 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Mind: Efficient Visual Chain-of-Thought via Predictive World Model for End-to-End Driving
Jun 27, 2026Predicting future states is essential for autonomous agents, yet current Vision-Language-Action (VLA) models fundamentally lack this capability, relying instead on reactive perception-action mapping. While integrating Predictive World Models (PWMs) addresses this gap, existing approaches either incur prohibitive cascaded latency or act as shallow terminal tasks that fail to deeply embed forward-looking reasoning. To endow VLA models with this reasoning capability, we propose X-Mind. Rather than treating PWMs as an external auxiliary module, this framework internalizes them as the Visual Chain-of-Thought (Visual CoT). By enforcing a world rollout prior to action, the model is constrained to imagine future evolution first, yielding a driving policy that is robustly grounded in environmental dynamics and aware of the future consequences its actions will unfold. The challenge here is efficiency, and we tackle it on two fronts. First, we introduce a compact representation of visual thinking: an abstract sketch that fuses a Bird's-Eye-View (BEV) layout with abstract driving priors (e.g., navigation intents and traffic rules). Rather than rolling out dense future frames, the model reasons over this sketch as a mental canvas; aided by a Deep Compression Autoencoder (DC-AE), a 12-frame future rollout is reduced to merely 96 tokens, alleviating the long-context computational bottleneck. Second, to accelerate generation further, we propose a recurrent block diffusion scheme that unrolls the denoising steps across the layers of the large drive model, folding iterative refinement into the backbone's one forward pass. Trained and validated on large-scale real-world data, X-Mind achieves competitive end-to-end driving performance, which makes it a highly practical, low-latency solution that successfully deploys large-scale cognitive reasoning directly onto resource-constrained vehicle platforms.
X-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling
May 24, 2026Physical world knowledge resides mainly in videos. Equipping Vision-Language-Action (VLA) models with such knowledge is fundamental for safe and generalizable planning. Predictive world modeling enables VLA to internalize physical dynamics and long-term causality by predicting future video from past observations. However, naive next-frame prediction faces two challenges: 1) unlike semantically distinct text tokens, video tokens are low-entropy and redundant, causing prediction to degenerate into trivial extrapolation. 2) world modeling poses a temporal dilemma: dense prediction captures instantaneous dynamics, but cannot efficiently model long-horizon causality. To learn world knowledge effectively, we introduce X-Foresight, a predictive world model integrated directly into the VLA architecture to jointly learn world modeling and real-time action control. At its core lies a long-horizon chunk-wise auto-regressive strategy that addresses both challenges: by predicting semantically distant chunks rather than adjacent frames, it escapes trivial extrapolation, while preserving dense intra-chunk frames for instantaneous dynamics and sparse inter-chunk transitions for long-term causality. A curriculum learning schedule progressively extends prediction horizons and stabilizes long-horizon training. To capture long-term causality effectively, we present temporal importance sampling, which concentrates supervision on safety-critical chunks identified by ego-motion and behavioral signals. We further delegate photorealistic synthesis to a diffusion-based multi-view renderer, improving photorealistic appearance. Comprehensive experiments demonstrate that X-Foresight significantly outperforms VLA baselines in planning performance while maintaining strong generative fidelity, establishing a robust paradigm for world-knowledge-driven autonomous systems.
Joint Training Scattering Matrix Learning and Channel Estimation for Beyond-Diagonal Reconfigurable Intelligent Surfaces
Mar 26, 2026Beyond-diagonal reconfigurable intelligent surface (BD-RIS) generalizes the conventional diagonal RIS (D-RIS) by introducing tunable inter-element connections, offering enhanced wave manipulation capabilities. However, realizing the advantages of BD-RIS requires accurate channel state information (CSI), whose acquisition becomes significantly more challenging due to the increased number of channel coefficients, leading to prohibitively large pilot training overhead in BD-RIS-aided multi-user multiple-input multiple-output (MU-MIMO) systems. Existing studies reduce pilot overhead by exploiting the channel correlations induced by the Kronecker-product or multi-linear structure of BD-RIS-aided channels, which neglect the spatial correlation among antennas and the statistical correlation across RIS-user channels. In this paper, we propose a learning-based channel estimation framework, namely the joint training scattering matrix learning and channel estimation framework (JTSMLCEF), which jointly optimizes the BD-RIS training scattering matrix and estimates the cascaded channels in an end-to-end manner to achieve accurate channel estimation and reduce the pilot overhead. The proposed JTSMLCEF follows a two-phase channel estimation protocol to enable adaptive training scattering matrix optimization with a training scattering matrix optimizer (TSMO) and cascaded channel estimation with a dual-attention channel estimator (DACE). Specifically, the DACE is designed with intra-user and inter-user attention modules to capture the multi-dimensional correlations in multi-user cascaded channels. Simulation results demonstrate the superiority of JTSMLCEF. Compared with the current state-of-the-art method, it reduces the pilot overhead by $80\%$ while further reducing the normalized mean squared error (NMSE) by $82.6\%$ and $92.5\%$ in indoor and urban micro-cell (UMi) scenarios, respectively.
