 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Design of Cyber-Physical Human Systems
Jan 07, 2020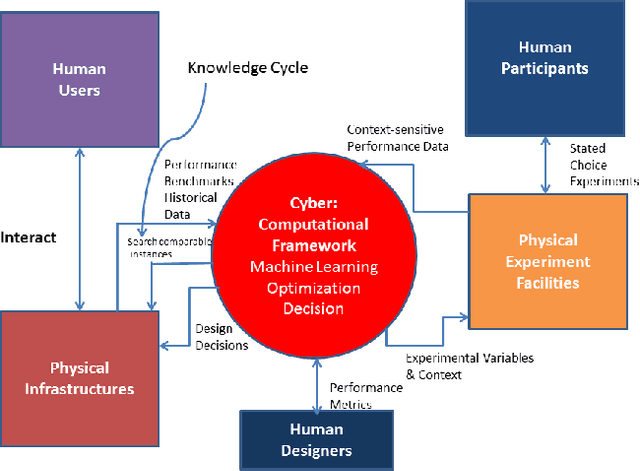
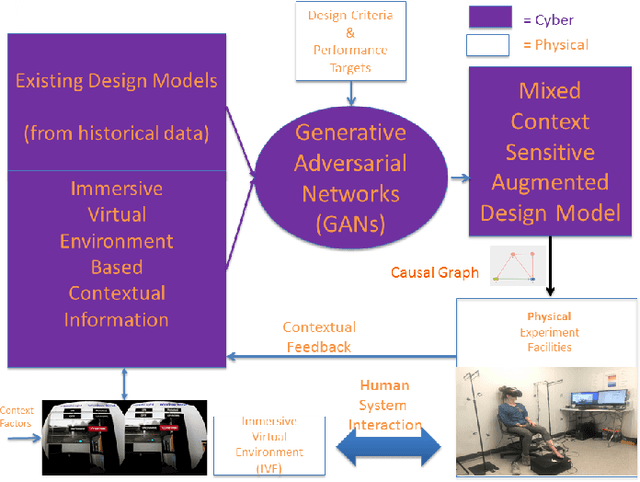
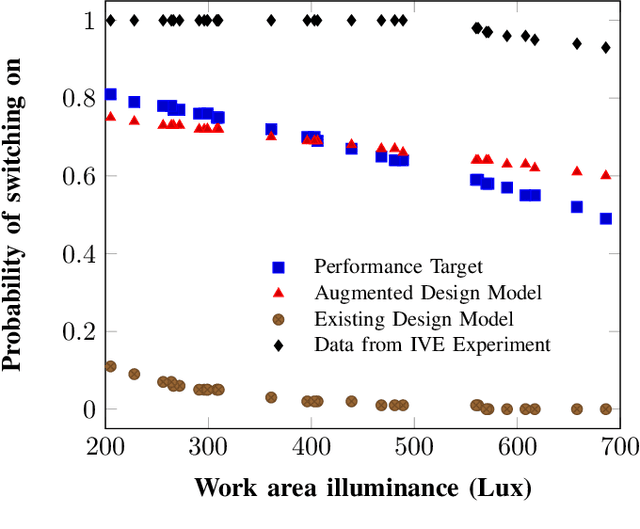
Recently, it has been widely accepted by the research community that interactions between humans and cyber-physical infrastructures have played a significant role in determining the performance of the latter. The existing paradigm for designing cyber-physical systems for optimal performance focuses on developing models based on historical data. The impacts of context factors driving human system interaction are challenging and are difficult to capture and replicate in existing design models. As a result, many existing models do not or only partially address those context factors of a new design owing to the lack of capabilities to capture the context factors. This limitation in many existing models often causes performance gaps between predicted and measured results. We envision a new design environment, a cyber-physical human system (CPHS) where decision-making processes for physical infrastructures under design are intelligently connected to distributed resources over cyberinfrastructure such as experiments on design features and empirical evidence from operations of existing instances. The framework combines existing design models with context-aware design-specific data involving human-infrastructure interactions in new designs, using a machine learning approach to create augmented design models with improved predictive powers.
