 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Apr 30, 2018


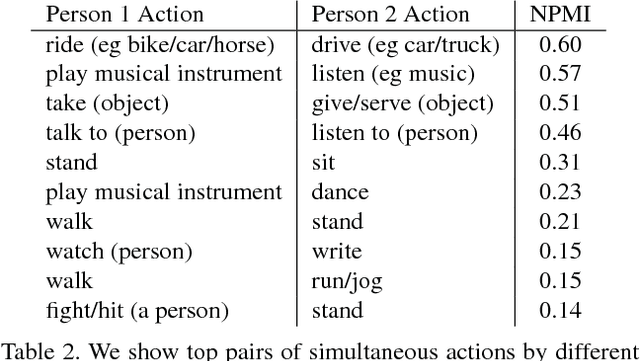
This paper introduces a video dataset of spatio-temporally localized Atomic Visual Actions (AVA). The AVA dataset densely annotates 80 atomic visual actions in 430 15-minute video clips, where actions are localized in space and time, resulting in 1.58M action labels with multiple labels per person occurring frequently. The key characteristics of our dataset are: (1) the definition of atomic visual actions, rather than composite actions; (2) precise spatio-temporal annotations with possibly multiple annotations for each person; (3) exhaustive annotation of these atomic actions over 15-minute video clips; (4) people temporally linked across consecutive segments; and (5) using movies to gather a varied set of action representations. This departs from existing datasets for spatio-temporal action recognition, which typically provide sparse annotations for composite actions in short video clips. We will release the dataset publicly. AVA, with its realistic scene and action complexity, exposes the intrinsic difficulty of action recognition. To benchmark this, we present a novel approach for action localization that builds upon the current state-of-the-art methods, and demonstrates better performance on JHMDB and UCF101-24 categories. While setting a new state of the art on existing datasets, the overall results on AVA are low at 15.6% mAP, underscoring the need for developing new approaches for video understanding.
Rethinking the Faster R-CNN Architecture for Temporal Action Localization
Apr 20, 2018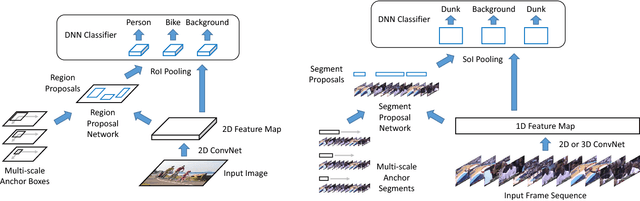
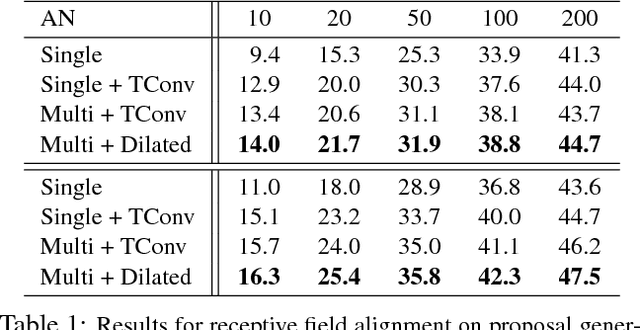
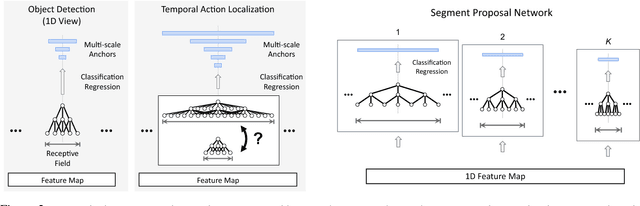
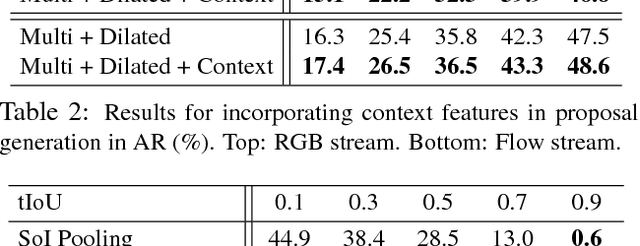
We propose TAL-Net, an improved approach to temporal action localization in video that is inspired by the Faster R-CNN object detection framework. TAL-Net addresses three key shortcomings of existing approaches: (1) we improve receptive field alignment using a multi-scale architecture that can accommodate extreme variation in action durations; (2) we better exploit the temporal context of actions for both proposal generation and action classification by appropriately extending receptive fields; and (3) we explicitly consider multi-stream feature fusion and demonstrate that fusing motion late is important. We achieve state-of-the-art performance for both action proposal and localization on THUMOS'14 detection benchmark and competitive performance on ActivityNet challenge.
