 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhy-CoSF: Physics-Guided Continuous Spectral Fields Reconstruction and Super-Resolution for Snapshot Compressive Imaging
May 13, 2026Recent advances have demonstrated that coded aperture snapshot spectral imaging (CASSI) systems show great potential for capturing 3D hyperspectral images (HSIs) from a single 2D measurement. Despite the inherent spectral continuity of scenes captured by CASSI, most existing reconstruction methods are restricted to fixed, discrete spectral outputs, thereby precluding continuous spectral reconstruction or spectral super-resolution. To address this challenge, we propose Phy-CoSF, which synergizes deep unfolding networks with implicit neural representations, establishing a new paradigm for continuous spectral reconstruction and super-resolution in CASSI. Specifically, we propose a two-phase architecture that bridges discrete-wavelength training with continuous spectral rendering, enabling the synthesis of high-fidelity HSIs at arbitrary target wavelengths. At the core of our framework lies the continuous spectral fields (CoSF) module, embedded within each unfolding stage as a dynamic prior, which comprises a triple-branch cross-domain feature mixer for comprehensive spatial-frequency-channel feature fusion, alongside a spectral synthesis head that generates spectral intensities by querying continuous wavelength coordinates. Extensive experimental results demonstrate that Phy-CoSF not only achieves continuous modeling at arbitrary spectral resolutions but also outperforms many state-of-the-art methods in both reconstruction fidelity and spectral detail preservation. Our code and more results are available at: https://github.com/PaiDii/Phy-CoSF.git.
WPGRec: Wavelet Packet Guided Graph Enhanced Sequential Recommendation
Apr 23, 2026Sequential recommendation aims to model users' evolving interests from noisy and non-stationary interaction streams, where long-term preferences, short-term intents, and localized behavioral fluctuations may coexist across temporal scales. Existing frequency-domain methods mainly rely on either global spectral operations or filter-based wavelet processing. However, global spectral operations tend to entangle local transients with long-range dependencies, while filter-based wavelet pipelines may suffer from temporal misalignment and boundary artifacts during multi-scale decomposition and reconstruction. Moreover, collaborative signals from the user-item interaction graph are often injected through scale-inconsistent auxiliary modules, limiting the benefit of jointly modeling temporal dynamics and structural dependencies. To address these issues, we propose Wavelet Packet Guided Graph Enhanced Sequential Recommendation (WPGRec), a unified time-frequency and graph-enhanced framework that aligns multi-resolution temporal modeling with graph propagation at matching scales. WPGRec first applies a full-tree undecimated stationary wavelet packet transform to generate equal-length, shift-invariant subband sequences. It then performs subband-wise interaction-graph propagation to inject high-order collaborative information while preserving temporal alignment across resolutions. Finally, an energy- and spectral-flatness-aware gated fusion module adaptively aggregates informative subbands and suppresses noise-like components. Extensive experiments on four public benchmarks show that WPGRec consistently outperforms sequential and graph-based baselines, with particularly clear gains on sparse and behaviorally complex datasets, highlighting the effectiveness of band-consistent structure injection and adaptive subband fusion for sequential recommendation.
Self-Awareness before Action: Mitigating Logical Inertia via Proactive Cognitive Awareness
Apr 22, 2026Large language models perform well on many reasoning tasks, yet they often lack awareness of whether their current knowledge or reasoning state is complete. In non-interactive puzzle settings, the narrative is fixed and the underlying structure is hidden; once a model forms an early hypothesis under incomplete premises, it can propagate that error throughout the reasoning process, leading to unstable conclusions. To address this issue, we propose SABA, a reasoning framework that explicitly introduces self-awareness of missing premises before making the final decision. SABA formulates reasoning as a recursive process that alternates between structured state construction and obstacle resolution: it first applies Information Fusion to consolidate the narrative into a verifiable base state, and then uses Query-driven Structured Reasoning to identify and resolve missing or underspecified premises by turning them into queries and progressively completing the reasoning state through hypothesis construction and state refinement. Across multiple evaluation metrics, SABA achieves the best performance on all three difficulty splits of the non-interactive Detective Puzzle benchmark, and it also maintains leading results on multiple public benchmarks.
