 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIS-Aided Wireless Amodal Sensing for Single-View 3D Reconstruction
Feb 02, 2026Amodal sensing is critical for various real-world sensing applications because it can recover the complete shapes of partially occluded objects in complex environments. Among various amodal sensing paradigms, wireless amodal sensing is a potential solution due to its advantages of environmental robustness, privacy preservation, and low cost. However, the sensing data obtained by wireless system is sparse for shape reconstruction because of the low spatial resolution, and this issue is further intensified in complex environments with occlusion. To address this issue, we propose a Reconfigurable Intelligent Surface (RIS)-aided wireless amodal sensing scheme that leverages a large-scale RIS to enhance the spatial resolution and create reflection paths that can bypass the obstacles. A generative learning model is also employed to reconstruct the complete shape based on the sensing data captured from the viewpoint of the RIS. In such a system, it is challenging to optimize the RIS phase shifts because the relationship between RIS phase shifts and amodal sensing accuracy is complex and the closed-form expression is unknown. To tackle this challenge, we develop an error prediction model that learns the mapping from RIS phase shifts to amodal sensing accuracy, and optimizes RIS phase shifts based on this mapping. Experimental results on the benchmark dataset show that our method achieves at least a 56.73% reduction in reconstruction error compared to conventional schemes under the same number of RIS configurations.
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
Attack-Resistant Watermarking for AIGC Image Forensics via Diffusion-based Semantic Deflection
Jan 10, 2026Protecting the copyright of user-generated AI images is an emerging challenge as AIGC becomes pervasive in creative workflows. Existing watermarking methods (1) remain vulnerable to real-world adversarial threats, often forced to trade off between defenses against spoofing and removal attacks; and (2) cannot support semantic-level tamper localization. We introduce PAI, a training-free inherent watermarking framework for AIGC copyright protection, plug-and-play with diffusion-based AIGC services. PAI simultaneously provides three key functionalities: robust ownership verification, attack detection, and semantic-level tampering localization. Unlike existing inherent watermark methods that only embed watermarks at noise initialization of diffusion models, we design a novel key-conditioned deflection mechanism that subtly steers the denoising trajectory according to the user key. Such trajectory-level coupling further strengthens the semantic entanglement of identity and content, thereby further enhancing robustness against real-world threats. Moreover, we also provide a theoretical analysis proving that only the valid key can pass verification. Experiments across 12 attack methods show that PAI achieves 98.43\% verification accuracy, improving over SOTA methods by 37.25\% on average, and retains strong tampering localization performance even against advanced AIGC edits. Our code is available at https://github.com/QingyuLiu/PAI.
RadioFormer: A Multiple-Granularity Radio Map Estimation Transformer with 1\textpertenthousand Spatial Sampling
Apr 27, 2025The task of radio map estimation aims to generate a dense representation of electromagnetic spectrum quantities, such as the received signal strength at each grid point within a geographic region, based on measurements from a subset of spatially distributed nodes (represented as pixels). Recently, deep vision models such as the U-Net have been adapted to radio map estimation, whose effectiveness can be guaranteed with sufficient spatial observations (typically 0.01% to 1% of pixels) in each map, to model local dependency of observed signal power. However, such a setting of sufficient measurements can be less practical in real-world scenarios, where extreme sparsity in spatial sampling can be widely encountered. To address this challenge, we propose RadioFormer, a novel multiple-granularity transformer designed to handle the constraints posed by spatial sparse observations. Our RadioFormer, through a dual-stream self-attention (DSA) module, can respectively discover the correlation of pixel-wise observed signal power and also learn patch-wise buildings' geometries in a style of multiple granularities, which are integrated into multi-scale representations of radio maps by a cross stream cross-attention (CCA) module. Extensive experiments on the public RadioMapSeer dataset demonstrate that RadioFormer outperforms state-of-the-art methods in radio map estimation while maintaining the lowest computational cost. Furthermore, the proposed approach exhibits exceptional generalization capabilities and robust zero-shot performance, underscoring its potential to advance radio map estimation in a more practical setting with very limited observation nodes.
WiFi-Diffusion: Achieving Fine-Grained WiFi Radio Map Estimation With Ultra-Low Sampling Rate by Diffusion Models
Mar 15, 2025Fine-grained radio map presents communication parameters of interest, e.g., received signal strength, at every point across a large geographical region. It can be leveraged to improve the efficiency of spectrum utilization for a large area, particularly critical for the unlicensed WiFi spectrum. The problem of fine-grained radio map estimation is to utilize radio samples collected by sparsely distributed sensors to infer the map. This problem is challenging due to the ultra-low sampling rate, where the number of available samples is far less than the fine-grained resolution required for radio map estimation. We propose WiFi-Diffusion -- a novel generative framework for achieving fine-grained WiFi radio map estimation using diffusion models. WiFi-Diffusion employs the creative power of generative AI to address the ultra-low sampling rate challenge and consists of three blocks: 1) a boost block, using prior information such as the layout of obstacles to optimize the diffusion model; 2) a generation block, leveraging the diffusion model to generate a candidate set of radio maps; and 3) an election block, utilizing the radio propagation model as a guide to find the best radio map from the candidate set. Extensive simulations demonstrate that 1) the fine-grained radio map generated by WiFi-Diffusion is ten times better than those produced by state-of-the-art (SOTA) when they use the same ultra-low sampling rate; and 2) WiFi-Diffusion achieves comparable fine-grained radio map quality with only one-fifth of the sampling rate required by SOTA.