Beyond Skip Connections: Top-Down Modulation for Object Detection
Sep 19, 2017

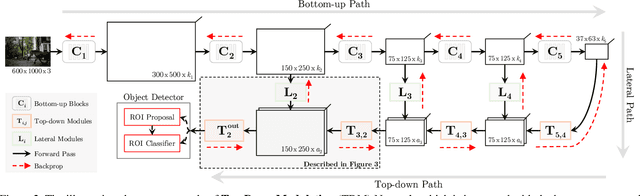
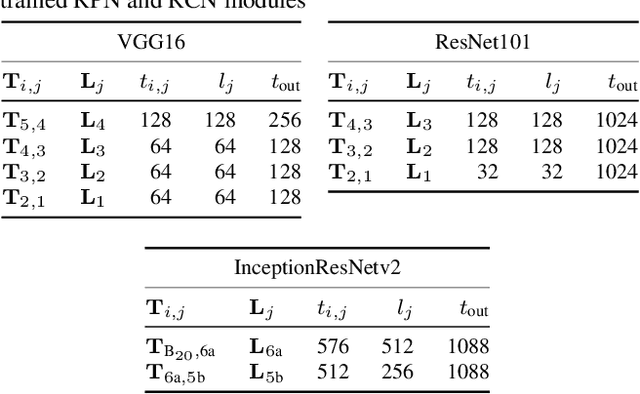
In recent years, we have seen tremendous progress in the field of object detection. Most of the recent improvements have been achieved by targeting deeper feedforward networks. However, many hard object categories such as bottle, remote, etc. require representation of fine details and not just coarse, semantic representations. But most of these fine details are lost in the early convolutional layers. What we need is a way to incorporate finer details from lower layers into the detection architecture. Skip connections have been proposed to combine high-level and low-level features, but we argue that selecting the right features from low-level requires top-down contextual information. Inspired by the human visual pathway, in this paper we propose top-down modulations as a way to incorporate fine details into the detection framework. Our approach supplements the standard bottom-up, feedforward ConvNet with a top-down modulation (TDM) network, connected using lateral connections. These connections are responsible for the modulation of lower layer filters, and the top-down network handles the selection and integration of contextual information and low-level features. The proposed TDM architecture provides a significant boost on the COCO testdev benchmark, achieving 28.6 AP for VGG16, 35.2 AP for ResNet101, and 37.3 for InceptionResNetv2 network, without any bells and whistles (e.g., multi-scale, iterative box refinement, etc.).
