 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Alignment Resonant Beam Empowers Beamforming without Estimation and Control for 6G IoT
Dec 09, 2025The integration of communication, sensing, and wireless power transfer (WPT) is a cornerstone of 6G intelligent IoT. However, relying on traditional beamforming imposes prohibitive overheads due to complex channel state information (CSI) estimation and active beam scanning, particularly in dynamic environments. This paper presents a comprehensive review of the radio frequency resonant beam system (RF-RBS), a native physical-layer paradigm that circumvents these limitations. By deploying retro-directive antenna arrays (RAA) at transceivers, RF-RBS establishes a self-sustaining cyclic electromagnetic loop. This mechanism inherently enables self-aligning, high-gain beamforming through positive feedback, eliminating the reliance on digital CSI processing. We analyze the system's architecture and its capability to support high-efficiency WPT, robust communication, and millimeter-level passive positioning. Finally, we evaluate the implementation challenges and strategic value of RF-RBS in latency-sensitive 6G scenarios, including unmanned systems and industrial automation.
OPT-BENCH: Evaluating LLM Agent on Large-Scale Search Spaces Optimization Problems
Jun 12, 2025



Large Language Models (LLMs) have shown remarkable capabilities in solving diverse tasks. However, their proficiency in iteratively optimizing complex solutions through learning from previous feedback remains insufficiently explored. To bridge this gap, we present OPT-BENCH, a comprehensive benchmark designed to evaluate LLM agents on large-scale search space optimization problems. OPT-BENCH includes 20 real-world machine learning tasks sourced from Kaggle and 10 classical NP problems, offering a diverse and challenging environment for assessing LLM agents on iterative reasoning and solution refinement. To enable rigorous evaluation, we introduce OPT-Agent, an end-to-end optimization framework that emulates human reasoning when tackling complex problems by generating, validating, and iteratively improving solutions through leveraging historical feedback. Through extensive experiments on 9 state-of-the-art LLMs from 6 model families, we analyze the effects of optimization iterations, temperature settings, and model architectures on solution quality and convergence. Our results demonstrate that incorporating historical context significantly enhances optimization performance across both ML and NP tasks. All datasets, code, and evaluation tools are open-sourced to promote further research in advancing LLM-driven optimization and iterative reasoning. Project page: \href{https://github.com/OliverLeeXZ/OPT-BENCH}{https://github.com/OliverLeeXZ/OPT-BENCH}.
FDMA-Based Passive Multiple Users SWIPT Utilizing Resonant Beams
May 24, 2025The rapid development of IoT technology has led to a shortage of spectrum resources and energy, giving rise to simultaneous wireless information and power transfer (SWIPT) technology. However, traditional multiple input multiple output (MIMO)-based SWIPT faces challenges in target detection. We have designed a passive multi-user resonant beam system (MU-RBS) that can achieve efficient power transfer and communication through adaptive beam alignment. The frequency division multiple access (FDMA) is employed in the downlink (DL) channel, while frequency conversion is utilized in the uplink (UL) channel to avoid echo interference and co-channel interference, and the system architecture design and corresponding mathematical model are presented. The simulation results show that MU-RBS can achieve adaptive beam-forming without the target transmitting pilot signals, has high directivity, and as the number of iterations increases, the power transmission efficiency, signal-to-noise ratio and spectral efficiency of the UL and DL are continuously optimized until the system reaches the optimal state.
