 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChildPredictor: A Child Face Prediction Framework with Disentangled Learning
Apr 21, 2022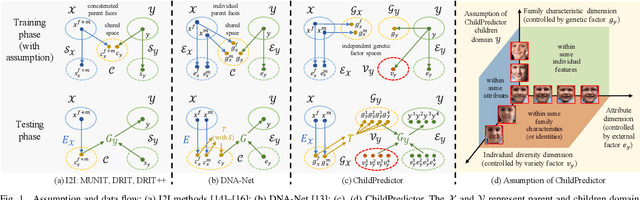

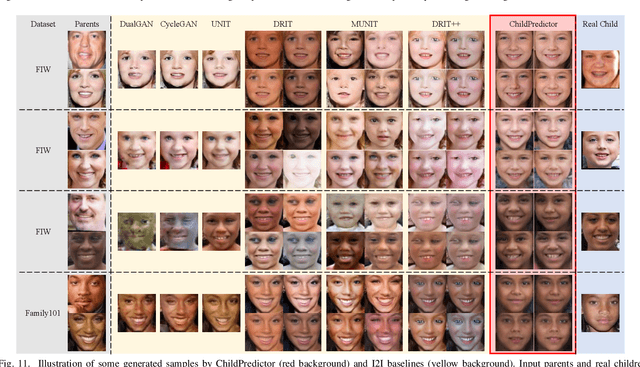

The appearances of children are inherited from their parents, which makes it feasible to predict them. Predicting realistic children's faces may help settle many social problems, such as age-invariant face recognition, kinship verification, and missing child identification. It can be regarded as an image-to-image translation task. Existing approaches usually assume domain information in the image-to-image translation can be interpreted by "style", i.e., the separation of image content and style. However, such separation is improper for the child face prediction, because the facial contours between children and parents are not the same. To address this issue, we propose a new disentangled learning strategy for children's face prediction. We assume that children's faces are determined by genetic factors (compact family features, e.g., face contour), external factors (facial attributes irrelevant to prediction, such as moustaches and glasses), and variety factors (individual properties for each child). On this basis, we formulate predictions as a mapping from parents' genetic factors to children's genetic factors, and disentangle them from external and variety factors. In order to obtain accurate genetic factors and perform the mapping, we propose a ChildPredictor framework. It transfers human faces to genetic factors by encoders and back by generators. Then, it learns the relationship between the genetic factors of parents and children through a mapping function. To ensure the generated faces are realistic, we collect a large Family Face Database to train ChildPredictor and evaluate it on the FF-Database validation set. Experimental results demonstrate that ChildPredictor is superior to other well-known image-to-image translation methods in predicting realistic and diverse child faces. Implementation codes can be found at https://github.com/zhaoyuzhi/ChildPredictor.
Dual-Camera Super-Resolution with Aligned Attention Modules
Sep 06, 2021
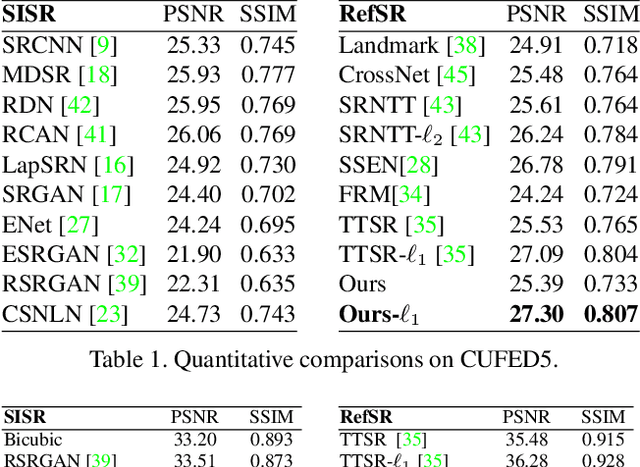
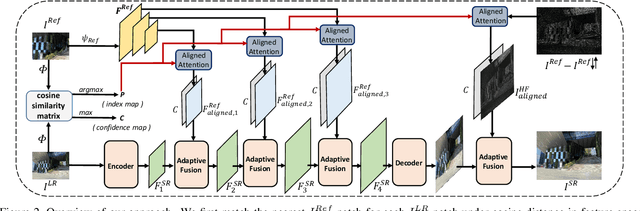
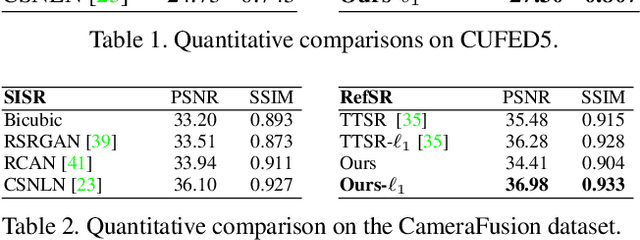
We present a novel approach to reference-based super-resolution (RefSR) with the focus on dual-camera super-resolution (DCSR), which utilizes reference images for high-quality and high-fidelity results. Our proposed method generalizes the standard patch-based feature matching with spatial alignment operations. We further explore the dual-camera super-resolution that is one promising application of RefSR, and build a dataset that consists of 146 image pairs from the main and telephoto cameras in a smartphone. To bridge the domain gaps between real-world images and the training images, we propose a self-supervised domain adaptation strategy for real-world images. Extensive experiments on our dataset and a public benchmark demonstrate clear improvement achieved by our method over state of the art in both quantitative evaluation and visual comparisons.
