 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Calibration Network for Occluded Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially for scenes containing serious occlusion. In this paper, we propose a novel feature learning method in the deep learning framework, referred to as Feature Calibration Network (FC-Net), to adaptively detect pedestrians under various occlusions. FC-Net is based on the observation that the visible parts of pedestrians are selective and decisive for detection, and is implemented as a self-paced feature learning framework with a self-activation (SA) module and a feature calibration (FC) module. In a new self-activated manner, FC-Net learns features which highlight the visible parts and suppress the occluded parts of pedestrians. The SA module estimates pedestrian activation maps by reusing classifier weights, without any additional parameter involved, therefore resulting in an extremely parsimony model to reinforce the semantics of features, while the FC module calibrates the convolutional features for adaptive pedestrian representation in both pixel-wise and region-based ways. Experiments on CityPersons and Caltech datasets demonstrate that FC-Net improves detection performance on occluded pedestrians up to 10% while maintaining excellent performance on non-occluded instances.
CircleNet: Reciprocating Feature Adaptation for Robust Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially when the scene contains significant occlusion and/or low resolution of the pedestrians to be detected. Existing methods are unable to adapt to these difficult cases while maintaining acceptable performance. In this paper we propose a novel feature learning model, referred to as CircleNet, to achieve feature adaptation by mimicking the process humans looking at low resolution and occluded objects: focusing on it again, at a finer scale, if the object can not be identified clearly for the first time. CircleNet is implemented as a set of feature pyramids and uses weight sharing path augmentation for better feature fusion. It targets at reciprocating feature adaptation and iterative object detection using multiple top-down and bottom-up pathways. To take full advantage of the feature adaptation capability in CircleNet, we design an instance decomposition training strategy to focus on detecting pedestrian instances of various resolutions and different occlusion levels in each cycle. Specifically, CircleNet implements feature ensemble with the idea of hard negative boosting in an end-to-end manner. Experiments on two pedestrian detection datasets, Caltech and CityPersons, show that CircleNet improves the performance of occluded and low-resolution pedestrians with significant margins while maintaining good performance on normal instances.
Integrally Pre-Trained Transformer Pyramid Networks
Nov 23, 2022



In this paper, we present an integral pre-training framework based on masked image modeling (MIM). We advocate for pre-training the backbone and neck jointly so that the transfer gap between MIM and downstream recognition tasks is minimal. We make two technical contributions. First, we unify the reconstruction and recognition necks by inserting a feature pyramid into the pre-training stage. Second, we complement mask image modeling (MIM) with masked feature modeling (MFM) that offers multi-stage supervision to the feature pyramid. The pre-trained models, termed integrally pre-trained transformer pyramid networks (iTPNs), serve as powerful foundation models for visual recognition. In particular, the base/large-level iTPN achieves an 86.2%/87.8% top-1 accuracy on ImageNet-1K, a 53.2%/55.6% box AP on COCO object detection with 1x training schedule using Mask-RCNN, and a 54.7%/57.7% mIoU on ADE20K semantic segmentation using UPerHead -- all these results set new records. Our work inspires the community to work on unifying upstream pre-training and downstream fine-tuning tasks. Code and the pre-trained models will be released at https://github.com/sunsmarterjie/iTPN.
Beyond Instance Discrimination: Relation-aware Contrastive Self-supervised Learning
Nov 02, 2022



Contrastive self-supervised learning (CSL) based on instance discrimination typically attracts positive samples while repelling negatives to learn representations with pre-defined binary self-supervision. However, vanilla CSL is inadequate in modeling sophisticated instance relations, limiting the learned model to retain fine semantic structure. On the one hand, samples with the same semantic category are inevitably pushed away as negatives. On the other hand, differences among samples cannot be captured. In this paper, we present relation-aware contrastive self-supervised learning (ReCo) to integrate instance relations, i.e., global distribution relation and local interpolation relation, into the CSL framework in a plug-and-play fashion. Specifically, we align similarity distributions calculated between the positive anchor views and the negatives at the global level to exploit diverse similarity relations among instances. Local-level interpolation consistency between the pixel space and the feature space is applied to quantitatively model the feature differences of samples with distinct apparent similarities. Through explicitly instance relation modeling, our ReCo avoids irrationally pushing away semantically identical samples and carves a well-structured feature space. Extensive experiments conducted on commonly used benchmarks justify that our ReCo consistently gains remarkable performance improvements.
