 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoSHAP: A Distributional Framework and Robust Metric for Stable Feature Attribution
May 14, 2026Feature attribution analysis is critical for interpreting machine learning models and supporting reliable data-driven decisions. However, feature attribution measures often exhibit stochastic variation: different train--test splits, random seeds, or model-fitting procedures can produce substantially different attribution values and feature rankings. This paper proposes a framework for incorporating stochastic nature of feature attribution and a robust attribution metric, RoSHAP, for stable feature ranking based on the SHAP metric. The proposed framework models the distribution of feature attribution scores and estimates it through bootstrap resampling and kernel density estimation. We show that, under mild regularity conditions, the aggregated feature attribution score is asymptotically Gaussian, which greatly reduces the computational cost of distribution estimation. The RoSHAP summarizes the distribution of SHAP into a robust feature-ranking criterion that simultaneously rewards features that are active, strong, and stable. Through simulations and real-data experiments, the proposed framework and RoSHAP outperform standard single-run attribution measures in identifying signal features. In addition, models built using RoSHAP-selected features achieve predictive performance comparable to full-feature models while using substantially fewer predictors. The proposed RoSHAP approach improves the stability and interpretability of machine learning models, enabling reliable and consistent insights for analysis.
Perception Characteristics Distance: Measuring Stability and Robustness of Perception System in Dynamic Conditions under a Certain Decision Rule
Jun 10, 2025



The performance of perception systems in autonomous driving systems (ADS) is strongly influenced by object distance, scene dynamics, and environmental conditions such as weather. AI-based perception outputs are inherently stochastic, with variability driven by these external factors, while traditional evaluation metrics remain static and event-independent, failing to capture fluctuations in confidence over time. In this work, we introduce the Perception Characteristics Distance (PCD) -- a novel evaluation metric that quantifies the farthest distance at which an object can be reliably detected, incorporating uncertainty in model outputs. To support this, we present the SensorRainFall dataset, collected on the Virginia Smart Road using a sensor-equipped vehicle (cameras, radar, LiDAR) under controlled daylight-clear and daylight-rain scenarios, with precise ground-truth distances to the target objects. Statistical analysis reveals the presence of change points in the variance of detection confidence score with distance. By averaging the PCD values across a range of detection quality thresholds and probabilistic thresholds, we compute the mean PCD (mPCD), which captures the overall perception characteristics of a system with respect to detection distance. Applying state-of-the-art perception models shows that mPCD captures meaningful reliability differences under varying weather conditions -- differences that static metrics overlook. PCD provides a principled, distribution-aware measure of perception performance, supporting safer and more robust ADS operation, while the SensorRainFall dataset offers a valuable benchmark for evaluation. The SensorRainFall dataset is publicly available at https://www.kaggle.com/datasets/datadrivenwheels/sensorrainfall, and the evaluation code is open-sourced at https://github.com/datadrivenwheels/PCD_Python.
SynSHRP2: A Synthetic Multimodal Benchmark for Driving Safety-critical Events Derived from Real-world Driving Data
May 06, 2025Driving-related safety-critical events (SCEs), including crashes and near-crashes, provide essential insights for the development and safety evaluation of automated driving systems. However, two major challenges limit their accessibility: the rarity of SCEs and the presence of sensitive privacy information in the data. The Second Strategic Highway Research Program (SHRP 2) Naturalistic Driving Study (NDS), the largest NDS to date, collected millions of hours of multimodal, high-resolution, high-frequency driving data from thousands of participants, capturing thousands of SCEs. While this dataset is invaluable for safety research, privacy concerns and data use restrictions significantly limit public access to the raw data. To address these challenges, we introduce SynSHRP2, a publicly available, synthetic, multimodal driving dataset containing over 1874 crashes and 6924 near-crashes derived from the SHRP 2 NDS. The dataset features de-identified keyframes generated using Stable Diffusion and ControlNet, ensuring the preservation of critical safety-related information while eliminating personally identifiable data. Additionally, SynSHRP2 includes detailed annotations on SCE type, environmental and traffic conditions, and time-series kinematic data spanning 5 seconds before and during each event. Synchronized keyframes and narrative descriptions further enhance its usability. This paper presents two benchmarks for event attribute classification and scene understanding, demonstrating the potential applications of SynSHRP2 in advancing safety research and automated driving system development.