A Categorized Reflection Removal Dataset with Diverse Real-world Scenes
Aug 07, 2021


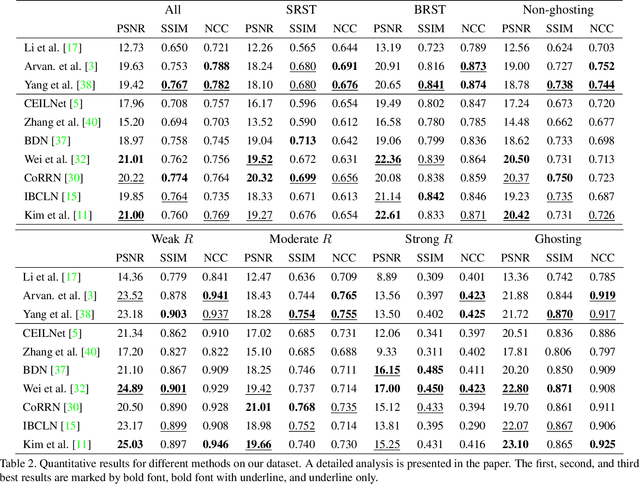
Due to the lack of a large-scale reflection removal dataset with diverse real-world scenes, many existing reflection removal methods are trained on synthetic data plus a small amount of real-world data, which makes it difficult to evaluate the strengths or weaknesses of different reflection removal methods thoroughly. Furthermore, existing real-world benchmarks and datasets do not categorize image data based on the types and appearances of reflection (e.g., smoothness, intensity), making it hard to analyze reflection removal methods. Hence, we construct a new reflection removal dataset that is categorized, diverse, and real-world (CDR). A pipeline based on RAW data is used to capture perfectly aligned input images and transmission images. The dataset is constructed using diverse glass types under various environments to ensure diversity. By analyzing several reflection removal methods and conducting extensive experiments on our dataset, we show that state-of-the-art reflection removal methods generally perform well on blurry reflection but fail in obtaining satisfying performance on other types of real-world reflection. We believe our dataset can help develop novel methods to remove real-world reflection better. Our dataset is available at https://alexzhao-hugga.github.io/Real-World-Reflection-Removal/.
Is a Green Screen Really Necessary for Real-Time Portrait Matting?