Duplex Self-Aligning Resonant Beam Communications and Power Transfer with Coupled Spatially Distributed Laser Resonator
May 08, 2025



Sustainable energy supply and high-speed communications are two significant needs for mobile electronic devices. This paper introduces a self-aligning resonant beam system for simultaneous light information and power transfer (SLIPT), employing a novel coupled spatially distributed resonator (CSDR). The system utilizes a resonant beam for efficient power delivery and a second-harmonic beam for concurrent data transmission, inherently minimizing echo interference and enabling bidirectional communication. Through comprehensive analyses, we investigate the CSDR's stable region, beam evolution, and power characteristics in relation to working distance and device parameters. Numerical simulations validate the CSDR-SLIPT system's feasibility by identifying a stable beam waist location for achieving accurate mode-match coupling between two spatially distributed resonant cavities and demonstrating its operational range and efficient power delivery across varying distances. The research reveals the system's benefits in terms of both safety and energy transmission efficiency. We also demonstrate the trade-off among the reflectivities of the cavity mirrors in the CSDR. These findings offer valuable design insights for resonant beam systems, advancing SLIPT with significant potential for remote device connectivity.
Squeeze Out Tokens from Sample for Finer-Grained Data Governance
Mar 18, 2025Widely observed data scaling laws, in which error falls off as a power of the training size, demonstrate the diminishing returns of unselective data expansion. Hence, data governance is proposed to downsize datasets through pruning non-informative samples. Yet, isolating the impact of a specific sample on overall model performance is challenging, due to the vast computation required for tryout all sample combinations. Current data governors circumvent this complexity by estimating sample contributions through heuristic-derived scalar scores, thereby discarding low-value ones. Despite thorough sample sieving, retained samples contain substantial undesired tokens intrinsically, underscoring the potential for further compression and purification. In this work, we upgrade data governance from a 'sieving' approach to a 'juicing' one. Instead of scanning for least-flawed samples, our dual-branch DataJuicer applies finer-grained intra-sample governance. It squeezes out informative tokens and boosts image-text alignments. Specifically, the vision branch retains salient image patches and extracts relevant object classes, while the text branch incorporates these classes to enhance captions. Consequently, DataJuicer yields more refined datasets through finer-grained governance. Extensive experiments across datasets demonstrate that DataJuicer significantly outperforms existing DataSieve in image-text retrieval, classification, and dense visual reasoning.
Bursting Filter Bubble: Enhancing Serendipity Recommendations with Aligned Large Language Models
Feb 19, 2025



Recommender systems (RSs) often suffer from the feedback loop phenomenon, e.g., RSs are trained on data biased by their recommendations. This leads to the filter bubble effect that reinforces homogeneous content and reduces user satisfaction. To this end, serendipity recommendations, which offer unexpected yet relevant items, are proposed. Recently, large language models (LLMs) have shown potential in serendipity prediction due to their extensive world knowledge and reasoning capabilities. However, they still face challenges in aligning serendipity judgments with human assessments, handling long user behavior sequences, and meeting the latency requirements of industrial RSs. To address these issues, we propose SERAL (Serendipity Recommendations with Aligned Large Language Models), a framework comprising three stages: (1) Cognition Profile Generation to compress user behavior into multi-level profiles; (2) SerenGPT Alignment to align serendipity judgments with human preferences using enriched training data; and (3) Nearline Adaptation to integrate SerenGPT into industrial RSs pipelines efficiently. Online experiments demonstrate that SERAL improves exposure ratio (PVR), clicks, and transactions of serendipitous items by 5.7%, 29.56%, and 27.6%, enhancing user experience without much impact on overall revenue. Now, it has been fully deployed in the "Guess What You Like" of the Taobao App homepage.
SlimGPT: Layer-wise Structured Pruning for Large Language Models
Dec 24, 2024



Large language models (LLMs) have garnered significant attention for their remarkable capabilities across various domains, whose vast parameter scales present challenges for practical deployment. Structured pruning is an effective method to balance model performance with efficiency, but performance restoration under computational resource constraints is a principal challenge in pruning LLMs. Therefore, we present a low-cost and fast structured pruning method for LLMs named SlimGPT based on the Optimal Brain Surgeon framework. We propose Batched Greedy Pruning for rapid and near-optimal pruning, which enhances the accuracy of head-wise pruning error estimation through grouped Cholesky decomposition and improves the pruning efficiency of FFN via Dynamic Group Size, thereby achieving approximate local optimal pruning results within one hour. Besides, we explore the limitations of layer-wise pruning from the perspective of error accumulation and propose Incremental Pruning Ratio, a non-uniform pruning strategy to reduce performance degradation. Experimental results on the LLaMA benchmark show that SlimGPT outperforms other methods and achieves state-of-the-art results.
