 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification
Sep 06, 2022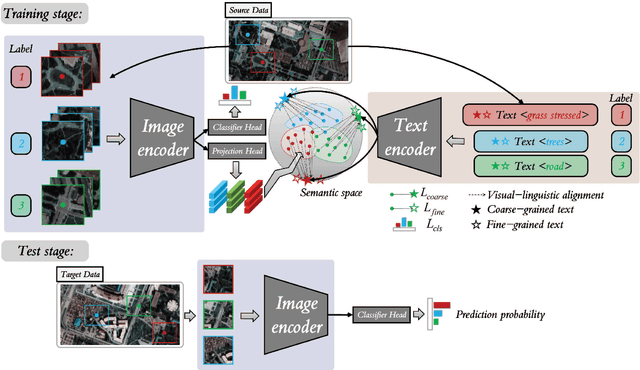
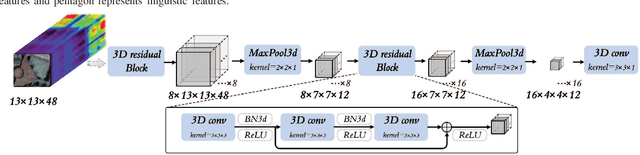
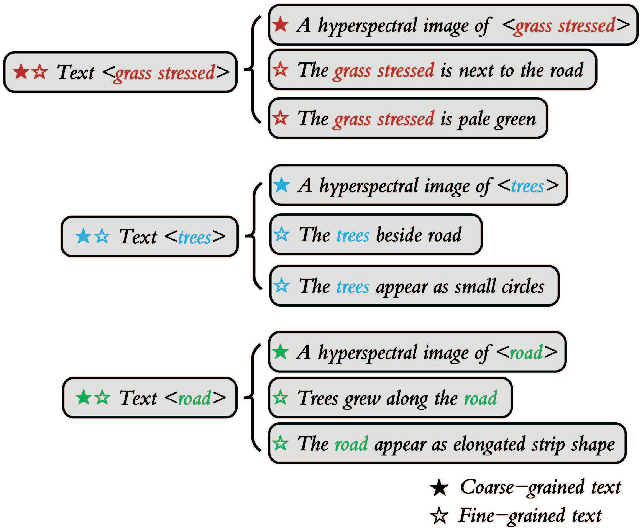
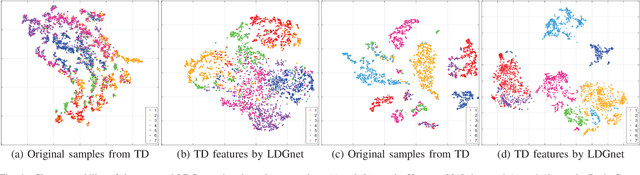
Text information including extensive prior knowledge about land cover classes has been ignored in hyperspectral image classification (HSI) tasks. It is necessary to explore the effectiveness of linguistic mode in assisting HSI classification. In addition, the large-scale pre-training image-text foundation models have demonstrated great performance in a variety of downstream applications, including zero-shot transfer. However, most domain generalization methods have never addressed mining linguistic modal knowledge to improve the generalization performance of model. To compensate for the inadequacies listed above, a Language-aware Domain Generalization Network (LDGnet) is proposed to learn cross-domain invariant representation from cross-domain shared prior knowledge. The proposed method only trains on the source domain (SD) and then transfers the model to the target domain (TD). The dual-stream architecture including image encoder and text encoder is used to extract visual and linguistic features, in which coarse-grained and fine-grained text representations are designed to extract two levels of linguistic features. Furthermore, linguistic features are used as cross-domain shared semantic space, and visual-linguistic alignment is completed by supervised contrastive learning in semantic space. Extensive experiments on three datasets demonstrate the superiority of the proposed method when compared with state-of-the-art techniques.
