 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards flexible perception with visual memory
Aug 15, 2024



Training a neural network is a monolithic endeavor, akin to carving knowledge into stone: once the process is completed, editing the knowledge in a network is nearly impossible, since all information is distributed across the network's weights. We here explore a simple, compelling alternative by marrying the representational power of deep neural networks with the flexibility of a database. Decomposing the task of image classification into image similarity (from a pre-trained embedding) and search (via fast nearest neighbor retrieval from a knowledge database), we build a simple and flexible visual memory that has the following key capabilities: (1.) The ability to flexibly add data across scales: from individual samples all the way to entire classes and billion-scale data; (2.) The ability to remove data through unlearning and memory pruning; (3.) An interpretable decision-mechanism on which we can intervene to control its behavior. Taken together, these capabilities comprehensively demonstrate the benefits of an explicit visual memory. We hope that it might contribute to a conversation on how knowledge should be represented in deep vision models -- beyond carving it in ``stone'' weights.
High-Fidelity Image Compression with Score-based Generative Models
May 26, 2023



Despite the tremendous success of diffusion generative models in text-to-image generation, replicating this success in the domain of image compression has proven difficult. In this paper, we demonstrate that diffusion can significantly improve perceptual quality at a given bit-rate, outperforming state-of-the-art approaches PO-ELIC and HiFiC as measured by FID score. This is achieved using a simple but theoretically motivated two-stage approach combining an autoencoder targeting MSE followed by a further score-based decoder. However, as we will show, implementation details matter and the optimal design decisions can differ greatly from typical text-to-image models.
Multi-Realism Image Compression with a Conditional Generator
Dec 28, 2022



By optimizing the rate-distortion-realism trade-off, generative compression approaches produce detailed, realistic images, even at low bit rates, instead of the blurry reconstructions produced by rate-distortion optimized models. However, previous methods do not explicitly control how much detail is synthesized, which results in a common criticism of these methods: users might be worried that a misleading reconstruction far from the input image is generated. In this work, we alleviate these concerns by training a decoder that can bridge the two regimes and navigate the distortion-realism trade-off. From a single compressed representation, the receiver can decide to either reconstruct a low mean squared error reconstruction that is close to the input, a realistic reconstruction with high perceptual quality, or anything in between. With our method, we set a new state-of-the-art in distortion-realism, pushing the frontier of achievable distortion-realism pairs, i.e., our method achieves better distortions at high realism and better realism at low distortion than ever before.
VCT: A Video Compression Transformer
Jun 15, 2022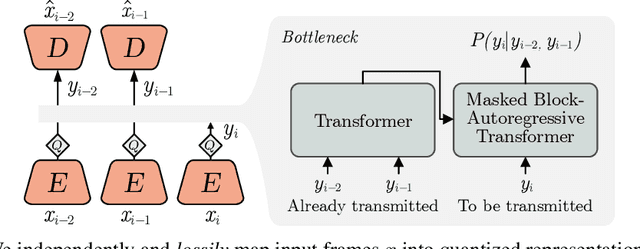

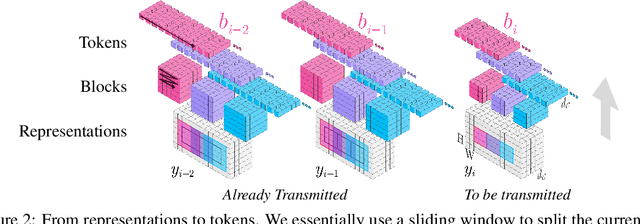
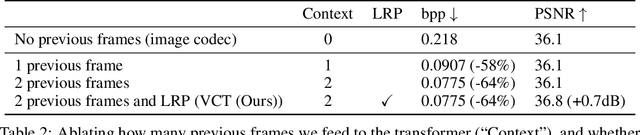
We show how transformers can be used to vastly simplify neural video compression. Previous methods have been relying on an increasing number of architectural biases and priors, including motion prediction and warping operations, resulting in complex models. Instead, we independently map input frames to representations and use a transformer to model their dependencies, letting it predict the distribution of future representations given the past. The resulting video compression transformer outperforms previous methods on standard video compression data sets. Experiments on synthetic data show that our model learns to handle complex motion patterns such as panning, blurring and fading purely from data. Our approach is easy to implement, and we release code to facilitate future research.
