 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Artificial Intelligence Models for Daily Coastal Hypoxia Forecasting
Feb 05, 2026Coastal hypoxia, especially in the northern part of Gulf of Mexico, presents a persistent ecological and economic concern. Seasonal models offer coarse forecasts that miss the fine-scale variability needed for daily, responsive ecosystem management. We present study that compares four deep learning architectures for daily hypoxia classification: Bidirectional Long Short-Term Memory (BiLSTM), Medformer (Medical Transformer), Spatio-Temporal Transformer (ST-Transformer), and Temporal Convolutional Network (TCN). We trained our models with twelve years of daily hindcast data from 2009-2020 Our training data consists of 2009-2020 hindcast data from a coupled hydrodynamic-biogeochemical model. Similarly, we use hindcast data from 2020 through 2024 as a test data. We constructed classification models incorporating water column stratification, sediment oxygen consumption, and temperature-dependent decomposition rates. We evaluated each architectures using the same data preprocessing, input/output formulation, and validation protocols. Each model achieved high classification accuracy and strong discriminative ability with ST-Transformer achieving the highest performance across all metrics and tests periods (AUC-ROC: 0.982-0.992). We also employed McNemar's method to identify statistically significant differences in model predictions. Our contribution is a reproducible framework for operational real-time hypoxia prediction that can support broader efforts in the environmental and ocean modeling systems community and in ecosystem resilience. The source code is available https://github.com/rmagesh148/hypoxia-ai/
COMBOOD: A Semiparametric Approach for Detecting Out-of-distribution Data for Image Classification
Feb 04, 2026Identifying out-of-distribution (OOD) data at inference time is crucial for many machine learning applications, especially for automation. We present a novel unsupervised semi-parametric framework COMBOOD for OOD detection with respect to image recognition. Our framework combines signals from two distance metrics, nearest-neighbor and Mahalanobis, to derive a confidence score for an inference point to be out-of-distribution. The former provides a non-parametric approach to OOD detection. The latter provides a parametric, simple, yet effective method for detecting OOD data points, especially, in the far OOD scenario, where the inference point is far apart from the training data set in the embedding space. However, its performance is not satisfactory in the near OOD scenarios that arise in practical situations. Our COMBOOD framework combines the two signals in a semi-parametric setting to provide a confidence score that is accurate both for the near-OOD and far-OOD scenarios. We show experimental results with the COMBOOD framework for different types of feature extraction strategies. We demonstrate experimentally that COMBOOD outperforms state-of-the-art OOD detection methods on the OpenOOD (both version 1 and most recent version 1.5) benchmark datasets (for both far-OOD and near-OOD) as well as on the documents dataset in terms of accuracy. On a majority of the benchmark datasets, the improvements in accuracy resulting from the COMBOOD framework are statistically significant. COMBOOD scales linearly with the size of the embedding space, making it ideal for many real-life applications.
* Copyright by SIAM. Unauthorized reproduction of this article is prohibited First Published in Proceedings of the 2024 SIAM International Conference on Data Mining (SDM24), published by the Society for Industrial and Applied Mathematics (SIAM)
Risks and Opportunities of Open-Source Generative AI
May 14, 2024



Applications of Generative AI (Gen AI) are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about the potential risks of the technology, and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open-source generative AI. Using a three-stage framework for Gen AI development (near, mid and long-term), we analyze the risks and opportunities of open-source generative AI models with similar capabilities to the ones currently available (near to mid-term) and with greater capabilities (long-term). We argue that, overall, the benefits of open-source Gen AI outweigh its risks. As such, we encourage the open sourcing of models, training and evaluation data, and provide a set of recommendations and best practices for managing risks associated with open-source generative AI.
Near to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024



In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.