Task-wise Sampling Convolutions for Arbitrary-Oriented Object Detection in Aerial Images
Sep 06, 2022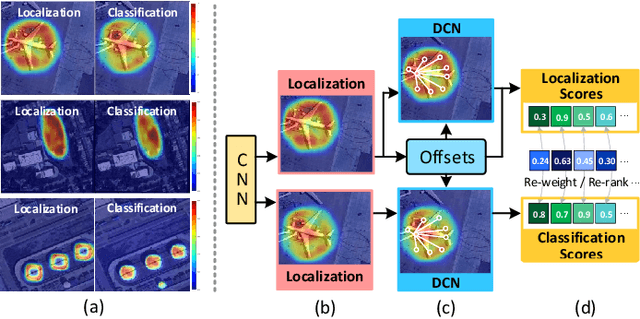

Arbitrary-oriented object detection (AOOD) has been widely applied to locate and classify objects with diverse orientations in remote sensing images. However, the inconsistent features for the localization and classification tasks in AOOD models may lead to ambiguity and low-quality object predictions, which constrains the detection performance. In this paper, an AOOD method called task-wise sampling convolutions (TS-Conv) is proposed. TS-Conv adaptively samples task-wise features from respective sensitive regions and maps these features together in alignment to guide a dynamic label assignment for better predictions. Specifically, sampling positions of the localization convolution in TS-Conv is supervised by the oriented bounding box (OBB) prediction associated with spatial coordinates. While sampling positions and convolutional kernel of the classification convolution are designed to be adaptively adjusted according to different orientations for improving the orientation robustness of features. Furthermore, a dynamic task-aware label assignment (DTLA) strategy is developed to select optimal candidate positions and assign labels dynamicly according to ranked task-aware scores obtained from TS-Conv. Extensive experiments on several public datasets covering multiple scenes, multimodal images, and multiple categories of objects demonstrate the effectiveness, scalability and superior performance of the proposed TS-Conv.
Single-source Domain Expansion Network for Cross-Scene Hyperspectral Image Classification
Sep 04, 2022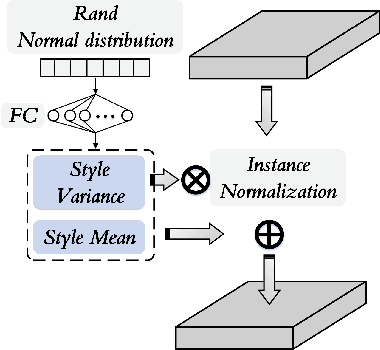
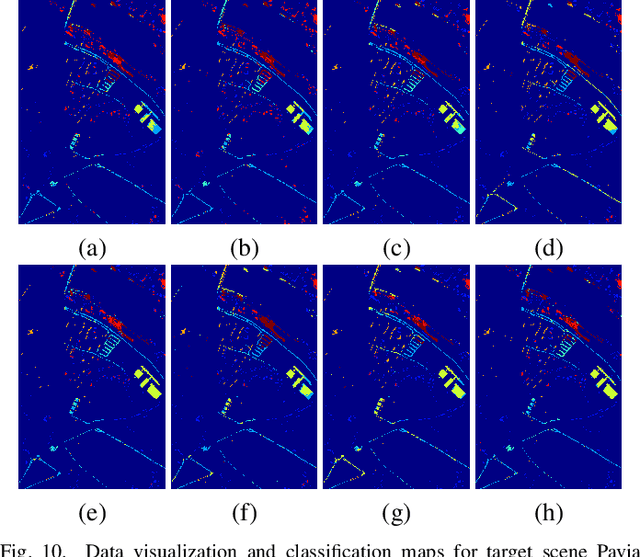
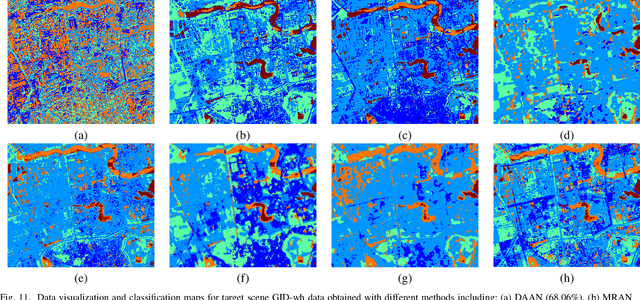
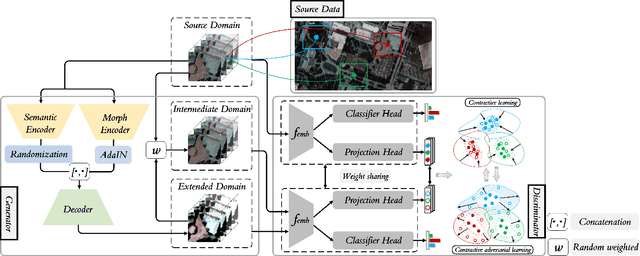
Currently, cross-scene hyperspectral image (HSI) classification has drawn increasing attention. It is necessary to train a model only on source domain (SD) and directly transferring the model to target domain (TD), when TD needs to be processed in real time and cannot be reused for training. Based on the idea of domain generalization, a Single-source Domain Expansion Network (SDEnet) is developed to ensure the reliability and effectiveness of domain extension. The method uses generative adversarial learning to train in SD and