LVAC: Learned Volumetric Attribute Compression for Point Clouds using Coordinate Based Networks
Nov 17, 2021
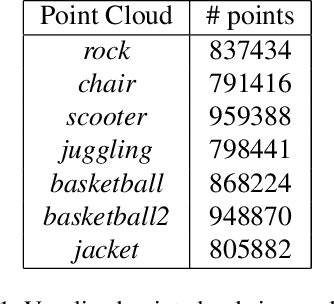
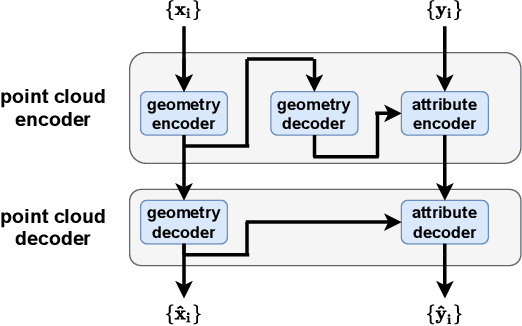
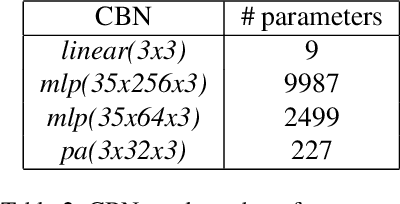
We consider the attributes of a point cloud as samples of a vector-valued volumetric function at discrete positions. To compress the attributes given the positions, we compress the parameters of the volumetric function. We model the volumetric function by tiling space into blocks, and representing the function over each block by shifts of a coordinate-based, or implicit, neural network. Inputs to the network include both spatial coordinates and a latent vector per block. We represent the latent vectors using coefficients of the region-adaptive hierarchical transform (RAHT) used in the MPEG geometry-based point cloud codec G-PCC. The coefficients, which are highly compressible, are rate-distortion optimized by back-propagation through a rate-distortion Lagrangian loss in an auto-decoder configuration. The result outperforms RAHT by 2--4 dB. This is the first work to compress volumetric functions represented by local coordinate-based neural networks. As such, we expect it to be applicable beyond point clouds, for example to compression of high-resolution neural radiance fields.
Towards Generative Video Compression
Jul 26, 2021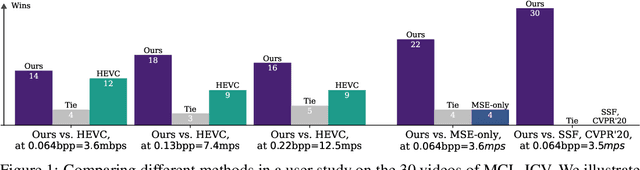
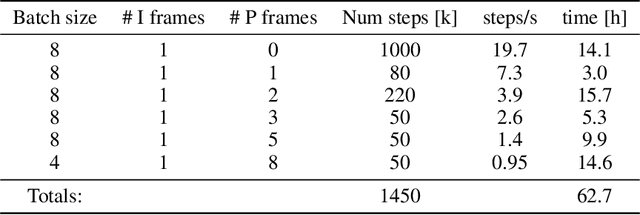
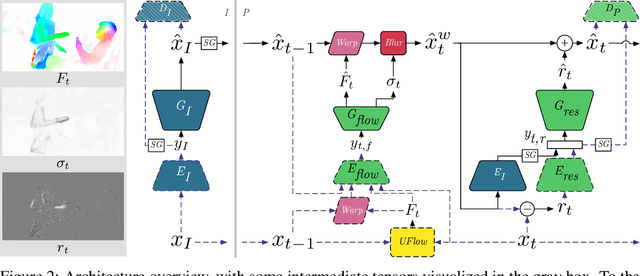
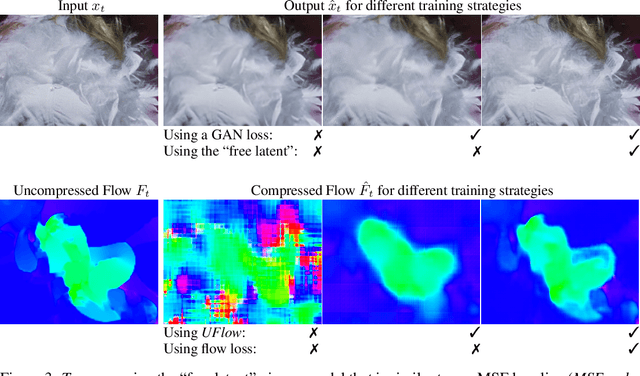
We present a neural video compression method based on generative adversarial networks (GANs) that outperforms previous neural video compression methods and is comparable to HEVC in a user study. We propose a technique to mitigate temporal error accumulation caused by recursive frame compression that uses randomized shifting and un-shifting, motivated by a spectral analysis. We present in detail the network design choices, their relative importance, and elaborate on the challenges of evaluating video compression methods in user studies.