Collisionless Pattern Discovery in Robot Swarms Using Deep Reinforcement Learning
Sep 20, 2022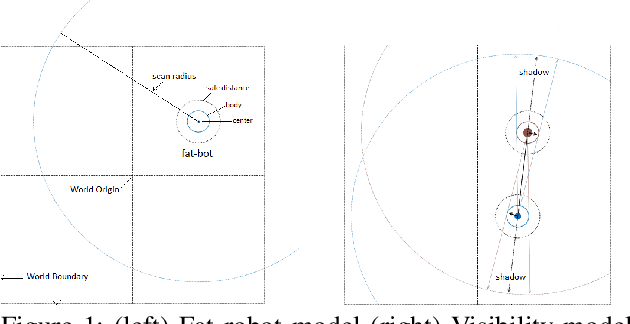
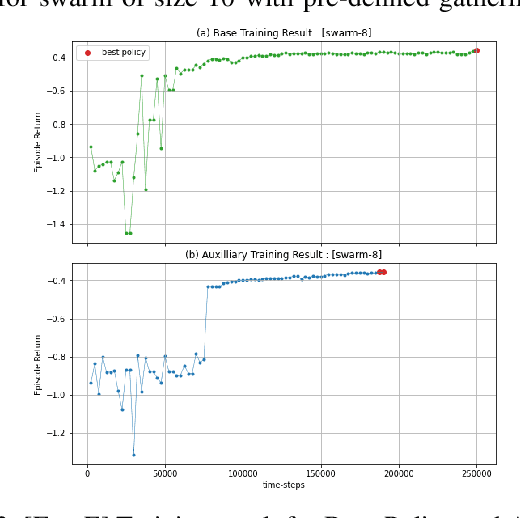

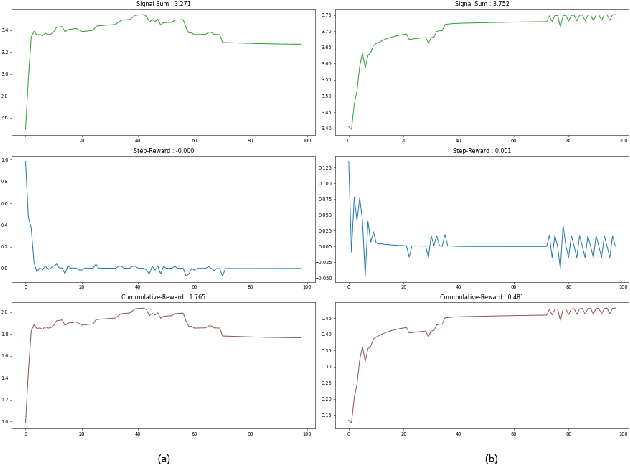
We present a deep reinforcement learning-based framework for automatically discovering patterns available in any given initial configuration of fat robot swarms. In particular, we model the problem of collision-less gathering and mutual visibility in fat robot swarms and discover patterns for solving them using our framework. We show that by shaping reward signals based on certain constraints like mutual visibility and safe proximity, the robots can discover collision-less trajectories leading to well-formed gathering and visibility patterns.