WebVision Challenge: Visual Learning and Understanding With Web Data
May 16, 2017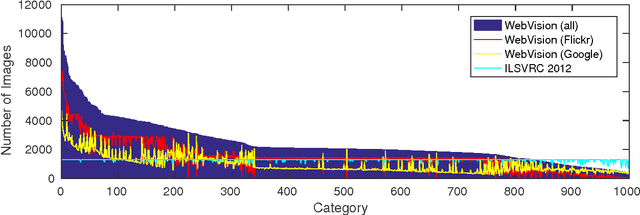

We present the 2017 WebVision Challenge, a public image recognition challenge designed for deep learning based on web images without instance-level human annotation. Following the spirit of previous vision challenges, such as ILSVRC, Places2 and PASCAL VOC, which have played critical roles in the development of computer vision by contributing to the community with large scale annotated data for model designing and standardized benchmarking, we contribute with this challenge a large scale web images dataset, and a public competition with a workshop co-located with CVPR 2017. The WebVision dataset contains more than $2.4$ million web images crawled from the Internet by using queries generated from the $1,000$ semantic concepts of the benchmark ILSVRC 2012 dataset. Meta information is also included. A validation set and test set containing human annotated images are also provided to facilitate algorithmic development. The 2017 WebVision challenge consists of two tracks, the image classification task on WebVision test set, and the transfer learning task on PASCAL VOC 2012 dataset. In this paper, we describe the details of data collection and annotation, highlight the characteristics of the dataset, and introduce the evaluation metrics.
Motion Prediction Under Multimodality with Conditional Stochastic Networks
May 05, 2017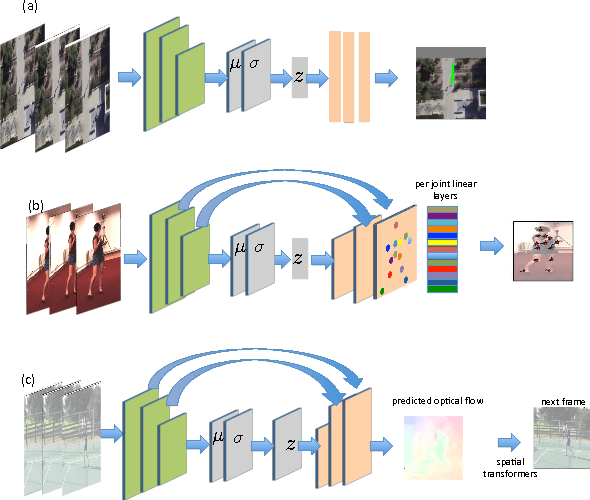
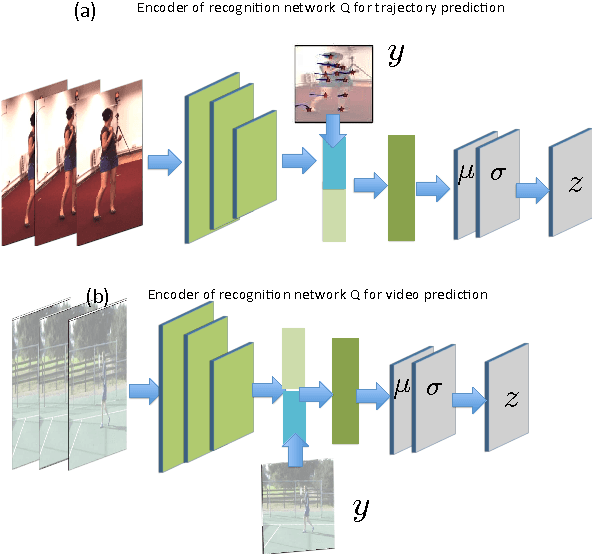

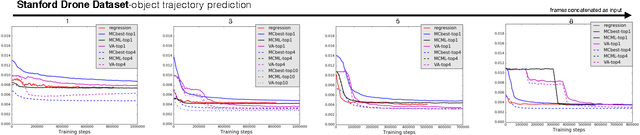
Given a visual history, multiple future outcomes for a video scene are equally probable, in other words, the distribution of future outcomes has multiple modes. Multimodality is notoriously hard to handle by standard regressors or classifiers: the former regress to the mean and the latter discretize a continuous high dimensional output space. In this work, we present stochastic neural network architectures that handle such multimodality through stochasticity: future trajectories of objects, body joints or frames are represented as deep, non-linear transformations of random (as opposed to deterministic) variables. Such random variables are sampled from simple Gaussian distributions whose means and variances are parametrized by the output of convolutional encoders over the visual history. We introduce novel convolutional architectures for predicting future body joint trajectories that outperform fully connected alternatives \cite{DBLP:journals/corr/WalkerDGH16}. We introduce stochastic spatial transformers through optical flow warping for predicting future frames, which outperform their deterministic equivalents \cite{DBLP:journals/corr/PatrauceanHC15}. Training stochastic networks involves an intractable marginalization over stochastic variables. We compare various training schemes that handle such marginalization through a) straightforward sampling from the prior, b) conditional variational autoencoders \cite{NIPS2015_5775,DBLP:journals/corr/WalkerDGH16}, and, c) a proposed K-best-sample loss that penalizes the best prediction under a fixed "prediction budget". We show experimental results on object trajectory prediction, human body joint trajectory prediction and video prediction under varying future uncertainty, validating quantitatively and qualitatively our architectural choices and training schemes.