Voices of Civilizations: A Multilingual QA Benchmark for Global Music Understanding
Feb 28, 2026We introduce Voices of Civilizations, the first multilingual QA benchmark for evaluating audio LLMs' cultural comprehension on full-length music recordings. Covering 380 tracks across 38 languages, our automated pipeline yields 1,190 multiple-choice questions through four stages - each followed by manual verification: 1) compiling a representative music list; 2) generating cultural-background documents for each sample in the music list via LLMs; 3) extracting key attributes from those documents; and 4) constructing multiple-choice questions probing language, region associations, mood, and thematic content. We evaluate models under four conditions and report per-language accuracy. Our findings demonstrate that even state-of-the-art audio LLMs struggle to capture subtle cultural nuances without rich textual context and exhibit systematic biases in interpreting music from different cultural traditions. The dataset is publicly available on Hugging Face to foster culturally inclusive music understanding research.
ScenePilot-Bench: A Large-Scale Dataset and Benchmark for Evaluation of Vision-Language Models in Autonomous Driving
Jan 27, 2026In this paper, we introduce ScenePilot-Bench, a large-scale first-person driving benchmark designed to evaluate vision-language models (VLMs) in autonomous driving scenarios. ScenePilot-Bench is built upon ScenePilot-4K, a diverse dataset comprising 3,847 hours of driving videos, annotated with multi-granularity information including scene descriptions, risk assessments, key participant identification, ego trajectories, and camera parameters. The benchmark features a four-axis evaluation suite that assesses VLM capabilities in scene understanding, spatial perception, motion planning, and GPT-Score, with safety-aware metrics and cross-region generalization settings. We benchmark representative VLMs on ScenePilot-Bench, providing empirical analyses that clarify current performance boundaries and identify gaps for driving-oriented reasoning. ScenePilot-Bench offers a comprehensive framework for evaluating and advancing VLMs in safety-critical autonomous driving contexts.
A Reference-Based 3D Semantic-Aware Framework for Accurate Local Facial Attribute Editing
Jul 29, 2024



Facial attribute editing plays a crucial role in synthesizing realistic faces with specific characteristics while maintaining realistic appearances. Despite advancements, challenges persist in achieving precise, 3D-aware attribute modifications, which are crucial for consistent and accurate representations of faces from different angles. Current methods struggle with semantic entanglement and lack effective guidance for incorporating attributes while maintaining image integrity. To address these issues, we introduce a novel framework that merges the strengths of latent-based and reference-based editing methods. Our approach employs a 3D GAN inversion technique to embed attributes from the reference image into a tri-plane space, ensuring 3D consistency and realistic viewing from multiple perspectives. We utilize blending techniques and predicted semantic masks to locate precise edit regions, merging them with the contextual guidance from the reference image. A coarse-to-fine inpainting strategy is then applied to preserve the integrity of untargeted areas, significantly enhancing realism. Our evaluations demonstrate superior performance across diverse editing tasks, validating our framework's effectiveness in realistic and applicable facial attribute editing.