XOOD: Extreme Value Based Out-Of-Distribution Detection For Image Classification
Aug 01, 2022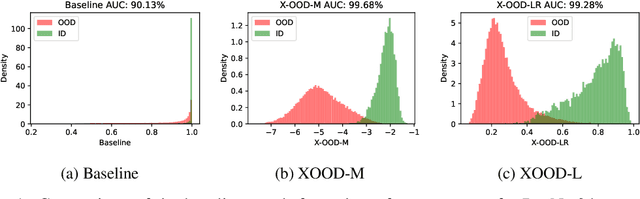
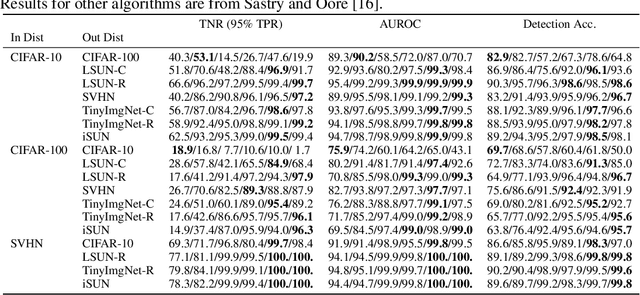
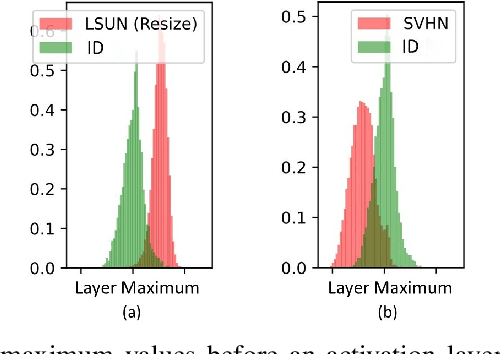
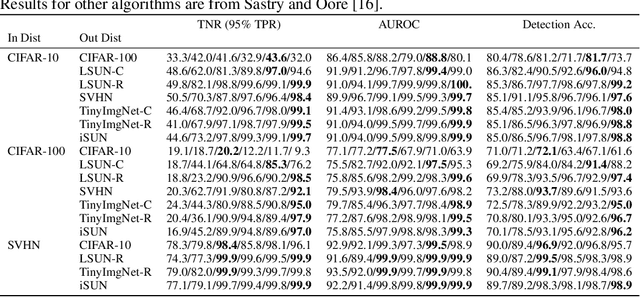
Detecting out-of-distribution (OOD) data at inference time is crucial for many applications of machine learning. We present XOOD: a novel extreme value-based OOD detection framework for image classification that consists of two algorithms. The first, XOOD-M, is completely unsupervised, while the second XOOD-L is self-supervised. Both algorithms rely on the signals captured by the extreme values of the data in the activation layers of the neural network in order to distinguish between in-distribution and OOD instances. We show experimentally that both XOOD-M and XOOD-L outperform state-of-the-art OOD detection methods on many benchmark data sets in both efficiency and accuracy, reducing false-positive rate (FPR95) by 50%, while improving the inferencing time by an order of magnitude.
Numerical Evaluation of a muon tomography system for imaging defects in concrete structures
Feb 17, 2021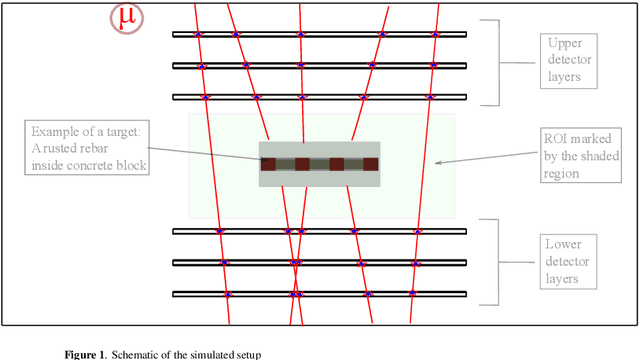
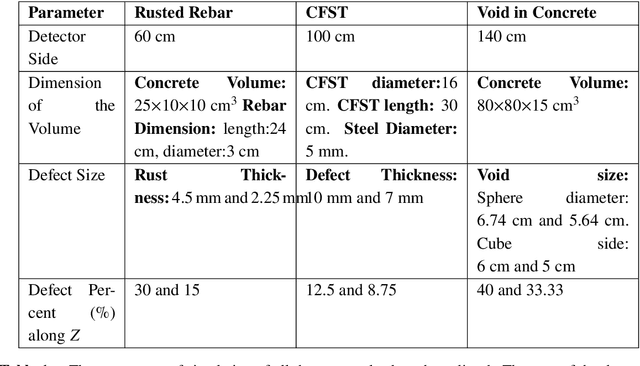
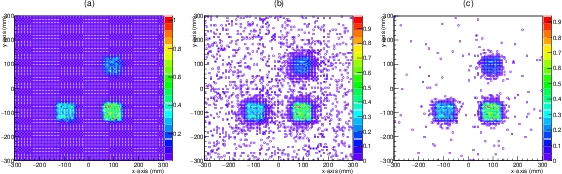
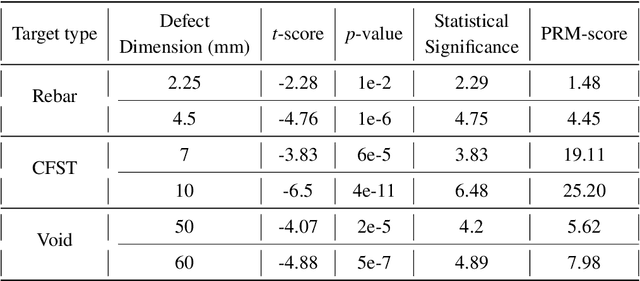
Among its numerous applications, deployment in civil structures has caught attraction of many recently. The detection of defects based on inherent physical quantities such as density and atomic number by probing naturally available cosmic muons makes