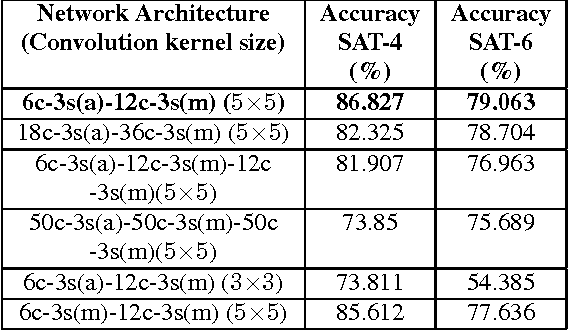
DeepSat V2: Feature Augmented Convolutional Neural Nets for Satellite Image Classification
Nov 15, 2019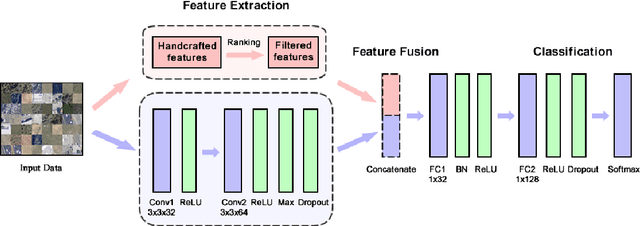
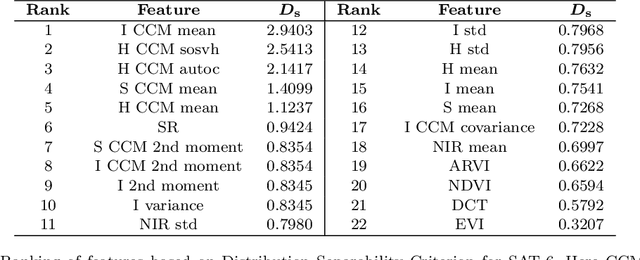
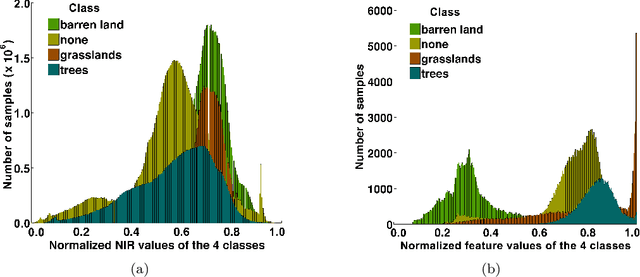
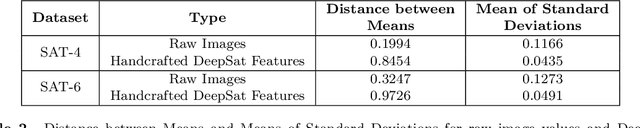
Satellite image classification is a challenging problem that lies at the crossroads of remote sensing, computer vision, and machine learning. Due to the high variability inherent in satellite data, most of the current object classification approaches are not suitable for handling satellite datasets. The progress of satellite image analytics has also been inhibited by the lack of a single labeled high-resolution dataset with multiple class labels. In a preliminary version of this work, we introduced two new high resolution satellite imagery datasets (SAT-4 and SAT-6) and proposed DeepSat framework for classification based on "handcrafted" features and a deep belief network (DBN). The present paper is an extended version, we present an end-to-end framework leveraging an improved architecture that augments a convolutional neural network (CNN) with handcrafted features (instead of using DBN-based architecture) for classification. Our framework, having access to fused spatial information obtained from handcrafted features as well as CNN feature maps, have achieved accuracies of 99.90% and 99.84% respectively, on SAT-4 and SAT-6, surpassing all the other state-of-the-art results. A statistical analysis based on Distribution Separability Criterion substantiates the robustness of our approach in learning better representations for satellite imagery.