SfM-Net: Learning of Structure and Motion from Video
Apr 25, 2017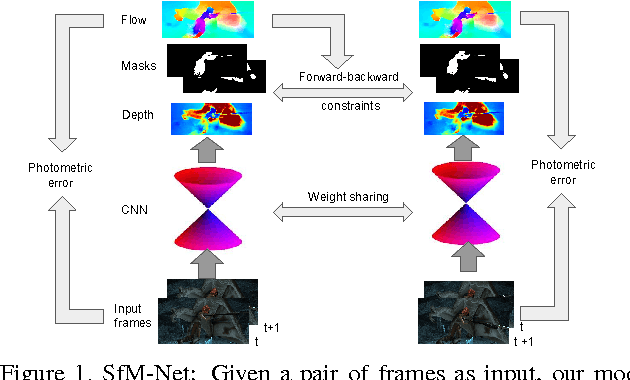
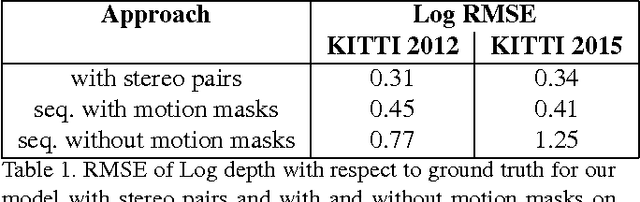
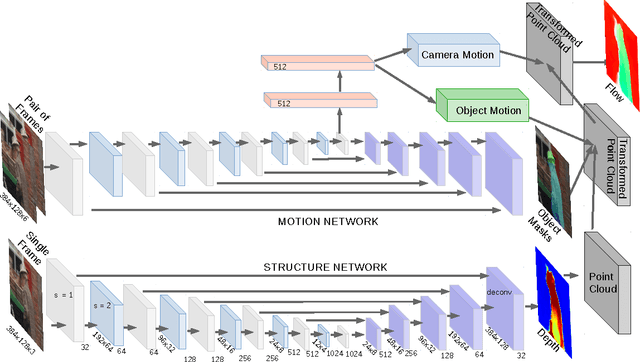
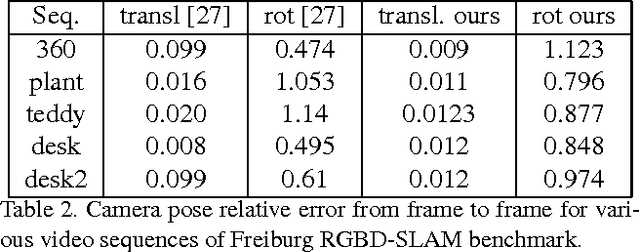
We propose SfM-Net, a geometry-aware neural network for motion estimation in videos that decomposes frame-to-frame pixel motion in terms of scene and object depth, camera motion and 3D object rotations and translations. Given a sequence of frames, SfM-Net predicts depth, segmentation, camera and rigid object motions, converts those into a dense frame-to-frame motion field (optical flow), differentiably warps frames in time to match pixels and back-propagates. The model can be trained with various degrees of supervision: 1) self-supervised by the re-projection photometric error (completely unsupervised), 2) supervised by ego-motion (camera motion), or 3) supervised by depth (e.g., as provided by RGBD sensors). SfM-Net extracts meaningful depth estimates and successfully estimates frame-to-frame camera rotations and translations. It often successfully segments the moving objects in the scene, even though such supervision is never provided.