test in TD. A generator including semantic encoder and morph encoder is designed to generate the extended domain (ED) based on encoder-randomization-decoder architecture, where spatial and spectral randomization are specifically used to generate variable spatial and spectral information, and the morphological knowledge is implicitly applied as domain invariant information during domain expansion. Furthermore, the supervised contrastive learning is employed in the discriminator to learn class-wise domain invariant representation, which drives intra-class samples of SD and ED. Meanwhile, adversarial training is designed to optimize the generator to drive intra-class samples of SD and ED to be separated. Extensive experiments on two public HSI datasets and one additional multispectral image (MSI) dataset demonstrate the superiority of the proposed method when compared with state-of-the-art techniques.
Conv-Adapter: Exploring Parameter Efficient Transfer Learning for ConvNets
Aug 24, 2022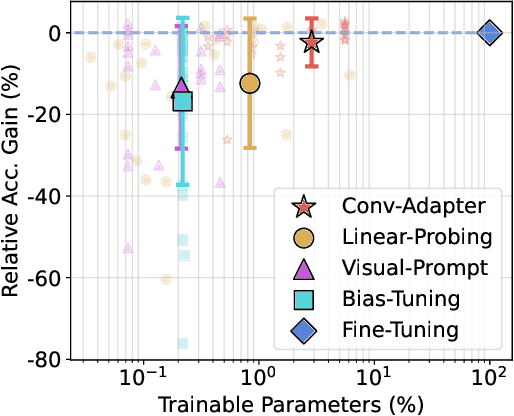
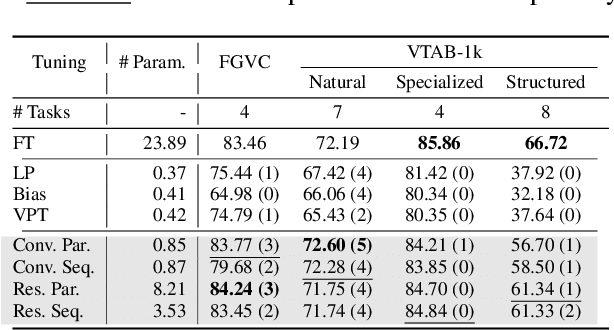
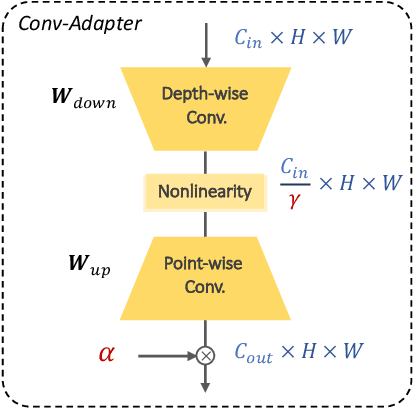
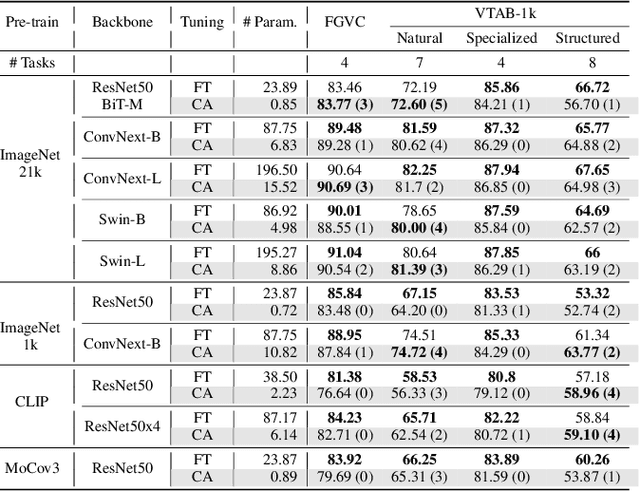
While parameter efficient tuning (PET) methods have shown great potential with transformer architecture on Natural Language Processing (NLP) tasks, their effectiveness is still under-studied with large-scale ConvNets on Computer Vision (CV) tasks. This paper proposes Conv-Adapter, a PET module designed for ConvNets. Conv-Adapter is light-weight, domain-transferable, and architecture-agnostic with generalized performance on different tasks. When transferring on downstream tasks, Conv-Adapter learns tasks-specific feature modulation to the intermediate representations of backbone while keeping the pre-trained parameters frozen. By introducing only a tiny amount of learnable parameters, e.g., only 3.5% full fine-tuning parameters of ResNet50, Conv-Adapter outperforms previous PET baseline methods and achieves comparable or surpasses the performance of full fine-tuning on 23 classification tasks of various domains. It also presents superior performance on few-shot classifications, with an average margin of 3.39%. Beyond classification, Conv-Adapter can generalize to detection and segmentation tasks with more than 50% reduction of parameters but comparable performance to the traditional full fine-tuning.