End-to-end Learning of Compressible Features
Jul 23, 2020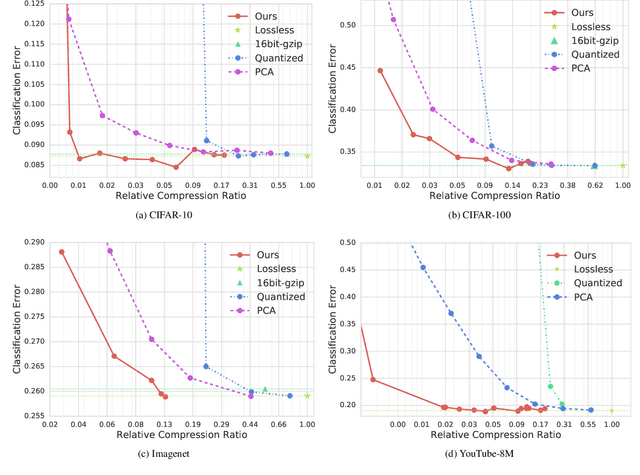
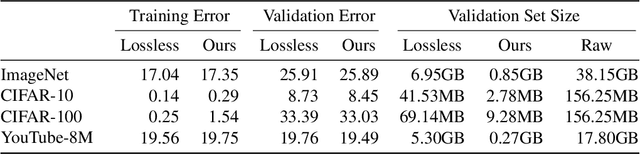
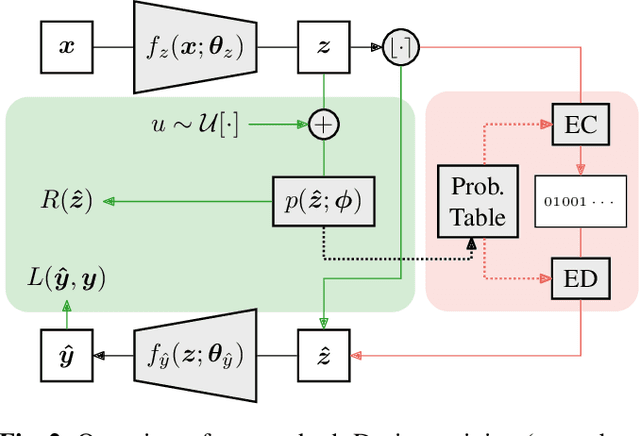
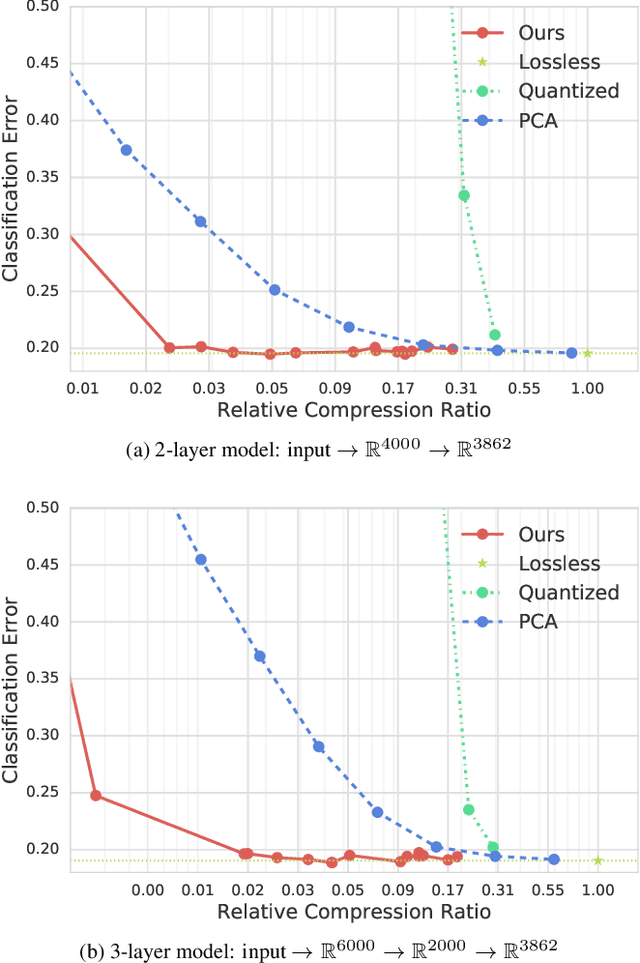
Pre-trained convolutional neural networks (CNNs) are powerful off-the-shelf feature generators and have been shown to perform very well on a variety of tasks. Unfortunately, the generated features are high dimensional and expensive to store: potentially hundreds of thousands of floats per example when processing videos. Traditional entropy based lossless compression methods are of little help as they do not yield desired level of compression, while general purpose lossy compression methods based on energy compaction (e.g. PCA followed by quantization and entropy coding) are sub-optimal, as they are not tuned to task specific objective. We propose a learned method that jointly optimizes for compressibility along with the task objective for learning the features. The plug-in nature of our method makes it straight-forward to integrate with any target objective and trade-off against compressibility. We present