 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a More Generalized Approach in Open Relation Extraction
May 28, 2025Open Relation Extraction (OpenRE) seeks to identify and extract novel relational facts between named entities from unlabeled data without pre-defined relation schemas. Traditional OpenRE methods typically assume that the unlabeled data consists solely of novel relations or is pre-divided into known and novel instances. However, in real-world scenarios, novel relations are arbitrarily distributed. In this paper, we propose a generalized OpenRE setting that considers unlabeled data as a mixture of both known and novel instances. To address this, we propose MixORE, a two-phase framework that integrates relation classification and clustering to jointly learn known and novel relations. Experiments on three benchmark datasets demonstrate that MixORE consistently outperforms competitive baselines in known relation classification and novel relation clustering. Our findings contribute to the advancement of generalized OpenRE research and real-world applications.
Bridge: A Unified Framework to Knowledge Graph Completion via Language Models and Knowledge Representation
Nov 11, 2024Knowledge graph completion (KGC) is a task of inferring missing triples based on existing Knowledge Graphs (KGs). Both structural and semantic information are vital for successful KGC. However, existing methods only use either the structural knowledge from the KG embeddings or the semantic information from pre-trained language models (PLMs), leading to suboptimal model performance. Moreover, since PLMs are not trained on KGs, directly using PLMs to encode triples may be inappropriate. To overcome these limitations, we propose a novel framework called Bridge, which jointly encodes structural and semantic information of KGs. Specifically, we strategically encode entities and relations separately by PLMs to better utilize the semantic knowledge of PLMs and enable structured representation learning via a structural learning principle. Furthermore, to bridge the gap between KGs and PLMs, we employ a self-supervised representation learning method called BYOL to fine-tune PLMs with two different views of a triple. Unlike BYOL, which uses augmentation methods to create two semantically similar views of the same image, potentially altering the semantic information. We strategically separate the triple into two parts to create different views, thus avoiding semantic alteration. Experiments demonstrate that Bridge outperforms the SOTA models on three benchmark datasets.
Investigating Context-Faithfulness in Large Language Models: The Roles of Memory Strength and Evidence Style
Sep 17, 2024



Retrieval-augmented generation (RAG) improves Large Language Models (LLMs) by incorporating external information into the response generation process. However, how context-faithful LLMs are and what factors influence LLMs' context-faithfulness remain largely unexplored. In this study, we investigate the impact of memory strength and evidence presentation on LLMs' receptiveness to external evidence. We introduce a method to quantify the memory strength of LLMs by measuring the divergence in LLMs' responses to different paraphrases of the same question, which is not considered by previous works. We also generate evidence in various styles to evaluate the effects of evidence in different styles. Two datasets are used for evaluation: Natural Questions (NQ) with popular questions and popQA featuring long-tail questions. Our results show that for questions with high memory strength, LLMs are more likely to rely on internal memory, particularly for larger LLMs such as GPT-4. On the other hand, presenting paraphrased evidence significantly increases LLMs' receptiveness compared to simple repetition or adding details.
Re-Examine Distantly Supervised NER: A New Benchmark and a Simple Approach
Feb 26, 2024



This paper delves into Named Entity Recognition (NER) under the framework of Distant Supervision (DS-NER), where the main challenge lies in the compromised quality of labels due to inherent errors such as false positives, false negatives, and positive type errors. We critically assess the efficacy of current DS-NER methodologies using a real-world benchmark dataset named QTL, revealing that their performance often does not meet expectations. To tackle the prevalent issue of label noise, we introduce a simple yet effective approach, Curriculum-based Positive-Unlabeled Learning CuPUL, which strategically starts on "easy" and cleaner samples during the training process to enhance model resilience to noisy samples. Our empirical results highlight the capability of CuPUL to significantly reduce the impact of noisy labels and outperform existing methods. QTL dataset and our code is available on GitHub.
Improving Unsupervised Relation Extraction by Augmenting Diverse Sentence Pairs
Dec 01, 2023



