 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Deterministic Nonlinear ICA via Total Correlation Minimization with Matrix-Based Entropy Functional
Dec 31, 2025Blind source separation, particularly through independent component analysis (ICA), is widely utilized across various signal processing domains for disentangling underlying components from observed mixed signals, owing to its fully data-driven nature that minimizes reliance on prior assumptions. However, conventional ICA methods rely on an assumption of linear mixing, limiting their ability to capture complex nonlinear relationships and to maintain robustness in noisy environments. In this work, we present deep deterministic nonlinear independent component analysis (DDICA), a novel deep neural network-based framework designed to address these limitations. DDICA leverages a matrix-based entropy function to directly optimize the independence criterion via stochastic gradient descent, bypassing the need for variational approximations or adversarial schemes. This results in a streamlined training process and improved resilience to noise. We validated the effectiveness and generalizability of DDICA across a range of applications, including simulated signal mixtures, hyperspectral image unmixing, modeling of primary visual receptive fields, and resting-state functional magnetic resonance imaging (fMRI) data analysis. Experimental results demonstrate that DDICA effectively separates independent components with high accuracy across a range of applications. These findings suggest that DDICA offers a robust and versatile solution for blind source separation in diverse signal processing tasks.
Exploiting Radio Frequency Fingerprints for Device Identification: Tackling Cross-receiver Challenges in the Source-data-free Scenario
Dec 18, 2025With the rapid proliferation of edge computing, Radio Frequency Fingerprint Identification (RFFI) has become increasingly important for secure device authentication. However, practical deployment of deep learning-based RFFI models is hindered by a critical challenge: their performance often degrades significantly when applied across receivers with different hardware characteristics due to distribution shifts introduced by receiver variation. To address this, we investigate the source-data-free cross-receiver RFFI (SCRFFI) problem, where a model pretrained on labeled signals from a source receiver must adapt to unlabeled signals from a target receiver, without access to any source-domain data during adaptation. We first formulate a novel constrained pseudo-labeling-based SCRFFI adaptation framework, and provide a theoretical analysis of its generalization performance. Our analysis highlights a key insight: the target-domain performance is highly sensitive to the quality of the pseudo-labels generated during adaptation. Motivated by this, we propose Momentum Soft pseudo-label Source Hypothesis Transfer (MS-SHOT), a new method for SCRFFI that incorporates momentum-center-guided soft pseudo-labeling and enforces global structural constraints to encourage confident and diverse predictions. Notably, MS-SHOT effectively addresses scenarios involving label shift or unknown, non-uniform class distributions in the target domain -- a significant limitation of prior methods. Extensive experiments on real-world datasets demonstrate that MS-SHOT consistently outperforms existing approaches in both accuracy and robustness, offering a practical and scalable solution for source-data-free cross-receiver adaptation in RFFI.
Constant-Modulus Secure Analog Beamforming for an IRS-Assisted Communication System with Large-Scale Antenna Array
Nov 19, 2025



Physical layer security (PLS) is an important technology in wireless communication systems to safeguard communication privacy and security between transmitters and legitimate users. The integration of large-scale antenna arrays (LSAA) and intelligent reflecting surfaces (IRS) has emerged as a promising approach to enhance PLS. However, LSAA requires a dedicated radio frequency (RF) chain for each antenna element, and IRS comprises hundreds of reflecting micro-antennas, leading to increased hardware costs and power consumption. To address this, cost-effective solutions like constant modulus analog beamforming (CMAB) have gained attention. This paper investigates PLS in IRS-assisted communication systems with a focus on jointly designing the CMAB at the transmitter and phase shifts at the IRS to maximize the secrecy rate. The resulting secrecy rate maximization (SRM) problem is non-convex. To solve the problem efficiently, we propose two algorithms: (1) the time-efficient Dinkelbach-BSUM algorithm, which reformulates the fractional problem into a series of quadratic programs using the Dinkelbach method and solves them via block successive upper-bound minimization (BSUM), and (2) the product manifold conjugate gradient descent (PMCGD) algorithm, which provides a better solution at the cost of slightly higher computational time by transforming the problem into an unconstrained optimization on a Riemannian product manifold and solving it using the conjugate gradient descent (CGD) algorithm. Simulation results validate the effectiveness of the proposed algorithms and highlight their distinct advantages.
