 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePageNet: Towards End-to-End Weakly Supervised Page-Level Handwritten Chinese Text Recognition
Jul 29, 2022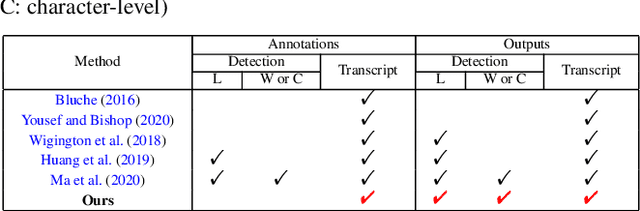
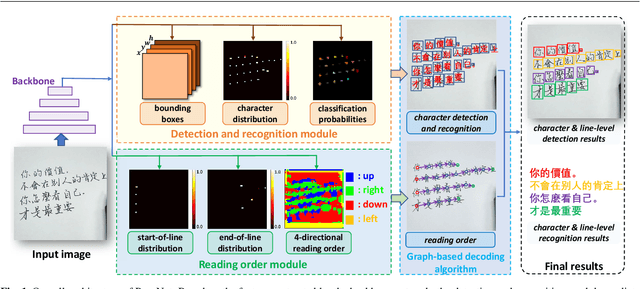
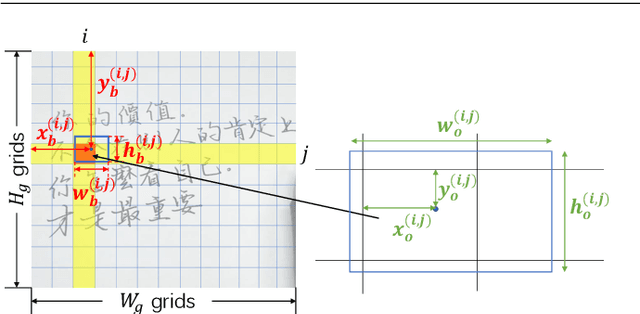

Handwritten Chinese text recognition (HCTR) has been an active research topic for decades. However, most previous studies solely focus on the recognition of cropped text line images, ignoring the error caused by text line detection in real-world applications. Although some approaches aimed at page-level text recognition have been proposed in recent years, they either are limited to simple layouts or require very detailed annotations including expensive line-level and even character-level bounding boxes. To this end, we propose PageNet for end-to-end weakly supervised page-level HCTR. PageNet detects and recognizes characters and predicts the reading order between them, which is more robust and flexible when dealing with complex layouts including multi-directional and curved text lines. Utilizing the proposed weakly supervised learning framework, PageNet requires only transcripts to be annotated for real data; however, it can still output detection and recognition results at both the character and line levels, avoiding the labor and cost of labeling bounding boxes of characters and text lines. Extensive experiments conducted on five datasets demonstrate the superiority of PageNet over existing weakly supervised and fully supervised page-level methods. These experimental results may spark further research beyond the realms of existing methods based on connectionist temporal classification or attention. The source code is available at https://github.com/shannanyinxiang/PageNet.