Resonant Beam Multi-Target DOA Estimation
Dec 20, 2024With the increasing demand for internet of things (IoT) applications, especially for location-based services, how to locate passive mobile targets (MTs) with minimal beam control has become a challenge. Resonant beam systems are considered promising IoT technologies with advantages such as beam self-alignment and energy concentration. To establish a resonant system in the radio frequency (RF) band and achieve multi-target localization, this paper designs a multi-target resonant system architecture, allowing a single base station (BS) to independently connect with multiple MTs. By employing a retro-directive array, a multi-channel cyclic model is established to realize one-to-many electromagnetic wave propagation and MT direction-of-arrival (DOA) estimation through echo resonance. Simulation results show that the proposed system supports resonant establishment between the BS and multiple MTs. This helps the BS to still have high DOA estimation accuracy in the face of multiple passive MTs, and can ensure that the DOA error is less than 1 degree within a range of 6 meters at a 50degree field of view, with higher accuracy than active beamforming localization systems.
Resonant Beam Enabled Passive 3D Positioning
Dec 20, 2024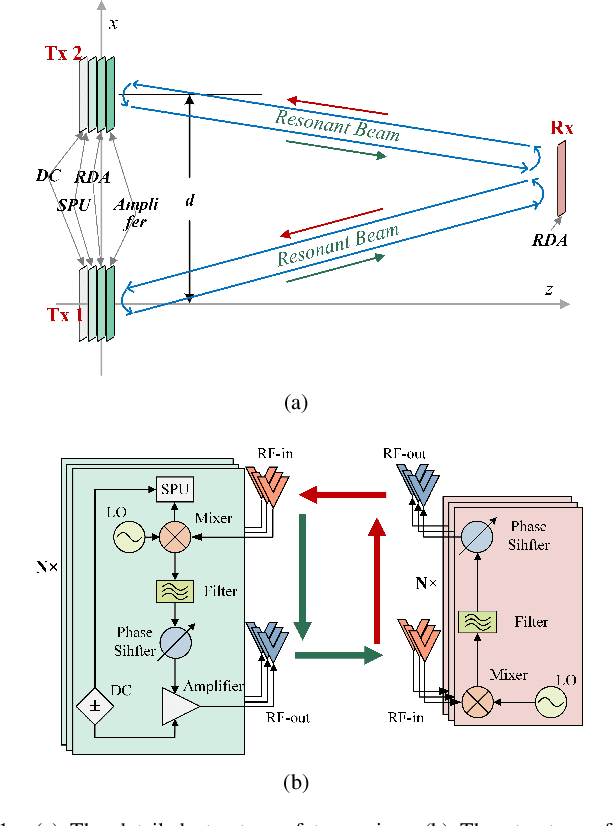
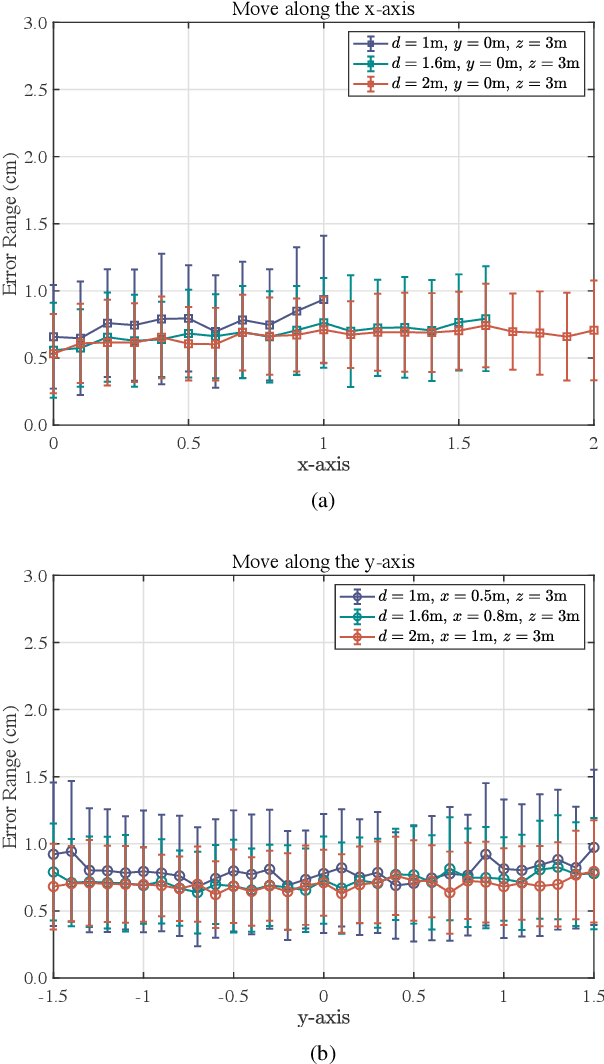
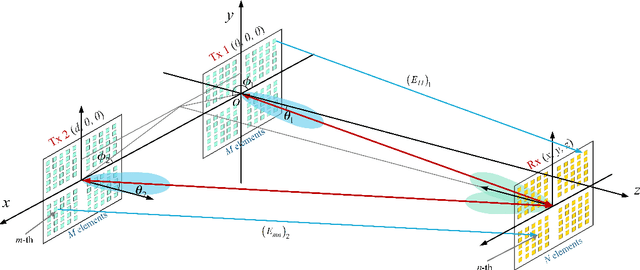
With the rapid development of the internet of things (IoT), location-based services are becoming increasingly prominent in various aspects of social life, and accurate location information is crucial. However, RF-based indoor positioning solutions are severely limited in positioning accuracy due to signal transmission losses and directional difficulties, and optical indoor positioning methods require high propagation conditions. To achieve higher accuracy in indoor positioning, we utilize the principle of resonance to design a triangulation-based resonant beam positioning system (TRBPS) in the RF band. The proposed system employs