the road map.
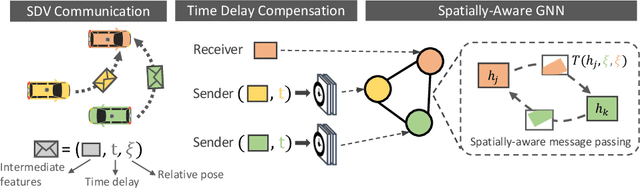
Learning to Communicate and Correct Pose Errors
Nov 10, 2020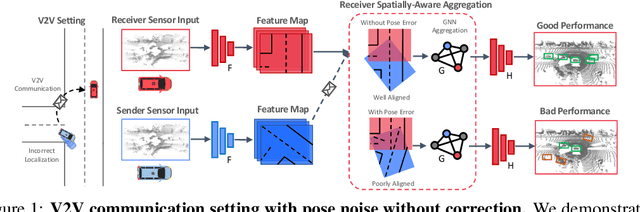
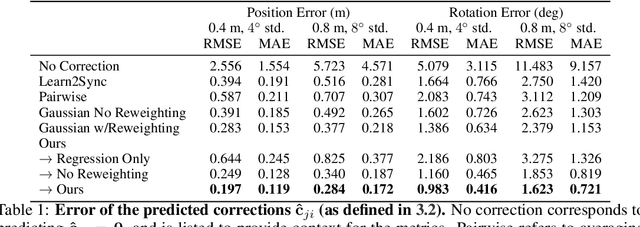
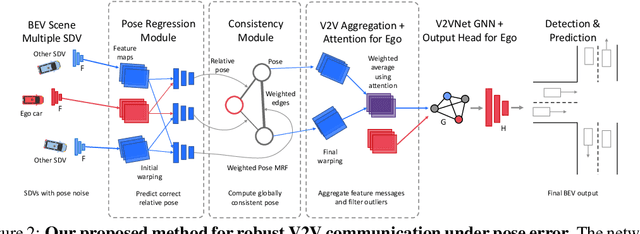
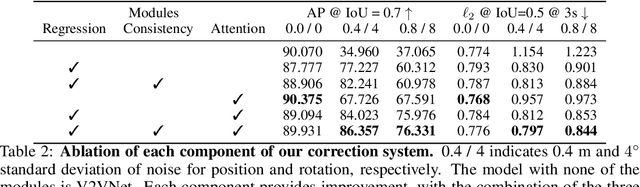
Learned communication makes multi-agent systems more effective by aggregating distributed information. However, it also exposes individual agents to the threat of erroneous messages they might receive. In this paper, we study the setting proposed in V2VNet, where nearby self-driving vehicles jointly perform object detection and motion forecasting in a cooperative manner. Despite a huge performance boost when the agents solve the task together, the gain is quickly diminished in the presence of pose noise since the communication relies on spatial transformations. Hence, we propose a novel neural reasoning framework that learns to communicate, to estimate potential errors, and finally, to reach a consensus about those errors. Experiments confirm that our proposed framework significantly improves the robustness of multi-agent self-driving perception and motion forecasting systems under realistic and severe localization noise.
Perceive, Attend, and Drive: Learning Spatial Attention for Safe Self-Driving
Nov 02, 2020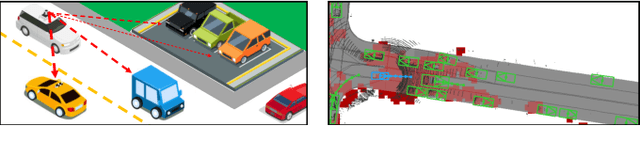
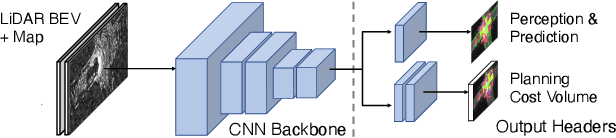
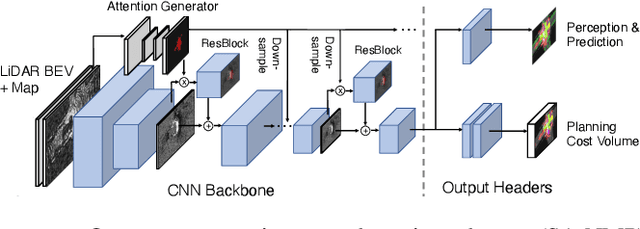
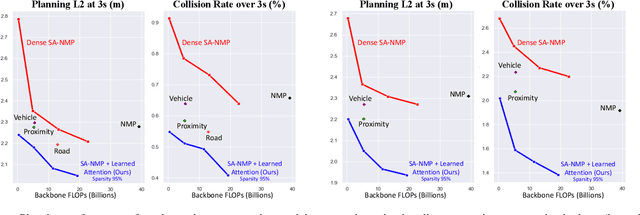
In this paper, we propose an end-to-end self-driving network featuring a sparse attention module that learns to automatically attend to important regions of the input. The attention module specifically targets motion planning, whereas prior literature only applied attention in perception tasks. Learning an attention mask directly targeted for motion planning significantly improves the planner safety by performing more focused computation. Furthermore, visualizing the attention improves interpretability of end-to-end self-driving.
Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks
Oct 29, 2020



Compressing large neural networks is an important step for their deployment in resource-constrained computational platforms. In this context, vector quantization is an appealing framework that expresses multiple parameters using a single code, and has recently achieved state-of-the-art network compression on a range of core vision and natural language processing tasks. Key to the success of vector quantization is deciding which parameter groups should be compressed together. Previous work has relied on heuristics that group the spatial dimension of individual convolutional filters, but a general solution remains unaddressed. This is desirable for pointwise convolutions (which dominate modern architectures), linear layers (which have no notion of spatial dimension), and convolutions (when more than one filter is compressed to the same codeword). In this paper we make the observation that the weights of two adjacent layers can be permuted while expressing the same function. We then establish a connection to rate-distortion theory and search for permutations that result in networks that are easier to compress. Finally, we rely on an annealed quantization algorithm to better compress the network and achieve higher final accuracy. We show results on image classification, object detection, and segmentation, reducing the gap with the uncompressed model by 40 to 70% with respect to the current state of the art.
LiRaNet: End-to-End Trajectory Prediction using Spatio-Temporal Radar Fusion
Oct 15, 2020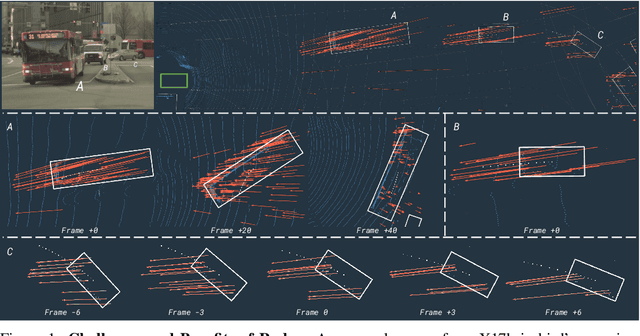
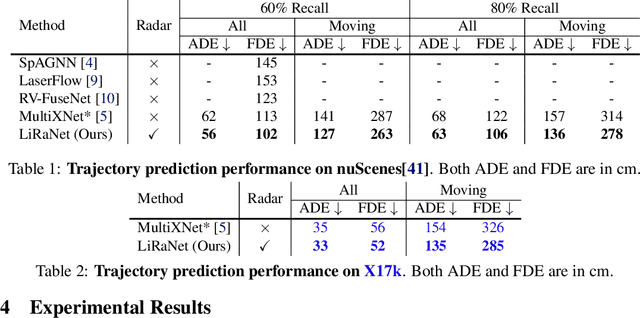
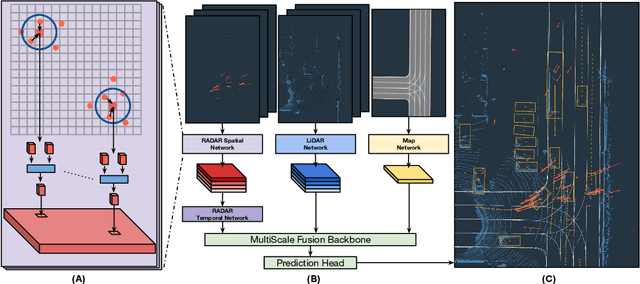

In this paper, we present LiRaNet, a novel end-to-end trajectory prediction method which utilizes radar sensor information along with widely used lidar and high definition (HD) maps. Automotive radar provides rich, complementary information, allowing for longer range vehicle detection as well as instantaneous radial velocity measurements. However, there are factors that make the fusion of lidar and radar information challenging, such as the relatively low angular resolution of radar measurements, their sparsity and the lack of exact time synchronization with lidar. To overcome these challenges, we propose an efficient spatio-temporal radar feature extraction scheme which achieves state-of-the-art performance on multiple large-scale datasets.Further, by incorporating radar information, we show a 52% reduction in prediction error for objects with high acceleration and a 16% reduction in prediction error for objects at longer range.