ScVLM: a Vision-Language Model for Driving Safety Critical Event Understanding
Oct 01, 2024Accurately identifying, understanding, and describing driving safety-critical events (SCEs), including crashes and near-crashes, is crucial for traffic safety, automated driving systems, and advanced driver assistance systems research and application. As SCEs are rare events, most general Vision-Language Models (VLMs) have not been trained sufficiently to link SCE videos and narratives, which could lead to hallucination and missing key safety characteristics. To tackle these challenges, we propose ScVLM, a hybrid approach that combines supervised learning and contrastive learning to improve driving video understanding and event description rationality for VLMs. The proposed approach is trained on and evaluated by more than 8,600 SCEs from the Second Strategic Highway Research Program Naturalistic Driving Study dataset, the largest publicly accessible driving dataset with videos and SCE annotations. The results demonstrate the superiority of the proposed approach in generating contextually accurate event descriptions and mitigate hallucinations from VLMs.
SUPER: Seated Upper Body Pose Estimation using mmWave Radars
Jul 02, 2024In industrial countries, adults spend a considerable amount of time sedentary each day at work, driving and during activities of daily living. Characterizing the seated upper body human poses using mmWave radars is an important, yet under-studied topic with many applications in human-machine interaction, transportation and road safety. In this work, we devise SUPER, a framework for seated upper body human pose estimation that utilizes dual-mmWave radars in close proximity. A novel masking algorithm is proposed to coherently fuse data from the radars to generate intensity and Doppler point clouds with complementary information for high-motion but small radar cross section areas (e.g., upper extremities) and low-motion but large RCS areas (e.g. torso). A lightweight neural network extracts both global and local features of upper body and output pose parameters for the Skinned Multi-Person Linear (SMPL) model. Extensive leave-one-subject-out experiments on various motion sequences from multiple subjects show that SUPER outperforms a state-of-the-art baseline method by 30 -- 184%. We also demonstrate its utility in a simple downstream task for hand-object interaction.
Pi-ViMo: Physiology-inspired Robust Vital Sign Monitoring using mmWave Radars
Mar 24, 2023



Continuous monitoring of human vital signs using non-contact mmWave radars is attractive due to their ability to penetrate garments and operate under different lighting conditions. Unfortunately, most prior research requires subjects to stay at a fixed distance from radar sensors and to remain still during monitoring. These restrictions limit the applications of radar vital sign monitoring in real life scenarios. In this paper, we address these limitations and present "Pi-ViMo", a non-contact Physiology-inspired Robust Vital Sign Monitoring system, using mmWave radars. We first derive a multi-scattering point model for the human body, and introduce a coherent combining of multiple scatterings to enhance the quality of estimated chest-wall movements. It enables vital sign estimations of subjects at any location in a radar's field of view. We then propose a template matching method to extract human vital signs by adopting physical models of respiration and cardiac activities. The proposed method is capable to separate respiration and heartbeat in the presence of micro-level random body movements (RBM) when a subject is at any location within the field of view of a radar. Experiments in a radar testbed show average respiration rate errors of 6% and heart rate errors of 11.9% for the stationary subjects and average errors of 13.5% for respiration rate and 13.6% for heart rate for subjects under different RBMs.