A Unified View of Masked Image Modeling
Oct 19, 2022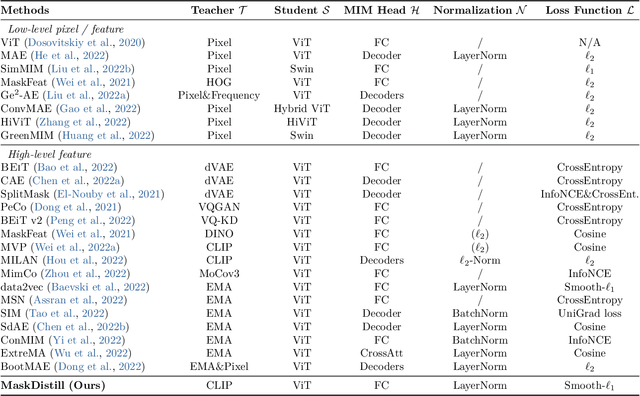
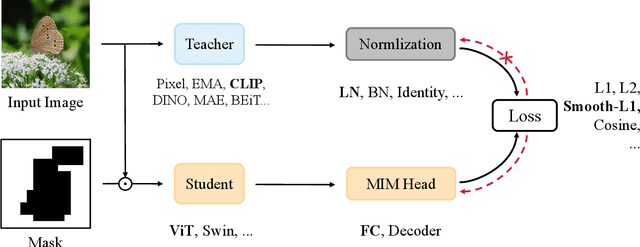


Masked image modeling has demonstrated great potential to eliminate the label-hungry problem of training large-scale vision Transformers, achieving impressive performance on various downstream tasks. In this work, we propose a unified view of masked image modeling after revisiting existing methods. Under the unified view, we introduce a simple yet effective method, termed as MaskDistill, which reconstructs normalized semantic features from teacher models at the masked positions, conditioning on corrupted input images. Experimental results on image classification and semantic segmentation show that MaskDistill achieves comparable or superior performance than state-of-the-art methods. When using the huge vision Transformer and pretraining 300 epochs, MaskDistill obtains 88.3% fine-tuning top-1 accuracy on ImageNet-1k (224 size) and 58.8% semantic segmentation mIoU metric on ADE20k (512 size). The code and pretrained models will be available at https://aka.ms/unimim.