Nov 29, 2020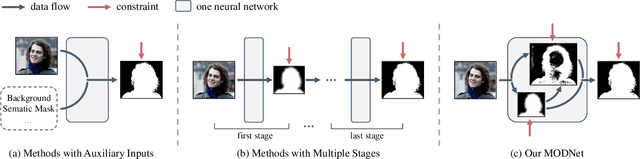
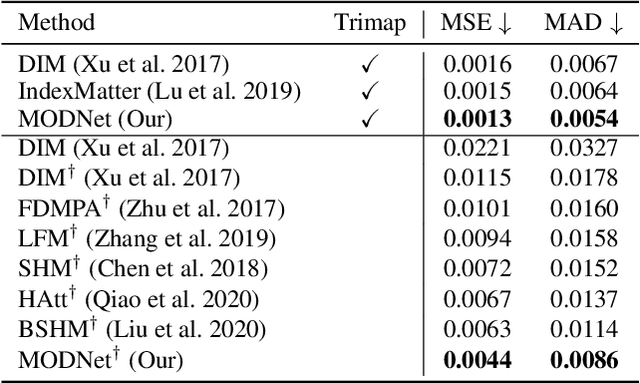
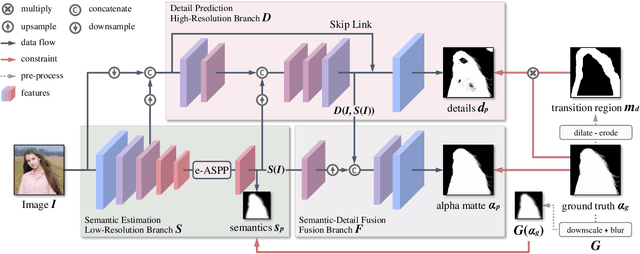
For portrait matting without the green screen, existing works either require auxiliary inputs that are costly to obtain or use multiple models that are computationally expensive. Consequently, they are unavailable in real-time applications. In contrast, we present a light-weight matting objective decomposition network (MODNet), which can process portrait matting from a single input image in real time. The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints. Moreover, since trimap-free methods usually suffer from the domain shift problem in practice, we introduce (1) a self-supervised strategy based on sub-objectives consistency to adapt MODNet to real-world data and (2) a one-frame delay trick to smooth the results when applying MODNet to portrait video sequence. MODNet is easy to be trained in an end-to-end style. It is much faster than contemporaneous matting methods and runs at 63 frames per second. On a carefully designed portrait matting benchmark newly proposed in this work, MODNet greatly outperforms prior trimap-free methods. More importantly, our method achieves remarkable results in daily photos and videos. Now, do you really need a green screen for real-time portrait matting?
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020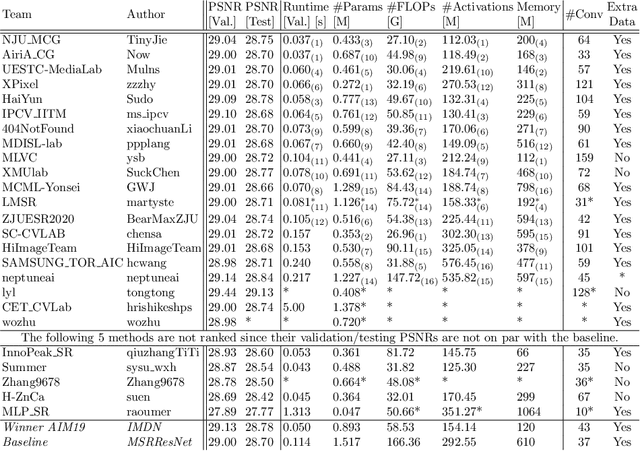
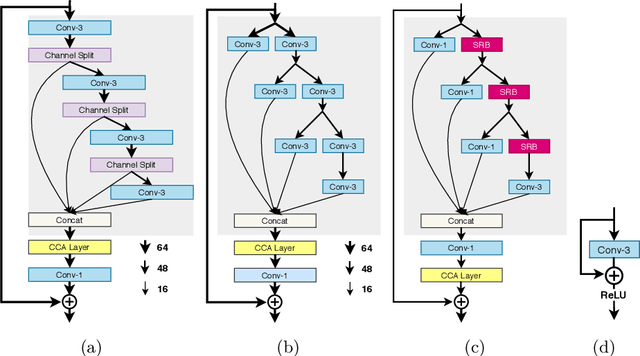
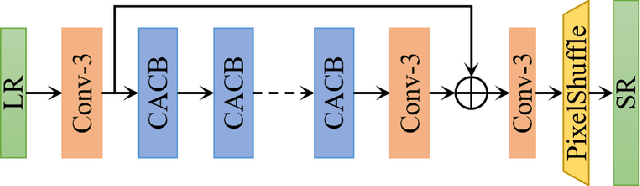
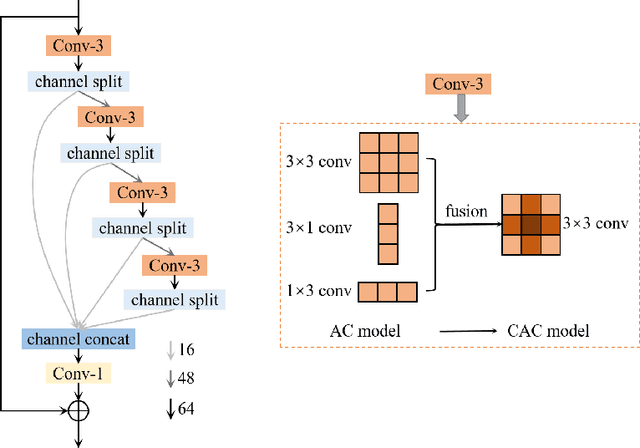
