 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulSeek: Exploring the Use of Social Cues in LLM-based Information Seeking
Jan 03, 2026Social cues, which convey others' presence, behaviors, or identities, play a crucial role in human information seeking by helping individuals judge relevance and trustworthiness. However, existing LLM-based search systems primarily rely on semantic features, creating a misalignment with the socialized cognition underlying natural information seeking. To address this gap, we explore how the integration of social cues into LLM-based search influences users' perceptions, experiences, and behaviors. Focusing on social media platforms that are beginning to adopt LLM-based search, we integrate design workshops, the implementation of the prototype system (SoulSeek), a between-subjects study, and mixed-method analyses to examine both outcome- and process-level findings. The workshop informs the prototype's cue-integrated design. The study shows that social cues improve perceived outcomes and experiences, promote reflective information behaviors, and reveal limits of current LLM-based search. We propose design implications emphasizing better social-knowledge understanding, personalized cue settings, and controllable interactions.
Unleashing the Potential of Model Bias for Generalized Category Discovery
Dec 17, 2024



Generalized Category Discovery is a significant and complex task that aims to identify both known and undefined novel categories from a set of unlabeled data, leveraging another labeled dataset containing only known categories. The primary challenges stem from model bias induced by pre-training on only known categories and the lack of precise supervision for novel ones, leading to category bias towards known categories and category confusion among different novel categories, which hinders models' ability to identify novel categories effectively. To address these challenges, we propose a novel framework named Self-Debiasing Calibration (SDC). Unlike prior methods that regard model bias towards known categories as an obstacle to novel category identification, SDC provides a novel insight into unleashing the potential of the bias to facilitate novel category learning. Specifically, the output of the biased model serves two key purposes. First, it provides an accurate modeling of category bias, which can be utilized to measure the degree of bias and debias the output of the current training model. Second, it offers valuable insights for distinguishing different novel categories by transferring knowledge between similar categories. Based on these insights, SDC dynamically adjusts the output logits of the current training model using the output of the biased model. This approach produces less biased logits to effectively address the issue of category bias towards known categories, and generates more accurate pseudo labels for unlabeled data, thereby mitigating category confusion for novel categories. Experiments on three benchmark datasets show that SDC outperforms SOTA methods, especially in the identification of novel categories. Our code and data are available at \url{https://github.com/Lackel/SDC}.
Schedule Your Edit: A Simple yet Effective Diffusion Noise Schedule for Image Editing
Oct 24, 2024



Text-guided diffusion models have significantly advanced image editing, enabling high-quality and diverse modifications driven by text prompts. However, effective editing requires inverting the source image into a latent space, a process often hindered by prediction errors inherent in DDIM inversion. These errors accumulate during the diffusion process, resulting in inferior content preservation and edit fidelity, especially with conditional inputs. We address these challenges by investigating the primary contributors to error accumulation in DDIM inversion and identify the singularity problem in traditional noise schedules as a key issue. To resolve this, we introduce the Logistic Schedule, a novel noise schedule designed to eliminate singularities, improve inversion stability, and provide a better noise space for image editing. This schedule reduces noise prediction errors, enabling more faithful editing that preserves the original content of the source image. Our approach requires no additional retraining and is compatible with various existing editing methods. Experiments across eight editing tasks demonstrate the Logistic Schedule's superior performance in content preservation and edit fidelity compared to traditional noise schedules, highlighting its adaptability and effectiveness.
Flipped Classroom: Aligning Teacher Attention with Student in Generalized Category Discovery
Sep 29, 2024



Recent advancements have shown promise in applying traditional Semi-Supervised Learning strategies to the task of Generalized Category Discovery (GCD). Typically, this involves a teacher-student framework in which the teacher imparts knowledge to the student to classify categories, even in the absence of explicit labels. Nevertheless, GCD presents unique challenges, particularly the absence of priors for new classes, which can lead to the teacher's misguidance and unsynchronized learning with the student, culminating in suboptimal outcomes. In our work, we delve into why traditional teacher-student designs falter in open-world generalized category discovery as compared to their success in closed-world semi-supervised learning. We identify inconsistent pattern learning across attention layers as the crux of this issue and introduce FlipClass, a method that dynamically updates the teacher to align with the student's attention, instead of maintaining a static teacher reference. Our teacher-student attention alignment strategy refines the teacher's focus based on student feedback from an energy perspective, promoting consistent pattern recognition and synchronized learning across old and new classes. Extensive experiments on a spectrum of benchmarks affirm that FlipClass significantly surpasses contemporary GCD methods, establishing new standards for the field.