Simultaneous Beamforming and Anti-Jamming With Intelligent Omni-Surfaces
Feb 04, 2025Wireless transmission is vulnerable to malicious jamming attacks due to the openness of wireless channels, posing a severe threat to wireless communications. Current anti-jamming studies primarily focus on either enhancing desired signals or mitigating jamming, resulting in limited performance. To address this issue, intelligent omni-surface (IOS) is a promising solution. By jointly designing its reflective and refractive properties, the IOS can simultaneously nullify jamming and enhance desired signals. In this paper, we consider an IOS-aided multi-user anti-jamming communication system, aiming to improve desired signals and nullify jamming by optimizing IOS phase shifts and transmit beamforming. However, this is challenging due to the coupled and discrete IOS reflection and refraction phase shifts, the unknown jammer's beamformer, and imperfect jammer-related channel state information. To tackle this, we relax IOS phase shifts to continuous states and optimize with a coupling-aware algorithm using the Cauchy-Schwarz inequality and S-procedure, followed by a local search to recover discrete states. Simulation results show that the proposed scheme significantly improves the sum rate amid jamming attacks.
ICSD: An Open-source Dataset for Infant Cry and Snoring Detection
Aug 20, 2024



The detection and analysis of infant cry and snoring events are crucial tasks within the field of audio signal processing. While existing datasets for general sound event detection are plentiful, they often fall short in providing sufficient, strongly labeled data specific to infant cries and snoring. To provide a benchmark dataset and thus foster the research of infant cry and snoring detection, this paper introduces the Infant Cry and Snoring Detection (ICSD) dataset, a novel, publicly available dataset specially designed for ICSD tasks. The ICSD comprises three types of subsets: a real strongly labeled subset with event-based labels annotated manually, a weakly labeled subset with only clip-level event annotations, and a synthetic subset generated and labeled with strong annotations. This paper provides a detailed description of the ICSD creation process, including the challenges encountered and the solutions adopted. We offer a comprehensive characterization of the dataset, discussing its limitations and key factors for ICSD usage. Additionally, we conduct extensive experiments on the ICSD dataset to establish baseline systems and offer insights into the main factors when using this dataset for ICSD research. Our goal is to develop a dataset that will be widely adopted by the community as a new open benchmark for future ICSD research.
Large Models for Aerial Edges: An Edge-Cloud Model Evolution and Communication Paradigm
Aug 09, 2024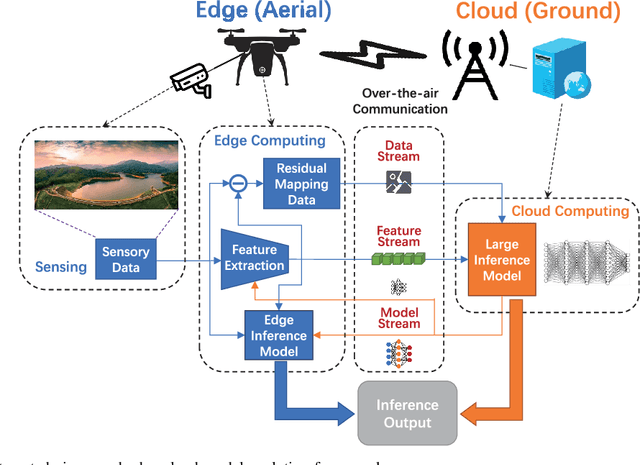
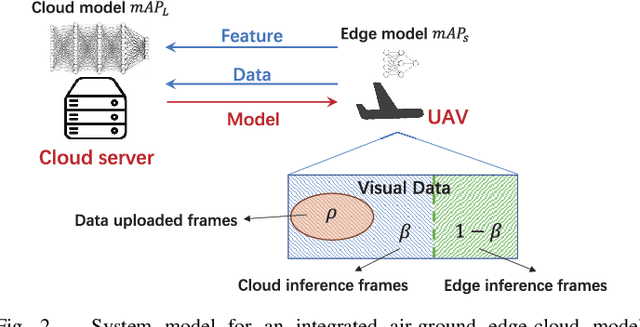
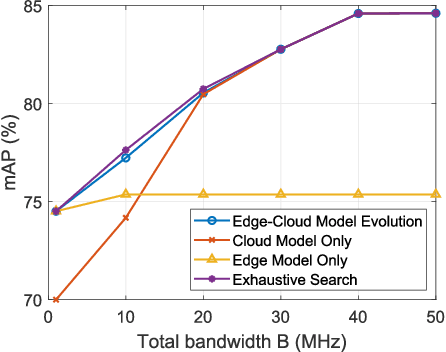
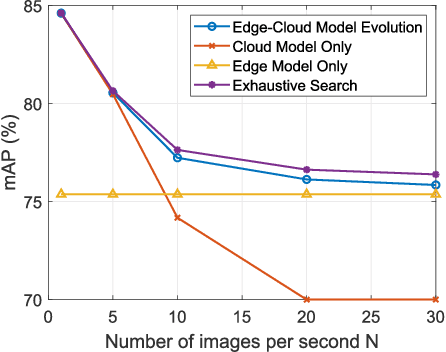
The future sixth-generation (6G) of wireless networks is expected to surpass its predecessors by offering ubiquitous coverage through integrated air-ground facility deployments in both communication and computing domains. In this network, aerial facilities, such as unmanned aerial vehicles (UAVs), conduct artificial intelligence (AI) computations based on multi-modal data to support diverse applications including surveillance and environment construction. However, these multi-domain inference and content generation tasks require large AI models, demanding powerful computing capabilities, thus posing significant challenges for UAVs. To tackle this problem, we propose an integrated edge-cloud model evolution framework, where UAVs serve as edge nodes for data collection and edge model computation. Through wireless channels, UAVs collaborate with ground cloud servers, providing cloud model computation and model updating for edge UAVs. With limited wireless communication bandwidth, the proposed framework faces the challenge of information exchange scheduling between the edge UAVs and the cloud server. To tackle this, we present