 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a More Generalized Approach in Open Relation Extraction
May 28, 2025Open Relation Extraction (OpenRE) seeks to identify and extract novel relational facts between named entities from unlabeled data without pre-defined relation schemas. Traditional OpenRE methods typically assume that the unlabeled data consists solely of novel relations or is pre-divided into known and novel instances. However, in real-world scenarios, novel relations are arbitrarily distributed. In this paper, we propose a generalized OpenRE setting that considers unlabeled data as a mixture of both known and novel instances. To address this, we propose MixORE, a two-phase framework that integrates relation classification and clustering to jointly learn known and novel relations. Experiments on three benchmark datasets demonstrate that MixORE consistently outperforms competitive baselines in known relation classification and novel relation clustering. Our findings contribute to the advancement of generalized OpenRE research and real-world applications.
AdInject: Real-World Black-Box Attacks on Web Agents via Advertising Delivery
May 27, 2025Vision-Language Model (VLM) based Web Agents represent a significant step towards automating complex tasks by simulating human-like interaction with websites. However, their deployment in uncontrolled web environments introduces significant security vulnerabilities. Existing research on adversarial environmental injection attacks often relies on unrealistic assumptions, such as direct HTML manipulation, knowledge of user intent, or access to agent model parameters, limiting their practical applicability. In this paper, we propose AdInject, a novel and real-world black-box attack method that leverages the internet advertising delivery to inject malicious content into the Web Agent's environment. AdInject operates under a significantly more realistic threat model than prior work, assuming a black-box agent, static malicious content constraints, and no specific knowledge of user intent. AdInject includes strategies for designing malicious ad content aimed at misleading agents into clicking, and a VLM-based ad content optimization technique that infers potential user intents from the target website's context and integrates these intents into the ad content to make it appear more relevant or critical to the agent's task, thus enhancing attack effectiveness. Experimental evaluations demonstrate the effectiveness of AdInject, attack success rates exceeding 60% in most scenarios and approaching 100% in certain cases. This strongly demonstrates that prevalent advertising delivery constitutes a potent and real-world vector for environment injection attacks against Web Agents. This work highlights a critical vulnerability in Web Agent security arising from real-world environment manipulation channels, underscoring the urgent need for developing robust defense mechanisms against such threats. Our code is available at https://github.com/NicerWang/AdInject.
One Shot Dominance: Knowledge Poisoning Attack on Retrieval-Augmented Generation Systems
May 15, 2025Large Language Models (LLMs) enhanced with Retrieval-Augmented Generation (RAG) have shown improved performance in generating accurate responses. However, the dependence on external knowledge bases introduces potential security vulnerabilities, particularly when these knowledge bases are publicly accessible and modifiable. Poisoning attacks on knowledge bases for RAG systems face two fundamental challenges: the injected malicious content must compete with multiple authentic documents retrieved by the retriever, and LLMs tend to trust retrieved information that aligns with their internal memorized knowledge. Previous works attempt to address these challenges by injecting multiple malicious documents, but such saturation attacks are easily detectable and impractical in real-world scenarios. To enable the effective single document poisoning attack, we propose AuthChain, a novel knowledge poisoning attack method that leverages Chain-of-Evidence theory and authority effect to craft more convincing poisoned documents. AuthChain generates poisoned content that establishes strong evidence chains and incorporates authoritative statements, effectively overcoming the interference from both authentic documents and LLMs' internal knowledge. Extensive experiments across six popular LLMs demonstrate that AuthChain achieves significantly higher attack success rates while maintaining superior stealthiness against RAG defense mechanisms compared to state-of-the-art baselines.
Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 Challenge
May 12, 2025We present Task 5 of the DCASE 2025 Challenge: an Audio Question Answering (AQA) benchmark spanning multiple domains of sound understanding. This task defines three QA subsets (Bioacoustics, Temporal Soundscapes, and Complex QA) to test audio-language models on interactive question-answering over diverse acoustic scenes. We describe the dataset composition (from marine mammal calls to soundscapes and complex real-world clips), the evaluation protocol (top-1 accuracy with answer-shuffling robustness), and baseline systems (Qwen2-Audio-7B, AudioFlamingo 2, Gemini-2-Flash). Preliminary results on the development set are compared, showing strong variation across models and subsets. This challenge aims to advance the audio understanding and reasoning capabilities of audio-language models toward human-level acuity, which are crucial for enabling AI agents to perceive and interact about the world effectively.