4DHands: Reconstructing Interactive Hands in 4D with Transformers
May 31, 2024In this paper, we introduce 4DHands, a robust approach to recovering interactive hand meshes and their relative movement from monocular inputs. Our approach addresses two major limitations of previous methods: lacking a unified solution for handling various hand image inputs and neglecting the positional relationship of two hands within images. To overcome these challenges, we develop a transformer-based architecture with novel tokenization and feature fusion strategies. Specifically, we propose a Relation-aware Two-Hand Tokenization (RAT) method to embed positional relation information into the hand tokens. In this way, our network can handle both single-hand and two-hand inputs and explicitly leverage relative hand positions, facilitating the reconstruction of intricate hand interactions in real-world scenarios. As such tokenization indicates the relative relationship of two hands, it also supports more effective feature fusion. To this end, we further develop a Spatio-temporal Interaction Reasoning (SIR) module to fuse hand tokens in 4D with attention and decode them into 3D hand meshes and relative temporal movements. The efficacy of our approach is validated on several benchmark datasets. The results on in-the-wild videos and real-world scenarios demonstrate the superior performances of our approach for interactive hand reconstruction. More video results can be found on the project page: https://4dhands.github.io.
DreamSalon: A Staged Diffusion Framework for Preserving Identity-Context in Editable Face Generation
Mar 28, 2024While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centered images, novel challenges arise with a nuanced task of "identity fine editing": precisely modifying specific features of a subject while maintaining its inherent identity and context. Existing personalization methods either require time-consuming optimization or learning additional encoders, adept in "identity re-contextualization". However, they often struggle with detailed and sensitive tasks like human face editing. To address these challenges, we introduce DreamSalon, a noise-guided, staged-editing framework, uniquely focusing on detailed image manipulations and identity-context preservation. By discerning editing and boosting stages via the frequency and gradient of predicted noises, DreamSalon first performs detailed manipulations on specific features in the editing stage, guided by high-frequency information, and then employs stochastic denoising in the boosting stage to improve image quality. For more precise editing, DreamSalon semantically mixes source and target textual prompts, guided by differences in their embedding covariances, to direct the model's focus on specific manipulation areas. Our experiments demonstrate DreamSalon's ability to efficiently and faithfully edit fine details on human faces, outperforming existing methods both qualitatively and quantitatively.
Transfer and Alignment Network for Generalized Category Discovery
Dec 27, 2023



Generalized Category Discovery is a crucial real-world task. Despite the improved performance on known categories, current methods perform poorly on novel categories. We attribute the poor performance to two reasons: biased knowledge transfer between labeled and unlabeled data and noisy representation learning on the unlabeled data. To mitigate these two issues, we propose a Transfer and Alignment Network (TAN), which incorporates two knowledge transfer mechanisms to calibrate the biased knowledge and two feature alignment mechanisms to learn discriminative features. Specifically, we model different categories with prototypes and transfer the prototypes in labeled data to correct model bias towards known categories. On the one hand, we pull instances with known categories in unlabeled data closer to these prototypes to form more compact clusters and avoid boundary overlap between known and novel categories. On the other hand, we use these prototypes to calibrate noisy prototypes estimated from unlabeled data based on category similarities, which allows for more accurate estimation of prototypes for novel categories that can be used as reliable learning targets later. After knowledge transfer, we further propose two feature alignment mechanisms to acquire both instance- and category-level knowledge from unlabeled data by aligning instance features with both augmented features and the calibrated prototypes, which can boost model performance on both known and novel categories with less noise. Experiments on three benchmark datasets show that our model outperforms SOTA methods, especially on novel categories. Theoretical analysis is provided for an in-depth understanding of our model in general. Our code and data are available at https://github.com/Lackel/TAN.