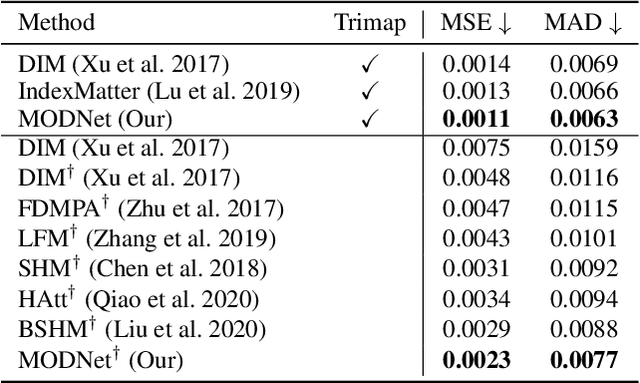
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
Guided Collaborative Training for Pixel-wise Semi-Supervised Learning
Aug 12, 2020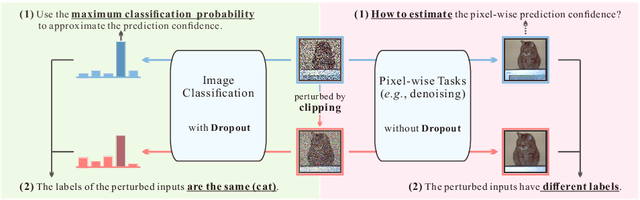
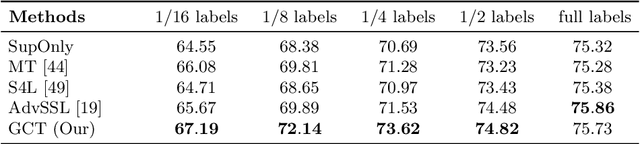
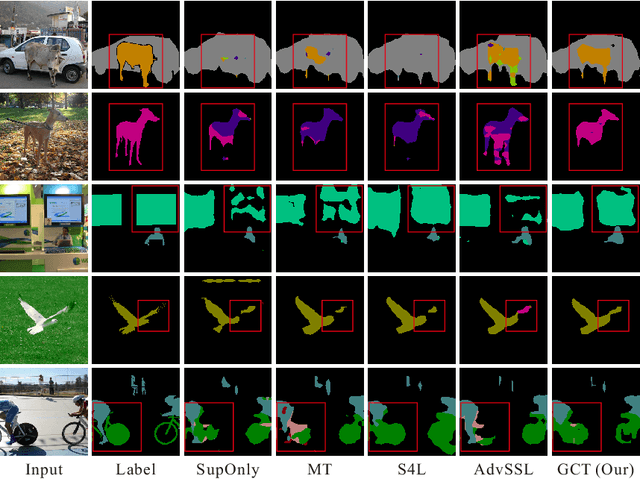
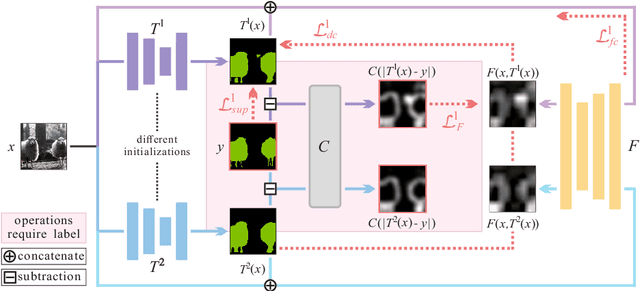
We investigate the generalization of semi-supervised learning (SSL) to diverse pixel-wise tasks. Although SSL methods have achieved impressive results in image classification, the performances of applying them to pixel-wise tasks are unsatisfactory due to their need for dense outputs. In addition, existing pixel-wise SSL approaches are only suitable for certain tasks as they usually require to use task-specific properties. In this paper, we present a new SSL framework, named Guided Collaborative Training (GCT), for pixel-wise tasks, with two main technical contributions. First, GCT addresses the issues caused by the dense outputs through a novel flaw detector. Second, the modules in GCT learn from unlabeled data collaboratively through two newly proposed constraints that are independent of task-specific properties. As a result, GCT can be applied to a wide range of pixel-wise tasks without structural adaptation. Our extensive experiments on four challenging vision tasks, including semantic segmentation, real image denoising, portrait image matting, and night image enhancement, show that GCT outperforms state-of-the-art SSL methods by a large margin. Our code available at: https://github.com/ZHKKKe/PixelSSL.