Knowing Where and What: Unified Word Block Pretraining for Document Understanding
Jul 29, 2022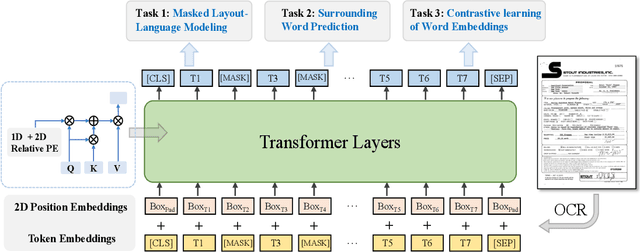
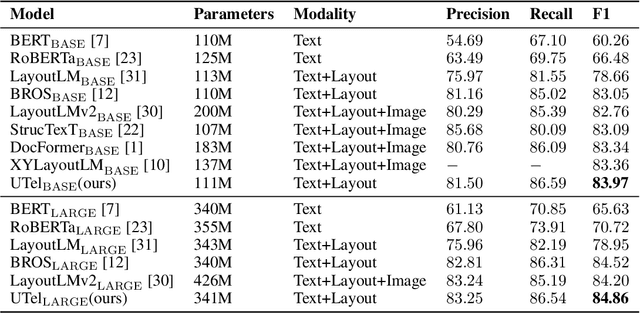
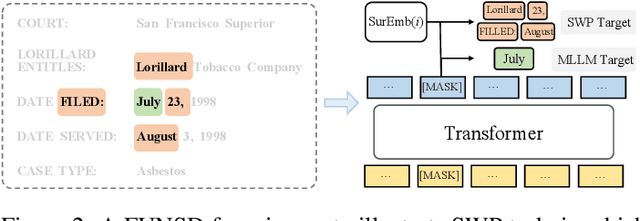

Due to the complex layouts of documents, it is challenging to extract information for documents. Most previous studies develop multimodal pre-trained models in a self-supervised way. In this paper, we focus on the embedding learning of word blocks containing text and layout information, and propose UTel, a language model with Unified TExt and Layout pre-training. Specifically, we propose two pre-training tasks: Surrounding Word Prediction (SWP) for the layout learning, and Contrastive learning of Word Embeddings (CWE) for identifying different word blocks. Moreover, we replace the commonly used 1D position embedding with a 1D clipped relative position embedding. In this way, the joint training of Masked Layout-Language Modeling (MLLM) and two newly proposed tasks enables the interaction between semantic and spatial features in a unified way. Additionally, the proposed UTel can process arbitrary-length sequences by removing the 1D position embedding, while maintaining competitive performance. Extensive experimental results show UTel learns better joint representations and achieves superior performance than previous methods on various downstream tasks, though requiring no image modality. Code is available at \url{https://github.com/taosong2019/UTel}.
Marior: Margin Removal and Iterative Content Rectification for Document Dewarping in the Wild
Jul 23, 2022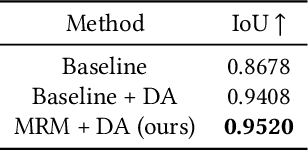
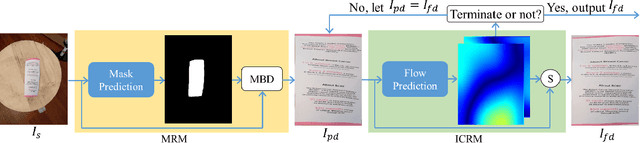

Camera-captured document images usually suffer from perspective and geometric deformations. It is of great value to rectify them when considering poor visual aesthetics and the deteriorated performance of OCR systems. Recent learning-based methods intensively focus on the accurately cropped document image. However, this might not be sufficient for overcoming practical challenges, including document images either with large marginal regions or without margins. Due to this impracticality, users struggle to crop documents precisely when they encounter large marginal regions. Simultaneously, dewarping images without margins is still an insurmountable problem. To the best of our knowledge, there is still no complete and effective pipeline for rectifying document images in the wild. To address this issue, we propose a novel approach called Marior (Margin Removal and \Iterative Content Rectification). Marior follows a progressive strategy to iteratively improve the dewarping quality and readability in a coarse-to-fine manner. Specifically, we divide the pipeline into two modules: margin removal module (MRM) and iterative content rectification module (ICRM). First, we predict the segmentation mask of the input image to remove the margin, thereby obtaining a preliminary result. Then we refine the image further by producing dense displacement flows to achieve content-aware rectification. We determine the number of refinement iterations adaptively. Experiments demonstrate the state-of-the-art performance of our method on public benchmarks. The resources are available at https://github.com/ZZZHANG-jx/Marior for further comparison.
