 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Energy Landscape of Stochastic Dynamical System via Physics-informed Self-supervised Learning
Feb 24, 2025



Energy landscapes play a crucial role in shaping dynamics of many real-world complex systems. System evolution is often modeled as particles moving on a landscape under the combined effect of energy-driven drift and noise-induced diffusion, where the energy governs the long-term motion of the particles. Estimating the energy landscape of a system has been a longstanding interdisciplinary challenge, hindered by the high operational costs or the difficulty of obtaining supervisory signals. Therefore, the question of how to infer the energy landscape in the absence of true energy values is critical. In this paper, we propose a physics-informed self-supervised learning method to learn the energy landscape from the evolution trajectories of the system. It first maps the system state from the observation space to a discrete landscape space by an adaptive codebook, and then explicitly integrates energy into the graph neural Fokker-Planck equation, enabling the joint learning of energy estimation and evolution prediction. Experimental results across interdisciplinary systems demonstrate that our estimated energy has a correlation coefficient above 0.9 with the ground truth, and evolution prediction accuracy exceeds the baseline by an average of 17.65\%. The code is available at github.com/tsinghua-fib-lab/PESLA.
Artificial Intelligence for Complex Network: Potential, Methodology and Application
Feb 23, 2024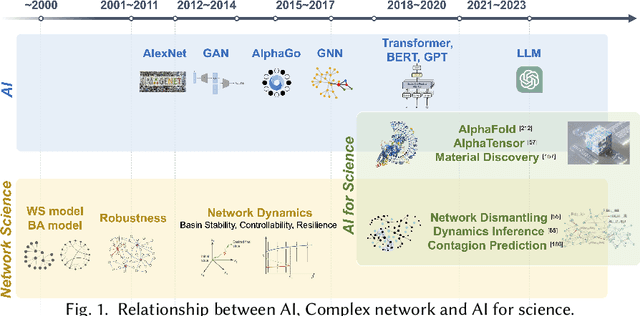
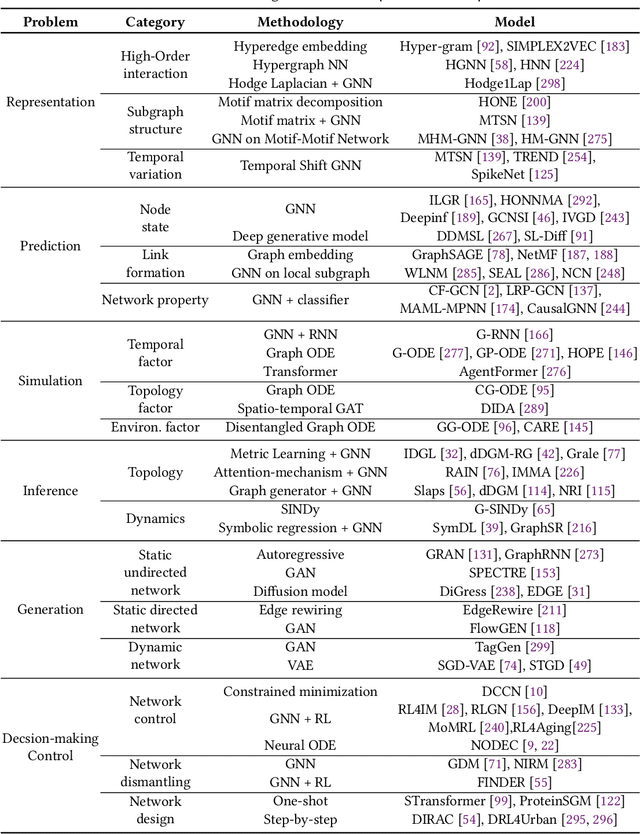
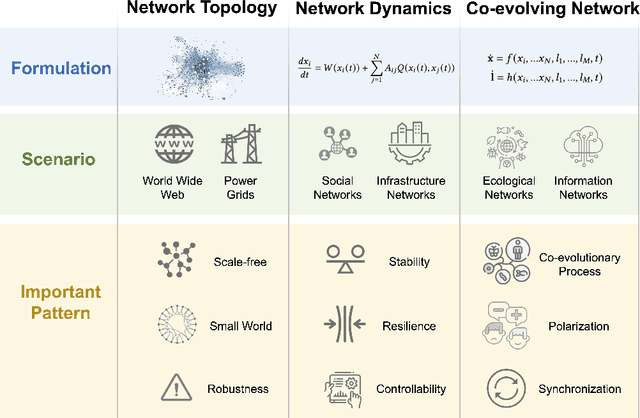
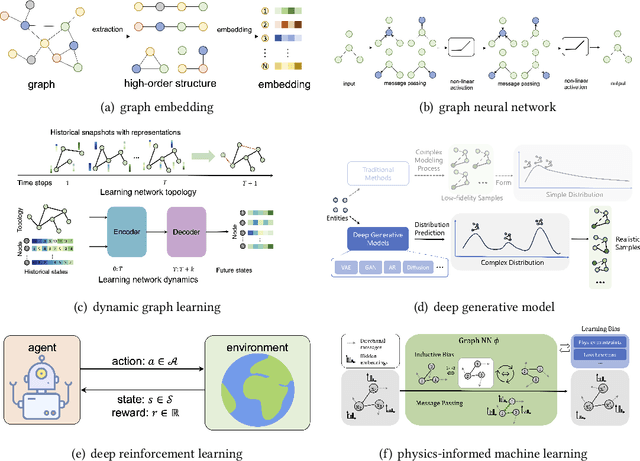
Complex networks pervade various real-world systems, from the natural environment to human societies. The essence of these networks is in their ability to transition and evolve from microscopic disorder-where network topology and node dynamics intertwine-to a macroscopic order characterized by certain collective behaviors. Over the past two decades, complex network science has significantly enhanced