Hierarchical Regression Network for Spectral Reconstruction from RGB Images
May 10, 2020
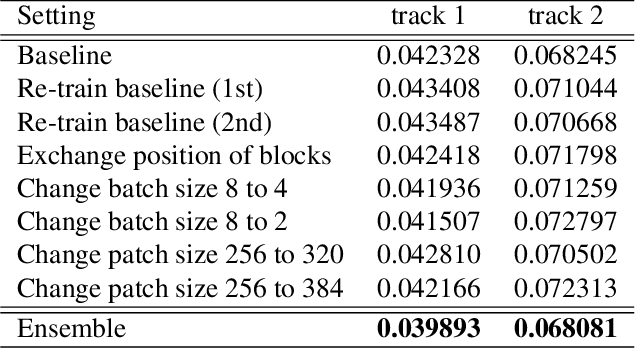
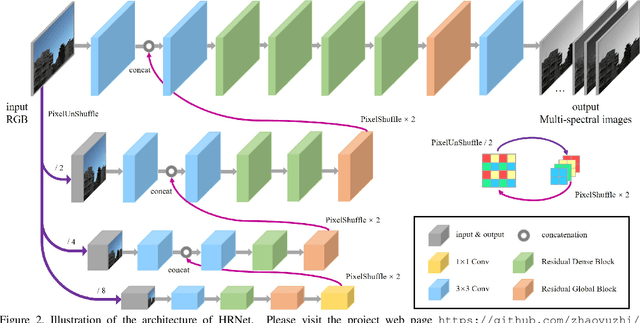
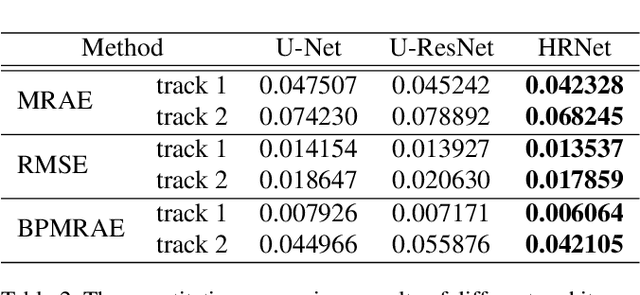
Capturing visual image with a hyperspectral camera has been successfully applied to many areas due to its narrow-band imaging technology. Hyperspectral reconstruction from RGB images denotes a reverse process of hyperspectral imaging by discovering an inverse response function. Current works mainly map RGB images directly to corresponding spectrum but do not consider context information explicitly. Moreover, the use of encoder-decoder pair in current algorithms leads to loss of information. To address these problems, we propose a 4-level Hierarchical Regression Network (HRNet) with PixelShuffle layer as inter-level interaction. Furthermore, we adopt a residual dense block to remove artifacts of real world RGB images and a residual global block to build attention mechanism for enlarging perceptive field. We evaluate proposed HRNet with other architectures and techniques by participating in NTIRE 2020 Challenge on Spectral Reconstruction from RGB Images. The HRNet is the winning method of track 2 - real world images and ranks 3rd on track 1 - clean images. Please visit the project web page https://github.com/zhaoyuzhi/Hierarchical-Regression-Network-for-Spectral-Reconstruction-from-RGB-Images to try our codes and pre-trained models.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020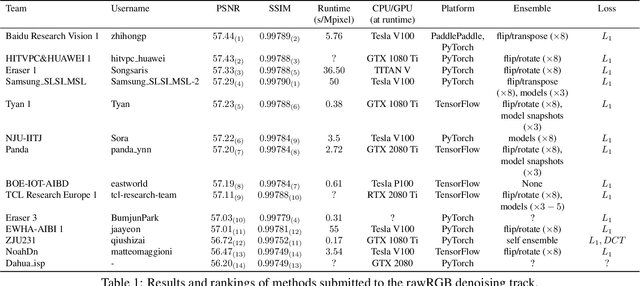
