 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Unsupervised Machine Translation To Adversarial Text Generation
Nov 10, 2020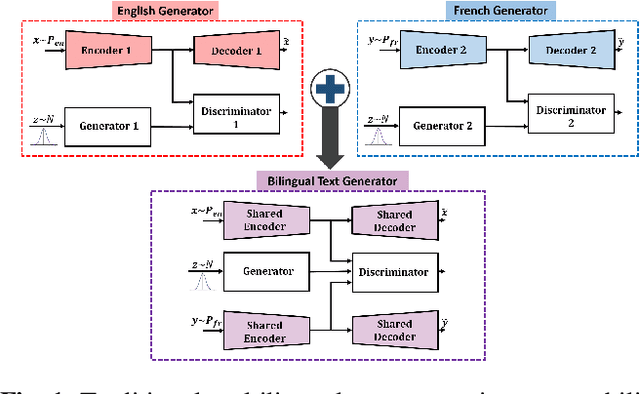
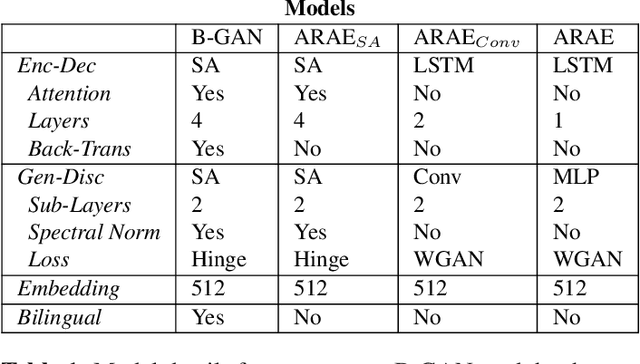
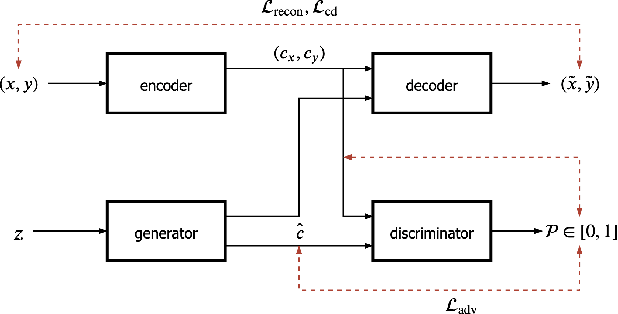
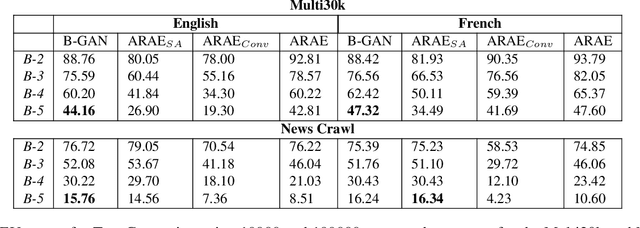
We present a self-attention based bilingual adversarial text generator (B-GAN) which can learn to generate text from the encoder representation of an unsupervised neural machine translation system. B-GAN is able to generate a distributed latent space representation which can be paired with an attention based decoder to generate fluent sentences. When trained on an encoder shared between two languages and paired with the appropriate decoder, it can generate sentences in either language. B-GAN is trained using a combination of reconstruction loss for auto-encoder, a cross domain loss for translation and a GAN based adversarial loss for text generation. We demonstrate that B-GAN, trained on monolingual corpora only using multiple losses, generates more fluent sentences compared to monolingual baselines while effectively using half the number of parameters.