MST a novel idea suitable for inexpensive and non-destructive imaging. In this work, capability of MST to detect concrete defects has been tested and evaluated in terms of two-dimensional imaging and statistical calculations. The imaging has been done on unique and critical defects causing degradation in civil structures. The capability and limitation of MST in this avenue have also been studied.
A One-Shot Learning Framework for Assessment of Fibrillar Collagen from Second Harmonic Generation Images of an Infarcted Myocardium
Jan 30, 2020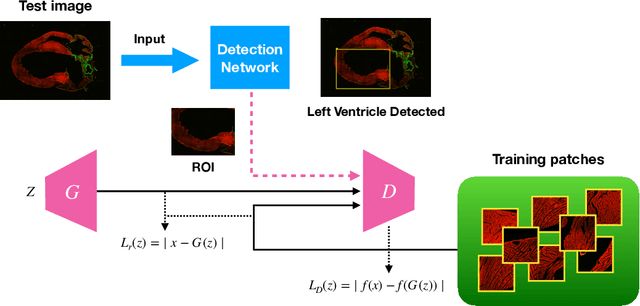
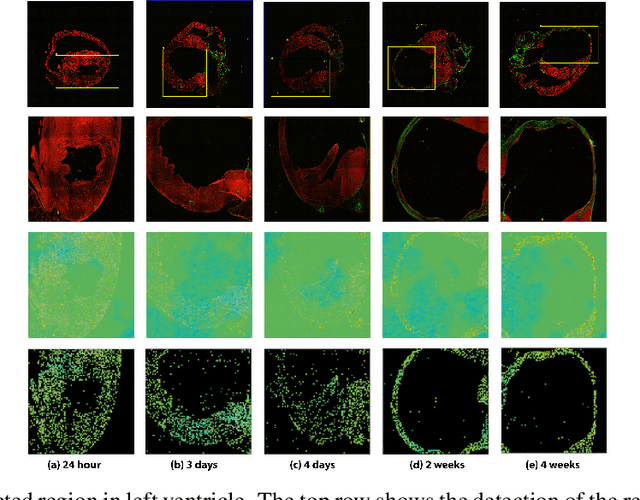
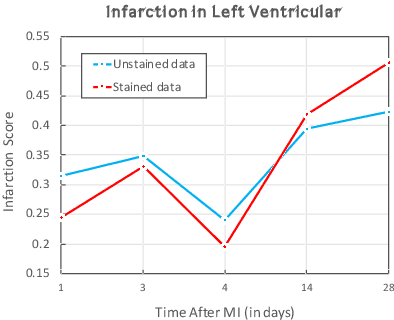
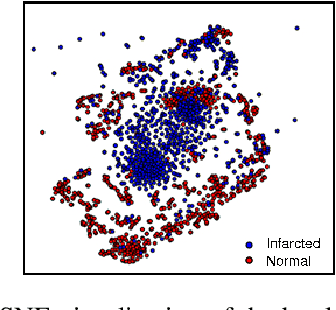
Myocardial infarction (MI) is a scientific term that refers to heart attack. In this study, we infer highly relevant second harmonic generation (SHG) cues from collagen fibers exhibiting highly non-centrosymmetric assembly together with two-photon excited cellular autofluorescence in infarcted mouse heart to quantitatively probe fibrosis, especially targeted at an early stage after MI. We present a robust one-shot machine learning algorithm that enables determination of 2D assembly of collagen with high spatial resolution along with its structural arrangement in heart tissues post-MI with spectral specificity and sensitivity. Detection, evaluation, and precise quantification of fibrosis extent at early stage would guide one to develop treatment therapies that may prevent further progression and determine heart transplant needs for patient survival.
