 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpand and Prune: Maximizing Trajectory Diversity for Effective GRPO in Generative Models
Dec 17, 2025Group Relative Policy Optimization (GRPO) is a powerful technique for aligning generative models, but its effectiveness is bottlenecked by the conflict between large group sizes and prohibitive computational costs. In this work, we investigate the trade-off through empirical studies, yielding two key observations. First, we discover the reward clustering phenomenon in which many trajectories collapse toward the group-mean reward, offering limited optimization value. Second, we design a heuristic strategy named Optimal Variance Filtering (OVF), and verify that a high-variance subset of trajectories, selected by OVF can outperform the larger, unfiltered group. However, this static, post-sampling OVF approach still necessitates critical computational overhead, as it performs unnecessary sampling for trajectories that are ultimately discarded. To resolve this, we propose Pro-GRPO (Proactive GRPO), a novel dynamic framework that integrates latent feature-based trajectory pruning into the sampling process. Through the early termination of reward-clustered trajectories, Pro-GRPO reduces computational overhead. Leveraging its efficiency, Pro-GRPO employs an "Expand-and-Prune" strategy. This strategy first expands the size of initial sampling group to maximize trajectory diversity, then it applies multi-step OVF to the latents, avoiding prohibitive computational costs. Extensive experiments on both diffusion-based and flow-based models demonstrate the generality and effectiveness of our Pro-GRPO framework.
VITA-VLA: Efficiently Teaching Vision-Language Models to Act via Action Expert Distillation
Oct 10, 2025Vision-Language Action (VLA) models significantly advance robotic manipulation by leveraging the strong perception capabilities of pretrained vision-language models (VLMs). By integrating action modules into these pretrained models, VLA methods exhibit improved generalization. However, training them from scratch is costly. In this work, we propose a simple yet effective distillation-based framework that equips VLMs with action-execution capability by transferring knowledge from pretrained small action models. Our architecture retains the original VLM structure, adding only an action token and a state encoder to incorporate physical inputs. To distill action knowledge, we adopt a two-stage training strategy. First, we perform lightweight alignment by mapping VLM hidden states into the action space of the small action model, enabling effective reuse of its pretrained action decoder and avoiding expensive pretraining. Second, we selectively fine-tune the language model, state encoder, and action modules, enabling the system to integrate multimodal inputs with precise action generation. Specifically, the action token provides the VLM with a direct handle for predicting future actions, while the state encoder allows the model to incorporate robot dynamics not captured by vision alone. This design yields substantial efficiency gains over training large VLA models from scratch. Compared with previous state-of-the-art methods, our method achieves 97.3% average success rate on LIBERO (11.8% improvement) and 93.5% on LIBERO-LONG (24.5% improvement). In real-world experiments across five manipulation tasks, our method consistently outperforms the teacher model, achieving 82.0% success rate (17% improvement), which demonstrate that action distillation effectively enables VLMs to generate precise actions while substantially reducing training costs.
Towards Robust Defense against Customization via Protective Perturbation Resistant to Diffusion-based Purification
Sep 19, 2025Diffusion models like Stable Diffusion have become prominent in visual synthesis tasks due to their powerful customization capabilities, which also introduce significant security risks, including deepfakes and copyright infringement. In response, a class of methods known as protective perturbation emerged, which mitigates image misuse by injecting imperceptible adversarial noise. However, purification can remove protective perturbations, thereby exposing images again to the risk of malicious forgery. In this work, we formalize the anti-purification task, highlighting challenges that hinder existing approaches, and propose a simple diagnostic protective perturbation named AntiPure. AntiPure exposes vulnerabilities of purification within the "purification-customization" workflow, owing to two guidance mechanisms: 1) Patch-wise Frequency Guidance, which reduces the model's influence over high-frequency components in the purified image, and 2) Erroneous Timestep Guidance, which disrupts the model's denoising strategy across different timesteps. With additional guidance, AntiPure embeds imperceptible perturbations that persist under representative purification settings, achieving effective post-customization distortion. Experiments show that, as a stress test for purification, AntiPure achieves minimal perceptual discrepancy and maximal distortion, outperforming other protective perturbation methods within the purification-customization workflow.
A Comprehensive Survey on Trustworthiness in Reasoning with Large Language Models
Sep 04, 2025The development of Long-CoT reasoning has advanced LLM performance across various tasks, including language understanding, complex problem solving, and code generation. This paradigm enables models to generate intermediate reasoning steps, thereby improving both accuracy and interpretability. However, despite these advancements, a comprehensive understanding of how CoT-based reasoning affects the trustworthiness of language models remains underdeveloped. In this paper, we survey recent work on reasoning models and CoT techniques, focusing on five core dimensions of trustworthy reasoning: truthfulness, safety, robustness, fairness, and privacy. For each aspect, we provide a clear and structured overview of recent studies in chronological order, along with detailed analyses of their methodologies, findings, and limitations. Future research directions are also appended at the end for reference and discussion. Overall, while reasoning techniques hold promise for enhancing model trustworthiness through hallucination mitigation, harmful content detection, and robustness improvement, cutting-edge reasoning models themselves often suffer from comparable or even greater vulnerabilities in safety, robustness, and privacy. By synthesizing these insights, we hope this work serves as a valuable and timely resource for the AI safety community to stay informed on the latest progress in reasoning trustworthiness. A full list of related papers can be found at \href{https://github.com/ybwang119/Awesome-reasoning-safety}{https://github.com/ybwang119/Awesome-reasoning-safety}.
InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Aug 19, 2025



Recent breakthroughs in video AIGC have ushered in a transformative era for audio-driven human animation. However, conventional video dubbing techniques remain constrained to mouth region editing, resulting in discordant facial expressions and body gestures that compromise viewer immersion. To overcome this limitation, we introduce sparse-frame video dubbing, a novel paradigm that strategically preserves reference keyframes to maintain identity, iconic gestures, and camera trajectories while enabling holistic, audio-synchronized full-body motion editing. Through critical analysis, we identify why naive image-to-video models fail in this task, particularly their inability to achieve adaptive conditioning. Addressing this, we propose InfiniteTalk, a streaming audio-driven generator designed for infinite-length long sequence dubbing. This architecture leverages temporal context frames for seamless inter-chunk transitions and incorporates a simple yet effective sampling strategy that optimizes control strength via fine-grained reference frame positioning. Comprehensive evaluations on HDTF, CelebV-HQ, and EMTD datasets demonstrate state-of-the-art performance. Quantitative metrics confirm superior visual realism, emotional coherence, and full-body motion synchronization.
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Aug 07, 2025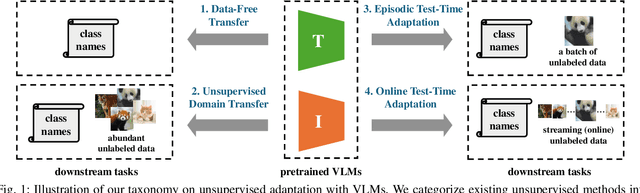
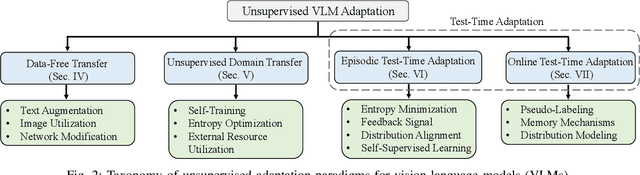
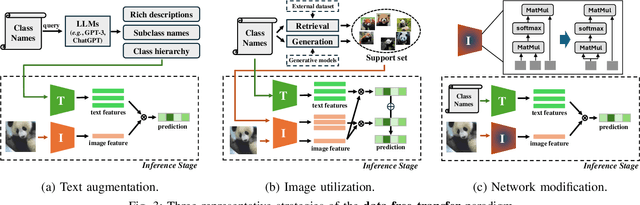
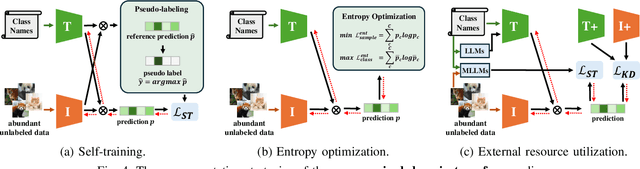
Vision-Language Models (VLMs) have demonstrated remarkable generalization capabilities across a wide range of tasks. However, their performance often remains suboptimal when directly applied to specific downstream scenarios without task-specific adaptation. To enhance their utility while preserving data efficiency, recent research has increasingly focused on unsupervised adaptation methods that do not rely on labeled data. Despite the growing interest in this area, there remains a lack of a unified, task-oriented survey dedicated to unsupervised VLM adaptation. To bridge this gap, we present a comprehensive and structured overview of the field. We propose a taxonomy based on the availability and nature of unlabeled visual data, categorizing existing approaches into four key paradigms: Data-Free Transfer (no data), Unsupervised Domain Transfer (abundant data), Episodic Test-Time Adaptation (batch data), and Online Test-Time Adaptation (streaming data). Within this framework, we analyze core methodologies and adaptation strategies associated with each paradigm, aiming to establish a systematic understanding of the field. Additionally, we review representative benchmarks across diverse applications and highlight open challenges and promising directions for future research. An actively maintained repository of relevant literature is available at https://github.com/tim-learn/Awesome-LabelFree-VLMs.