USB: A Unified Semi-supervised Learning Benchmark
Aug 12, 2022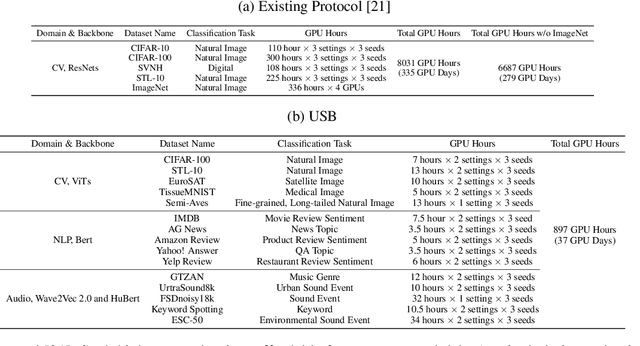
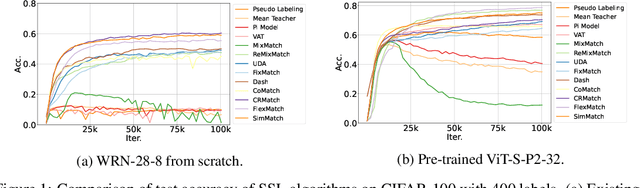
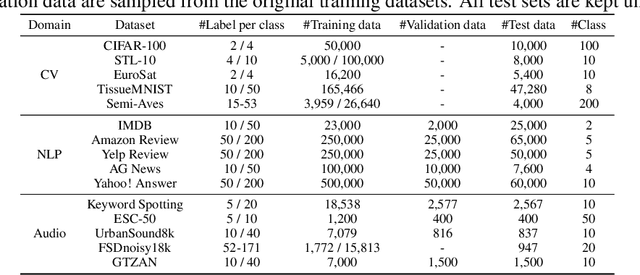
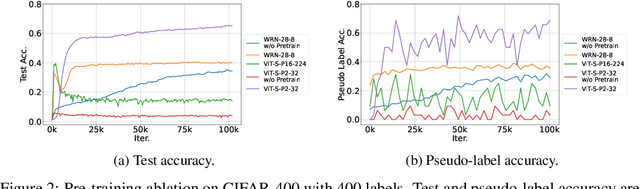
Semi-supervised learning (SSL) improves model generalization by leveraging massive unlabeled data to augment limited labeled samples. However, currently, popular SSL evaluation protocols are often constrained to computer vision (CV) tasks. In addition, previous work typically trains deep neural networks from scratch, which is time-consuming and environmentally unfriendly. To address the above issues, we construct a Unified SSL Benchmark (USB) by selecting 15 diverse, challenging, and comprehensive tasks from CV, natural language processing (NLP), and audio processing (Audio), on which we systematically evaluate dominant SSL methods, and also open-source a modular and extensible codebase for fair evaluation on these SSL methods. We further provide pre-trained versions of the state-of-the-art neural models for CV tasks to make the cost affordable for further tuning. USB enables the evaluation of a single SSL algorithm on more tasks from multiple domains but with less cost. Specifically, on a single NVIDIA V100, only 37 GPU days are required to evaluate FixMatch on 15 tasks in USB while 335 GPU days (279 GPU days on 4 CV datasets except for ImageNet) are needed on 5 CV tasks with the typical protocol.