Robust Adversarial Reinforcement Learning
Mar 08, 2017
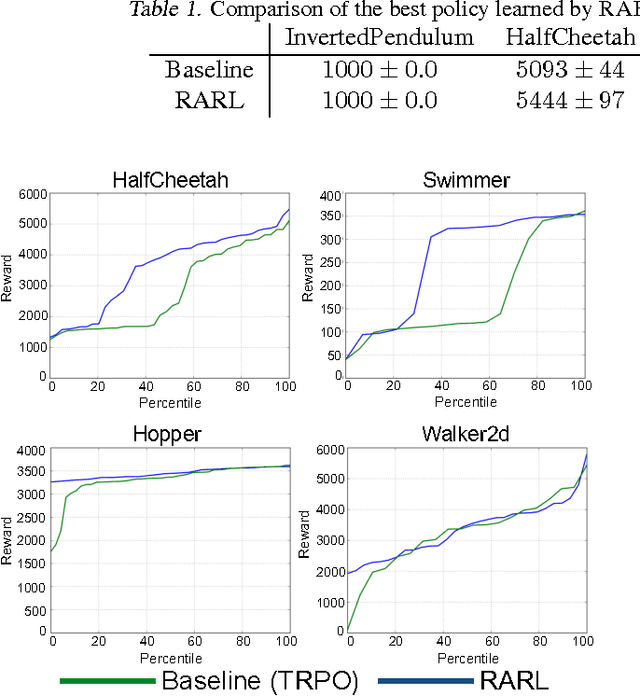
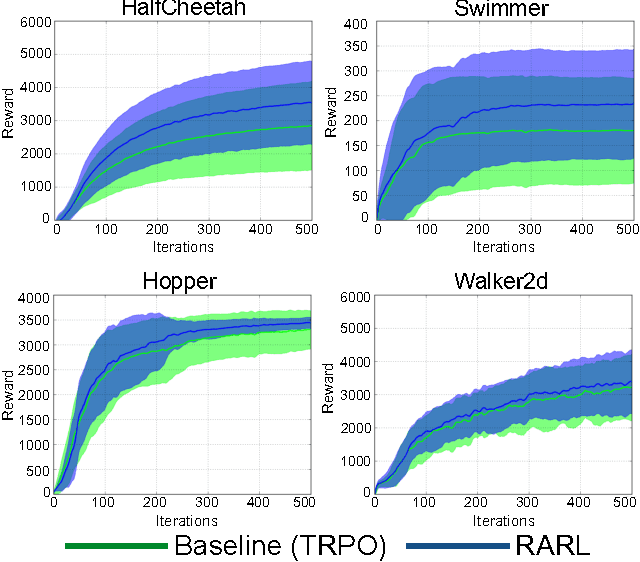
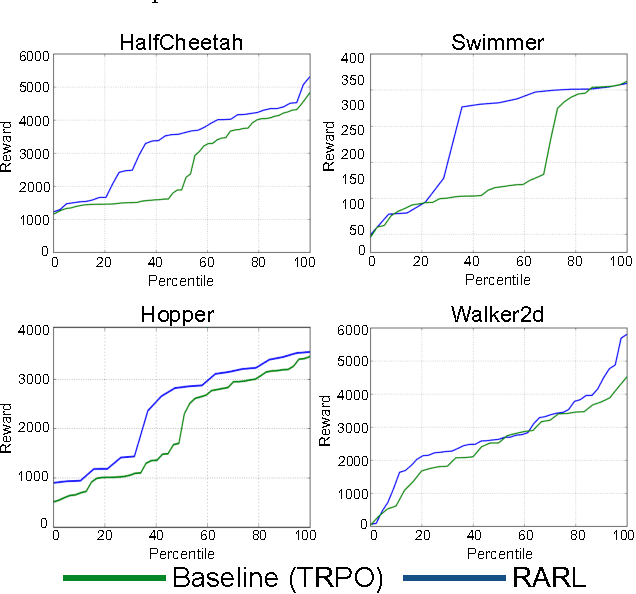
Deep neural networks coupled with fast simulation and improved computation have led to recent successes in the field of reinforcement learning (RL). However, most current RL-based approaches fail to generalize since: (a) the gap between simulation and real world is so large that policy-learning approaches fail to transfer; (b) even if policy learning is done in real world, the data scarcity leads to failed generalization from training to test scenarios (e.g., due to different friction or object masses). Inspired from H-infinity control methods, we note that both modeling errors and differences in training and test scenarios can be viewed as extra forces/disturbances in the system. This paper proposes the idea of robust adversarial reinforcement learning (RARL), where we train an agent to operate in the presence of a destabilizing adversary that applies disturbance forces to the system. The jointly trained adversary is reinforced -- that is, it learns an optimal destabilization policy. We formulate the policy learning as a zero-sum, minimax objective function. Extensive experiments in multiple environments (InvertedPendulum, HalfCheetah, Swimmer, Hopper