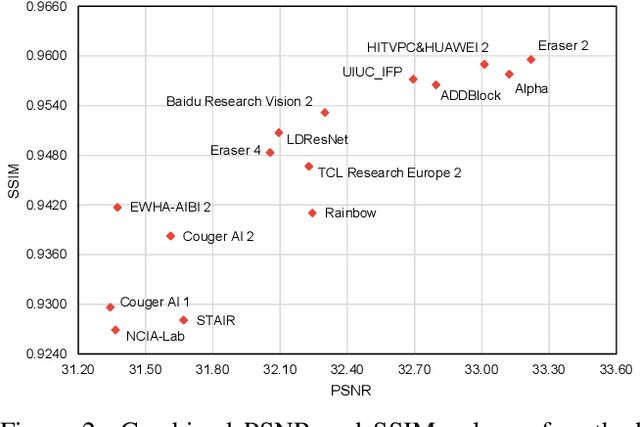
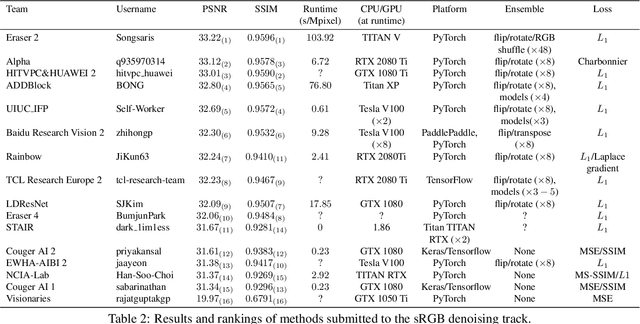
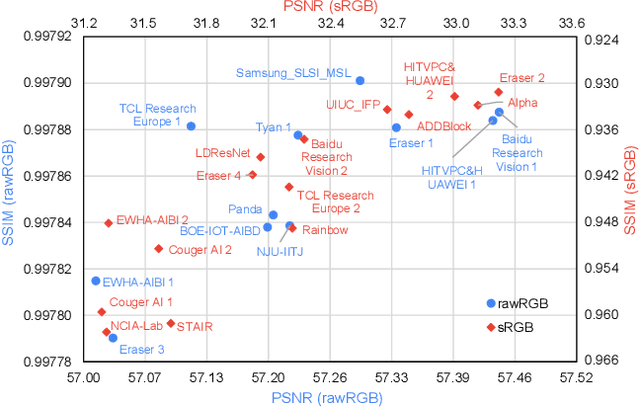
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Polarized Reflection Removal with Perfect Alignment in the Wild
Mar 28, 2020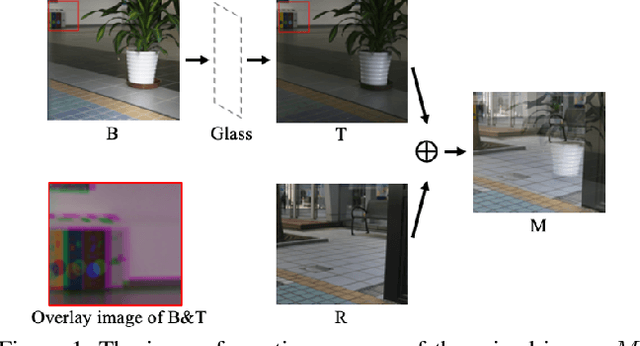

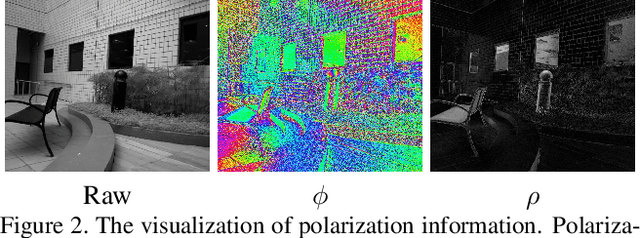
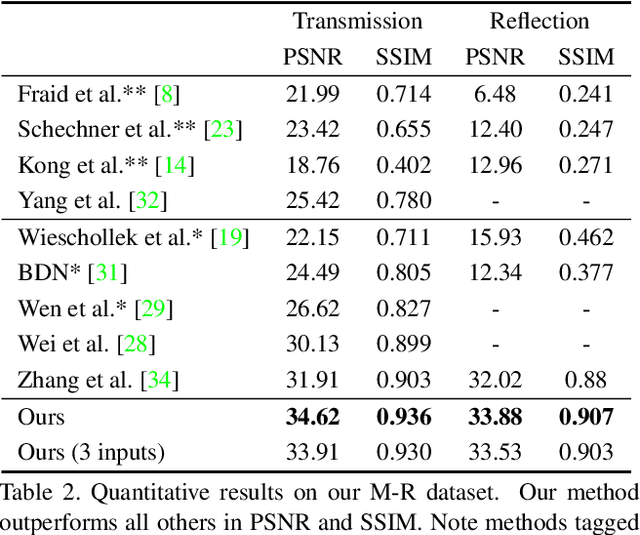
We present a novel formulation to removing reflection from polarized images in the wild. We first identify the misalignment issues of existing reflection removal datasets where the collected reflection-free images are not perfectly aligned with input mixed images due to glass refraction. Then we build a new dataset with more than 100 types of glass in which obtained transmission images are perfectly aligned with input mixed images. Second, capitalizing on the special relationship between reflection and polarized light, we propose a polarized reflection removal model with a two-stage architecture. In addition, we design a novel perceptual NCC loss that can improve the performance of reflection removal and general image decomposition tasks. We conduct extensive experiments, and results suggest that our model outperforms state-of-the-art methods on reflection removal.