FDMA-Based Passive Multiple Users SWIPT Utilizing Resonant Beams
May 24, 2025The rapid development of IoT technology has led to a shortage of spectrum resources and energy, giving rise to simultaneous wireless information and power transfer (SWIPT) technology. However, traditional multiple input multiple output (MIMO)-based SWIPT faces challenges in target detection. We have designed a passive multi-user resonant beam system (MU-RBS) that can achieve efficient power transfer and communication through adaptive beam alignment. The frequency division multiple access (FDMA) is employed in the downlink (DL) channel, while frequency conversion is utilized in the uplink (UL) channel to avoid echo interference and co-channel interference, and the system architecture design and corresponding mathematical model are presented. The simulation results show that MU-RBS can achieve adaptive beam-forming without the target transmitting pilot signals, has high directivity, and as the number of iterations increases, the power transmission efficiency, signal-to-noise ratio and spectral efficiency of the UL and DL are continuously optimized until the system reaches the optimal state.
A Comprehensive Survey on Physical Risk Control in the Era of Foundation Model-enabled Robotics
May 19, 2025Recent Foundation Model-enabled robotics (FMRs) display greatly improved general-purpose skills, enabling more adaptable automation than conventional robotics. Their ability to handle diverse tasks thus creates new opportunities to replace human labor. However, unlike general foundation models, FMRs interact with the physical world, where their actions directly affect the safety of humans and surrounding objects, requiring careful deployment and control. Based on this proposition, our survey comprehensively summarizes robot control approaches to mitigate physical risks by covering all the lifespan of FMRs ranging from pre-deployment to post-accident stage. Specifically, we broadly divide the timeline into the following three phases: (1) pre-deployment phase, (2) pre-incident phase, and (3) post-incident phase. Throughout this survey, we find that there is much room to study (i) pre-incident risk mitigation strategies, (ii) research that assumes physical interaction with humans, and (iii) essential issues of foundation models themselves. We hope that this survey will be a milestone in providing a high-resolution analysis of the physical risks of FMRs and their control, contributing to the realization of a good human-robot relationship.
Triply Laplacian Scale Mixture Modeling for Seismic Data Noise Suppression
Feb 20, 2025Sparsity-based tensor recovery methods have shown great potential in suppressing seismic data noise. These methods exploit tensor sparsity measures capturing the low-dimensional structures inherent in seismic data tensors to remove noise by applying sparsity constraints through soft-thresholding or hard-thresholding operators. However, in these methods, considering that real seismic data are non-stationary and affected by noise, the variances of tensor coefficients are unknown and may be difficult to accurately estimate from the degraded seismic data, leading to undesirable noise suppression performance. In this paper, we propose a novel triply Laplacian scale mixture (TLSM) approach for seismic data noise suppression, which significantly improves the estimation accuracy of both the sparse tensor coefficients and hidden scalar parameters. To make the optimization problem manageable, an alternating direction method of multipliers (ADMM) algorithm is employed to solve the proposed TLSM-based seismic data noise suppression problem. Extensive experimental results on synthetic and field seismic data demonstrate that the proposed TLSM algorithm outperforms many state-of-the-art seismic data noise suppression methods in both quantitative and qualitative evaluations while providing exceptional computational efficiency.
Resonant Beam Multi-Target DOA Estimation
Dec 20, 2024With the increasing demand for internet of things (IoT) applications, especially for location-based services, how to locate passive mobile targets (MTs) with minimal beam control has become a challenge. Resonant beam systems are considered promising IoT technologies with advantages such as beam self-alignment and energy concentration. To establish a resonant system in the radio frequency (RF) band and achieve multi-target localization, this paper designs a multi-target resonant system architecture, allowing a single base station (BS) to independently connect with multiple MTs. By employing a retro-directive array, a multi-channel cyclic model is established to realize one-to-many electromagnetic wave propagation and MT direction-of-arrival (DOA) estimation through echo resonance. Simulation results show that the proposed system supports resonant establishment between the BS and multiple MTs. This helps the BS to still have high DOA estimation accuracy in the face of multiple passive MTs, and can ensure that the DOA error is less than 1 degree within a range of 6 meters at a 50degree field of view, with higher accuracy than active beamforming localization systems.