Pixel-level Reconstruction and Classification for Noisy Handwritten Bangla Characters
Jun 21, 2018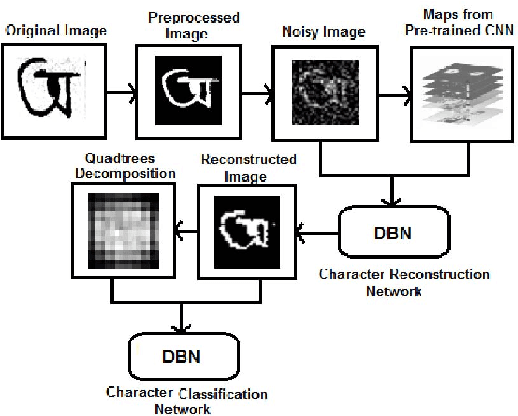
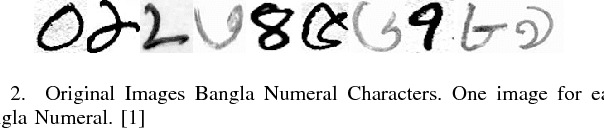


Classification techniques for images of handwritten characters are susceptible to noise. Quadtrees can be an efficient representation for learning from sparse features. In this paper, we improve the effectiveness of probabilistic quadtrees by using a pixel level classifier to extract the character pixels and remove noise from handwritten character images. The pixel level denoiser (a deep belief network) uses the map responses obtained from a pretrained CNN as features for reconstructing the characters eliminating noise. We experimentally demonstrate the effectiveness of our approach by reconstructing and classifying a noisy version of handwritten Bangla Numeral and Basic Character datasets.
CactusNets: Layer Applicability as a Metric for Transfer Learning
Apr 20, 2018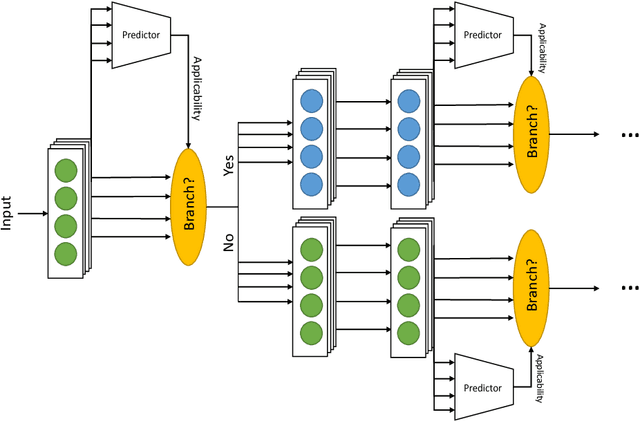
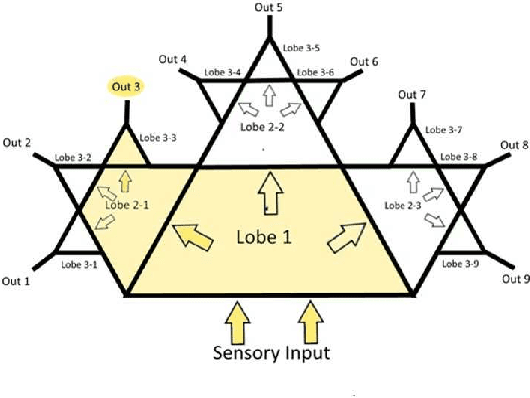
Deep neural networks trained over large datasets learn features that are both generic to the whole dataset, and specific to individual classes in the dataset. Learned features tend towards generic in the lower layers and specific in the higher layers of a network. Methods like fine-tuning are made possible because of the ability for one filter to apply to multiple target classes. Much like the human brain this behavior, can also be used to cluster and separate classes. However, to the best of our knowledge there is no metric for how applicable learned features are to specific classes. In this paper we propose a definition and metric for measuring the applicability of learned features to individual classes, and use this applicability metric to estimate input applicability and produce a new method of unsupervised learning we call the CactusNet.