Conditional Entropy Coding for Efficient Video Compression
Aug 20, 2020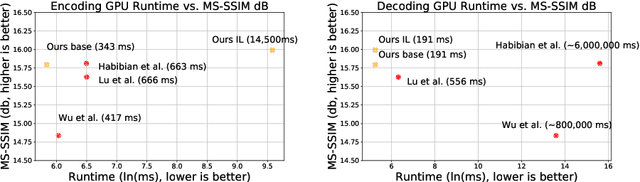
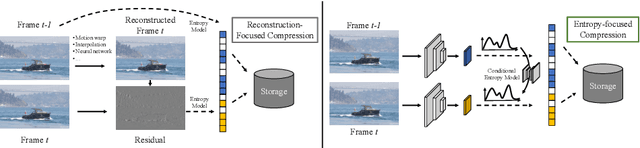
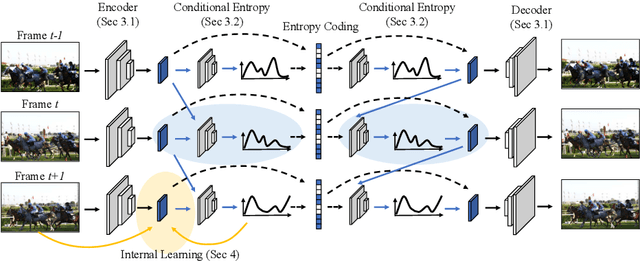
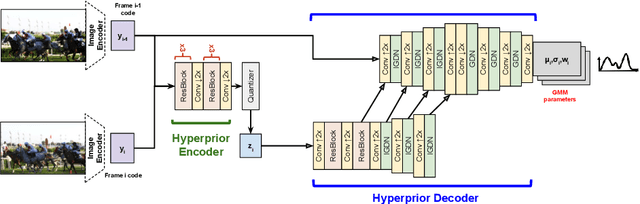
We propose a very simple and efficient video compression framework that only focuses on modeling the conditional entropy between frames. Unlike prior learning-based approaches, we reduce complexity by not performing any form of explicit transformations between frames and assume each frame is encoded with an independent state-of-the-art deep image compressor. We first show that a simple architecture modeling the entropy between the image latent codes is as competitive as other neural video compression works and video codecs while being much faster and easier to implement. We then propose a novel internal learning extension on top of this architecture that brings an additional 10% bitrate savings without trading off decoding speed. Importantly, we show that our approach outperforms H.265 and other deep learning baselines in MS-SSIM on higher bitrate UVG video, and against all video codecs on lower framerates, while being thousands of times faster in decoding than deep models utilizing an autoregressive entropy model.
Weakly-supervised 3D Shape Completion in the Wild
Aug 20, 2020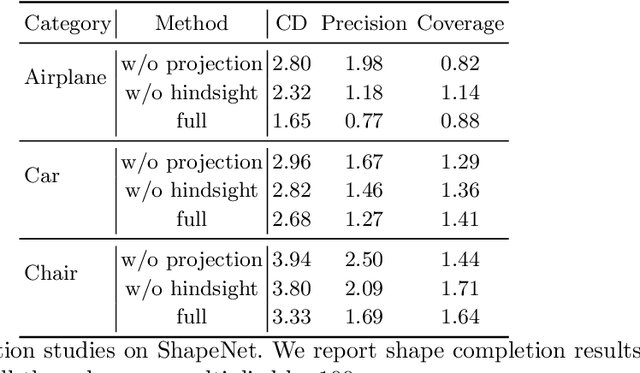

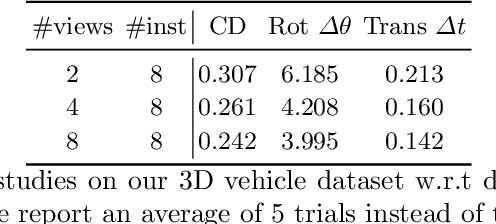
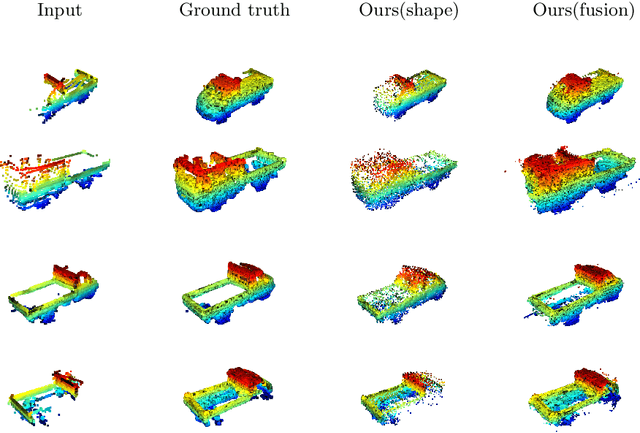
3D shape completion for real data is important but challenging, since partial point clouds acquired by real-world sensors are usually sparse, noisy and unaligned. Different from previous methods, we address the problem of learning 3D complete shape from unaligned and real-world partial point clouds. To this end, we propose a weakly-supervised method to estimate both 3D canonical shape and 6-DoF pose for alignment, given multiple partial observations associated with the same instance. The network jointly optimizes canonical shapes and poses with multi-view geometry constraints during training, and can infer the complete shape given a single partial point cloud. Moreover, learned pose estimation can facilitate partial point cloud registration. Experiments on both synthetic and real data show that it is feasible and promising to learn 3D shape completion through large-scale data without shape and pose supervision.