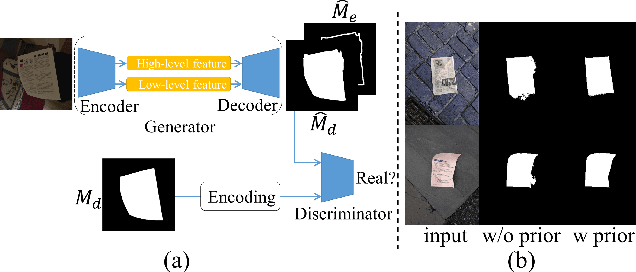
Don't Forget Me: Accurate Background Recovery for Text Removal via Modeling Local-Global Context
Jul 21, 2022
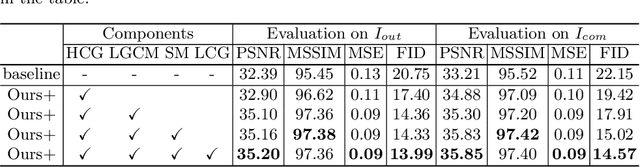
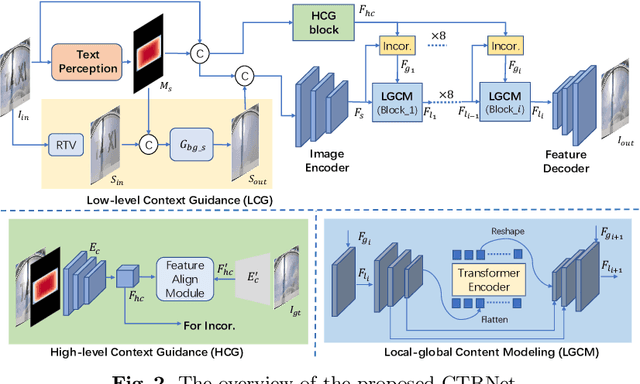
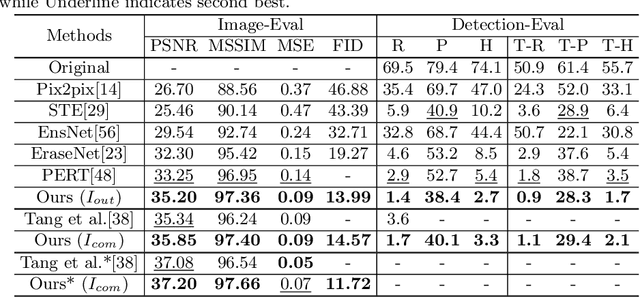
Text removal has attracted increasingly attention due to its various applications on privacy protection, document restoration, and text editing. It has shown significant progress with deep neural network. However, most of the existing methods often generate inconsistent results for complex background. To address this issue, we propose a Contextual-guided Text Removal Network, termed as CTRNet. CTRNet explores both low-level structure and high-level discriminative context feature as prior knowledge to guide the process of background restoration. We further propose a Local-global Content Modeling (LGCM) block with CNNs and Transformer-Encoder to capture local features and establish the long-term relationship among pixels globally. Finally, we incorporate LGCM with context guidance for feature modeling and decoding. Experiments on benchmark datasets, SCUT-EnsText and SCUT-Syn show that CTRNet significantly outperforms the existing state-of-the-art methods. Furthermore, a qualitative experiment on examination papers also demonstrates the generalization ability of our method. The codes and supplement materials are available at https://github.com/lcy0604/CTRNet.
Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator
Apr 30, 2022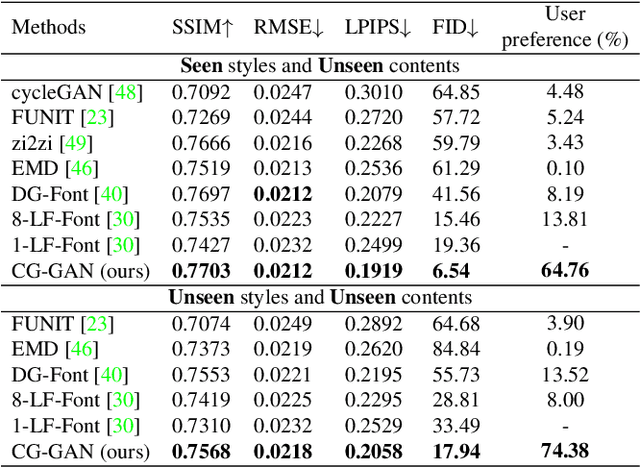
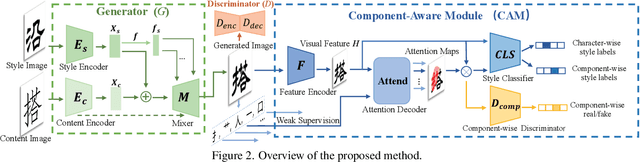


Automatic font generation remains a challenging research issue due to the large amounts of characters with complicated structures. Typically, only a few samples can serve as the style/content reference (termed few-shot learning), which further increases the difficulty to preserve local style patterns or detailed glyph structures. We investigate the drawbacks of previous studies and find that a coarse-grained discriminator is insufficient for supervising a font generator. To this end, we propose a novel Component-Aware Module (CAM), which supervises the generator to decouple content and style at a more fine-grained level, \textit{i.e.}, the component level. Different from previous studies struggling to increase the complexity of generators, we aim to perform more effective supervision for a relatively simple generator to achieve its full potential, which is a brand new perspective for font generation. The whole framework achieves remarkable results by coupling component-level supervision with adversarial learning, hence we call it Component-Guided GAN, shortly CG-GAN. Extensive experiments show that our approach outperforms state-of-the-art one-shot font generation methods. Furthermore, it can be applied to handwritten word synthesis and scene text image editing, suggesting the generalization of our approach.