Core Sampling Framework for Pixel Classification
Dec 06, 2016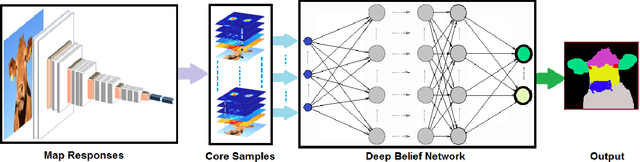

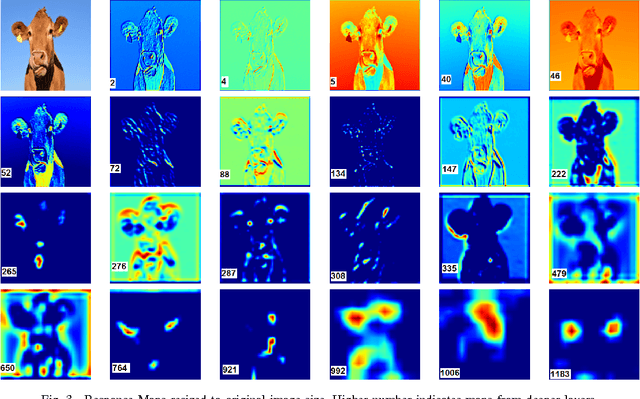
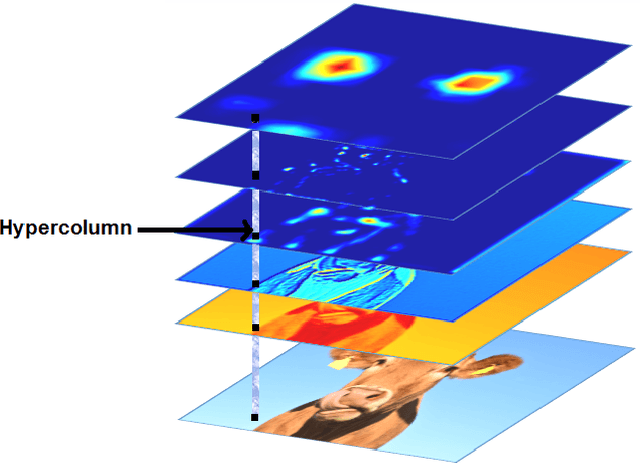
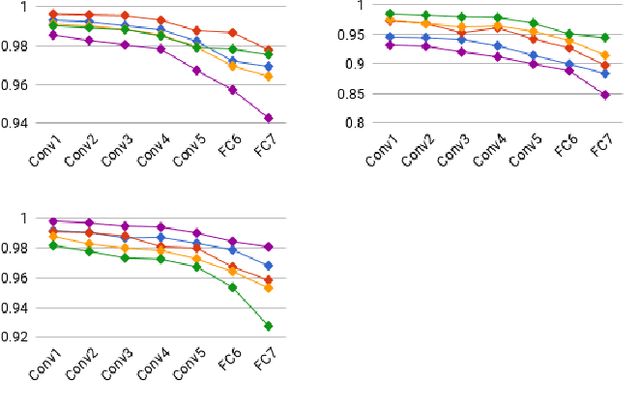
The intermediate map responses of a Convolutional Neural Network (CNN) contain information about an image that can be used to extract contextual knowledge about it. In this paper, we present a core sampling framework that is able to use these activation maps from several layers as features to another neural network using transfer learning to provide an understanding of an input image. Our framework creates a representation that combines features from the test data and the contextual knowledge gained from the responses of a pretrained network, processes it and feeds it to a separate Deep Belief Network. We use this representation to extract more information from an image at the pixel level, hence gaining understanding of the whole image. We experimentally demonstrate the usefulness of our framework using a pretrained VGG-16 model to perform segmentation on the BAERI dataset of Synthetic Aperture Radar(SAR) imagery and the CAMVID dataset.