Know What You Don't Need: Single-Shot Meta-Pruning for Attention Heads
Nov 07, 2020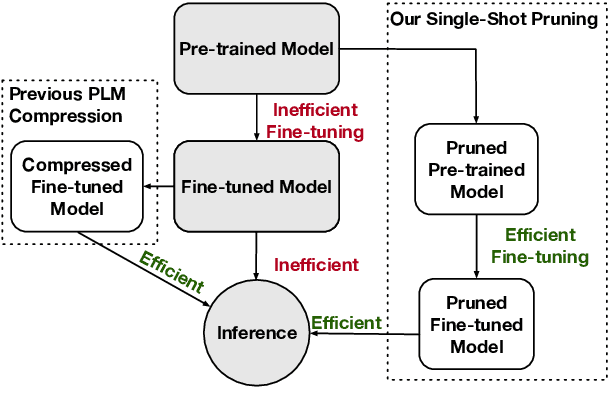

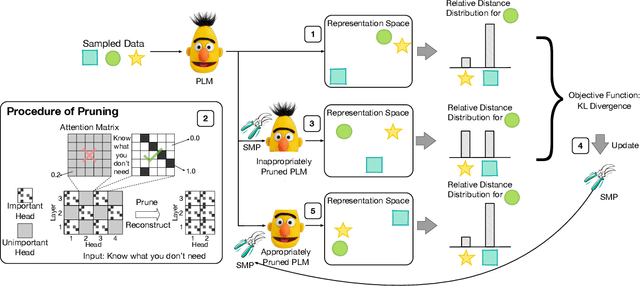
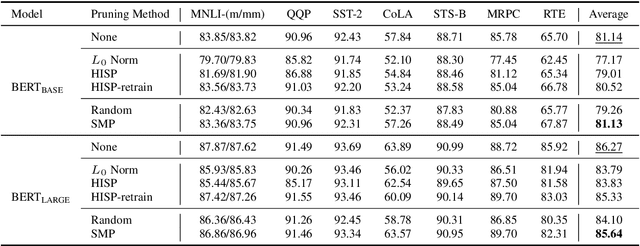
Deep pre-trained Transformer models have achieved state-of-the-art results over a variety of natural language processing (NLP) tasks. By learning rich language knowledge with millions of parameters, these models are usually overparameterized and significantly increase the computational overhead in applications. It is intuitive to address this issue by model compression. In this work, we propose a method, called Single-Shot Meta-Pruning, to compress deep pre-trained Transformers before fine-tuning. Specifically, we focus on pruning unnecessary attention heads adaptively for different downstream tasks. To measure the informativeness of attention heads, we train our Single-Shot Meta-Pruner (SMP) with a meta-learning paradigm aiming to maintain the distribution of text representations after pruning. Compared with existing compression methods for pre-trained models, our method can reduce the overhead of both fine-tuning and inference. Experimental results show that our pruner can selectively prune 50% of attention heads with little impact on the performance on downstream tasks and even provide better text representations. The source code will be released in the future.
HyperText: Endowing FastText with Hyperbolic Geometry
Oct 30, 2020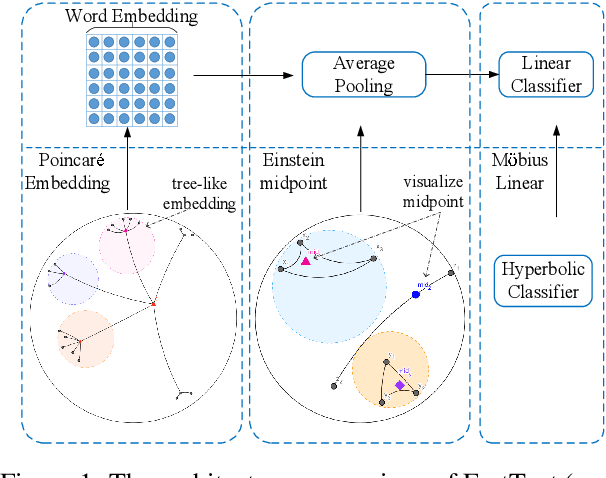

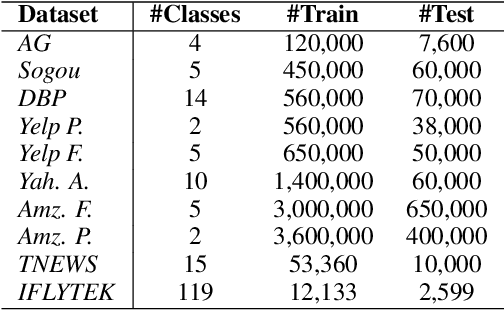
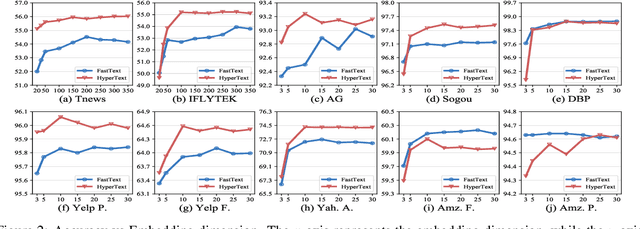