scDrugMap: Benchmarking Large Foundation Models for Drug Response Prediction
May 08, 2025Drug resistance presents a major challenge in cancer therapy. Single cell profiling offers insights into cellular heterogeneity, yet the application of large-scale foundation models for predicting drug response in single cell data remains underexplored. To address this, we developed scDrugMap, an integrated framework featuring both a Python command-line interface and a web server for drug response prediction. scDrugMap evaluates a wide range of foundation models, including eight single-cell models and two large language models, using a curated dataset of over 326,000 cells in the primary collection and 18,800 cells in the validation set, spanning 36 datasets and diverse tissue and cancer types. We benchmarked model performance under pooled-data and cross-data evaluation settings, employing both layer freezing and Low-Rank Adaptation (LoRA) fine-tuning strategies. In the pooled-data scenario, scFoundation achieved the best performance, with mean F1 scores of 0.971 (layer freezing) and 0.947 (fine-tuning), outperforming the lowest-performing model by over 50%. In the cross-data setting, UCE excelled post fine-tuning (mean F1: 0.774), while scGPT led in zero-shot learning (mean F1: 0.858). Overall, scDrugMap provides the first large-scale benchmark of foundation models for drug response prediction in single-cell data and serves as a user-friendly, flexible platform for advancing drug discovery and translational research.
LODAP: On-Device Incremental Learning Via Lightweight Operations and Data Pruning
Apr 28, 2025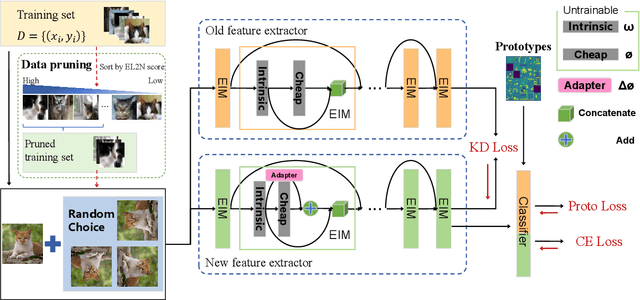
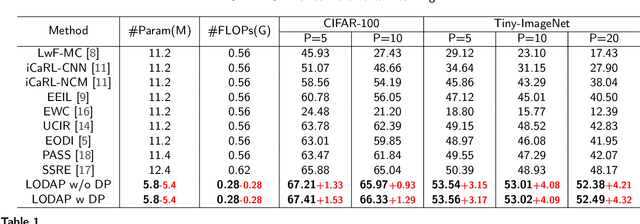
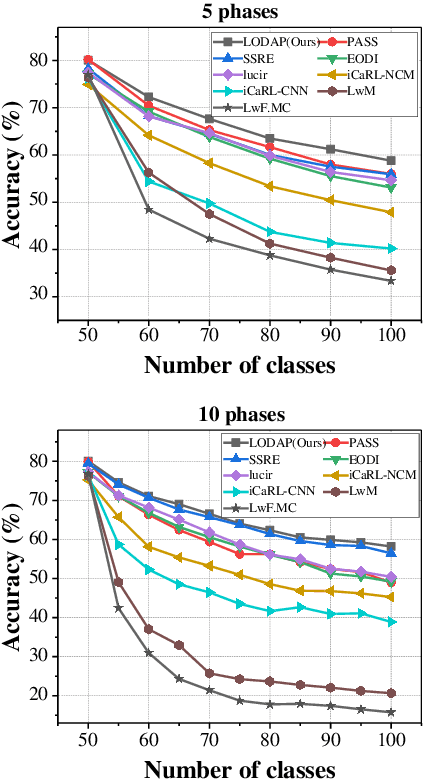
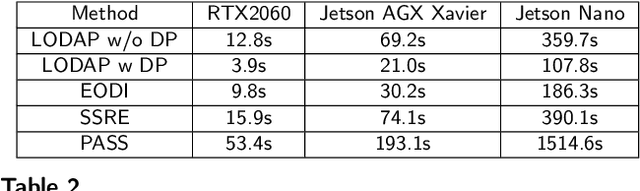
Incremental learning that learns new classes over time after the model's deployment is becoming increasingly crucial, particularly for industrial edge systems, where it is difficult to communicate with a remote server to conduct computation-intensive learning. As more classes are expected to learn after their execution for edge devices. In this paper, we propose LODAP, a new on-device incremental learning framework for edge systems. The key part of LODAP is a new module, namely Efficient Incremental Module (EIM). EIM is composed of normal convolutions and lightweight operations. During incremental learning, EIM exploits some lightweight operations, called adapters, to effectively and efficiently learn features for new classes so that it can improve the accuracy of incremental learning while reducing model complexity as well as training overhead. The efficiency of LODAP is further enhanced by a data pruning strategy that significantly reduces the training data, thereby lowering the training overhead. We conducted extensive experiments on the CIFAR-100 and Tiny- ImageNet datasets. Experimental results show that LODAP improves the accuracy by up to 4.32\% over existing methods while reducing around 50\% of model complexity. In addition, evaluations on real edge systems demonstrate its applicability for on-device machine learning. The code is available at https://github.com/duanbiqing/LODAP.