Detecting subtle macroscopic changes in a finite temperature classical scalar field with machine learning
Nov 21, 2023The ability to detect macroscopic changes is important for probing the behaviors of experimental many-body systems from the classical to the quantum realm. Although abrupt changes near phase boundaries can easily be detected, subtle macroscopic changes are much more difficult to detect as the changes can be obscured by noise. In this study, as a toy model for detecting subtle macroscopic changes in many-body systems, we try to differentiate scalar field samples at varying temperatures. We compare different methods for making such differentiations, from physics method, statistics method, to AI method. Our finding suggests that the AI method outperforms both the statistical method and the physics method in its sensitivity. Our result provides a proof-of-concept that AI can potentially detect macroscopic changes in many-body systems that elude physical measures.
Powering Finetuning in Few-shot Learning: Domain-Agnostic Feature Adaptation with Rectified Class Prototypes
Apr 07, 2022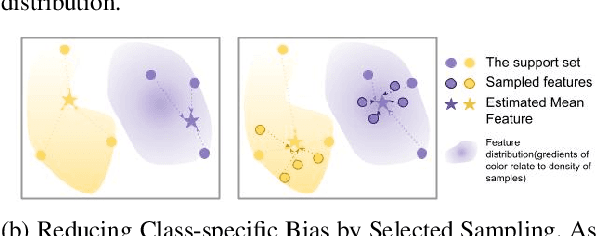

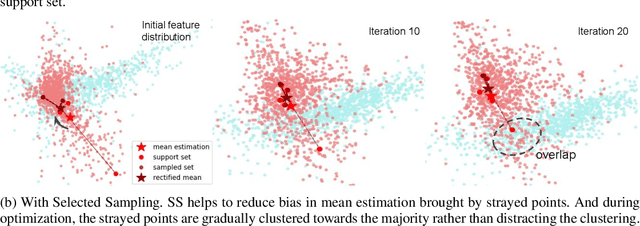
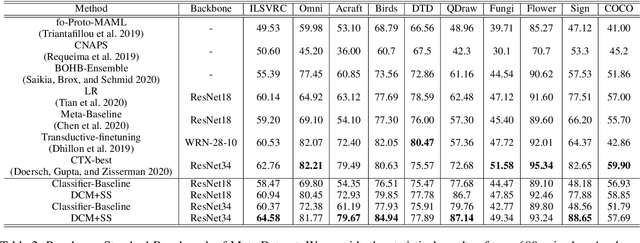
In recent works, utilizing a deep network trained on meta-training set serves as a strong baseline in few-shot learning. In this paper, we move forward to refine novel-class features by finetuning a trained deep network. Finetuning is designed to focus on reducing biases in novel-class feature distributions, which we define as two aspects: class-agnostic and class-specific biases. Class-agnostic bias is defined as the distribution shifting introduced by domain difference, which we propose Distribution Calibration Module(DCM) to reduce. DCM owes good property of eliminating domain difference and fast feature adaptation during optimization. Class-specific bias is defined as the biased estimation using a few samples in novel classes, which we propose Selected Sampling(SS) to reduce. Without inferring the actual class distribution, SS is designed by running sampling using proposal distributions around support-set samples. By powering finetuning with DCM and SS, we achieve state-of-the-art results on Meta-Dataset with consistent performance boosts over ten datasets from different domains. We believe our simple yet effective method demonstrates its possibility to be applied on practical few-shot applications.