Natural language data exhibit tree-like hierarchical structures such as the hypernym-hyponym relations in WordNet. FastText, as the state-of-the-art text classifier based on shallow neural network in Euclidean space, may not model such hierarchies precisely with limited representation capacity. Considering that hyperbolic space is naturally suitable for modeling tree-like hierarchical data, we propose a new model named HyperText for efficient text classification by endowing FastText with hyperbolic geometry. Empirically, we show that HyperText outperforms FastText on a range of text classification tasks with much reduced parameters.
LiDAM: Semi-Supervised Learning with Localized Domain Adaptation and Iterative Matching
Oct 13, 2020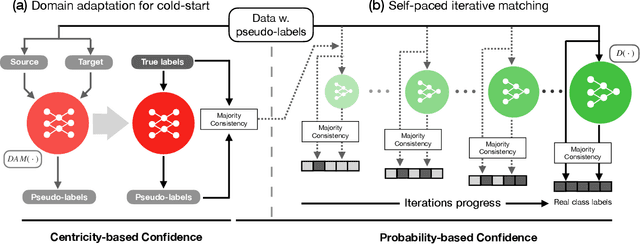

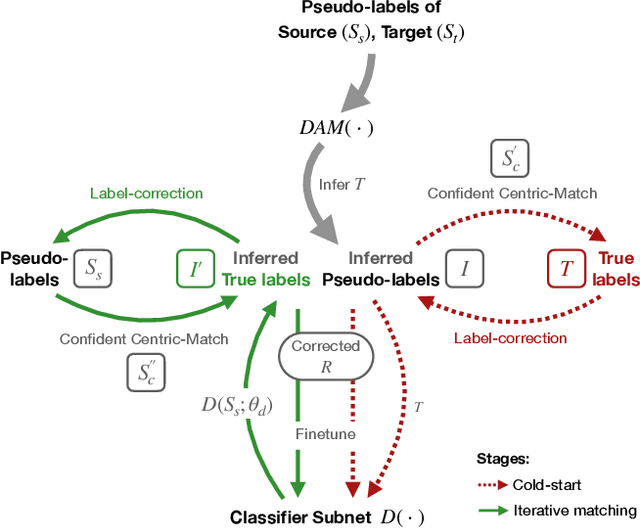
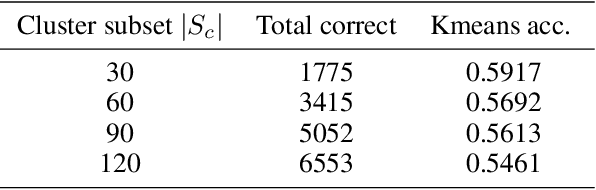
Although data is abundant, data labeling is expensive. Semi-supervised learning methods combine a few labeled samples with a large corpus of unlabeled data to effectively train models. This paper introduces our proposed method LiDAM, a semi-supervised learning approach rooted in both domain adaptation and self-paced learning. LiDAM first performs localized domain shifts to extract better domain-invariant features for the model that results in more accurate clusters and pseudo-labels. These pseudo-labels are then aligned with real class labels in a self-paced fashion using a novel iterative matching technique that is based on majority consistency over high-confidence predictions. Simultaneously, a final classifier is trained to predict ground-truth labels until convergence. LiDAM achieves state-of-the-art performance on the CIFAR-100 dataset, outperforming FixMatch (73.50% vs. 71.82%) when using 2500 labels.