our understanding of the statistical mechanics, structures, and dynamics underlying real-world networks. Despite these advancements, there remain considerable challenges in exploring more realistic systems and enhancing practical applications. The emergence of artificial intelligence (AI) technologies, coupled with the abundance of diverse real-world network data, has heralded a new era in complex network science research. This survey aims to systematically address the potential advantages of AI in overcoming the lingering challenges of complex network research. It endeavors to summarize the pivotal research problems and provide an exhaustive review of the corresponding methodologies and applications. Through this comprehensive survey-the first of its kind on AI for complex networks-we expect to provide valuable insights that will drive further research and advancement in this interdisciplinary field.
Diffusion Models for Time Series Applications: A Survey
May 01, 2023
Diffusion models, a family of generative models based on deep learning, have become increasingly prominent in cutting-edge machine learning research. With a distinguished performance in generating samples that resemble the observed data, diffusion models are widely used in image, video, and text synthesis nowadays. In recent years, the concept of diffusion has been extended to time series applications, and many powerful models have been developed. Considering the deficiency of a methodical summary and discourse on these models, we provide this survey as an elementary resource for new researchers in this area and also an inspiration to motivate future research. For better understanding, we include an introduction about the basics of diffusion models. Except for this, we primarily focus on diffusion-based methods for time series forecasting, imputation, and generation, and present them respectively in three individual sections. We also compare different methods for the same application and highlight their connections if applicable. Lastly, we conclude the common limitation of diffusion-based methods and highlight potential future research directions.