Multi-Agent Automated Machine Learning
Oct 17, 2022
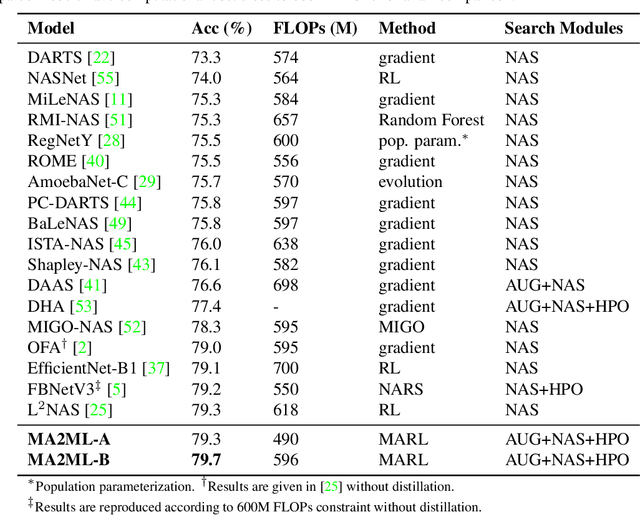
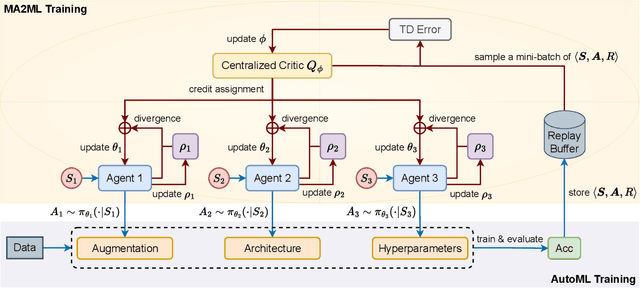
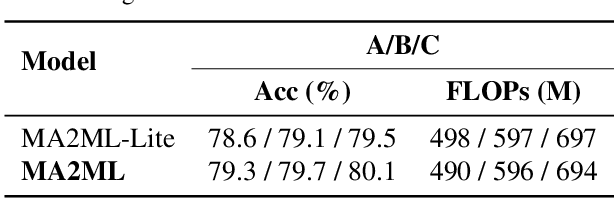
In this paper, we propose multi-agent automated machine learning (MA2ML) with the aim to effectively handle joint optimization of modules in automated machine learning (AutoML). MA2ML takes each machine learning module, such as data augmentation (AUG), neural architecture search (NAS), or hyper-parameters (HPO), as an agent and the final performance as the reward, to formulate a multi-agent reinforcement learning problem. MA2ML explicitly assigns credit to each agent according to its marginal contribution to enhance cooperation among modules, and incorporates off-policy learning to improve search efficiency. Theoretically, MA2ML guarantees monotonic improvement of joint optimization. Extensive experiments show that MA2ML yields the state-of-the-art top-1 accuracy on ImageNet under constraints of computational cost, e.g., $79.7\%/80.5\%$ with FLOPs fewer than 600M/800M. Extensive ablation studies verify the benefits of credit assignment and off-policy learning of MA2ML.
Learnable Distribution Calibration for Few-Shot Class-Incremental Learning
Oct 01, 2022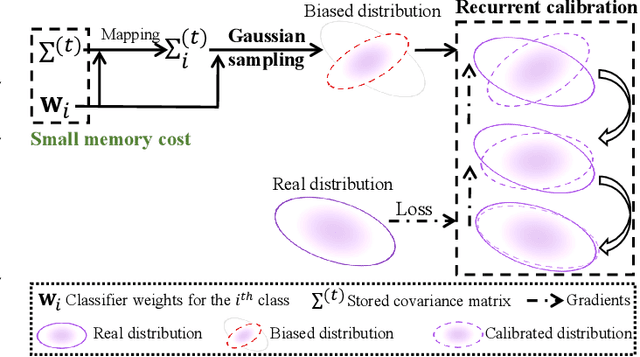



Few-shot class-incremental learning (FSCIL) faces challenges of memorizing old class distributions and estimating new class distributions given few training samples. In this study, we propose a learnable distribution calibration (LDC) approach, with the aim to systematically solve these two challenges using a unified framework. LDC is built upon a parameterized calibration unit (PCU), which initializes biased distributions for all classes based on classifier vectors (memory-free) and a single covariance matrix. The covariance matrix is shared by all classes, so that the memory costs are fixed. During base training, PCU is endowed with the ability to calibrate biased distributions by recurrently updating sampled features under the supervision of real distributions. During incremental learning, PCU recovers distributions for old classes to avoid `forgetting', as well as estimating distributions and augmenting samples for new classes to alleviate `over-fitting' caused by the biased distributions of few-shot samples. LDC is theoretically plausible by formatting a variational inference procedure. It improves FSCIL's flexibility as the training procedure requires no class similarity priori. Experiments on CUB200, CIFAR100, and mini-ImageNet datasets show that LDC outperforms the state-of-the-arts by 4.64%, 1.98%, and 3.97%, respectively. LDC's effectiveness is also validated on few-shot learning scenarios.
BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
Aug 12, 2022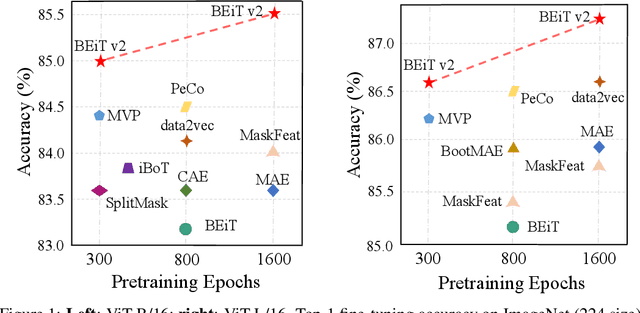
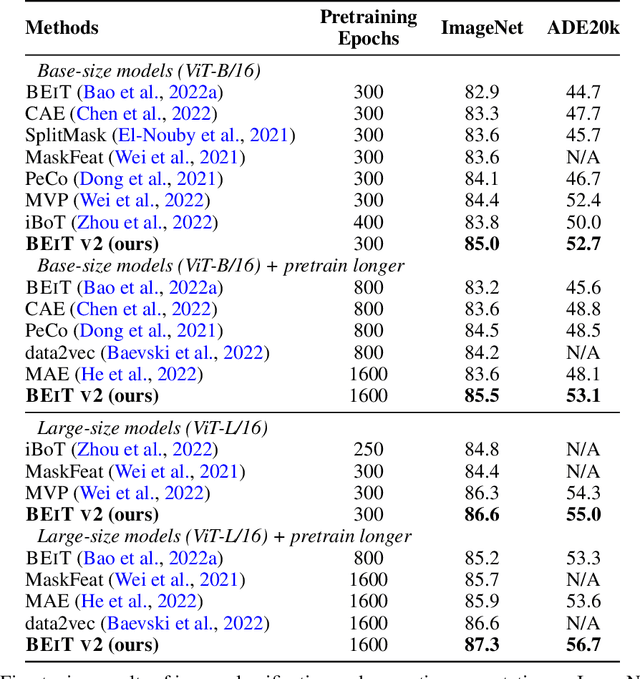
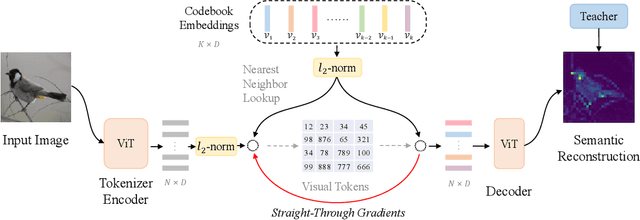

Masked image modeling (MIM) has demonstrated impressive results in self-supervised representation learning by recovering corrupted image patches. However, most methods still operate on low-level image pixels, which hinders the exploitation of high-level semantics for representation models. In this study, we propose to use a semantic-rich visual tokenizer as the reconstruction target for masked prediction, providing a systematic way to promote MIM from pixel-level to semantic-level. Specifically, we introduce vector-quantized knowledge distillation to train the tokenizer, which discretizes a continuous semantic space to compact codes. We then pretrain vision Transformers by predicting the original visual tokens for the masked image patches. Moreover, we encourage the model to explicitly aggregate patch information into a global image representation, which facilities linear probing. Experiments on image classification and semantic segmentation show that our approach outperforms all compared MIM methods. On ImageNet-1K (224 size), the base-size BEiT v2 achieves 85.5% top-1 accuracy for fine-tuning and 80.1% top-1 accuracy for linear probing. The large-size BEiT v2 obtains 87.3% top-1 accuracy for ImageNet-1K (224 size) fine-tuning, and 56.7% mIoU on ADE20K for semantic segmentation. The code and pretrained models are available at https://aka.ms/beit.