joint task allocation, transmission resource allocation, transmission data quantization design, and edge model update design to enhance the inference accuracy of the integrated air-ground edge-cloud model evolution framework by mean average precision (mAP) maximization. A closed-form lower bound on the mAP of the proposed framework is derived, and the solution to the mAP maximization problem is optimized accordingly. Simulations, based on results from vision-based classification experiments, consistently demonstrate that the mAP of the proposed framework outperforms both a centralized cloud model framework and a distributed edge model framework across various communication bandwidths and data sizes.
Exposing the Deception: Uncovering More Forgery Clues for Deepfake Detection
Mar 04, 2024



Deepfake technology has given rise to a spectrum of novel and compelling applications. Unfortunately, the widespread proliferation of high-fidelity fake videos has led to pervasive confusion and deception, shattering our faith that seeing is believing. One aspect that has been overlooked so far is that current deepfake detection approaches may easily fall into the trap of overfitting, focusing only on forgery clues within one or a few local regions. Moreover, existing works heavily rely on neural networks to extract forgery features, lacking theoretical constraints guaranteeing that sufficient forgery clues are extracted and superfluous features are eliminated. These deficiencies culminate in unsatisfactory accuracy and limited generalizability in real-life scenarios. In this paper, we try to tackle these challenges through three designs: (1) We present a novel framework to capture broader forgery clues by extracting multiple non-overlapping local representations and fusing them into a global semantic-rich feature. (2) Based on the information bottleneck theory, we derive Local Information Loss to guarantee the orthogonality of local representations while preserving comprehensive task-relevant information. (3) Further, to fuse the local representations and remove task-irrelevant information, we arrive at a Global Information Loss through the theoretical analysis of mutual information. Empirically, our method achieves state-of-the-art performance on five benchmark datasets.Our code is available at \url{https://github.com/QingyuLiu/Exposing-the-Deception}, hoping to inspire researchers.
FLTracer: Accurate Poisoning Attack Provenance in Federated Learning
Oct 20, 2023



Federated Learning (FL) is a promising distributed learning approach that enables multiple clients to collaboratively train a shared global model. However, recent studies show that FL is vulnerable to various poisoning attacks, which can degrade the performance of global models or introduce backdoors into them. In this paper, we first conduct a comprehensive study on prior FL attacks and detection methods. The results show that all existing detection methods are only effective against limited and specific attacks. Most detection methods suffer from high false positives, which lead to significant performance degradation, especially in not independent and identically distributed (non-IID) settings. To address these issues, we propose FLTracer, the first FL attack provenance framework to accurately detect various attacks and trace the attack time, objective, type, and poisoned location of updates. Different from existing methodologies that rely solely on cross-client anomaly detection, we propose a Kalman filter-based cross-round detection to identify adversaries by seeking the behavior changes before and after the attack. Thus, this makes it resilient to data heterogeneity and is effective even in non-IID settings. To further improve the accuracy of our detection method, we employ four novel features and capture their anomalies with the joint decisions. Extensive evaluations show that FLTracer achieves an average true positive rate of over $96.88\%$ at an average false positive rate of less than $2.67\%$, significantly outperforming SOTA detection methods. \footnote{Code is available at \url{https://github.com/Eyr3/FLTracer}.}