Dual Student: Breaking the Limits of the Teacher in Semi-supervised Learning
Sep 03, 2019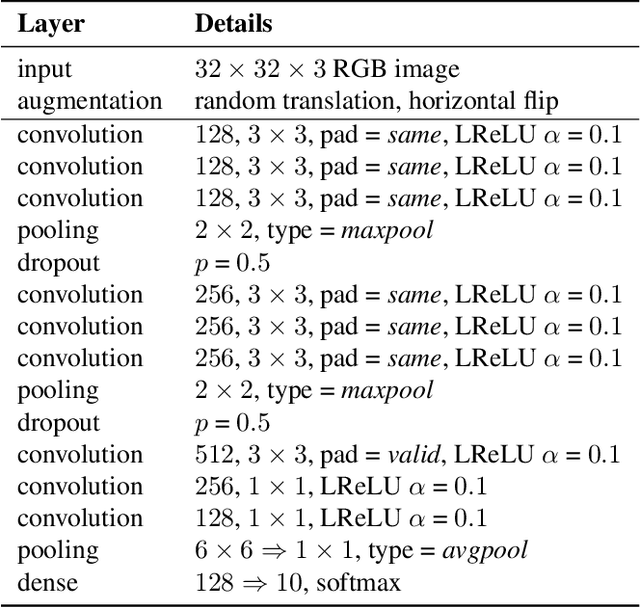

Recently, consistency-based methods have achieved state-of-the-art results in semi-supervised learning (SSL). These methods always involve two roles, an explicit or implicit teacher model and a student model, and penalize predictions under different perturbations by a consistency constraint. However, the weights of these two roles are tightly coupled since the teacher is essentially an exponential moving average (EMA) of the student. In this work, we show that the coupled EMA teacher causes a performance bottleneck. To address this problem, we introduce Dual Student, which replaces the teacher with another student. We also define a novel concept, stable sample, following which a stabilization constraint is designed for our structure to be trainable. Further, we discuss two variants of our method, which produce even higher performance. Extensive experiments show that our method improves the classification performance significantly on several main SSL benchmarks. Specifically, it reduces the error rate of the 13-layer CNN from 16.84% to 12.39% on CIFAR-10 with 1k labels and from 34.10% to 31.56% on CIFAR-100 with 10k labels. In addition, our method also achieves a clear improvement in domain adaptation.