Context-Aware Design of Cyber-Physical Human Systems
Jan 07, 2020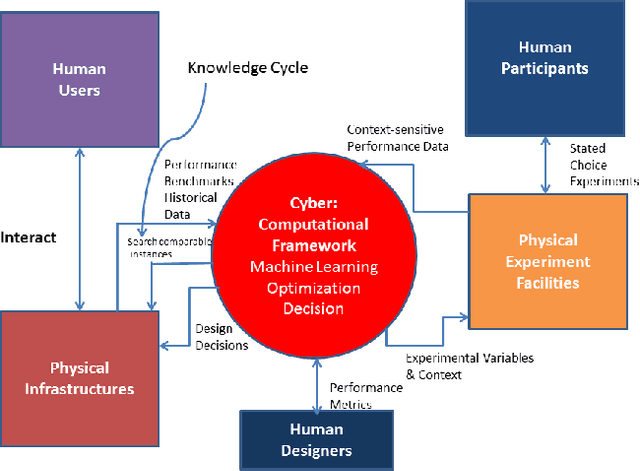
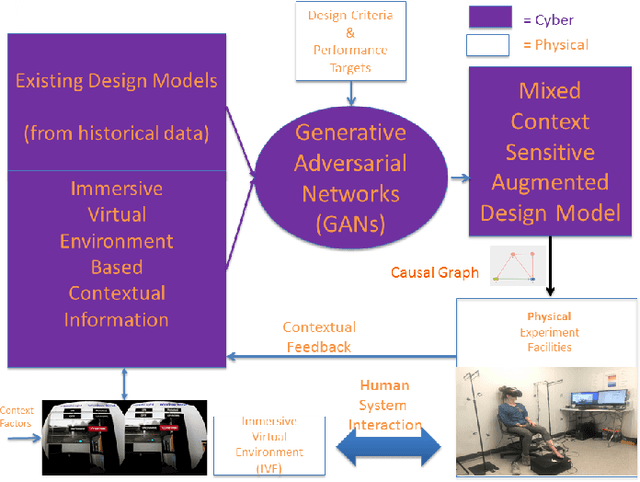
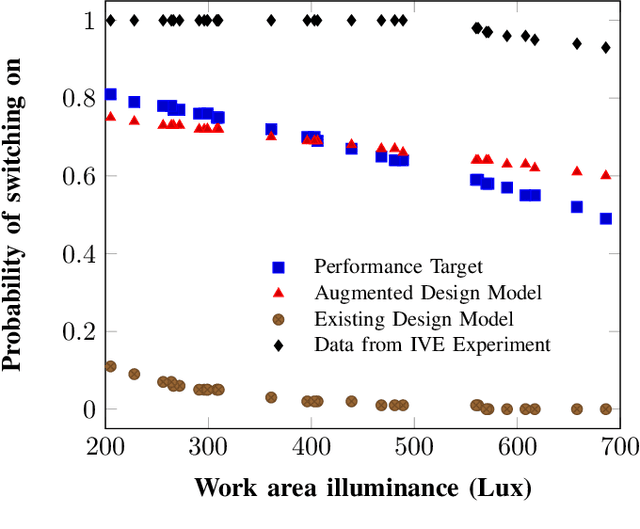
Recently, it has been widely accepted by the research community that interactions between humans and cyber-physical infrastructures have played a significant role in determining the performance of the latter. The existing paradigm for designing cyber-physical systems for optimal performance focuses on developing models based on historical data. The impacts of context factors driving human system interaction are challenging and are difficult to capture and replicate in existing design models. As a result, many existing models do not or only partially address those context factors of a new design owing to the lack of capabilities to capture the context factors. This limitation in many existing models often causes performance gaps between predicted and measured results. We envision a new design environment, a cyber-physical human system (CPHS) where decision-making processes for physical infrastructures under design are intelligently connected to distributed resources over cyberinfrastructure such as experiments on design features and empirical evidence from operations of existing instances. The framework combines existing design models with context-aware design-specific data involving human-infrastructure interactions in new designs, using a machine learning approach to create augmented design models with improved predictive powers.