TernaryBERT: Distillation-aware Ultra-low Bit BERT
Oct 10, 2020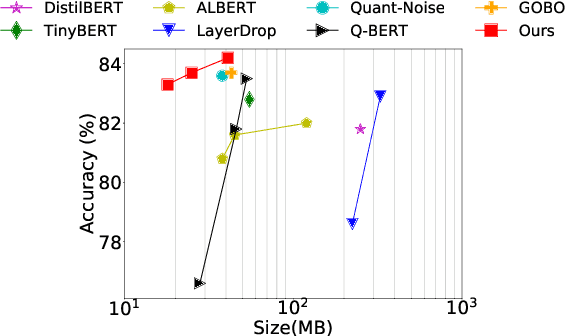
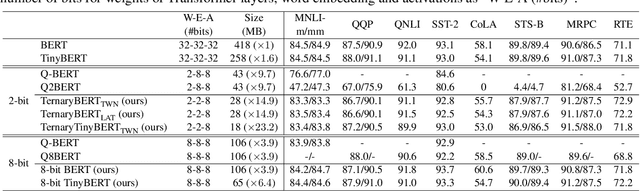
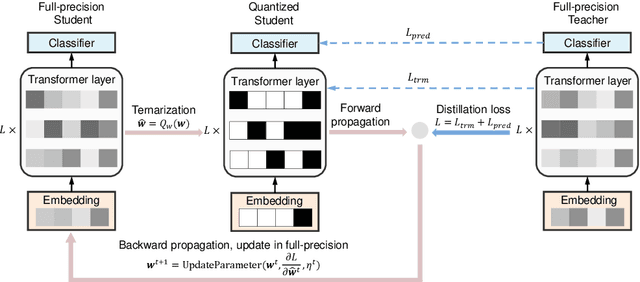
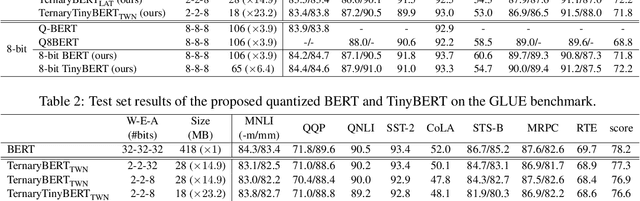
Transformer-based pre-training models like BERT have achieved remarkable performance in many natural language processing tasks.However, these models are both computation and memory expensive, hindering their deployment to resource-constrained devices. In this work, we propose TernaryBERT, which ternarizes the weights in a fine-tuned BERT model. Specifically, we use both approximation-based and loss-aware ternarization methods and empirically investigate the ternarization granularity of different parts of BERT. Moreover, to reduce the accuracy degradation caused by the lower capacity of low bits, we leverage the knowledge distillation technique in the training process. Experiments on the GLUE benchmark and SQuAD show that our proposed TernaryBERT outperforms the other BERT quantization methods, and even achieves comparable performance as the full-precision model while being 14.9x smaller.