Unsupervised Disentanglement of Linear-Encoded Facial Semantics
Mar 30, 2021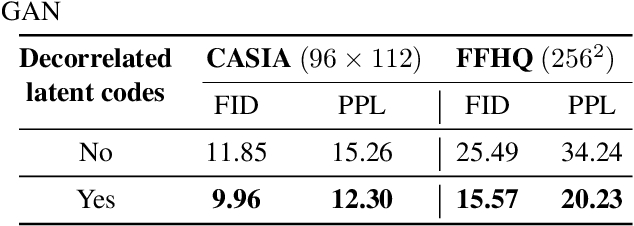
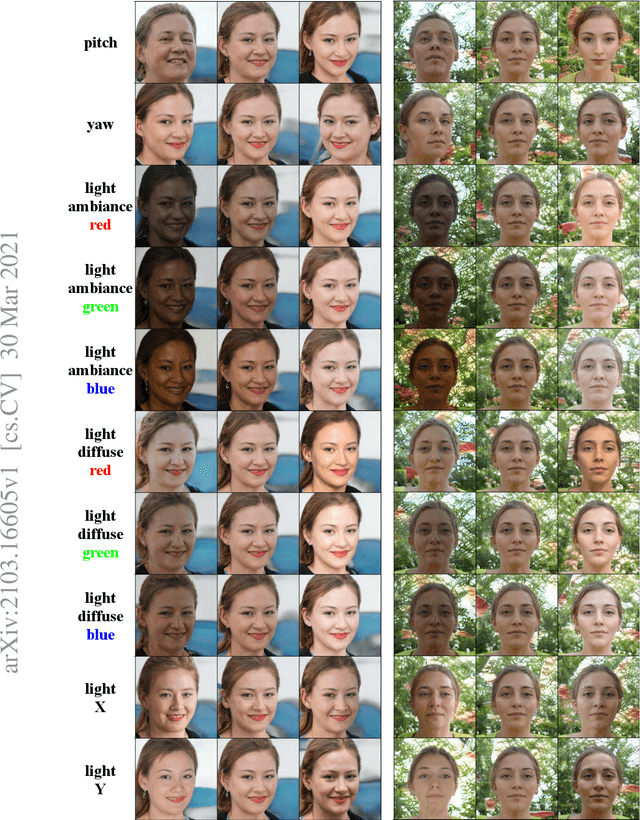
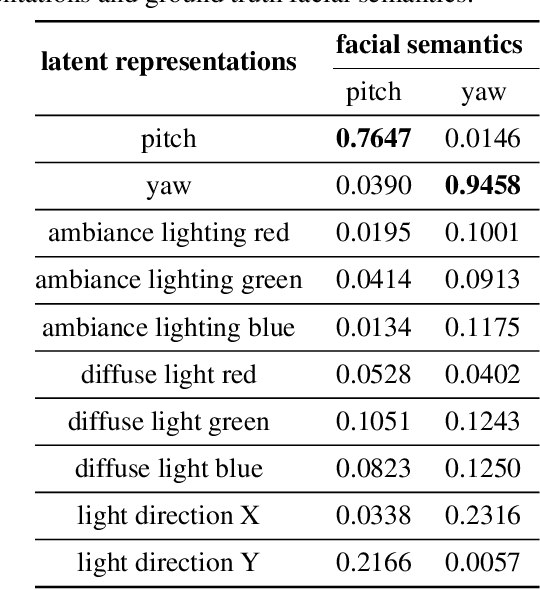
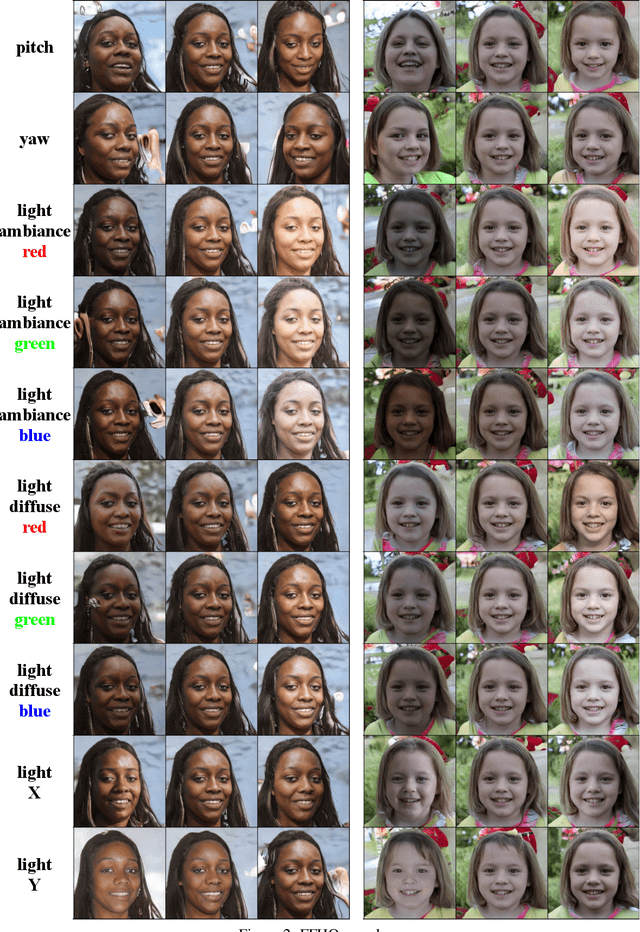
We propose a method to disentangle linear-encoded facial semantics from StyleGAN without external supervision. The method derives from linear regression and sparse representation learning concepts to make the disentangled latent representations easily interpreted as well. We start by coupling StyleGAN with a stabilized 3D deformable facial reconstruction method to decompose single-view GAN generations into multiple semantics. Latent representations are then extracted to capture interpretable facial semantics. In this work, we make it possible to get rid of labels for disentangling meaningful facial semantics. Also, we demonstrate that the guided extrapolation along the disentangled representations can help with data augmentation, which sheds light on handling unbalanced data. Finally, we provide an analysis of our learned localized facial representations and illustrate that the semantic information is encoded, which surprisingly complies with human intuition. The overall unsupervised design brings more flexibility to representation learning in the wild.
