 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCTAM: Global and Contextual Truncated Affinity Combined Maximization Model For Unsupervised Graph Anomaly Detection
Mar 02, 2026Anomalies often occur in real-world information networks/graphs, such as malevolent users, malicious comments, banned users, and fake news in social graphs. The latest graph anomaly detection methods use a novel mechanism called truncated affinity maximization (TAM) to detect anomaly nodes without using any label information and achieve impressive results. TAM maximizes the affinities among the normal nodes while truncating the affinities of the anomalous nodes to identify the anomalies. However, existing TAM-based methods truncate suspicious nodes according to a rigid threshold that ignores the specificity and high-order affinities of different nodes. This inevitably causes inefficient truncations from both normal and anomalous nodes, limiting the effectiveness of anomaly detection. To this end, this paper proposes a novel truncation model combining contextual and global affinity to truncate the anomalous nodes. The core idea of the work is to use contextual truncation to decrease the affinity of anomalous nodes, while global truncation increases the affinity of normal nodes. Extensive experiments on massive real-world datasets show that our method surpasses peer methods in most graph anomaly detection tasks. In highlights, compared with previous state-of-the-art methods, the proposed method has +15\% $\sim$ +20\% improvements in two famous real-world datasets, Amazon and YelpChi. Notably, our method works well in large datasets, Amazin-all and YelpChi-all, and achieves the best results, while most previous models cannot complete the tasks.
LODAP: On-Device Incremental Learning Via Lightweight Operations and Data Pruning
Apr 28, 2025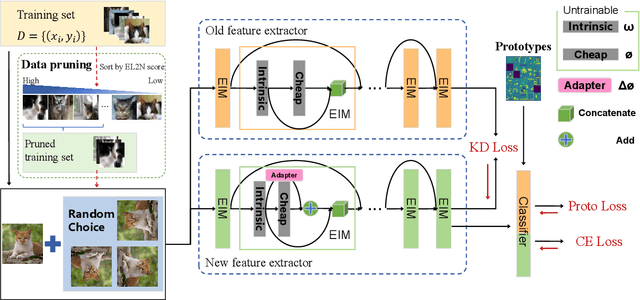
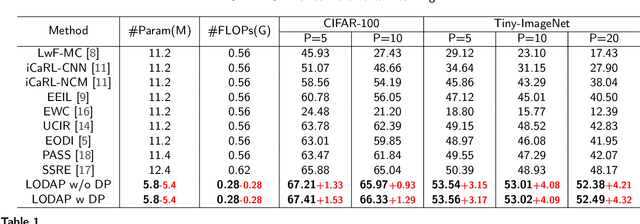
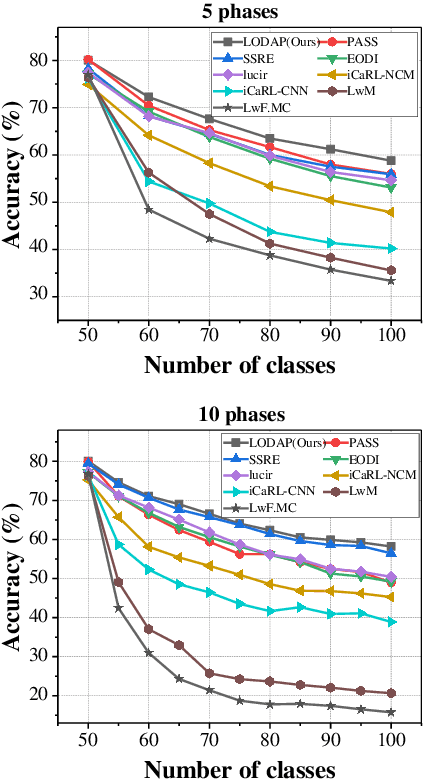
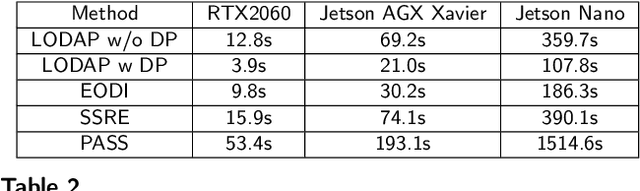
Incremental learning that learns new classes over time after the model's deployment is becoming increasingly crucial, particularly for industrial edge systems, where it is difficult to communicate with a remote server to conduct computation-intensive learning. As more classes are expected to learn after their execution for edge devices. In this paper, we propose LODAP, a new on-device incremental learning framework for edge systems. The key part of LODAP is a new module, namely Efficient Incremental Module (EIM). EIM is composed of normal convolutions and lightweight operations. During incremental learning, EIM exploits some lightweight operations, called adapters, to effectively and efficiently learn features for new classes so that it can improve the accuracy of incremental learning while reducing model complexity as well as training overhead. The efficiency of LODAP is further enhanced by a data pruning strategy that significantly reduces the training data, thereby lowering the training overhead. We conducted extensive experiments on the CIFAR-100 and Tiny- ImageNet datasets. Experimental results show that LODAP improves the accuracy by up to 4.32\% over existing methods while reducing around 50\% of model complexity. In addition, evaluations on real edge systems demonstrate its applicability for on-device machine learning. The code is available at https://github.com/duanbiqing/LODAP.