MPANet: Multi-Patch Attention For Infrared Small Target object Detection
Jun 05, 2022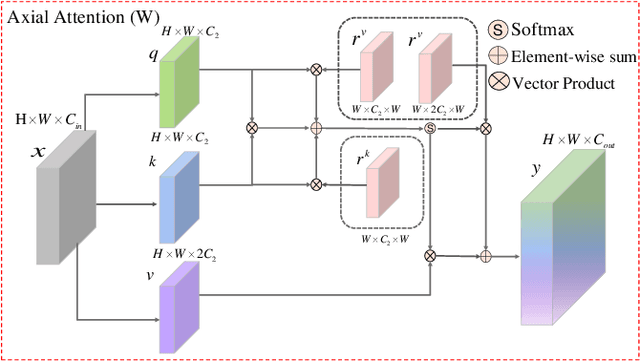
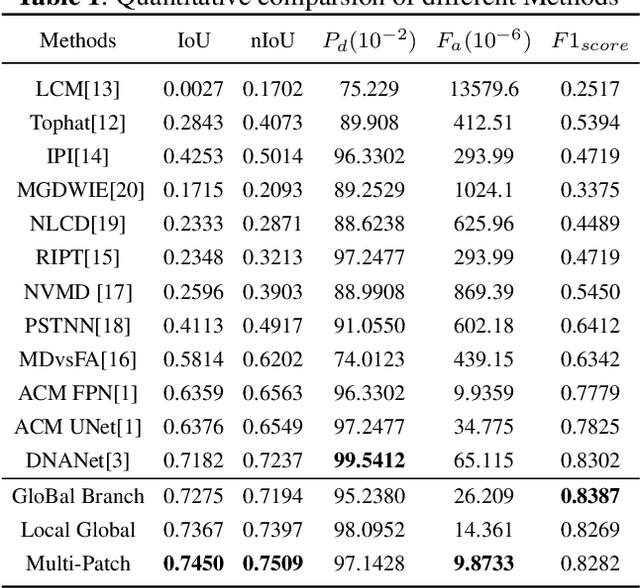
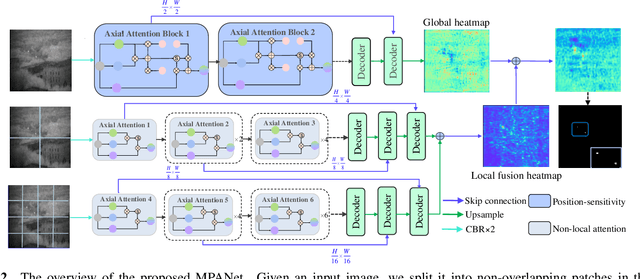
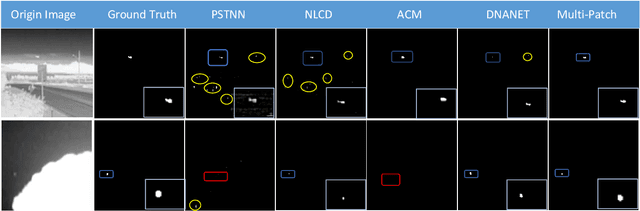
Infrared small target detection (ISTD) has attracted widespread attention and been applied in various fields. Due to the small size of infrared targets and the noise interference from complex backgrounds, the performance of ISTD using convolutional neural networks (CNNs) is restricted. Moreover, the constriant that long-distance dependent features can not be encoded by the vanilla CNNs also impairs the robustness of capturing targets' shapes and locations in complex scenarios. To this end, a multi-patch attention network (MPANet) based on the axial-attention encoder and the multi-scale patch branch (MSPB) structure is proposed. Specially, an axial-attention-improved encoder architecture is designed to highlight the effective features of small targets and suppress background noises. Furthermore, the developed MSPB structure fuses the coarse-grained and fine-grained features from different semantic scales. Extensive experiments on the SIRST dataset show the superiority performance and effectiveness of the proposed MPANet compared to the state-of-the-art methods.