MatchVIE: Exploiting Match Relevancy between Entities for Visual Information Extraction
Jun 24, 2021
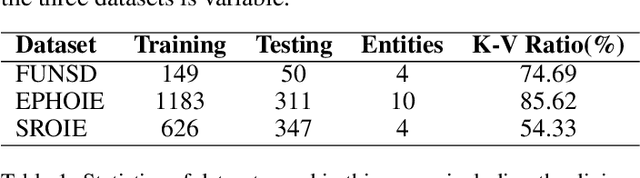
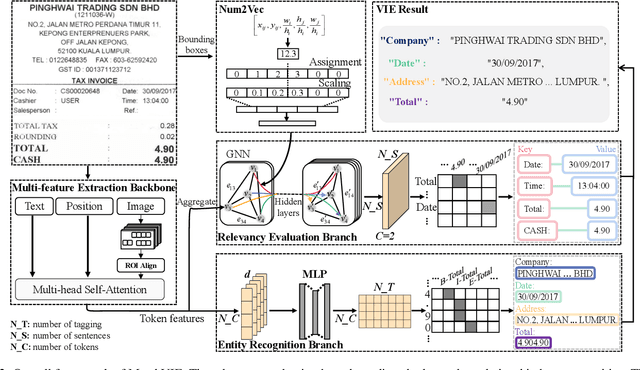
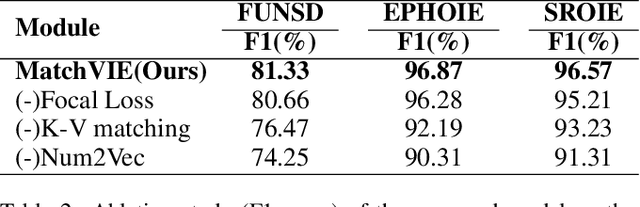
Visual Information Extraction (VIE) task aims to extract key information from multifarious document images (e.g., invoices and purchase receipts). Most previous methods treat the VIE task simply as a sequence labeling problem or classification problem, which requires models to carefully identify each kind of semantics by introducing multimodal features, such as font, color, layout. But simply introducing multimodal features couldn't work well when faced with numeric semantic categories or some ambiguous texts. To address this issue, in this paper we propose a novel key-value matching model based on a graph neural network for VIE (MatchVIE). Through key-value matching based on relevancy evaluation, the proposed MatchVIE can bypass the recognitions to various semantics, and simply focuses on the strong relevancy between entities. Besides, we introduce a simple but effective operation, Num2Vec, to tackle the instability of encoded values, which helps model converge more smoothly. Comprehensive experiments demonstrate that the proposed MatchVIE can significantly outperform previous methods. Notably, to the best of our knowledge, MatchVIE may be the first attempt to tackle the VIE task by modeling the relevancy between keys and values and it is a good complement to the existing methods.
Towards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution
Jan 24, 2021

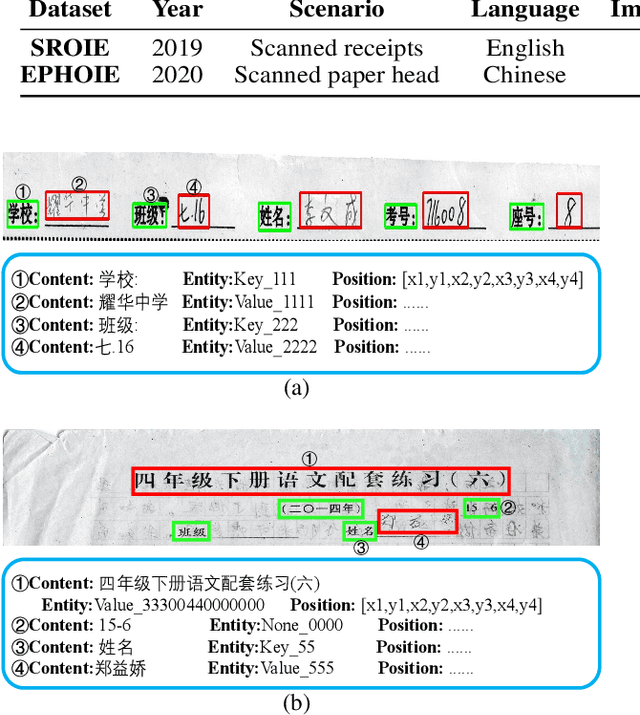
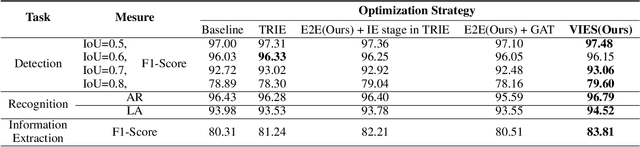
Visual information extraction (VIE) has attracted considerable attention recently owing to its various advanced applications such as document understanding, automatic marking and intelligent education. Most existing works decoupled this problem into several independent sub-tasks of text spotting (text detection and recognition) and information extraction, which completely ignored the high correlation among them during optimization. In this paper, we propose a robust visual information extraction system (VIES) towards real-world scenarios, which is a unified end-to-end trainable framework for simultaneous text detection, recognition and information extraction by taking a single document image as input and outputting the structured information. Specifically, the information extraction branch collects abundant visual and semantic representations from text spotting for multimodal feature fusion and conversely, provides higher-level semantic clues to contribute to the optimization of text spotting. Moreover, regarding the shortage of public benchmarks, we construct a fully-annotated dataset called EPHOIE (https://github.com/HCIILAB/EPHOIE), which is the first Chinese benchmark for both text spotting and visual information extraction. EPHOIE consists of 1,494 images of examination paper head with complex layouts and background, including a total of 15,771 Chinese handwritten or printed text instances. Compared with the state-of-the-art methods, our VIES shows significant superior performance on the EPHOIE dataset and achieves a 9.01% F-score gain on the widely used SROIE dataset under the end-to-end scenario.