V2VNet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction
Aug 17, 2020

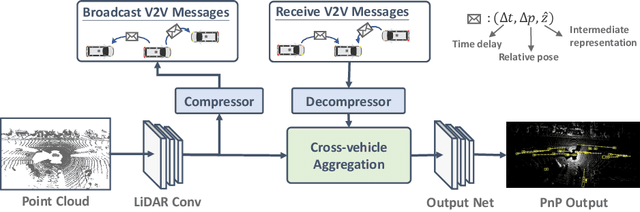
In this paper, we explore the use of vehicle-to-vehicle (V2V) communication to improve the perception and motion forecasting performance of self-driving vehicles. By intelligently aggregating the information received from multiple nearby vehicles, we can observe the same scene from different viewpoints. This allows us to see through occlusions and detect actors at long range, where the observations are very sparse or non-existent. We also show that our approach of sending compressed deep feature map activations achieves high accuracy while satisfying communication bandwidth requirements.
DSDNet: Deep Structured self-Driving Network
Aug 13, 2020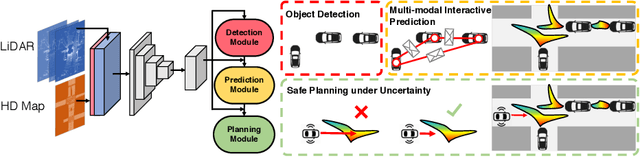

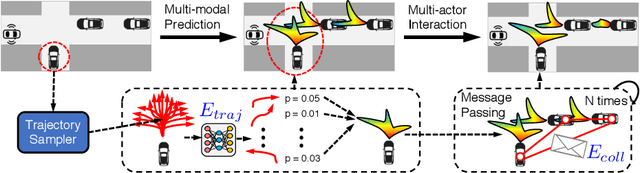
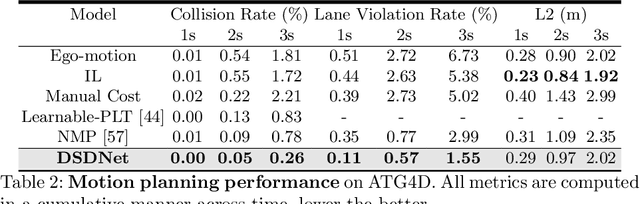
In this paper, we propose the Deep Structured self-Driving Network (DSDNet), which performs object detection, motion prediction, and motion planning with a single neural network. Towards this goal, we develop a deep structured energy based model which considers the interactions between actors and produces socially consistent multimodal future predictions. Furthermore, DSDNet explicitly exploits the predicted future distributions of actors to plan a safe maneuver by using a structured planning cost. Our sample-based formulation allows us to overcome the difficulty in probabilistic inference of continuous random variables. Experiments on a number of large-scale self driving datasets demonstrate that our model significantly outperforms the state-of-the-art.