* 4 pages 3 figures
Optimizing Nitrogen Management with Deep Reinforcement Learning and Crop Simulations
Apr 21, 2022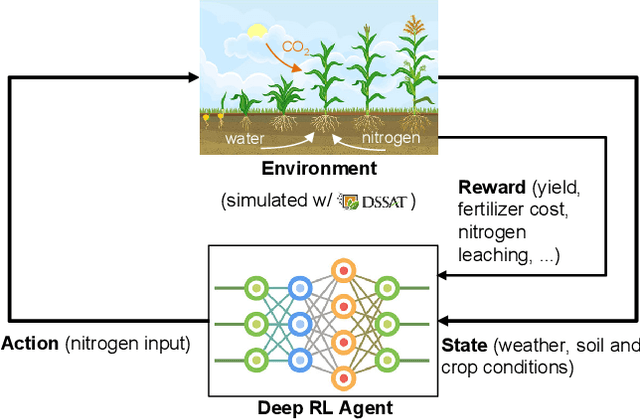

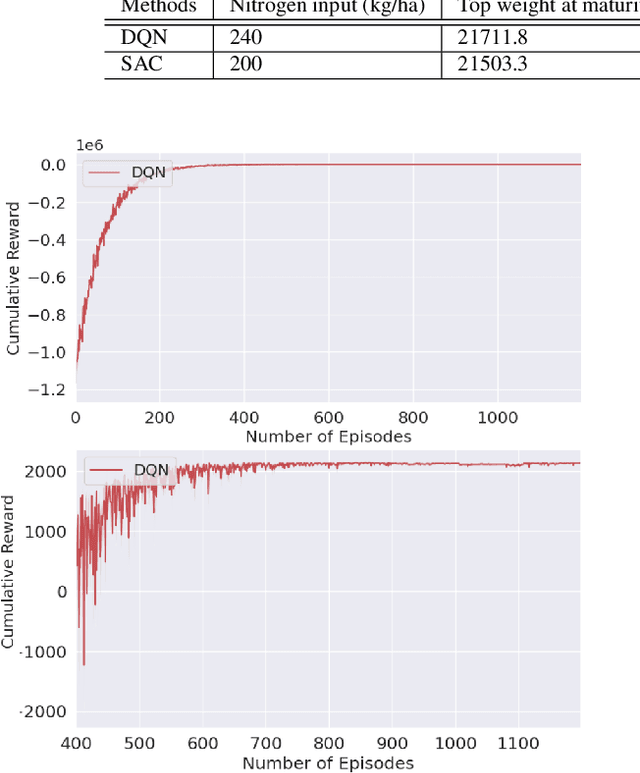
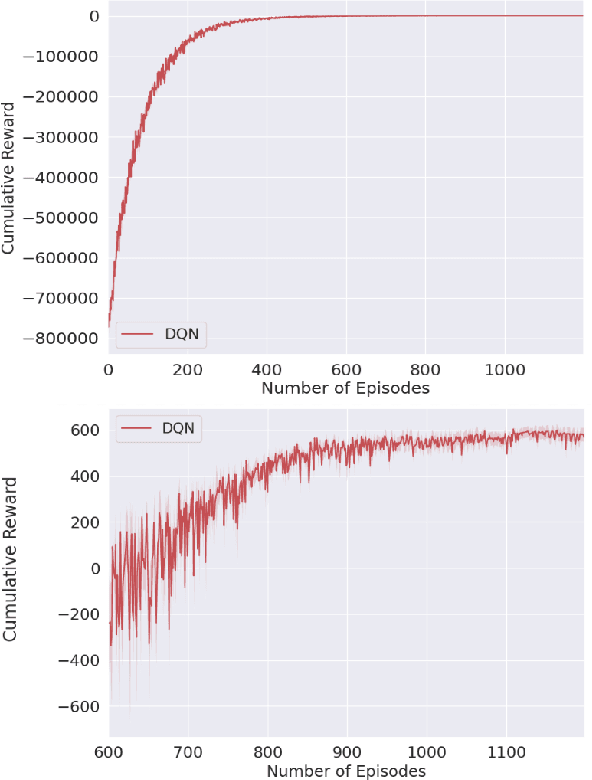
Nitrogen (N) management is critical to sustain soil fertility and crop production while minimizing the negative environmental impact, but is challenging to optimize. This paper proposes an intelligent N management system using deep reinforcement learning (RL) and crop simulations with Decision Support System for Agrotechnology Transfer (DSSAT). We first formulate the N management problem as an RL problem. We then train management policies with deep Q-network and soft actor-critic algorithms, and the Gym-DSSAT interface that allows for daily interactions between the simulated crop environment and RL agents. According to the experiments on the maize crop in both Iowa and Florida in the US, our RL-trained policies outperform previous empirical methods by achieving higher or similar yield while using less fertilizers
Powering Finetuning in Few-shot Learning: Domain-Agnostic Feature Adaptation with Rectified Class Prototypes
Apr 07, 2022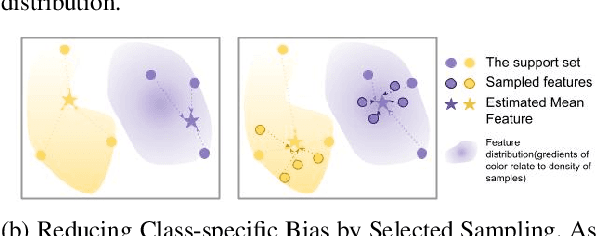

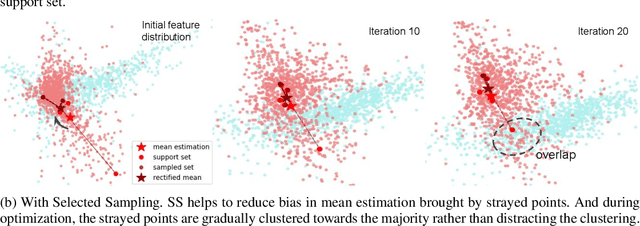
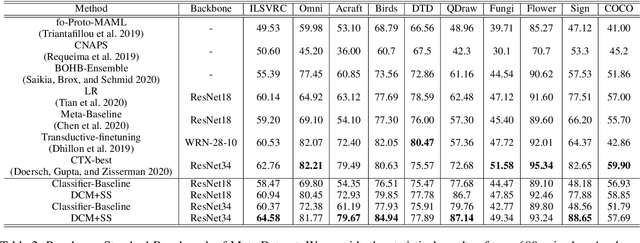
In recent works, utilizing a deep network trained on meta-training set serves as a strong baseline in few-shot learning. In this paper, we move forward to refine novel-class features by finetuning a trained deep network. Finetuning is designed to focus on reducing biases in novel-class feature distributions, which we define as two aspects: class-agnostic and class-specific biases. Class-agnostic bias is defined as the distribution shifting introduced by domain difference, which we propose Distribution