Joint Analog Beamforming and Antenna Position Design for Secure Communication systems With Movable Antennas
Nov 19, 2025Movable antennas (MA) are a novel technology that allows for the flexible adjustment of antenna positions within a specified region, thereby enhancing the performance of wireless communication systems. In this paper, we explore the use of MA to improve physical layer security in an analog beamforming (AB) communication system. Our goal is to maximize the secrecy rate by jointly optimizing the transmit AB and MA position, subject to constant modulus (CM) constraints on the AB and position constraints for the MA. The resulting problem is non-convex, and we propose a penalty product manifold (PPM) method to solve it efficiently. Specifically, we convert the inequality constraints related to MA position into a penalty function using smoothing techniques, thereby reformulating the problem as an unconstrained optimization on the product manifold space (PMS). We then derive a parallel conjugate gradient descent (PCGD) algorithm to update both the AB and MA position on the PMS. This method is efficient, providing an analytical solution at each step and ensuring convergence to a KKT point. Simulation results show that the MA system achieves a higher secrecy rate than systems with fixed-position antennas.
Enhancing Physical Layer Security in MIMO Systems Assisted by Beyond-Diagonal Reconfigurable Intelligent Surfaces
Nov 19, 2025



Reconfigurable intelligent surfaces (RISs) hold significant promise for enhancing physical layer security (PLS). However, conventional RISs are typically modeled using diagonal scattering matrices, capturing only independent reflections from each reflecting element, which limits their flexibility in channel manipulation. In contrast, beyond-diagonal RISs (BD-RISs) employ non-diagonal scattering matrices enabled by active and tunable inter-element connections through a shared impedance network. This architecture significantly enhances channel shaping capabilities, creating new opportunities for advanced PLS techniques. This paper investigates PLS in a multiple-input multiple-output (MIMO) system assisted by BD-RISs, where a multi-antenna transmitter sends confidential information to a multi-antenna legitimate user while a multi-antenna eavesdropper attempts interception. To maximize the secrecy rate (SR), we formulate it as a non-convex optimization problem by jointly optimizing the transmit beamforming and BD-RIS REs under power and structural constraints. To solve this problem, we first introduce an auxiliary variable to decouple BD-RIS constraints. We then propose a low-complexity penalty product Riemannian conjugate gradient descent (P-PRCGD) method, which combines the augmented Lagrangian (AL) approach with the product manifold gradient descent (PMGD) method to obtain a Karush-Kuhn-Tucker (KKT) solution. Simulation results confirm that BD-RIS-assisted systems significantly outperform conventional RIS-assisted systems in PLS performance.
GUIDE: Gaussian Unified Instance Detection for Enhanced Obstacle Perception in Autonomous Driving
Nov 17, 2025In the realm of autonomous driving, accurately detecting surrounding obstacles is crucial for effective decision-making. Traditional methods primarily rely on 3D bounding boxes to represent these obstacles, which often fail to capture the complexity of irregularly shaped, real-world objects. To overcome these limitations, we present GUIDE, a novel framework that utilizes 3D Gaussians for instance detection and occupancy prediction. Unlike conventional occupancy prediction methods, GUIDE also offers robust tracking capabilities. Our framework employs a sparse representation strategy, using Gaussian-to-Voxel Splatting to provide fine-grained, instance-level occupancy data without the computational demands associated with dense voxel grids. Experimental validation on the nuScenes dataset demonstrates GUIDE's performance, with an instance occupancy mAP of 21.61, marking a 50\% improvement over existing methods, alongside competitive tracking capabilities. GUIDE establishes a new benchmark in autonomous perception systems, effectively combining precision with computational efficiency to better address the complexities of real-world driving environments.