and Walker2d) conclusively demonstrate that our method (a) improves training stability; (b) is robust to differences in training/test conditions; and c) outperform the baseline even in the absence of the adversary.
Traffic Lights with Auction-Based Controllers: Algorithms and Real-World Data
Feb 03, 2017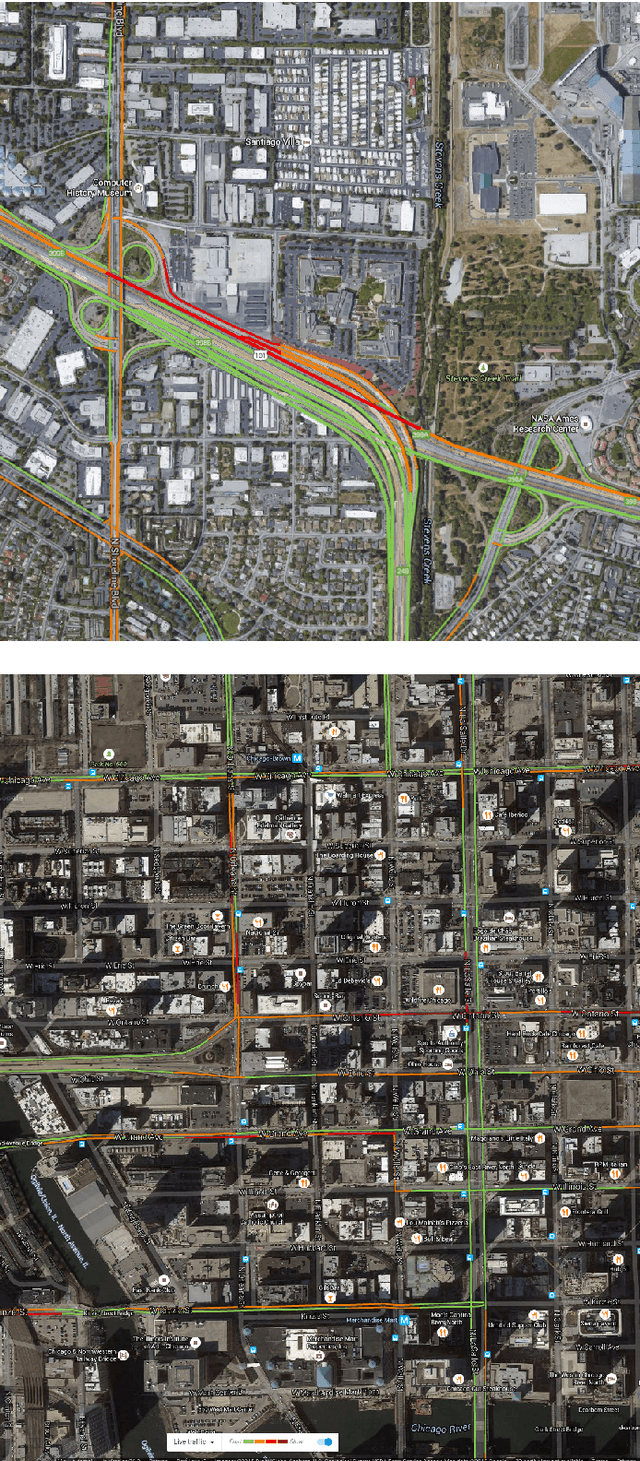

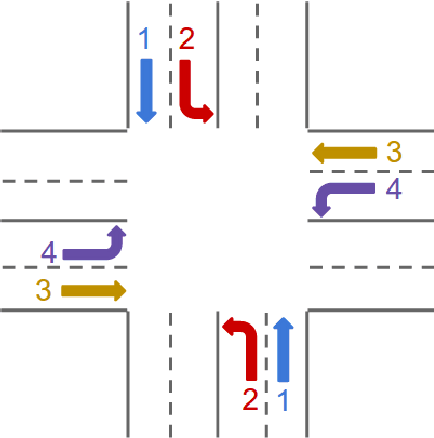

Real-time optimization of traffic flow addresses important practical problems: reducing a driver's wasted time, improving city-wide efficiency, reducing gas emissions and improving air quality. Much of the current research in traffic-light optimization relies on extending the capabilities of traffic lights to either communicate with each other or communicate with vehicles. However, before such capabilities become ubiquitous, opportunities exist to improve traffic lights by being more responsive to current traffic situations within the current, already deployed, infrastructure. In this paper, we introduce a traffic light controller that employs bidding within micro-auctions to efficiently incorporate traffic sensor information; no other outside sources of information are assumed. We train and test traffic light controllers on large-scale data collected from opted-in Android cell-phone users over a period of several months in Mountain