Point-to-Box Network for Accurate Object Detection via Single Point Supervision
Jul 14, 2022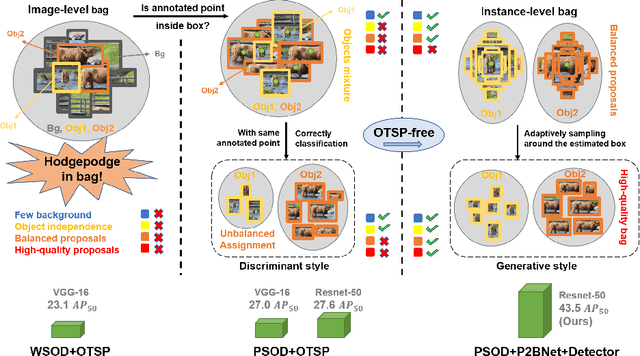
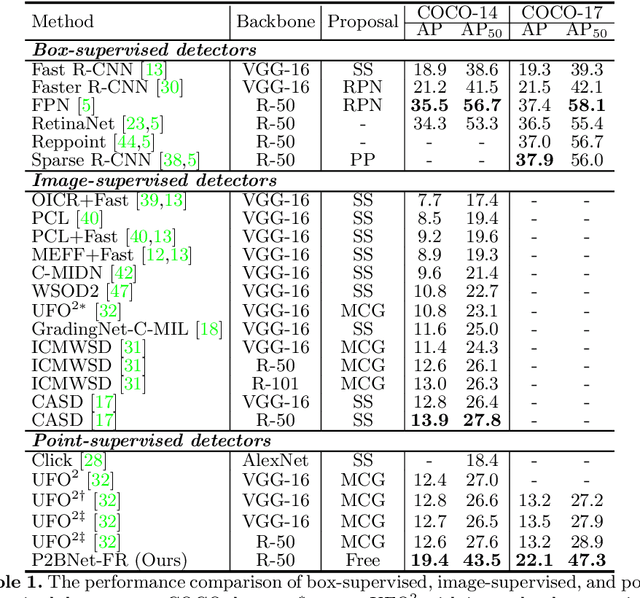
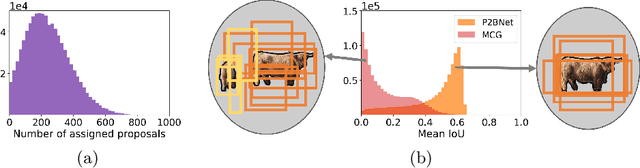
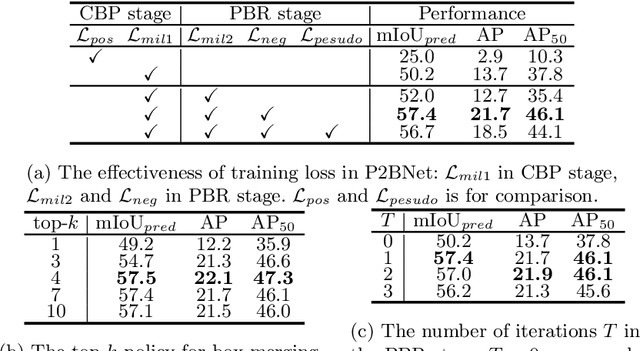
Object detection using single point supervision has received increasing attention over the years. In this paper, we attribute such a large performance gap to the failure of generating high-quality proposal bags which are crucial for multiple instance learning (MIL). To address this problem, we introduce a lightweight alternative to the off-the-shelf proposal (OTSP) method and thereby create the Point-to-Box Network (P2BNet), which can construct an inter-objects balanced proposal bag by generating proposals in an anchor-like way. By fully investigating the accurate position information, P2BNet further constructs an instance-level bag, avoiding the mixture of multiple objects. Finally, a coarse-to-fine policy in a cascade fashion is utilized to improve the IoU between proposals and ground-truth (GT). Benefiting from these strategies, P2BNet is able to produce high-quality instance-level bags for object detection. P2BNet improves the mean average precision (AP) by more than 50% relative to the previous best PSOD method on the MS COCO dataset. It also demonstrates the great potential to bridge the performance gap between point supervised and bounding-box supervised detectors. The code will be released at github.com/ucas-vg/P2BNet.