results on multiple benchmarks and demonstrate that our method produces features that are an order of magnitude more compressible, while having a regularization effect that leads to a consistent improvement in accuracy.
High-Fidelity Generative Image Compression
Jul 10, 2020


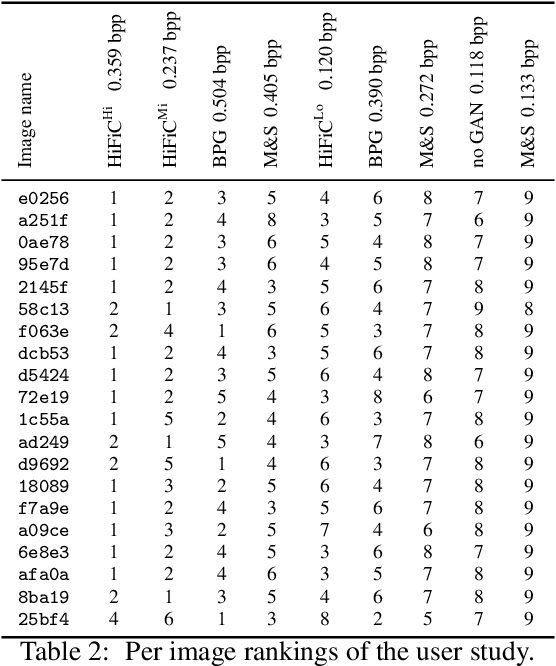
We extensively study how to combine Generative Adversarial Networks and learned compression to obtain a state-of-the-art generative lossy compression system. In particular, we investigate normalization layers, generator and discriminator architectures, training strategies, as well as perceptual losses. In contrast to previous work, i) we obtain visually pleasing reconstructions that are perceptually similar to the input, ii) we operate in a broad range of bitrates, and iii) our approach can be applied to high-resolution images. We bridge the gap between rate-distortion-perception theory and practice by evaluating our approach both quantitatively with various perceptual metrics and a user study. The study shows that our method is preferred to previous approaches even if they use more than 2x the bitrate.