Calibration Module(DCM) to reduce. DCM owes good property of eliminating domain difference and fast feature adaptation during optimization. Class-specific bias is defined as the biased estimation using a few samples in novel classes, which we propose Selected Sampling(SS) to reduce. Without inferring the actual class distribution, SS is designed by running sampling using proposal distributions around support-set samples. By powering finetuning with DCM and SS, we achieve state-of-the-art results on Meta-Dataset with consistent performance boosts over ten datasets from different domains. We believe our simple yet effective method demonstrates its possibility to be applied on practical few-shot applications.
MS-HLMO: Multi-scale Histogram of Local Main Orientation for Remote Sensing Image Registration
Apr 01, 2022

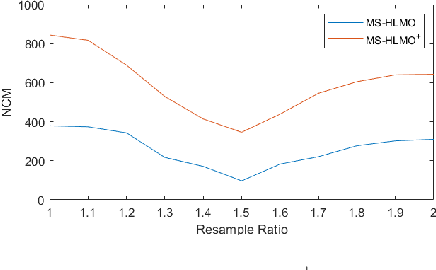

Multi-source image registration is challenging due to intensity, rotation, and scale differences among the images. Considering the characteristics and differences of multi-source remote sensing images, a feature-based registration algorithm named Multi-scale Histogram of Local Main Orientation (MS-HLMO) is proposed. Harris corner detection is first adopted to generate feature points. The HLMO feature of each Harris feature point is extracted on a Partial Main Orientation Map (PMOM) with a Generalized Gradient Location and Orientation Histogram-like (GGLOH) feature descriptor, which provides high intensity, rotation, and scale invariance. The feature points are matched through a multi-scale matching strategy. Comprehensive experiments on 17 multi-source remote sensing scenes demonstrate that the proposed MS-HLMO and its simplified version MS-HLMO$^+$ outperform other competitive registration algorithms in terms of effectiveness and generalization.