Why Skip If You Can Combine: A Simple Knowledge Distillation Technique for Intermediate Layers
Oct 06, 2020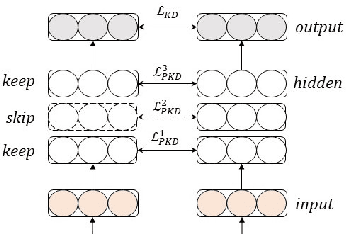
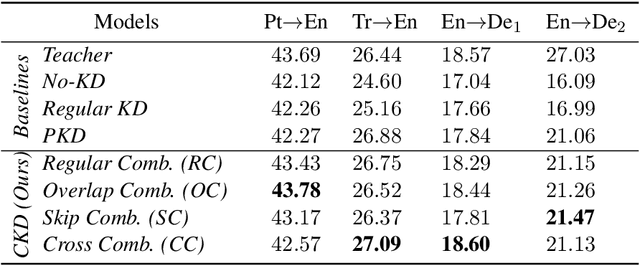
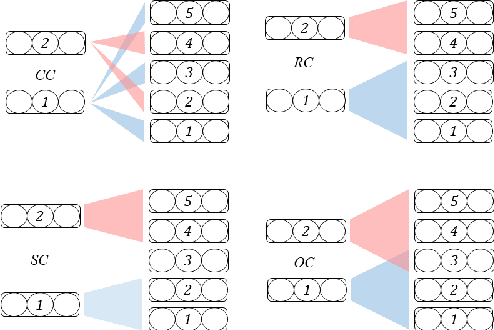
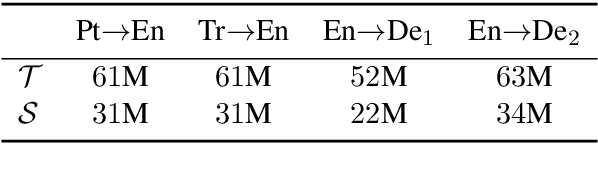
With the growth of computing power neural machine translation (NMT) models also grow accordingly and become better. However, they also become harder to deploy on edge devices due to memory constraints. To cope with this problem, a common practice is to distill knowledge from a large and accurately-trained teacher network (T) into a compact student network (S). Although knowledge distillation (KD) is useful in most cases, our study shows that existing KD techniques might not be suitable enough for deep NMT engines, so we propose a novel alternative. In our model, besides matching T and S predictions we have a combinatorial mechanism to inject layer-level supervision from T to S. In this paper, we target low-resource settings and evaluate our translation engines for Portuguese--English, Turkish--English, and English--German directions. Students trained using our technique have 50% fewer parameters and can still deliver comparable results to those of 12-layer teachers.
TensorCoder: Dimension-Wise Attention via Tensor Representation for Natural Language Modeling
Aug 12, 2020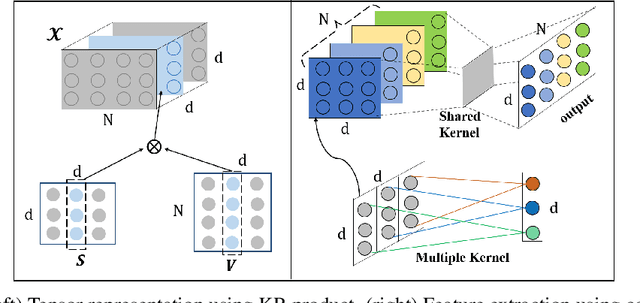
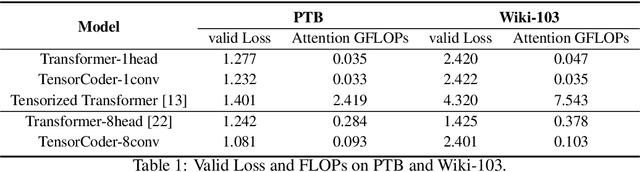
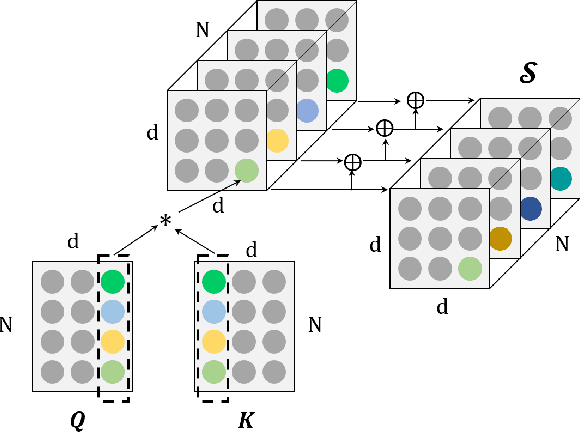
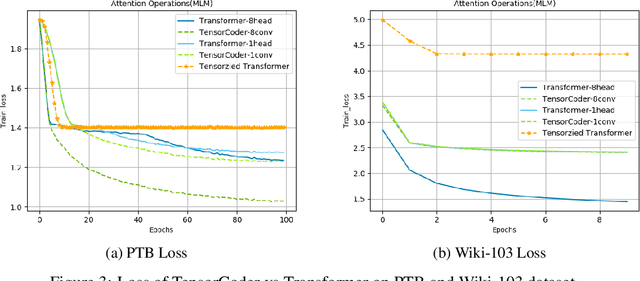