Decoupled Attention Network for Text Recognition
Dec 21, 2019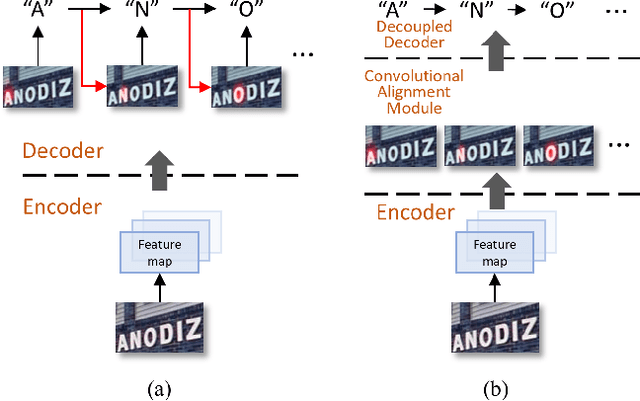
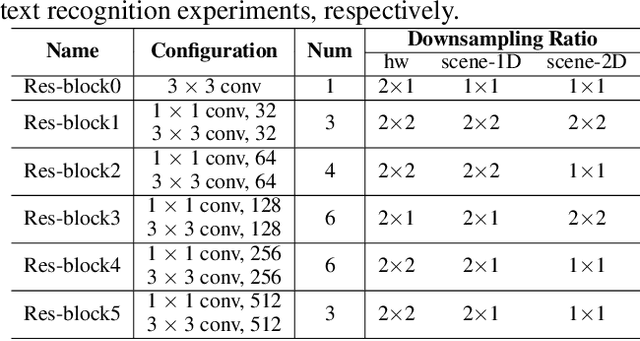
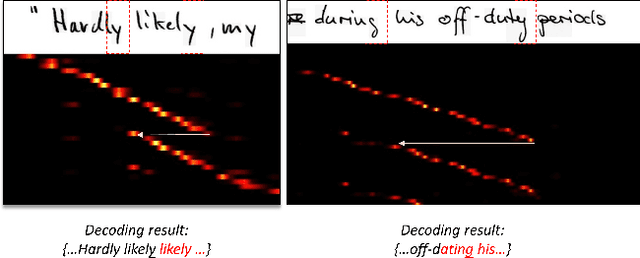
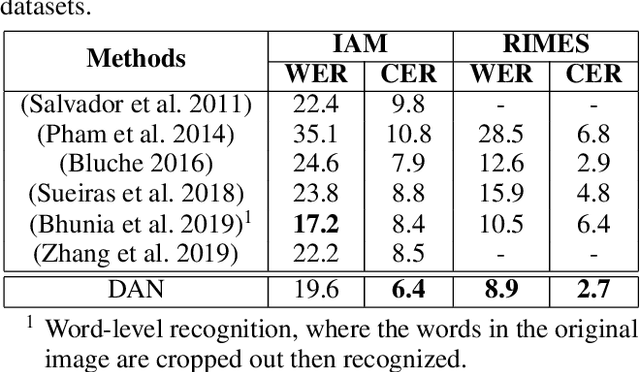
Text recognition has attracted considerable research interests because of its various applications. The cutting-edge text recognition methods are based on attention mechanisms. However, most of attention methods usually suffer from serious alignment problem due to its recurrency alignment operation, where the alignment relies on historical decoding results. To remedy this issue, we propose a decoupled attention network (DAN), which decouples the alignment operation from using historical decoding results. DAN is an effective, flexible and robust end-to-end text recognizer, which consists of three components: 1) a feature encoder that extracts visual features from the input image; 2) a convolutional alignment module that performs the alignment operation based on visual features from the encoder; and 3) a decoupled text decoder that makes final prediction by jointly using the feature map and attention maps. Experimental results show that DAN achieves state-of-the-art performance on multiple text recognition tasks, including offline handwritten text recognition and regular/irregular scene text recognition.