A Paired Phase and Magnitude Reconstruction for Advanced Diffusion-Weighted Imaging
Mar 28, 2022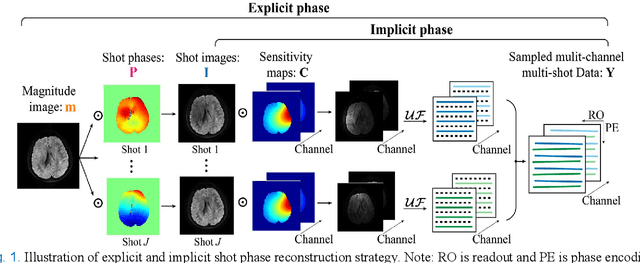
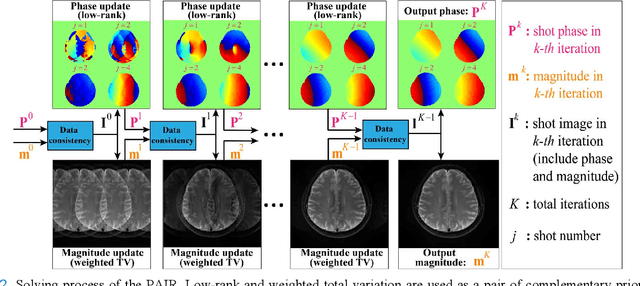
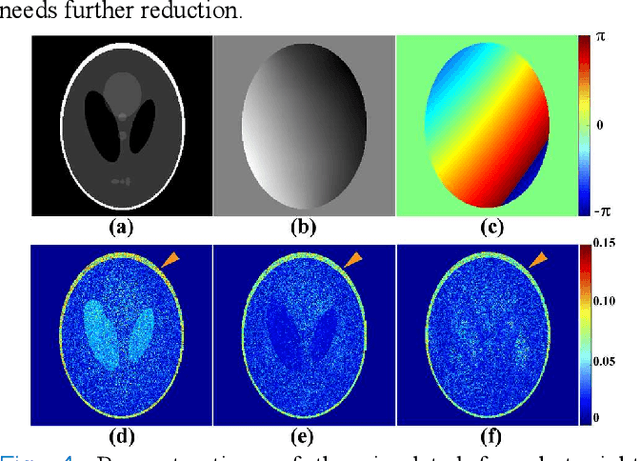
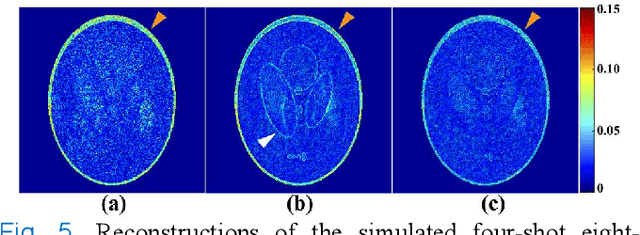
Multi-shot interleaved echo planer imaging can obtain diffusion-weighted images (DWI) with high spatial resolution and low distortion, but suffers from ghost artifacts introduced by phase variations between shots. In this work, we aim at solving the challenging reconstructions under severe motions between shots and low signal-to-noise ratio. An explicit phase model with paired phase and magnitude priors is proposed to regularize the reconstruction (PAIR). The former prior is derived from the smoothness of the shot phase and enforced with low-rankness in the k-space domain. The latter explores similar edges among multi-b-value and multi-direction DWI with weighted total variation in the image domain. Extensive simulation and in vivo results show that PAIR can remove ghost image artifacts very well under the high number of shots (8 shots) and significantly suppress the noise under the ultra-high b-value (4000 s/mm2). The explicit phase model PAIR with complementary priors has a good performance on challenging reconstructions under severe motions between shots and low signal-to-noise ratio. PAIR has great potential in the advanced clinical DWI applications and brain function research.