Resonant Beam Enabled Passive 3D Positioning
Dec 20, 2024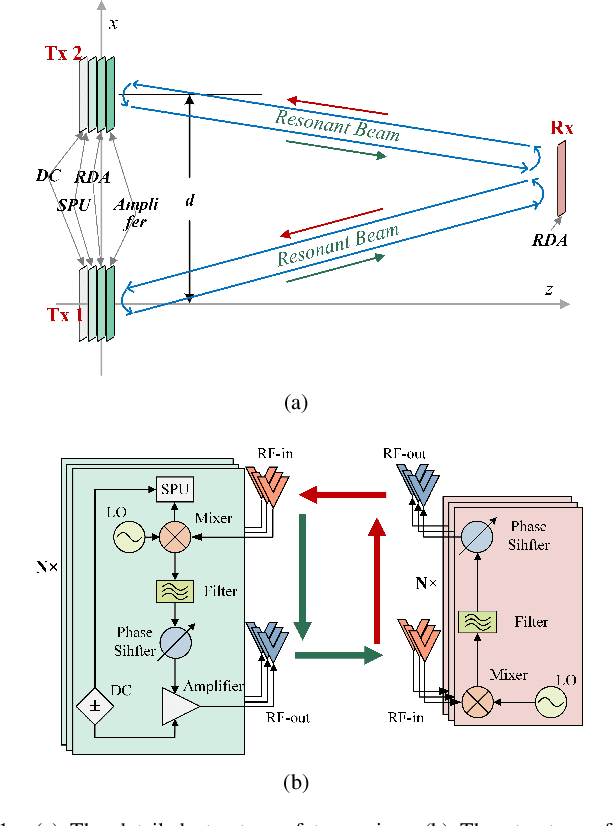
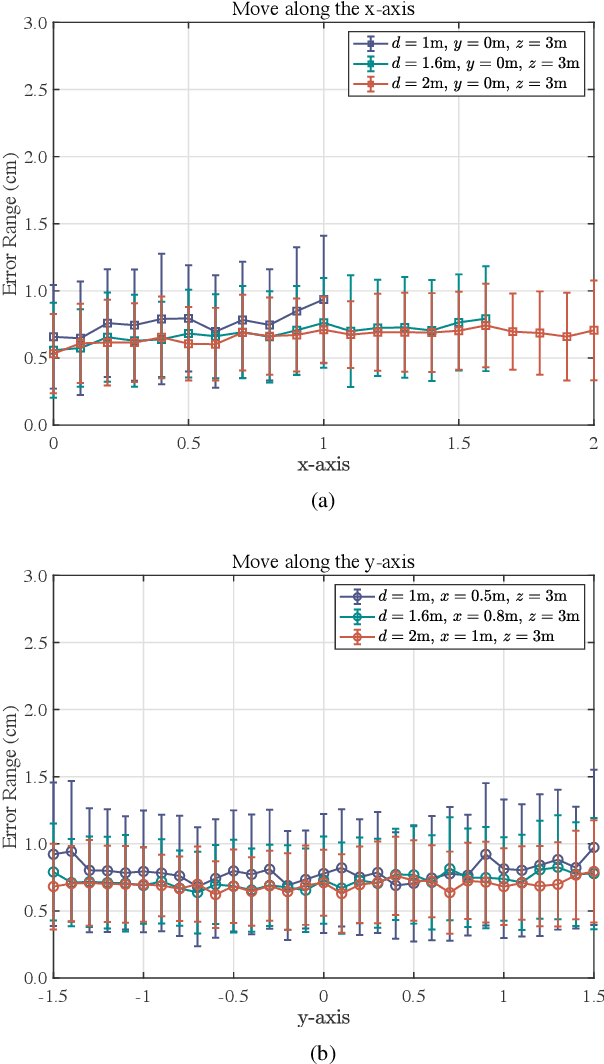
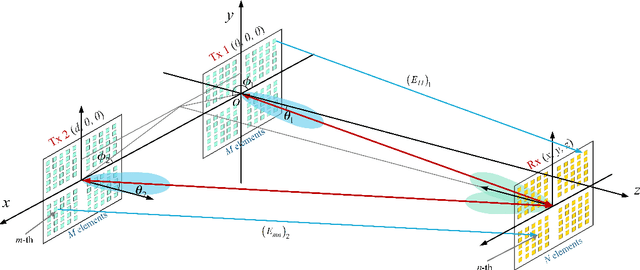
With the rapid development of the internet of things (IoT), location-based services are becoming increasingly prominent in various aspects of social life, and accurate location information is crucial. However, RF-based indoor positioning solutions are severely limited in positioning accuracy due to signal transmission losses and directional difficulties, and optical indoor positioning methods require high propagation conditions. To achieve higher accuracy in indoor positioning, we utilize the principle of resonance to design a triangulation-based resonant beam positioning system (TRBPS) in the RF band. The proposed system employs phase-conjugation antenna arrays and resonance mechanism to achieve energy concentration and beam self-alignment, without requiring active signals from the target for positioning and complex beam control algorithms. Numerical evaluations indicate that TRBPS can achieve millimeter-level accuracy within a range of 3.6 m without the need for additional embedded systems.