SimAN: Exploring Self-Supervised Representation Learning of Scene Text via Similarity-Aware Normalization
Mar 22, 2022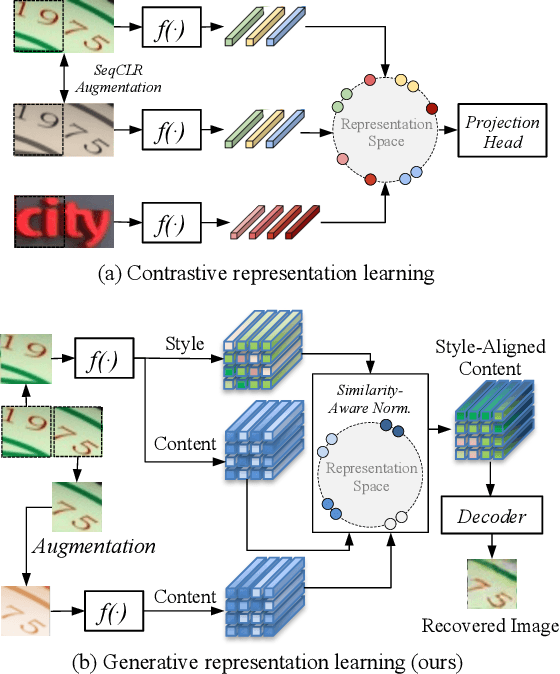

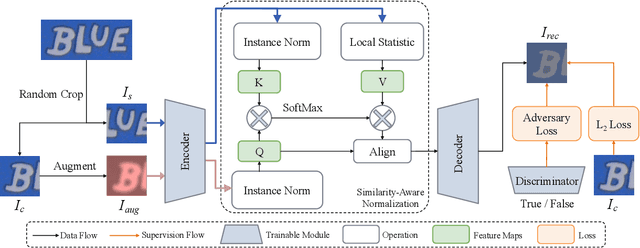
Recently self-supervised representation learning has drawn considerable attention from the scene text recognition community. Different from previous studies using contrastive learning, we tackle the issue from an alternative perspective, i.e., by formulating the representation learning scheme in a generative manner. Typically, the neighboring image patches among one text line tend to have similar styles, including the strokes, textures, colors, etc. Motivated by this common sense, we augment one image patch and use its neighboring patch as guidance to recover itself. Specifically, we propose a Similarity-Aware Normalization (SimAN) module to identify the different patterns and align the corresponding styles from the guiding patch. In this way, the network gains representation capability for distinguishing complex patterns such as messy strokes and cluttered backgrounds. Experiments show that the proposed SimAN significantly improves the representation quality and achieves promising performance. Moreover, we surprisingly find that our self-supervised generative network has impressive potential for data synthesis, text image editing, and font interpolation, which suggests that the proposed SimAN has a wide range of practical applications.