A Theoretical Analysis of Deep Neural Networks for Texture Classification
Jun 21, 2016
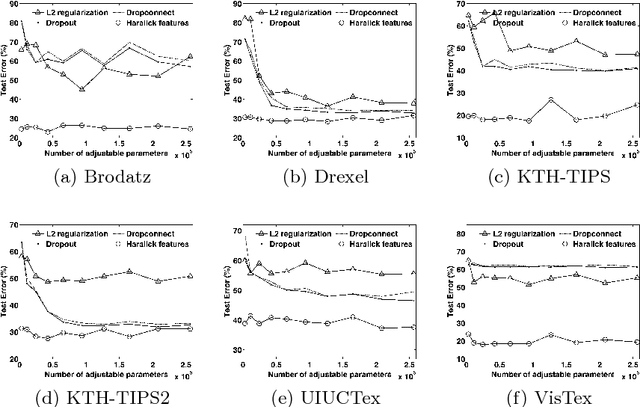
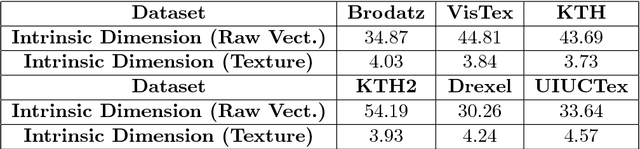
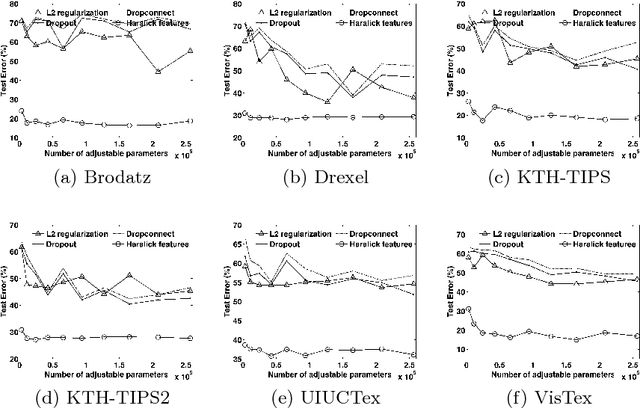
We investigate the use of Deep Neural Networks for the classification of image datasets where texture features are important for generating class-conditional discriminative representations. To this end, we first derive the size of the feature space for some standard textural features extracted from the input dataset and then use the theory of Vapnik-Chervonenkis dimension to show that hand-crafted feature extraction creates low-dimensional representations which help in reducing the overall excess error rate. As a corollary to this analysis, we derive for the first time upper bounds on the VC dimension of Convolutional Neural Network as well as Dropout and Dropconnect networks and the relation between excess error rate of Dropout and Dropconnect networks. The concept of intrinsic dimension is used to validate the intuition that texture-based datasets are inherently higher dimensional as compared to handwritten digits or other object recognition datasets and hence more difficult to be shattered by neural networks. We then derive the mean distance from the centroid to the nearest and farthest sampling points in an n-dimensional manifold and show that the Relative Contrast of the sample data vanishes as dimensionality of the underlying vector space tends to infinity.