Physics-informed deep diffusion MRI reconstruction: break the bottleneck of training data in artificial intelligence
Oct 20, 2022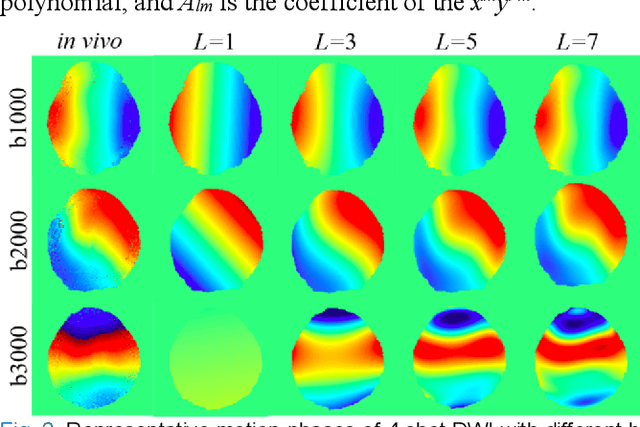
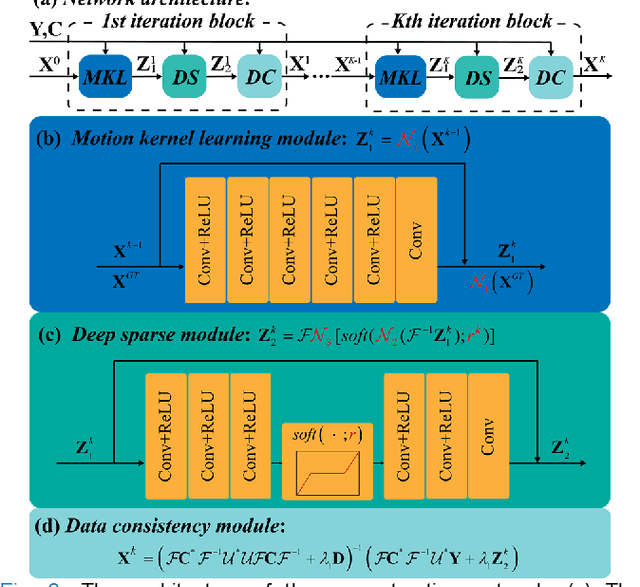
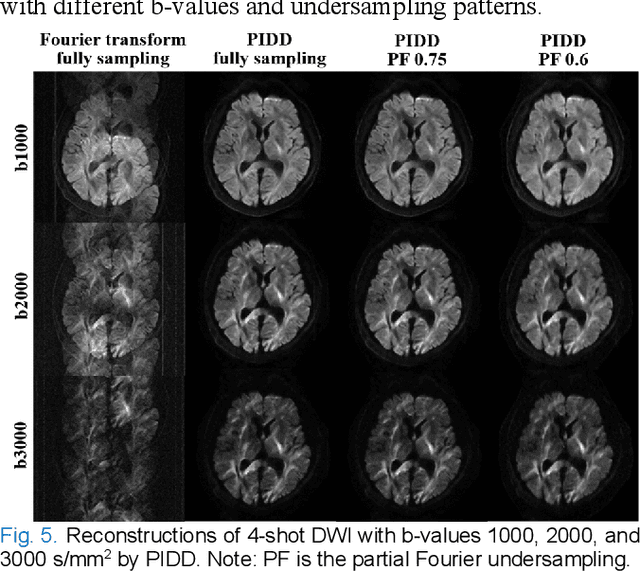
In this work, we propose a Physics-Informed Deep Diffusion magnetic resonance imaging (DWI) reconstruction method (PIDD). PIDD contains two main components: The multi-shot DWI data synthesis and a deep learning reconstruction network. For data synthesis, we first mathematically analyze the motion during the multi-shot data acquisition and approach it by a simplified physical motion model. The motion model inspires a polynomial model for motion-induced phase synthesis. Then, lots of synthetic phases are combined with a few real data to generate a large amount of training data. For reconstruction network, we exploit the smoothness property of each shot image phase as learnable convolution kernels in the k-space and complementary sparsity in the image domain. Results on both synthetic and in vivo brain data show that, the proposed PIDD trained on synthetic data enables sub-second ultra-fast, high-quality, and robust reconstruction with different b-values and undersampling patterns.