Graph Denoising with Framelet Regularizer
Nov 05, 2021
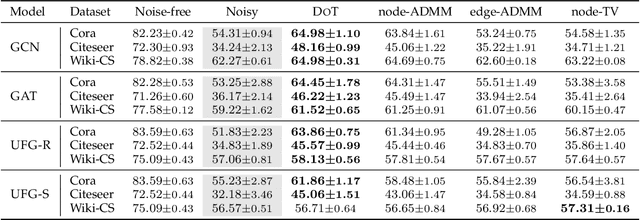
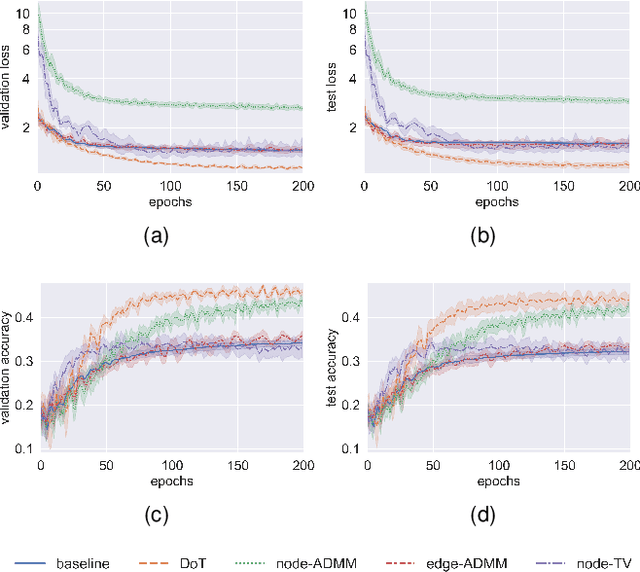
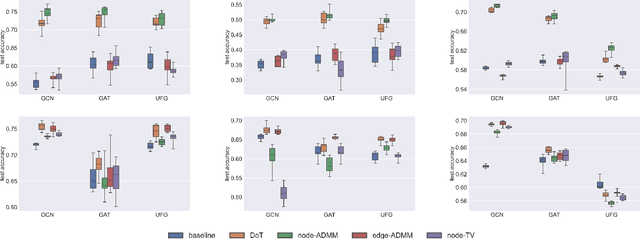
As graph data collected from the real world is merely noise-free, a practical representation of graphs should be robust to noise. Existing research usually focuses on feature smoothing but leaves the geometric structure untouched. Furthermore, most work takes L2-norm that pursues a global smoothness, which limits the expressivity of graph neural networks. This paper tailors regularizers for graph data in terms of both feature and structure noises, where the objective function is efficiently solved with the alternating direction method of multipliers (ADMM). The proposed scheme allows to take multiple layers without the concern of over-smoothing, and it guarantees convergence to the optimal solutions. Empirical study proves that our model achieves significantly better performance compared with popular graph convolutions even when the graph is heavily contaminated.
PartsNet: A Unified Deep Network for Automotive Engine Precision Parts Defect Detection
Oct 29, 2018
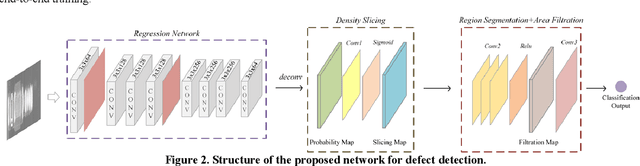
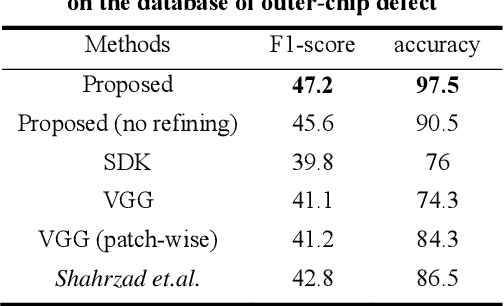
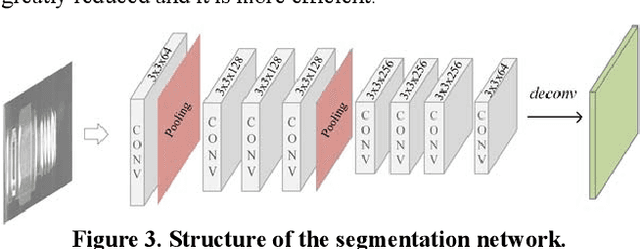
Defect detection is a basic and essential task in automatic parts production, especially for automotive engine precision parts. In this paper, we propose a new idea to construct a deep convolutional network combining related knowledge of feature processing and the representation ability of deep learning. Our algorithm consists of a pixel-wise segmentation Deep Neural Network (DNN) and a feature refining network. The fully convolutional DNN is presented to learn basic features of parts defects. After that, several typical traditional methods which are used to refine the segmentation results are transformed into convolutional manners and integrated. We assemble these methods as a shallow network with fixed weights and empirical thresholds. These thresholds are then released to enhance its adaptation ability and realize end-to-end training. Testing results on different datasets show that the proposed method has good portability and outperforms the state-of-the-art algorithms.