SLOGAN: Handwriting Style Synthesis for Arbitrary-Length and Out-of-Vocabulary Text
Feb 23, 2022



Large amounts of labeled data are urgently required for the training of robust text recognizers. However, collecting handwriting data of diverse styles, along with an immense lexicon, is considerably expensive. Although data synthesis is a promising way to relieve data hunger, two key issues of handwriting synthesis, namely, style representation and content embedding, remain unsolved. To this end, we propose a novel method that can synthesize parameterized and controllable handwriting Styles for arbitrary-Length and Out-of-vocabulary text based on a Generative Adversarial Network (GAN), termed SLOGAN. Specifically, we propose a style bank to parameterize the specific handwriting styles as latent vectors, which are input to a generator as style priors to achieve the corresponding handwritten styles. The training of the style bank requires only the writer identification of the source images, rather than attribute annotations. Moreover, we embed the text content by providing an easily obtainable printed style image, so that the diversity of the content can be flexibly achieved by changing the input printed image. Finally, the generator is guided by dual discriminators to handle both the handwriting characteristics that appear as separated characters and in a series of cursive joins. Our method can synthesize words that are not included in the training vocabulary and with various new styles. Extensive experiments have shown that high-quality text images with great style diversity and rich vocabulary can be synthesized using our method, thereby enhancing the robustness of the recognizer.
Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter
Jun 10, 2021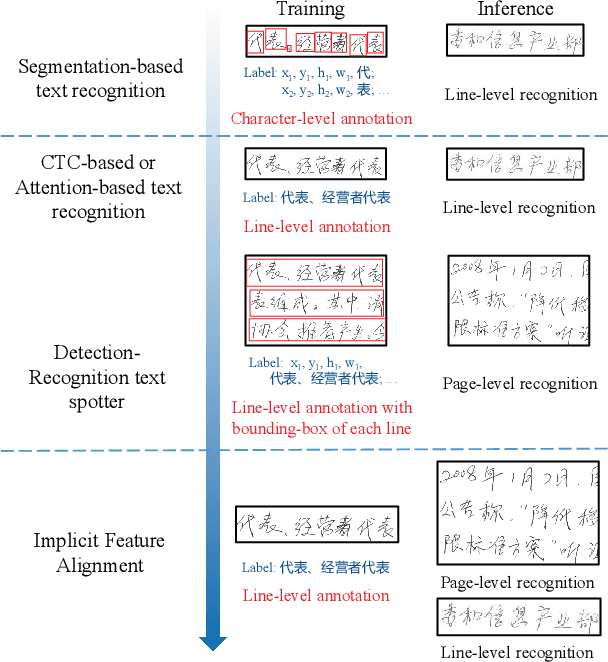
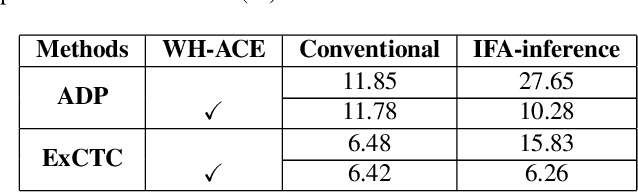
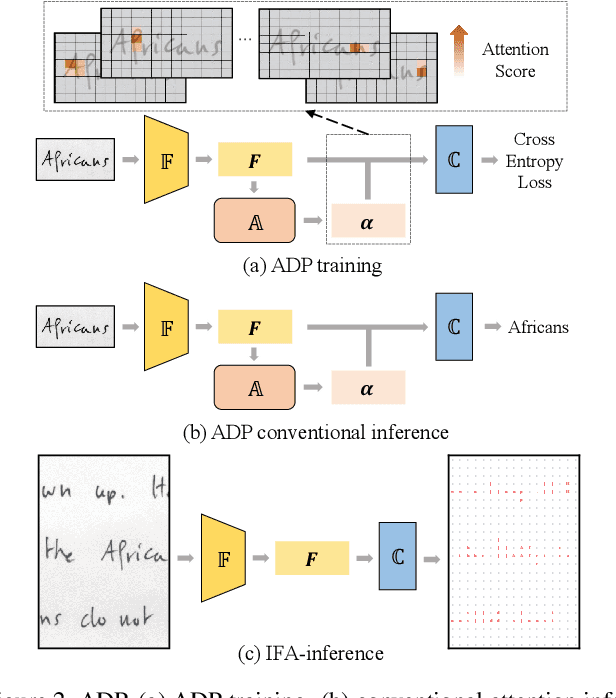
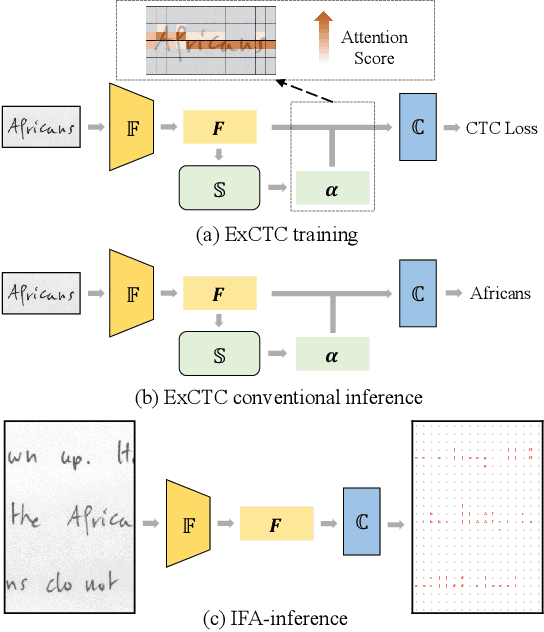