Test-Time Immunization: A Universal Defense Framework Against Jailbreaks for (Multimodal) Large Language Models
May 28, 2025While (multimodal) large language models (LLMs) have attracted widespread attention due to their exceptional capabilities, they remain vulnerable to jailbreak attacks. Various defense methods are proposed to defend against jailbreak attacks, however, they are often tailored to specific types of jailbreak attacks, limiting their effectiveness against diverse adversarial strategies. For instance, rephrasing-based defenses are effective against text adversarial jailbreaks but fail to counteract image-based attacks. To overcome these limitations, we propose a universal defense framework, termed Test-time IMmunization (TIM), which can adaptively defend against various jailbreak attacks in a self-evolving way. Specifically, TIM initially trains a gist token for efficient detection, which it subsequently applies to detect jailbreak activities during inference. When jailbreak attempts are identified, TIM implements safety fine-tuning using the detected jailbreak instructions paired with refusal answers. Furthermore, to mitigate potential performance degradation in the detector caused by parameter updates during safety fine-tuning, we decouple the fine-tuning process from the detection module. Extensive experiments on both LLMs and multimodal LLMs demonstrate the efficacy of TIM.
HAD: Hybrid Architecture Distillation Outperforms Teacher in Genomic Sequence Modeling
May 27, 2025Inspired by the great success of Masked Language Modeling (MLM) in the natural language domain, the paradigm of self-supervised pre-training and fine-tuning has also achieved remarkable progress in the field of DNA sequence modeling. However, previous methods often relied on massive pre-training data or large-scale base models with huge parameters, imposing a significant computational burden. To address this, many works attempted to use more compact models to achieve similar outcomes but still fell short by a considerable margin. In this work, we propose a Hybrid Architecture Distillation (HAD) approach, leveraging both distillation and reconstruction tasks for more efficient and effective pre-training. Specifically, we employ the NTv2-500M as the teacher model and devise a grouping masking strategy to align the feature embeddings of visible tokens while concurrently reconstructing the invisible tokens during MLM pre-training. To validate the effectiveness of our proposed method, we conducted comprehensive experiments on the Nucleotide Transformer Benchmark and Genomic Benchmark. Compared to models with similar parameters, our model achieved excellent performance. More surprisingly, it even surpassed the distillation ceiling-teacher model on some sub-tasks, which is more than 500 $\times$ larger. Lastly, we utilize t-SNE for more intuitive visualization, which shows that our model can gain a sophisticated understanding of the intrinsic representation pattern in genomic sequences.
T^2Agent A Tool-augmented Multimodal Misinformation Detection Agent with Monte Carlo Tree Search
May 26, 2025Real-world multimodal misinformation often arises from mixed forgery sources, requiring dynamic reasoning and adaptive verification. However, existing methods mainly rely on static pipelines and limited tool usage, limiting their ability to handle such complexity and diversity. To address this challenge, we propose T2Agent, a novel misinformation detection agent that incorporates an extensible toolkit with Monte Carlo Tree Search (MCTS). The toolkit consists of modular tools such as web search, forgery detection, and consistency analysis. Each tool is described using standardized templates, enabling seamless integration and future expansion. To avoid inefficiency from using all tools simultaneously, a Bayesian optimization-based selector is proposed to identify a task-relevant subset. This subset then serves as the action space for MCTS to dynamically collect evidence and perform multi-source verification. To better align MCTS with the multi-source nature of misinformation detection, T2Agent extends traditional MCTS with multi-source verification, which decomposes the task into coordinated subtasks targeting different forgery sources. A dual reward mechanism containing a reasoning trajectory score and a confidence score is further proposed to encourage a balance between exploration across mixed forgery sources and exploitation for more reliable evidence. We conduct ablation studies to confirm the effectiveness of the tree search mechanism and tool usage. Extensive experiments further show that T2Agent consistently outperforms existing baselines on challenging mixed-source multimodal misinformation benchmarks, demonstrating its strong potential as a training-free approach for enhancing detection accuracy. The code will be released.
Breaking Complexity Barriers: High-Resolution Image Restoration with Rank Enhanced Linear Attention
May 22, 2025Transformer-based models have made remarkable progress in image restoration (IR) tasks. However, the quadratic complexity of self-attention in Transformer hinders its applicability to high-resolution images. Existing methods mitigate this issue with sparse or window-based attention, yet inherently limit global context modeling. Linear attention, a variant of softmax attention, demonstrates promise in global context modeling while maintaining linear complexity, offering a potential solution to the above challenge. Despite its efficiency benefits, vanilla linear attention suffers from a significant performance drop in IR, largely due to the low-rank nature of its attention map. To counter this, we propose Rank Enhanced Linear Attention (RELA), a simple yet effective method that enriches feature representations by integrating a lightweight depthwise convolution. Building upon RELA, we propose an efficient and effective image restoration Transformer, named LAformer. LAformer achieves effective global perception by integrating linear attention and channel attention, while also enhancing local fitting capabilities through a convolutional gated feed-forward network. Notably, LAformer eliminates hardware-inefficient operations such as softmax and window shifting, enabling efficient processing of high-resolution images. Extensive experiments across 7 IR tasks and 21 benchmarks demonstrate that LAformer outperforms SOTA methods and offers significant computational advantages.