DeepSat V2: Feature Augmented Convolutional Neural Nets for Satellite Image Classification
Nov 15, 2019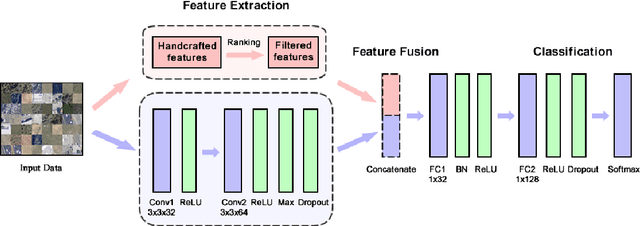
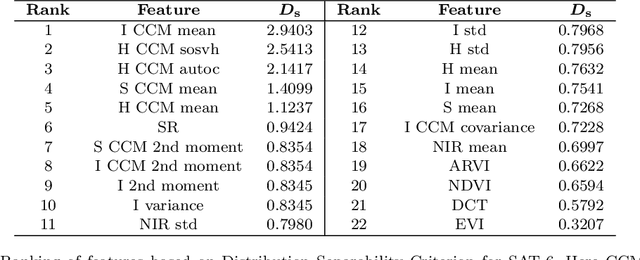
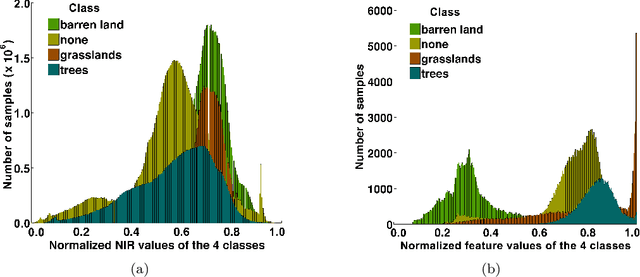
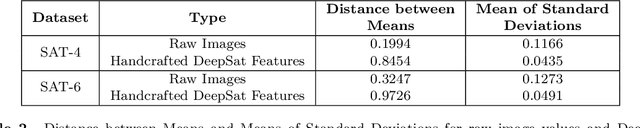
Satellite image classification is a challenging problem that lies at the crossroads of remote sensing, computer vision, and machine learning. Due to the high variability inherent in satellite data, most of the current object classification approaches are not suitable for handling satellite datasets. The progress of satellite image analytics has also been inhibited by the lack of a single labeled high-resolution dataset with multiple class labels. In a preliminary version of this work, we introduced two new high resolution satellite imagery datasets (SAT-4 and SAT-6) and proposed DeepSat framework for classification based on "handcrafted" features and a deep belief network (DBN). The present paper is an extended version, we present an end-to-end framework leveraging an improved architecture that augments a convolutional neural network (CNN) with handcrafted features (instead of using DBN-based architecture) for classification. Our framework, having access to fused spatial information obtained from handcrafted features as well as CNN feature maps, have achieved accuracies of 99.90% and 99.84% respectively, on SAT-4 and SAT-6, surpassing all the other state-of-the-art results. A statistical analysis based on Distribution Separability Criterion substantiates the robustness of our approach in learning better representations for satellite imagery.