Joint Autoregressive and Hierarchical Priors for Learned Image Compression
Sep 08, 2018

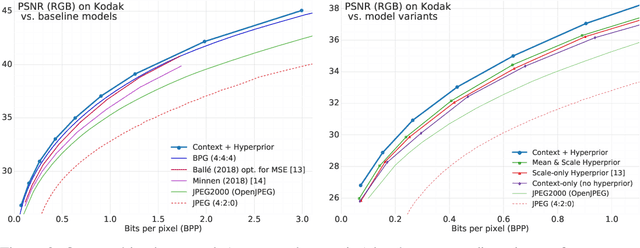
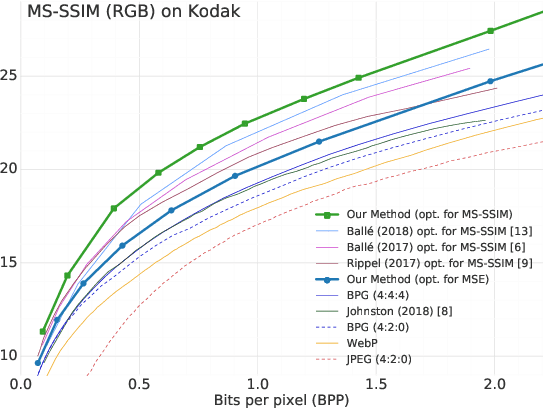
Recent models for learned image compression are based on autoencoders, learning approximately invertible mappings from pixels to a quantized latent representation. These are combined with an entropy model, a prior on the latent representation that can be used with standard arithmetic coding algorithms to yield a compressed bitstream. Recently, hierarchical entropy models have been introduced as a way to exploit more structure in the latents than simple fully factorized priors, improving compression performance while maintaining end-to-end optimization. Inspired by the success of autoregressive priors in probabilistic generative models, we examine autoregressive, hierarchical, as well as combined priors as alternatives, weighing their costs and benefits in the context of image compression. While it is well known that autoregressive models come with a significant computational penalty, we find that in terms of compression performance, autoregressive and hierarchical priors are complementary and, together, exploit the probabilistic structure in the latents better than all previous learned models. The combined model yields state-of-the-art rate--distortion performance, providing a 15.8% average reduction in file size over the previous state-of-the-art method based on deep learning, which corresponds to a 59.8% size reduction over JPEG, more than 35% reduction compared to WebP and JPEG2000, and bitstreams 8.4% smaller than BPG, the current state-of-the-art image codec. To the best of our knowledge, our model is the first learning-based method to outperform BPG on both PSNR and MS-SSIM distortion metrics.
Towards a Semantic Perceptual Image Metric
Aug 01, 2018
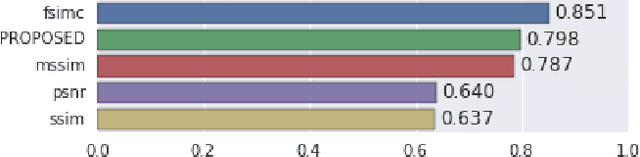
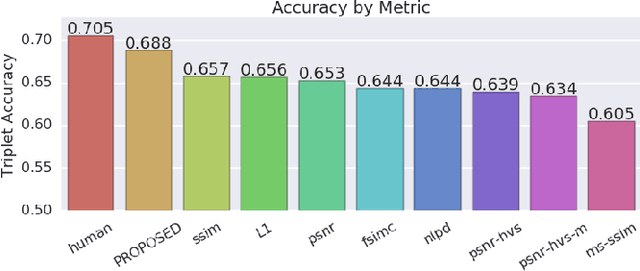

We present a full reference, perceptual image metric based on VGG-16, an artificial neural network trained on object classification. We fit the metric to a new database based on 140k unique images annotated with ground truth by human raters who received minimal instruction. The resulting metric shows competitive performance on TID 2013, a database widely used to assess image quality assessments methods. More interestingly, it shows strong responses to objects potentially carrying semantic relevance such as faces and text, which we demonstrate using a visualization technique and ablation experiments. In effect, the metric appears to model a higher influence of semantic context on judgments, which we observe particularly in untrained raters. As the vast majority of users of image processing systems are unfamiliar with Image Quality Assessment (IQA) tasks, these findings may have significant impact on real-world applications of perceptual metrics.