View, California and the River North neighborhood of Chicago, Illinois. The learned auction-based controllers surpass (in both the relevant metrics of road-capacity and mean travel time) the currently deployed lights, optimized static-program lights, and longer-term planning approaches, in both cities, measured using real user driving data.
Recovering Spatiotemporal Correspondence between Deformable Objects by Exploiting Consistent Foreground Motion in Video
Aug 16, 2016

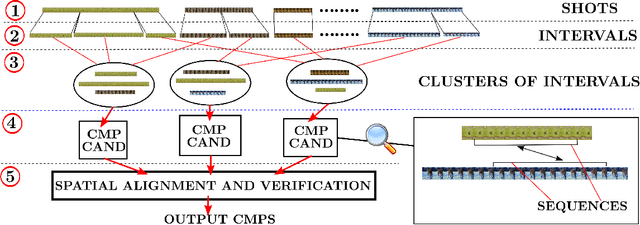
Given unstructured videos of deformable objects, we automatically recover spatiotemporal correspondences to map one object to another (such as animals in the wild). While traditional methods based on appearance fail in such challenging conditions, we exploit consistency in object motion between instances. Our approach discovers pairs of short video intervals where the object moves in a consistent manner and uses these candidates as seeds for spatial alignment. We model the spatial correspondence between the point trajectories on the object in one interval to those in the other using a time-varying Thin Plate Spline deformation model. On a large dataset of tiger and horse videos, our method automatically aligns thousands of pairs of frames to a high accuracy, and outperforms the popular SIFT Flow algorithm.