Unsupervised relation extraction (URE) aims to extract relations between named entities from raw text without requiring manual annotations or pre-existing knowledge bases. In recent studies of URE, researchers put a notable emphasis on contrastive learning strategies for acquiring relation representations. However, these studies often overlook two important aspects: the inclusion of diverse positive pairs for contrastive learning and the exploration of appropriate loss functions. In this paper, we propose AugURE with both within-sentence pairs augmentation and augmentation through cross-sentence pairs extraction to increase the diversity of positive pairs and strengthen the discriminative power of contrastive learning. We also identify the limitation of noise-contrastive estimation (NCE) loss for relation representation learning and propose to apply margin loss for sentence pairs. Experiments on NYT-FB and TACRED datasets demonstrate that the proposed relation representation learning and a simple K-Means clustering achieves state-of-the-art performance.
Relation-Aware Network with Attention-Based Loss for Few-Shot Knowledge Graph Completion
Jun 15, 2023Few-shot knowledge graph completion (FKGC) task aims to predict unseen facts of a relation with few-shot reference entity pairs. Current approaches randomly select one negative sample for each reference entity pair to minimize a margin-based ranking loss, which easily leads to a zero-loss problem if the negative sample is far away from the positive sample and then out of the margin. Moreover, the entity should have a different representation under a different context. To tackle these issues, we propose a novel Relation-Aware Network with Attention-Based Loss (RANA) framework. Specifically, to better utilize the plentiful negative samples and alleviate the zero-loss issue, we strategically select relevant negative samples and design an attention-based loss function to further differentiate the importance of each negative sample. The intuition is that negative samples more similar to positive samples will contribute more to the model. Further, we design a dynamic relation-aware entity encoder for learning a context-dependent entity representation. Experiments demonstrate that RANA outperforms the state-of-the-art models on two benchmark datasets.
Improving Distantly Supervised Relation Extraction by Natural Language Inference
Jul 31, 2022
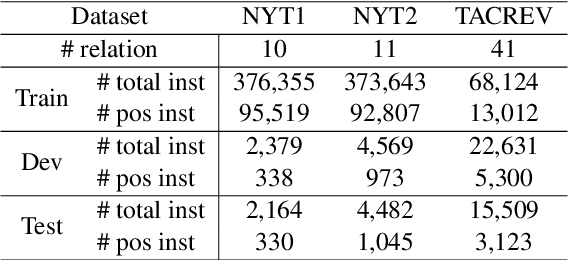
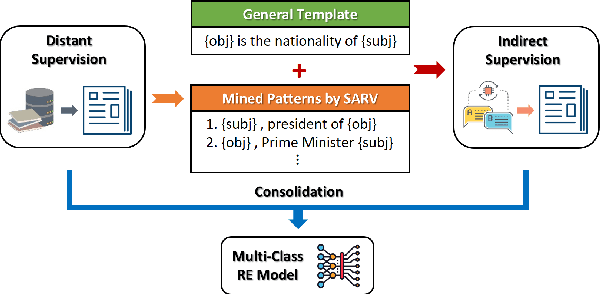
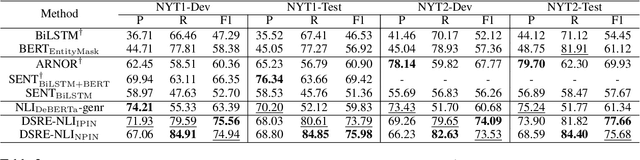
To reduce human annotations for relation extraction (RE) tasks, distantly supervised approaches have been proposed, while struggling with low performance. In this work, we propose a novel DSRE-NLI framework, which considers both distant supervision from existing knowledge bases and indirect supervision from pretrained language models for other tasks. DSRE-NLI energizes an off-the-shelf natural language inference (NLI) engine with a semi-automatic relation verbalization (SARV) mechanism to provide indirect supervision and further consolidates the distant annotations to benefit multi-classification RE models. The NLI-based indirect supervision acquires only one relation verbalization template from humans as a semantically general template for each relationship, and then the template set is enriched by high-quality textual patterns automatically mined from the distantly annotated corpus. With two simple and effective data consolidation strategies, the quality of training data is substantially improved. Extensive experiments demonstrate that the proposed framework significantly improves the SOTA performance (up to 7.73\% of F1) on distantly supervised RE benchmark datasets.