Transformer has been widely-used in many Natural Language Processing (NLP) tasks and the scaled dot-product attention between tokens is a core module of Transformer. This attention is a token-wise design and its complexity is quadratic to the length of sequence, limiting its application potential for long sequence tasks. In this paper, we propose a dimension-wise attention mechanism based on which a novel language modeling approach (namely TensorCoder) can be developed. The dimension-wise attention can reduce the attention complexity from the original $O(N^2d)$ to $O(Nd^2)$, where $N$ is the length of the sequence and $d$ is the dimensionality of head. We verify TensorCoder on two tasks including masked language modeling and neural machine translation. Compared with the original Transformer, TensorCoder not only greatly reduces the calculation of the original model but also obtains improved performance on masked language modeling task (in PTB dataset) and comparable performance on machine translation tasks.
Learning to Detect Unacceptable Machine Translations for Downstream Tasks
May 08, 2020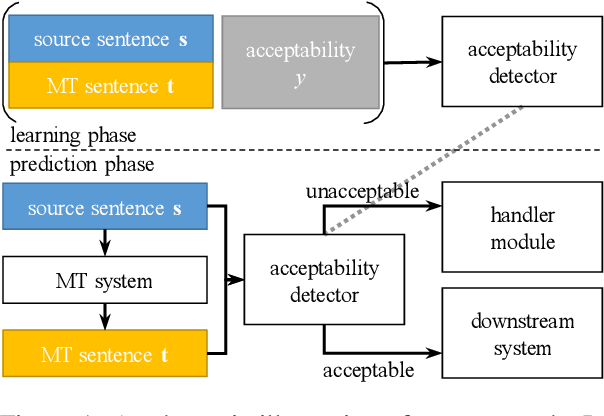
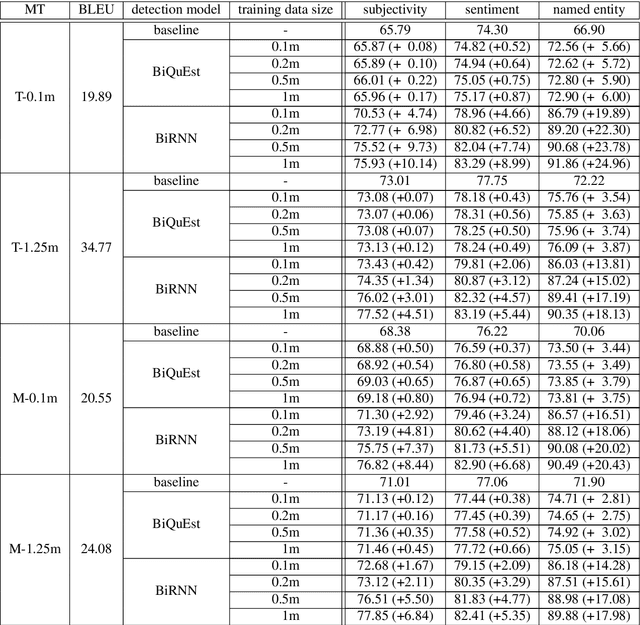

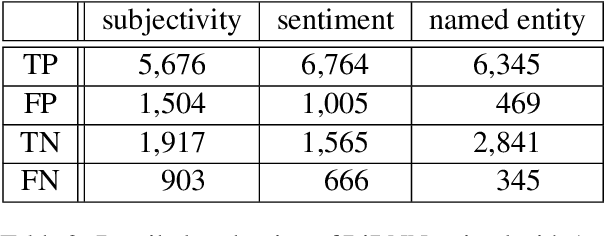
The field of machine translation has progressed tremendously in recent years. Even though the translation quality has improved significantly, current systems are still unable to produce uniformly acceptable machine translations for the variety of possible use cases. In this work, we put machine translation in a cross-lingual pipeline and introduce downstream tasks to define task-specific acceptability of machine translations. This allows us to leverage parallel data to automatically generate acceptability annotations on a large scale, which in turn help to learn acceptability detectors for the downstream tasks. We conduct experiments to demonstrate the effectiveness of our framework for a range of downstream tasks and translation models.