Text recognition is a popular research subject with many associated challenges. Despite the considerable progress made in recent years, the text recognition task itself is still constrained to solve the problem of reading cropped line text images and serves as a subtask of optical character recognition (OCR) systems. As a result, the final text recognition result is limited by the performance of the text detector. In this paper, we propose a simple, elegant and effective paradigm called Implicit Feature Alignment (IFA), which can be easily integrated into current text recognizers, resulting in a novel inference mechanism called IFAinference. This enables an ordinary text recognizer to process multi-line text such that text detection can be completely freed. Specifically, we integrate IFA into the two most prevailing text recognition streams (attention-based and CTC-based) and propose attention-guided dense prediction (ADP) and Extended CTC (ExCTC). Furthermore, the Wasserstein-based Hollow Aggregation Cross-Entropy (WH-ACE) is proposed to suppress negative predictions to assist in training ADP and ExCTC. We experimentally demonstrate that IFA achieves state-of-the-art performance on end-to-end document recognition tasks while maintaining the fastest speed, and ADP and ExCTC complement each other on the perspective of different application scenarios. Code will be available at https://github.com/WangTianwei/Implicit-feature-alignment.
Text Recognition in the Wild: A Survey
May 07, 2020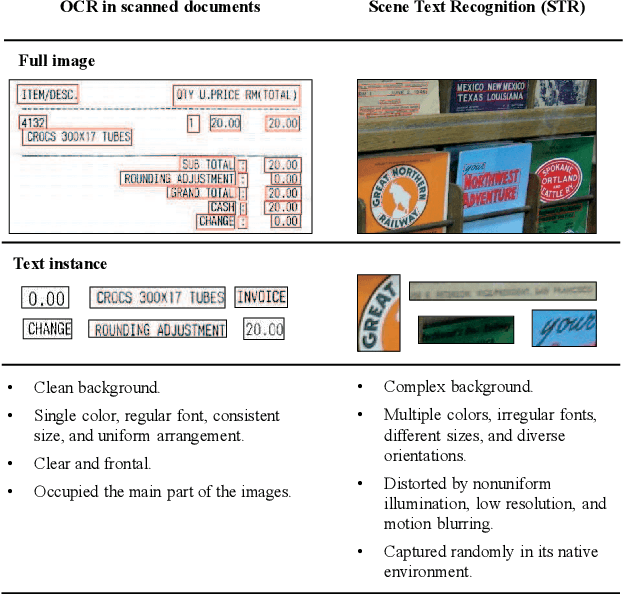
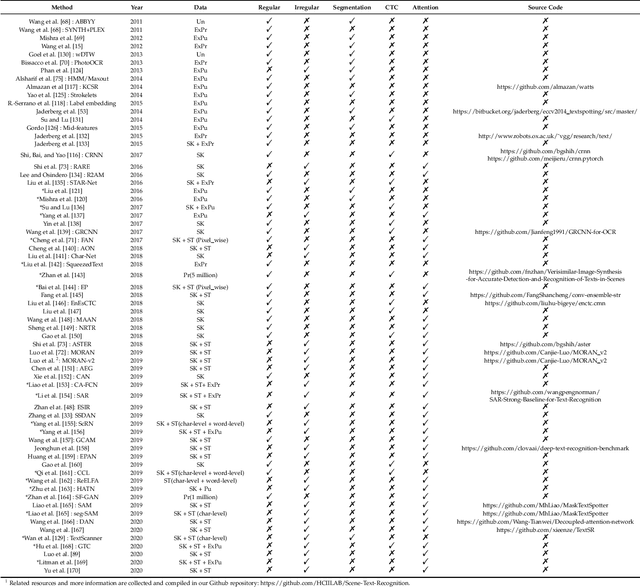

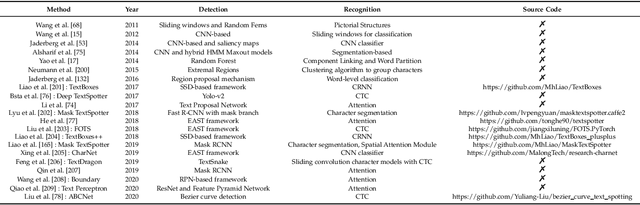
The history of text can be traced back over thousands of years. Rich and precise semantic information carried by text is important in a wide range of vision-based application scenarios. Therefore, text recognition in natural scenes has been an active research field in computer vision and pattern recognition. In recent years, with the rise and development of deep learning, numerous methods have shown promising in terms of innovation, practicality, and efficiency. This paper aims to (1) summarize the fundamental problems and the state-of-the-art associated