Behavior Discovery and Alignment of Articulated Object Classes from Unstructured Video
Aug 11, 2016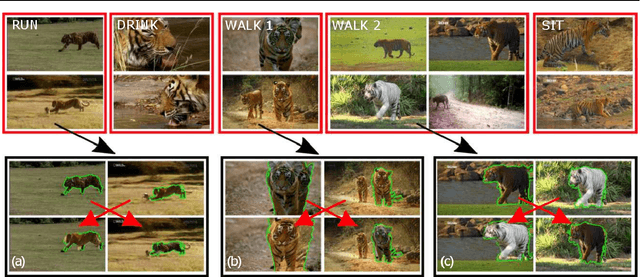
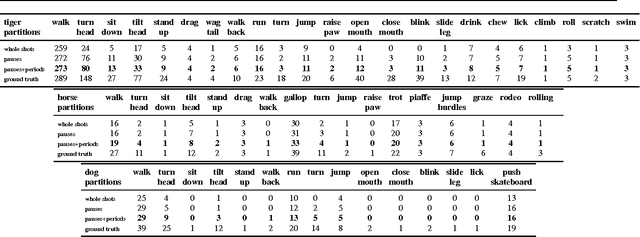
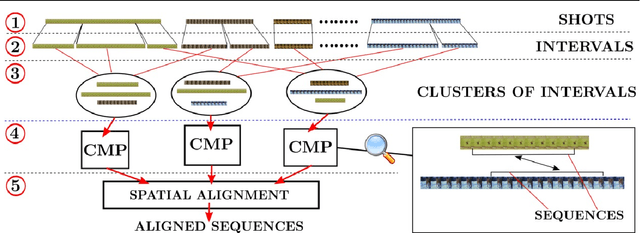
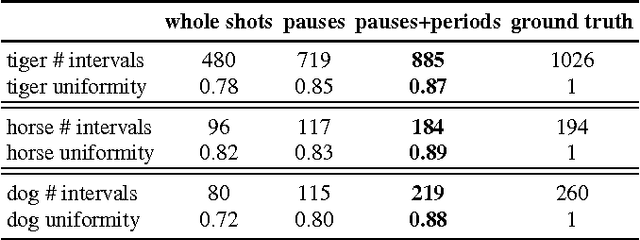
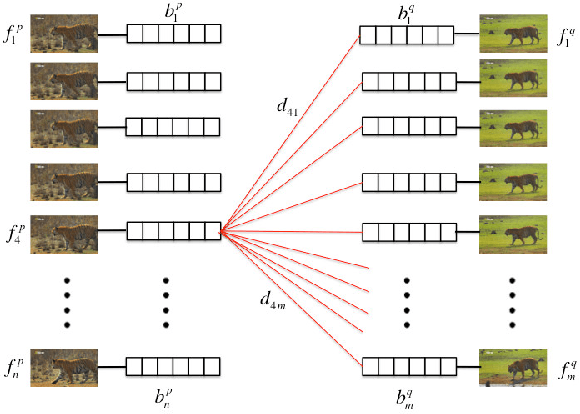
We propose an automatic system for organizing the content of a collection of unstructured videos of an articulated object class (e.g. tiger, horse). By exploiting the recurring motion patterns of the class across videos, our system: 1) identifies its characteristic behaviors; and 2) recovers pixel-to-pixel alignments across different instances. Our system can be useful for organizing video collections for indexing and retrieval. Moreover, it can be a platform for learning the appearance or behaviors of object classes from Internet video. Traditional supervised techniques cannot exploit this wealth of data directly, as they require a large amount of time-consuming manual annotations. The behavior discovery stage generates temporal video intervals, each automatically trimmed to one instance of the discovered behavior, clustered by type. It relies on our novel motion representation for articulated motion based on the displacement of ordered pairs of trajectories (PoTs). The alignment stage aligns hundreds of instances of the class to a great accuracy despite considerable appearance variations (e.g. an adult tiger and a cub). It uses a flexible Thin Plate Spline deformation model that can vary through time. We carefully evaluate each step of our system on a new, fully annotated dataset. On behavior discovery, we outperform the state-of-the-art Improved DTF descriptor. On spatial alignment, we outperform the popular SIFT Flow algorithm.
* 19 pages, 19 figure, 3 tables. arXiv admin note: substantial text overlap with arXiv:1411.7883