Accurate Word Alignment Induction from Neural Machine Translation
Apr 30, 2020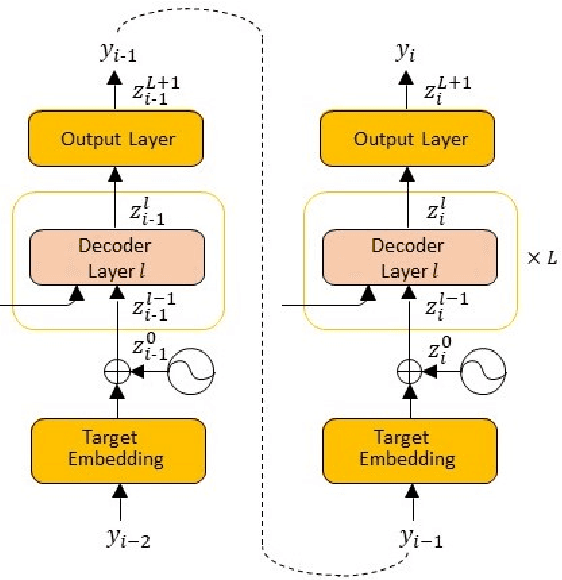
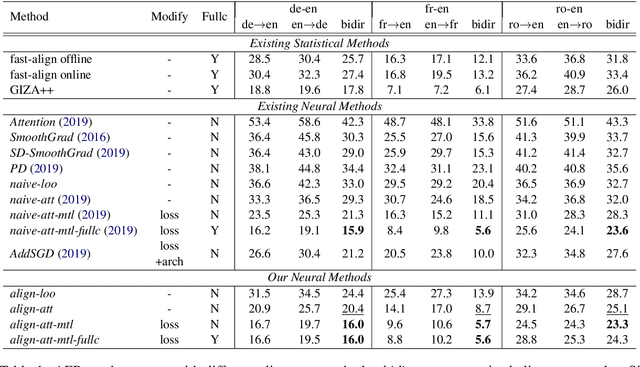
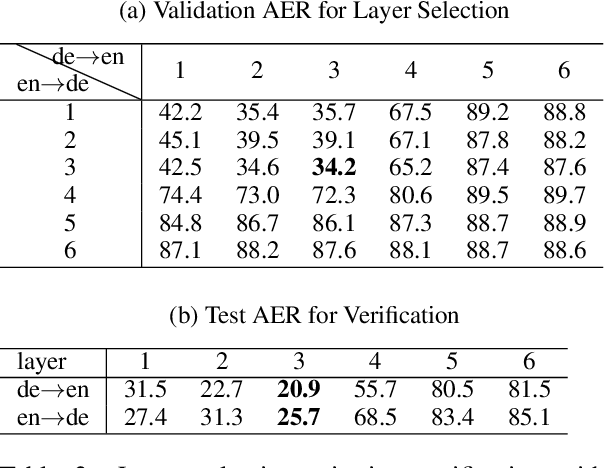
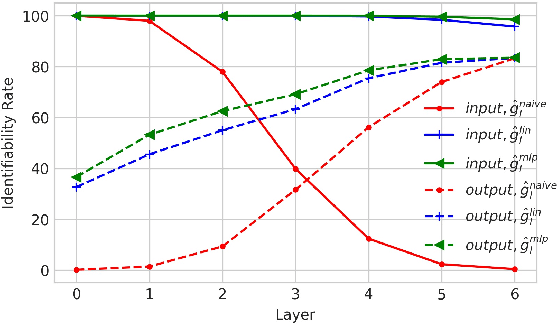
Despite its original goal to jointly learn to align and translate, prior researches suggest that the state-of-the-art neural machine translation model Transformer captures poor word alignment through its attention mechanism. In this paper, we show that attention weights do capture accurate word alignment, which could only be revealed if we choose the correct decoding step and layer to induce word alignment. We propose to induce alignment with the to-be-aligned target token as the decoder input and present two simple but effective interpretation methods for word alignment induction, either through the attention weights or the leave-one-out measures. In contrast to previous studies, we find that attention weights capture better word alignment than the leave-one-out measures under our setting. Using the proposed method with attention weights, we greatly improve over fast-align on word alignment induction. Finally, we present a multi-task learning framework to train the Transformer model and show that by incorporating GIZA++ alignments into our multi-task training, we can induce significantly better alignments than GIZA++.
Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT
Apr 30, 2020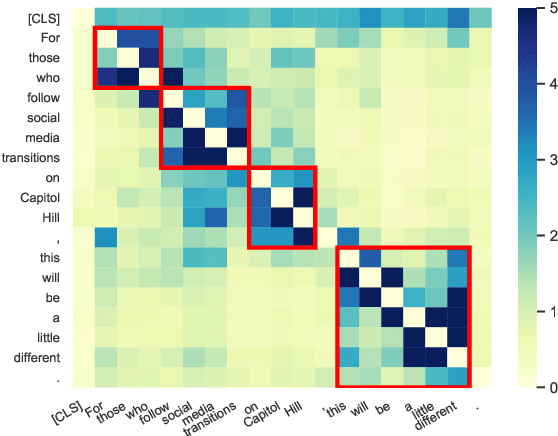
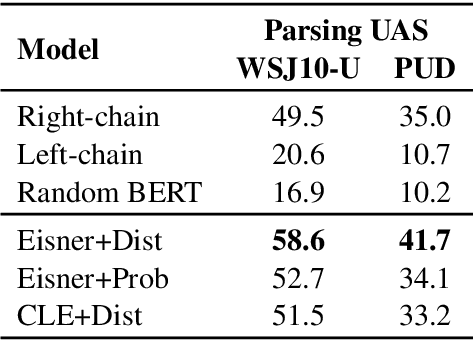
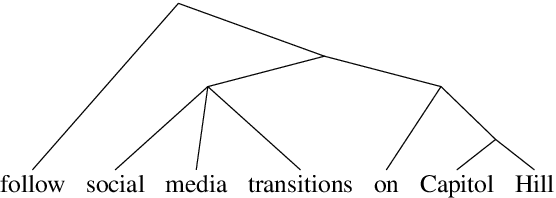
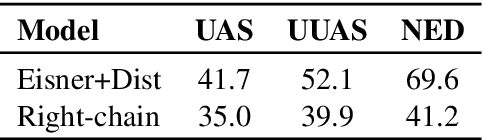
By introducing a small set of additional parameters, a probe learns to solve specific linguistic tasks (e.g., dependency parsing) in a supervised manner using feature representations (e.g., contextualized embeddings). The effectiveness of such probing tasks is taken as evidence that the pre-trained model encodes linguistic knowledge. However, this approach of evaluating a language model is undermined by the uncertainty of the amount of knowledge that is learned by the probe itself. Complementary to those works, we propose a parameter-free probing technique for analyzing pre-trained language models (e.g., BERT). Our method does not require direct supervision from the probing tasks, nor do we introduce additional parameters to the probing process. Our experiments on BERT show that syntactic trees recovered from BERT using our method are significantly better than linguistically-uninformed baselines. We further feed the empirically induced dependency structures into a downstream sentiment classification task and find its improvement compatible with or even superior to a human-designed dependency schema.