with scene text recognition; (2) introduce new insights and ideas; (3) provide a comprehensive review of publicly available resources; (4) point out directions for future work. In summary, this literature review attempts to present the entire picture of the field of scene text recognition. It provides a comprehensive reference for people entering this field, and could be helpful to inspire future research. Related resources are available at our Github repository: https://github.com/HCIILAB/Scene-Text-Recognition.
Learn to Augment: Joint Data Augmentation and Network Optimization for Text Recognition
Mar 14, 2020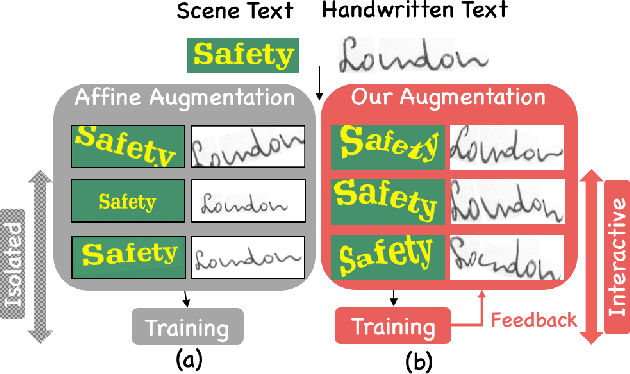

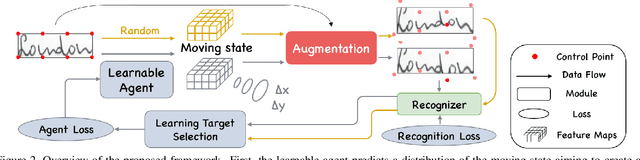
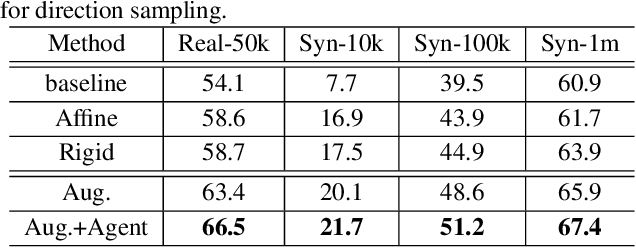
Handwritten text and scene text suffer from various shapes and distorted patterns. Thus training a robust recognition model requires a large amount of data to cover diversity as much as possible. In contrast to data collection and annotation, data augmentation is a low cost way. In this paper, we propose a new method for text image augmentation. Different from traditional augmentation methods such as rotation, scaling and perspective transformation, our proposed augmentation method is designed to learn proper and efficient data augmentation which is more effective and specific for training a robust recognizer. By using a set of custom fiducial points, the proposed augmentation method is flexible and controllable. Furthermore, we bridge the gap between the isolated processes of data augmentation and network optimization by joint learning. An agent network learns from the output of the recognition network and controls the fiducial points to generate more proper training samples for the recognition network. Extensive experiments on various benchmarks, including regular scene text, irregular scene text and handwritten text, show that the proposed augmentation and the joint learning methods significantly boost the performance of the recognition networks. A general toolkit for geometric augmentation is available.