A Paired Phase and Magnitude Reconstruction for Advanced Diffusion-Weighted Imaging
Mar 28, 2022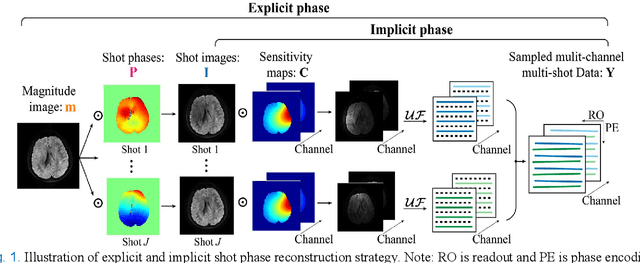
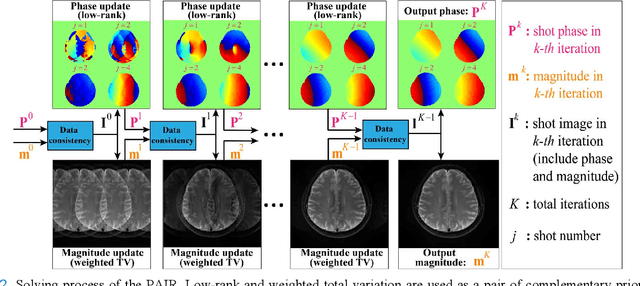
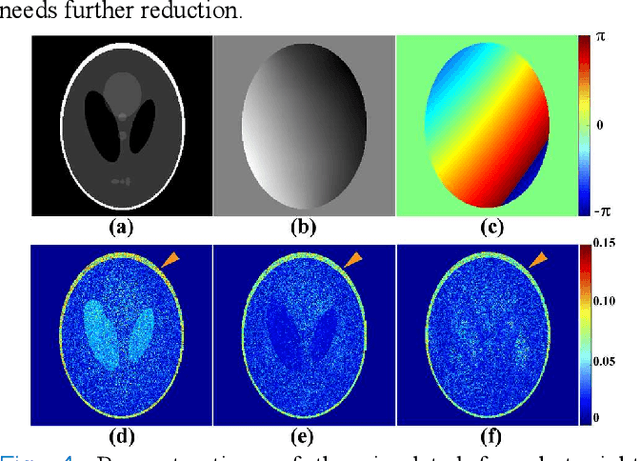
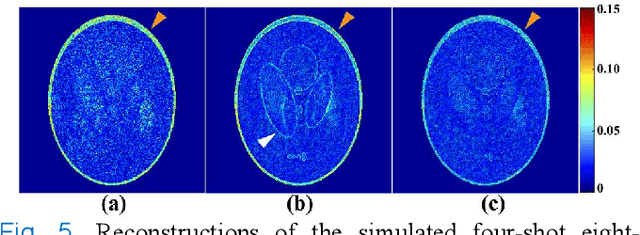
Multi-shot interleaved echo planer imaging can obtain diffusion-weighted images (DWI) with high spatial resolution and low distortion, but suffers from ghost artifacts introduced by phase variations between shots. In this work, we aim at solving the challenging reconstructions under severe motions between shots and low signal-to-noise ratio. An explicit phase model with paired phase and magnitude priors is proposed to regularize the reconstruction (PAIR). The former prior is derived from the smoothness of the shot phase and enforced with low-rankness in the k-space domain. The latter explores similar edges among multi-b-value and multi-direction DWI with weighted total variation in the image domain. Extensive simulation and in vivo results show that PAIR can remove ghost image artifacts very well under the high number of shots (8 shots) and significantly suppress the noise under the ultra-high b-value (4000 s/mm2). The explicit phase model PAIR with complementary priors has a good performance on challenging reconstructions under severe motions between shots and low signal-to-noise ratio. PAIR has great potential in the advanced clinical DWI applications and brain function research.