DeepSat - A Learning framework for Satellite Imagery
Sep 11, 2015
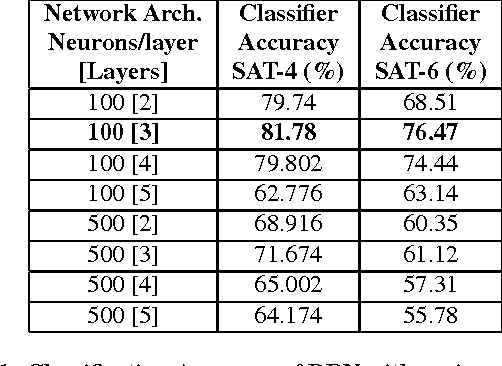
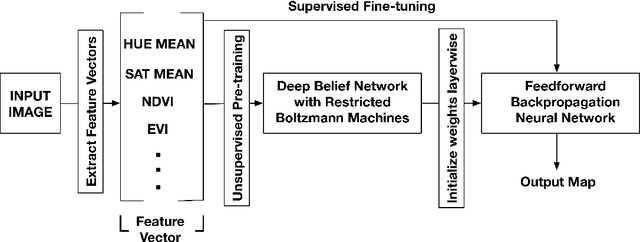
Satellite image classification is a challenging problem that lies at the crossroads of remote sensing, computer vision, and machine learning. Due to the high variability inherent in satellite data, most of the current object classification approaches are not suitable for handling satellite datasets. The progress of satellite image analytics has also been inhibited by the lack of a single labeled high-resolution dataset with multiple class labels. The contributions of this paper are twofold - (1) first, we present two new satellite datasets called SAT-4 and SAT-6, and (2) then, we propose a classification framework that extracts features from an input image, normalizes them and feeds the normalized feature vectors to a Deep Belief Network for classification. On the SAT-4 dataset, our best network produces a classification accuracy of 97.95% and outperforms three state-of-the-art object recognition algorithms, namely - Deep Belief Networks, Convolutional Neural Networks and Stacked Denoising Autoencoders by ~11%. On SAT-6, it produces a classification accuracy of 93.9% and outperforms the other algorithms by ~15%. Comparative studies with a Random Forest classifier show the advantage of an unsupervised learning approach over traditional supervised learning techniques. A statistical analysis based on Distribution Separability Criterion and Intrinsic Dimensionality Estimation substantiates the effectiveness of our approach in learning better representations for satellite imagery.
Learning Sparse Feature Representations using Probabilistic Quadtrees and Deep Belief Nets
Sep 11, 2015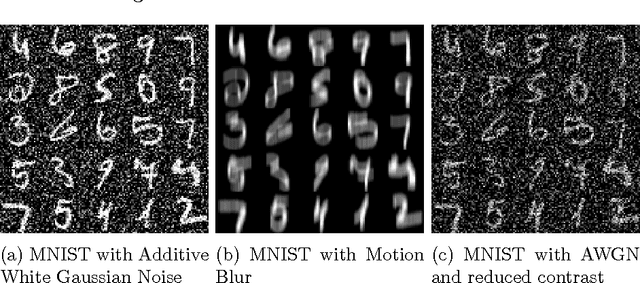
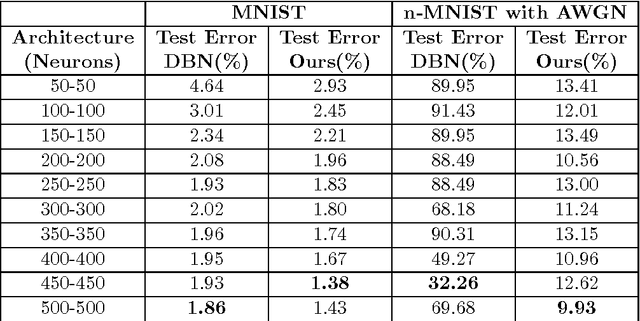
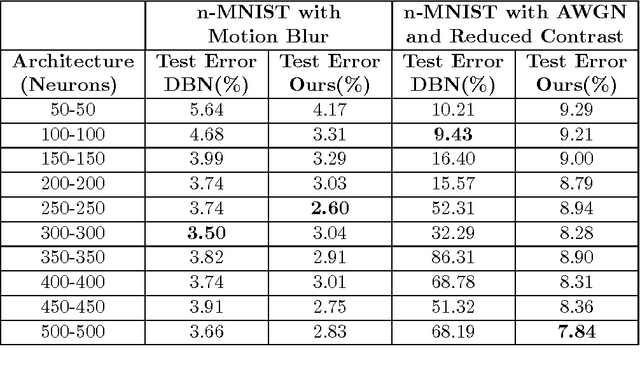
Learning sparse feature representations is a useful instrument for solving an unsupervised learning problem. In this paper, we present three labeled handwritten digit datasets, collectively called n-MNIST. Then, we propose a novel framework for the classification of handwritten digits that learns sparse representations using probabilistic quadtrees and Deep Belief Nets. On the MNIST and n-MNIST datasets, our framework shows promising results and significantly outperforms traditional Deep Belief Networks.