See Where You Read with Eye Gaze Tracking and Large Language Model
Sep 28, 2024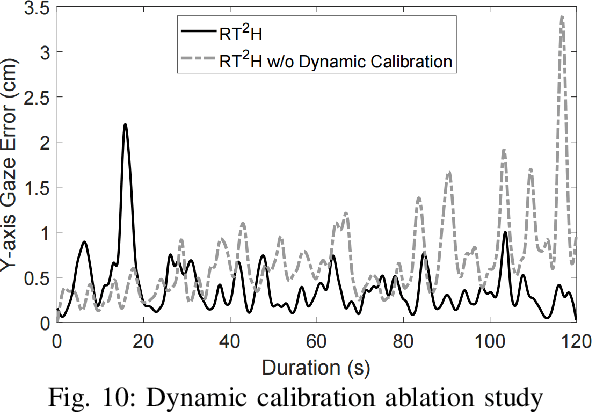

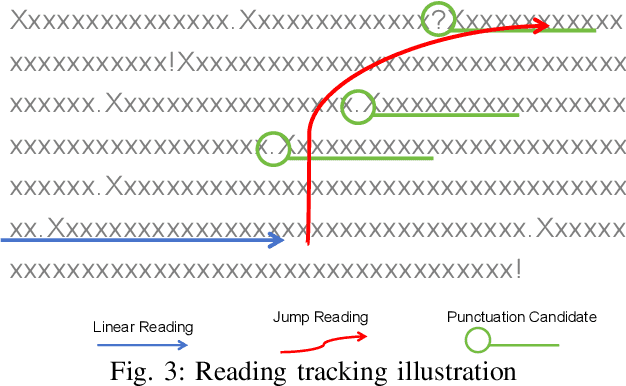
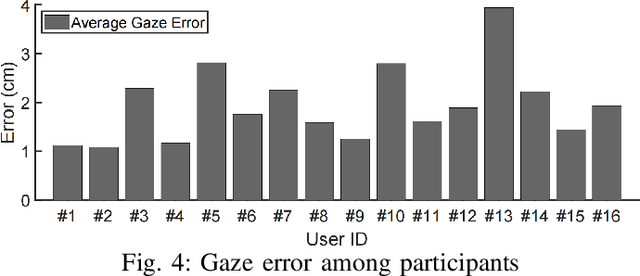
Losing track of reading progress during line switching can be frustrating. Eye gaze tracking technology offers a potential solution by highlighting read paragraphs, aiding users in avoiding wrong line switches. However, the gap between gaze tracking accuracy (2-3 cm) and text line spacing (3-5 mm) makes direct application impractical. Existing methods leverage the linear reading pattern but fail during jump reading. This paper presents a reading tracking and highlighting system that supports both linear and jump reading. Based on experimental insights from the gaze nature study of 16 users, two gaze error models are designed to enable both jump reading detection and relocation. The system further leverages the large language model's contextual perception capability in aiding reading tracking. A reading tracking domain-specific line-gaze alignment opportunity is also exploited to enable dynamic and frequent calibration of the gaze results. Controlled experiments demonstrate reliable linear reading tracking, as well as 84% accuracy in tracking jump reading. Furthermore, real field tests with 18 volunteers demonstrated the system's effectiveness in tracking and highlighting read paragraphs, improving reading efficiency, and enhancing user experience.
Resonant Beam Enabled DoA Estimation in Passive Positioning System
Aug 08, 2024



The rapid advancement of the next generation of communications and internet of things (IoT) technologies has made the provision of location-based services for diverse devices an increasingly pressing necessity. Localizing devices with/without intelligent computing abilities, including both active and passive devices is essential, especially in indoor scenarios. For traditional RF positioning systems, aligning transmission signals and dealing with signal interference in complex environments are inevitable challenges. Therefore, this paper proposed a new passive positioning system, the RF-band resonant beam positioning system (RF-RBPS), which achieves energy concentration and beam alignment by amplifying echoes between the base station (BS) and the passive target (PT), without the need for complex channel estimation and time-consuming beamforming and provides high-precision direction of arrival (DoA) estimation for battery-free targets using the resonant mechanism. The direction information of the PT is estimated using the multiple signal classification (MUSIC) algorithm at the end of BS. The feasibility of the proposed system is validated through theoretical analysis and simulations. Results indicate that the proposed RF-RBPS surpasses RF-band active positioning system (RF-APS) in precision, achieving millimeter-level precision at 2m within an elevation angle of 35$^\circ$, and an error of less than 3cm at 2.5m within an elevation angle of 35$^\circ$.