Adversarial-Based Knowledge Distillation for Multi-Model Ensemble and Noisy Data Refinement
Aug 22, 2019
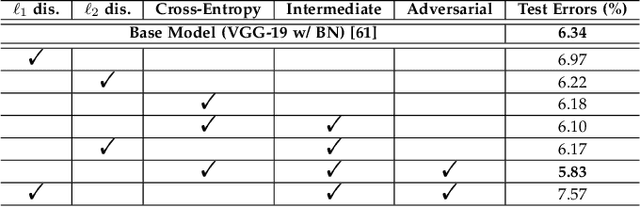
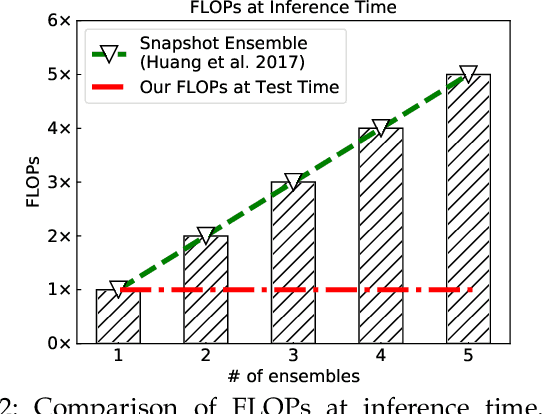
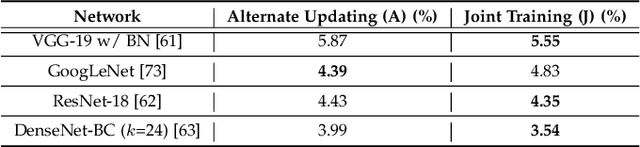
Generic Image recognition is a fundamental and fairly important visual problem in computer vision. One of the major challenges of this task lies in the fact that single image usually has multiple objects inside while the labels are still one-hot, another one is noisy and sometimes missing labels when annotated by humans. In this paper, we focus on tackling these challenges accompanying with two different image recognition problems: multi-model ensemble and noisy data recognition with a unified framework. As is well-known, usually the best performing deep neural models are ensembles of multiple base-level networks, as it can mitigate the variation or noise containing in the dataset. Unfortunately, the space required to store these many networks, and the time required to execute them at runtime, prohibit their use in applications where test sets are large (e.g., ImageNet). In this paper, we present a method for compressing large, complex trained ensembles into a single network, where the knowledge from a variety of trained deep neural networks (DNNs) is distilled and transferred to a single DNN. In order to distill diverse knowledge from different trained (teacher) models, we propose to use adversarial-based learning strategy where we define a block-wise training loss to guide and optimize the predefined student network to recover the knowledge in teacher models, and to promote the discriminator network to distinguish teacher vs. student features simultaneously. Extensive experiments on CIFAR-10/100, SVHN, ImageNet and iMaterialist Challenge Dataset demonstrate the effectiveness of our MEAL method. On ImageNet, our ResNet-50 based MEAL achieves top-1/5 21.79%/5.99% val error, which outperforms the original model by 2.06%/1.14%. On iMaterialist Challenge Dataset, our MEAL obtains a remarkable improvement of top-3 1.15% (official evaluation metric) on a strong baseline model of ResNet-101.