FIA-Edit: Frequency-Interactive Attention for Efficient and High-Fidelity Inversion-Free Text-Guided Image Editing
Nov 15, 2025Text-guided image editing has advanced rapidly with the rise of diffusion models. While flow-based inversion-free methods offer high efficiency by avoiding latent inversion, they often fail to effectively integrate source information, leading to poor background preservation, spatial inconsistencies, and over-editing due to the lack of effective integration of source information. In this paper, we present FIA-Edit, a novel inversion-free framework that achieves high-fidelity and semantically precise edits through a Frequency-Interactive Attention. Specifically, we design two key components: (1) a Frequency Representation Interaction (FRI) module that enhances cross-domain alignment by exchanging frequency components between source and target features within self-attention, and (2) a Feature Injection (FIJ) module that explicitly incorporates source-side queries, keys, values, and text embeddings into the target branch's cross-attention to preserve structure and semantics. Comprehensive and extensive experiments demonstrate that FIA-Edit supports high-fidelity editing at low computational cost (~6s per 512 * 512 image on an RTX 4090) and consistently outperforms existing methods across diverse tasks in visual quality, background fidelity, and controllability. Furthermore, we are the first to extend text-guided image editing to clinical applications. By synthesizing anatomically coherent hemorrhage variations in surgical images, FIA-Edit opens new opportunities for medical data augmentation and delivers significant gains in downstream bleeding classification. Our project is available at: https://github.com/kk42yy/FIA-Edit.
TiS-TSL: Image-Label Supervised Surgical Video Stereo Matching via Time-Switchable Teacher-Student Learning
Nov 12, 2025Stereo matching in minimally invasive surgery (MIS) is essential for next-generation navigation and augmented reality. Yet, dense disparity supervision is nearly impossible due to anatomical constraints, typically limiting annotations to only a few image-level labels acquired before the endoscope enters deep body cavities. Teacher-Student Learning (TSL) offers a promising solution by leveraging a teacher trained on sparse labels to generate pseudo labels and associated confidence maps from abundant unlabeled surgical videos. However, existing TSL methods are confined to image-level supervision, providing only spatial confidence and lacking temporal consistency estimation. This absence of spatio-temporal reliability results in unstable disparity predictions and severe flickering artifacts across video frames. To overcome these challenges, we propose TiS-TSL, a novel time-switchable teacher-student learning framework for video stereo matching under minimal supervision. At its core is a unified model that operates in three distinct modes: Image-Prediction (IP), Forward Video-Prediction (FVP), and Backward Video-Prediction (BVP), enabling flexible temporal modeling within a single architecture. Enabled by this unified model, TiS-TSL adopts a two-stage learning strategy. The Image-to-Video (I2V) stage transfers sparse image-level knowledge to initialize temporal modeling. The subsequent Video-to-Video (V2V) stage refines temporal disparity predictions by comparing forward and backward predictions to calculate bidirectional spatio-temporal consistency. This consistency identifies unreliable regions across frames, filters noisy video-level pseudo labels, and enforces temporal coherence. Experimental results on two public datasets demonstrate that TiS-TSL exceeds other image-based state-of-the-arts by improving TEPE and EPE by at least 2.11% and 4.54%, respectively.