HiViT: Hierarchical Vision Transformer Meets Masked Image Modeling
May 30, 2022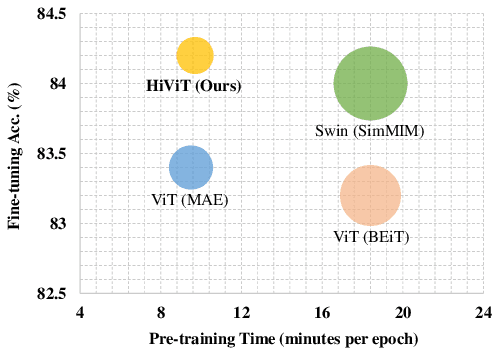

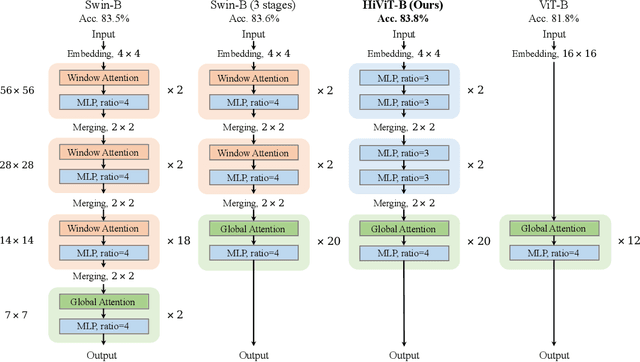
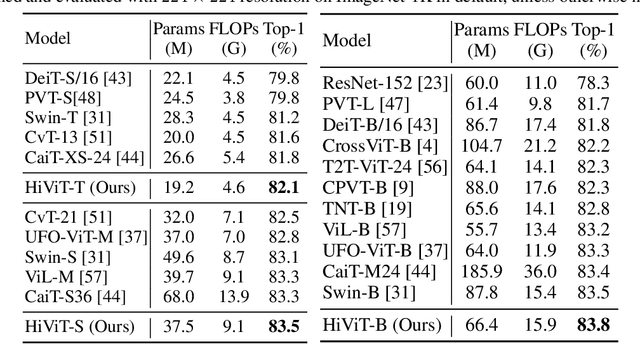
Recently, masked image modeling (MIM) has offered a new methodology of self-supervised pre-training of vision transformers. A key idea of efficient implementation is to discard the masked image patches (or tokens) throughout the target network (encoder), which requires the encoder to be a plain vision transformer (e.g., ViT), albeit hierarchical vision transformers (e.g., Swin Transformer) have potentially better properties in formulating vision inputs. In this paper, we offer a new design of hierarchical vision transformers named HiViT (short for Hierarchical ViT) that enjoys both high efficiency and good performance in MIM. The key is to remove the unnecessary "local inter-unit operations", deriving structurally simple hierarchical vision transformers in which mask-units can be serialized like plain vision transformers. For this purpose, we start with Swin Transformer and (i) set the masking unit size to be the token size in the main stage of Swin Transformer, (ii) switch off inter-unit self-attentions before the main stage, and (iii) eliminate all operations after the main stage. Empirical studies demonstrate the advantageous performance of HiViT in terms of fully-supervised, self-supervised, and transfer learning. In particular, in running MAE on ImageNet-1K, HiViT-B reports a +0.6% accuracy gain over ViT-B and a 1.9$\times$ speed-up over Swin-B, and the performance gain generalizes to downstream tasks of detection and segmentation. Code will be made publicly available.