Improving Significant Wave Height Prediction Using Chronos Models
Apr 23, 2025Accurate wave height prediction is critical for maritime safety and coastal resilience, yet conventional physics-based models and traditional machine learning methods face challenges in computational efficiency and nonlinear dynamics modeling. This study introduces Chronos, the first implementation of a large language model (LLM)-powered temporal architecture (Chronos) optimized for wave forecasting. Through advanced temporal pattern recognition applied to historical wave data from three strategically chosen marine zones in the Northwest Pacific basin, our framework achieves multimodal improvements: (1) 14.3% reduction in training time with 2.5x faster inference speed compared to PatchTST baselines, achieving 0.575 mean absolute scaled error (MASE) units; (2) superior short-term forecasting (1-24h) across comprehensive metrics; (3) sustained predictive leadership in extended-range forecasts (1-120h); and (4) demonstrated zero-shot capability maintaining median performance (rank 4/12) against specialized operational models. This LLM-enhanced temporal modeling paradigm establishes a new standard in wave prediction, offering both computationally efficient solutions and a transferable framework for complex geophysical systems modeling.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
STaR: Seamless Spatial-Temporal Aware Motion Retargeting with Penetration and Consistency Constraints
Apr 09, 2025Motion retargeting seeks to faithfully replicate the spatio-temporal motion characteristics of a source character onto a target character with a different body shape. Apart from motion semantics preservation, ensuring geometric plausibility and maintaining temporal consistency are also crucial for effective motion retargeting. However, many existing methods prioritize either geometric plausibility or temporal consistency. Neglecting geometric plausibility results in interpenetration while neglecting temporal consistency leads to motion jitter. In this paper, we propose a novel sequence-to-sequence model for seamless Spatial-Temporal aware motion Retargeting (STaR), with penetration and consistency constraints. STaR consists of two modules: (1) a spatial module that incorporates dense shape representation and a novel limb penetration constraint to ensure geometric plausibility while preserving motion semantics, and (2) a temporal module that utilizes a temporal transformer and a novel temporal consistency constraint to predict the entire motion sequence at once while enforcing multi-level trajectory smoothness. The seamless combination of the two modules helps us achieve a good balance between the semantic, geometric, and temporal targets. Extensive experiments on the Mixamo and ScanRet datasets demonstrate that our method produces plausible and coherent motions while significantly reducing interpenetration rates compared with other approaches.
HandSplat: Embedding-Driven Gaussian Splatting for High-Fidelity Hand Rendering
Mar 18, 2025



Existing 3D Gaussian Splatting (3DGS) methods for hand rendering rely on rigid skeletal motion with an oversimplified non-rigid motion model, which fails to capture fine geometric and appearance details. Additionally, they perform densification based solely on per-point gradients and process poses independently, ignoring spatial and temporal correlations. These limitations lead to geometric detail loss, temporal instability, and inefficient point distribution. To address these issues, we propose HandSplat, a novel Gaussian Splatting-based framework that enhances both fidelity and stability for hand rendering. To improve fidelity, we extend standard 3DGS attributes with implicit geometry and appearance embeddings for finer non-rigid motion modeling while preserving the static hand characteristic modeled by original 3DGS attributes. Additionally, we introduce a local gradient-aware densification strategy that dynamically refines Gaussian density in high-variation regions. To improve stability, we incorporate pose-conditioned attribute regularization to encourage attribute consistency across similar poses, mitigating temporal artifacts. Extensive experiments on InterHand2.6M demonstrate that HandSplat surpasses existing methods in fidelity and stability while achieving real-time performance. We will release the code and pre-trained models upon acceptance.