Bidirectional Mammogram View Translation with Column-Aware and Implicit 3D Conditional Diffusion
Oct 06, 2025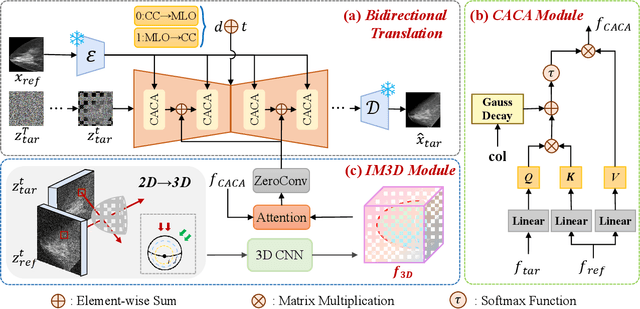
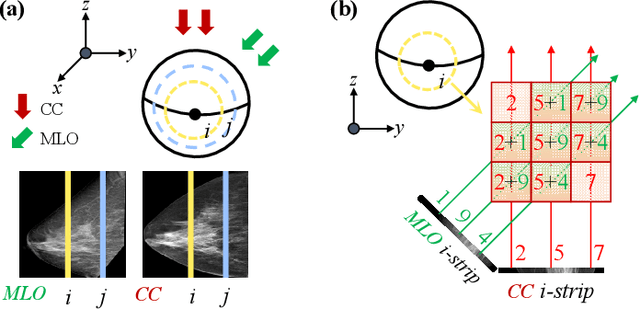
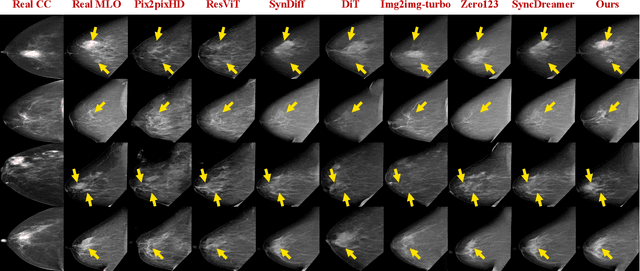
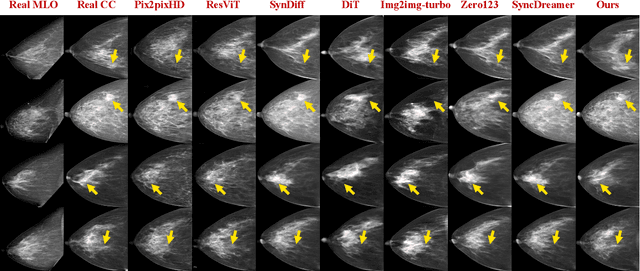
Dual-view mammography, including craniocaudal (CC) and mediolateral oblique (MLO) projections, offers complementary anatomical views crucial for breast cancer diagnosis. However, in real-world clinical workflows, one view may be missing, corrupted, or degraded due to acquisition errors or compression artifacts, limiting the effectiveness of downstream analysis. View-to-view translation can help recover missing views and improve lesion alignment. Unlike natural images, this task in mammography is highly challenging due to large non-rigid deformations and severe tissue overlap in X-ray projections, which obscure pixel-level correspondences. In this paper, we propose Column-Aware and Implicit 3D Diffusion (CA3D-Diff), a novel bidirectional mammogram view translation framework based on conditional diffusion model. To address cross-view structural misalignment, we first design a column-aware cross-attention mechanism that leverages the geometric property that anatomically corresponding regions tend to lie in similar column positions across views. A Gaussian-decayed bias is applied to emphasize local column-wise correlations while suppressing distant mismatches. Furthermore, we introduce an implicit 3D structure reconstruction module that back-projects noisy 2D latents into a coarse 3D feature volume based on breast-view projection geometry. The reconstructed 3D structure is refined and injected into the denoising UNet to guide cross-view generation with enhanced anatomical awareness. Extensive experiments demonstrate that CA3D-Diff achieves superior performance in bidirectional tasks, outperforming state-of-the-art methods in visual fidelity and structural consistency. Furthermore, the synthesized views effectively improve single-view malignancy classification in screening settings, demonstrating the practical value of our method in real-world diagnostics.
Terahertz Channel Measurement and Modeling for Short-Range Indoor Environments
Oct 05, 2025



Accurate channel modeling is essential for realizing the potential of terahertz (THz) communications in 6G indoor networks, where existing models struggle with severe frequency selectivity and multipath effects. We propose a physically grounded Rician fading channel model that jointly incorporates deterministic line-of-sight (LOS) and stochastic non-line-of-sight (NLOS) components, enhanced by frequency-dependent attenuation characterized by optimized exponents alpha and beta. Unlike conventional approaches, our model integrates a two-ray reflection framework to capture standing wave phenomena and employs wideband spectral averaging to mitigate frequency selectivity over bandwidths up to 15 GHz. Empirical measurements at a 208 GHz carrier, spanning 0.1-0.9 m, demonstrate that our model achieves root mean square errors (RMSE) as low as 2.54 dB, outperforming free-space path loss (FSPL) by up to 14.2% and reducing RMSE by 73.3% as bandwidth increases. These findings underscore the importance of bandwidth in suppressing oscillatory artifacts and improving modeling accuracy. Our approach provides a robust foundation for THz system design, supporting reliable indoor wireless personal area networks (WPANs), device-to-device (D2D) communications, and precise localization in future 6G applications.