 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooped World Models
Jun 16, 2026Current world models face a fundamental tension: faithful long-horizon simulation demands deep computation, but deeper models are expensive to deploy and prone to compounding errors. We resolve this by introducing Looped World Models (LoopWM), which are the first looped architectures for world modelling. Our method iteratively refines latent environment states through a parameter-shared transformer block. This yield up to 100x parameter efficiency over conventional approaches with adaptive computation that automatically scales depth to match the complexity of each prediction step. Orthogonal to scaling model size and training data, LoopWM establishes iterative latent depth as a new scaling axis for world simulation, which might significantly push the community forward.
Terahertz Channel Measurement and Modeling for Short-Range Indoor Environments
Oct 05, 2025



Accurate channel modeling is essential for realizing the potential of terahertz (THz) communications in 6G indoor networks, where existing models struggle with severe frequency selectivity and multipath effects. We propose a physically grounded Rician fading channel model that jointly incorporates deterministic line-of-sight (LOS) and stochastic non-line-of-sight (NLOS) components, enhanced by frequency-dependent attenuation characterized by optimized exponents alpha and beta. Unlike conventional approaches, our model integrates a two-ray reflection framework to capture standing wave phenomena and employs wideband spectral averaging to mitigate frequency selectivity over bandwidths up to 15 GHz. Empirical measurements at a 208 GHz carrier, spanning 0.1-0.9 m, demonstrate that our model achieves root mean square errors (RMSE) as low as 2.54 dB, outperforming free-space path loss (FSPL) by up to 14.2% and reducing RMSE by 73.3% as bandwidth increases. These findings underscore the importance of bandwidth in suppressing oscillatory artifacts and improving modeling accuracy. Our approach provides a robust foundation for THz system design, supporting reliable indoor wireless personal area networks (WPANs), device-to-device (D2D) communications, and precise localization in future 6G applications.
Integrated Computation and Communication with Fiber-optic Transmissions
Mar 04, 2025

Fiber-optic transmission systems are leveraged not only as high-speed communication channels but also as nonlinear kernel functions for machine learning computations, enabling the seamless integration of computational intelligence and communication.
CauESC: A Causal Aware Model for Emotional Support Conversation
Jan 31, 2024Emotional Support Conversation aims at reducing the seeker's emotional distress through supportive response. Existing approaches have two limitations: (1) They ignore the emotion causes of the distress, which is important for fine-grained emotion understanding; (2) They focus on the seeker's own mental state rather than the emotional dynamics during interaction between speakers. To address these issues, we propose a novel framework CauESC, which firstly recognizes the emotion causes of the distress, as well as the emotion effects triggered by the causes, and then understands each strategy of verbal grooming independently and integrates them skillfully. Experimental results on the benchmark dataset demonstrate the effectiveness of our approach and show the benefits of emotion understanding from cause to effect and independent-integrated strategy modeling.
Transfer Representation Learning with TSK Fuzzy System
Jan 09, 2019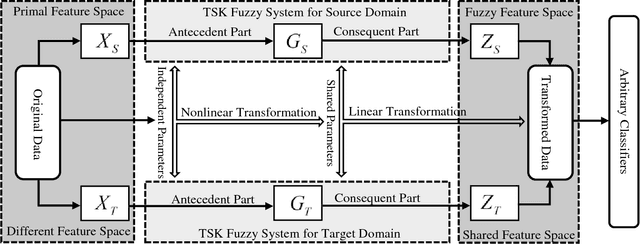

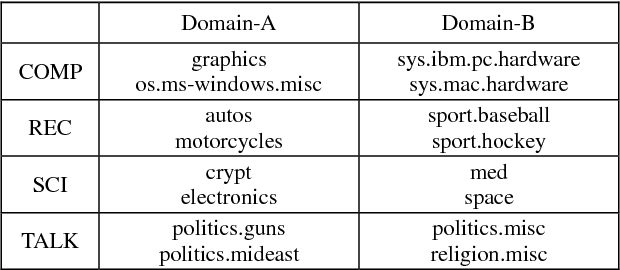
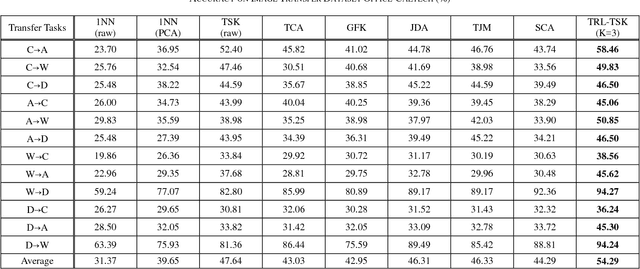
Transfer learning can address the learning tasks of unlabeled data in the target domain by leveraging plenty of labeled data from a different but related source domain. A core issue in transfer learning is to learn a shared feature space in where the distributions of the data from two domains are matched. This learning process can be named as transfer representation learning (TRL). The feature transformation methods are crucial to ensure the success of TRL. The most commonly used feature transformation method in TRL is kernel-based nonlinear mapping to the high-dimensional space followed by linear dimensionality reduction. But the kernel functions are lack of interpretability and are difficult to be selected. To this end, the TSK fuzzy system (TSK-FS) is combined with transfer learning and a more intuitive and interpretable modeling method, called transfer representation learning with TSK-FS (TRL-TSK-FS) is proposed in this paper. Specifically, TRL-TSK-FS realizes TRL from two aspects. On one hand, the data in the source and target domains are transformed into the fuzzy feature space in which the distribution distance of the data between two domains is min-imized. On the other hand, discriminant information and geo-metric properties of the data are preserved by linear discriminant analysis and principal component analysis. In addition, another advantage arises with the proposed method, that is, the nonlinear transformation is realized by constructing fuzzy mapping with the antecedent part of the TSK-FS instead of kernel functions which are difficult to be selected. Extensive experiments are conducted on the text and image datasets. The results obviously show the superiority of the proposed method.