Testing the Safety of Self-driving Vehicles by Simulating Perception and Prediction
Aug 13, 2020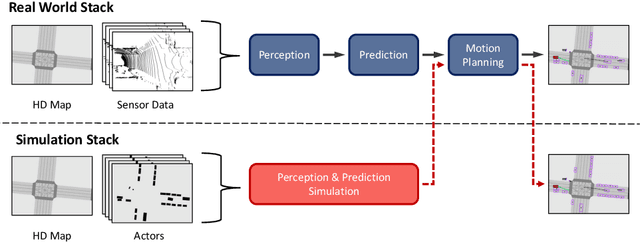
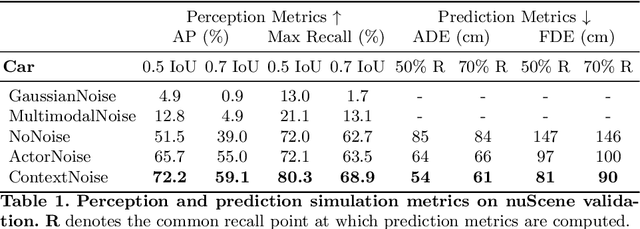
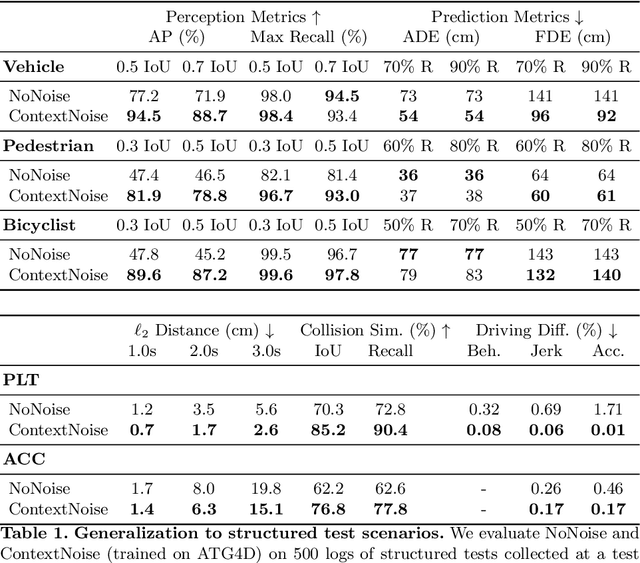
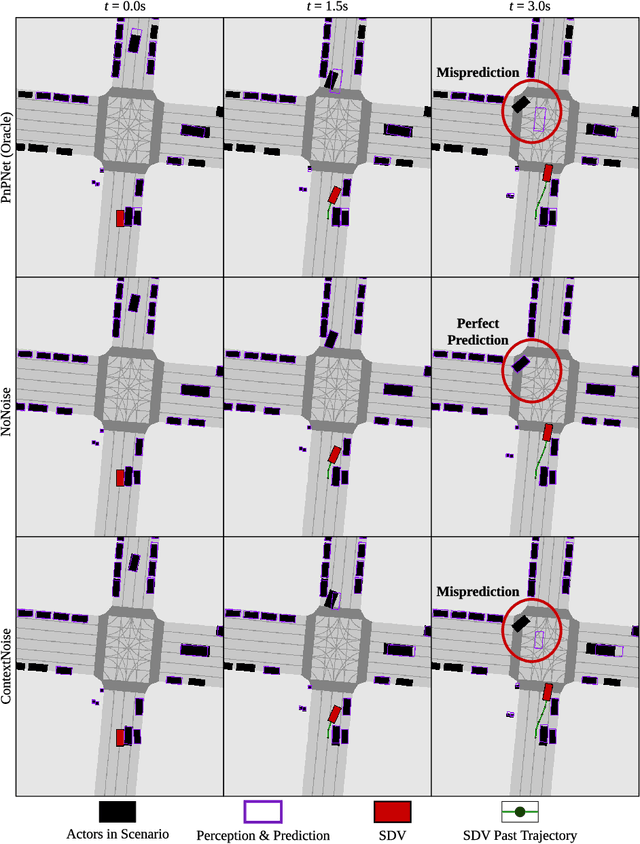
We present a novel method for testing the safety of self-driving vehicles in simulation. We propose an alternative to sensor simulation, as sensor simulation is expensive and has large domain gaps. Instead, we directly simulate the outputs of the self-driving vehicle's perception and prediction system, enabling realistic motion planning testing. Specifically, we use paired data in the form of ground truth labels and real perception and prediction outputs to train a model that predicts what the online system will produce. Importantly, the inputs to our system consists of high definition maps, bounding boxes, and trajectories, which can be easily sketched by a test engineer in a matter of minutes. This makes our approach a much more scalable solution. Quantitative results on two large-scale datasets demonstrate that we can realistically test motion planning using our simulations.