phase-conjugation antenna arrays and resonance mechanism to achieve energy concentration and beam self-alignment, without requiring active signals from the target for positioning and complex beam control algorithms. Numerical evaluations indicate that TRBPS can achieve millimeter-level accuracy within a range of 3.6 m without the need for additional embedded systems.
Can video generation replace cinematographers? Research on the cinematic language of generated video
Dec 16, 2024



Recent advancements in text-to-video (T2V) generation have leveraged diffusion models to enhance the visual coherence of videos generated from textual descriptions. However, most research has primarily focused on object motion, with limited attention given to cinematic language in videos, which is crucial for cinematographers to convey emotion and narrative pacing. To address this limitation, we propose a threefold approach to enhance the ability of T2V models to generate controllable cinematic language. Specifically, we introduce a cinematic language dataset that encompasses shot framing, angle, and camera movement, enabling models to learn diverse cinematic styles. Building on this, to facilitate robust cinematic alignment evaluation, we present CameraCLIP, a model fine-tuned on the proposed dataset that excels in understanding complex cinematic language in generated videos and can further provide valuable guidance in the multi-shot composition process. Finally, we propose CLIPLoRA, a cost-guided dynamic LoRA composition method that facilitates smooth transitions and realistic blending of cinematic language by dynamically fusing multiple pre-trained cinematic LoRAs within a single video. Our experiments demonstrate that CameraCLIP outperforms existing models in assessing the alignment between cinematic language and video, achieving an R@1 score of 0.81. Additionally, CLIPLoRA improves the ability for multi-shot composition, potentially bridging the gap between automatically generated videos and those shot by professional cinematographers.