 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALAM: Algebraically Consistent Latent Transitions for Vision-Language-Action Models
May 11, 2026Vision-language-action (VLA) models remain constrained by the scarcity of action-labeled robot data, whereas action-free videos provide abundant evidence of how the physical world changes. Latent action models offer a promising way to extract such priors from videos, but reconstruction-trained latent codes are not necessarily suitable for policy generation: they may predict future observations while lacking the structure needed to be reused or generated coherently with robot actions. We introduce ALAM (Algebraic Latent Action Model), an Algebraically Consistent Latent Action Model that turns temporal relations in action-free video into structural supervision. Given frame triplets, ALAM learns latent transitions that are grounded by reconstruction while being regularized by composition and reversal consistency, encouraging a locally additive transition space. For downstream VLA learning, we freeze the pretrained encoder and use its latent transition sequences as auxiliary generative targets, co-generated with robot actions under a joint flow-matching objective. This couples structured latent transitions with flow-based policy generation, allowing the policy to exploit ALAM's locally consistent transition geometry without requiring latent-to-action decoding. Representation probes show that ALAM reduces additivity and reversibility errors by 25-85 times over unstructured latent-action baselines and improves long-horizon cumulative reconstruction. When transferred to VLA policies, ALAM raises the average success rate from 47.9% to 85.0% on MetaWorld MT50 and from 94.1% to 98.1% on LIBERO, with consistent gains on real-world manipulation tasks. Ablations further confirm that the strongest improvements arise from the synergy between algebraically structured latent transitions and joint flow matching.
Bridging Quantized Artificial Neural Networks and Neuromorphic Hardware
May 18, 2025Neuromorphic hardware has been proposed and also been produced for decades. One of the main goals of this hardware is to leverage distributed computing and event-driven circuit design and achieve power-efficient AI system. The name ``neuromorphic'' is derived from its spiking and local computational nature, which mimics the fundamental activity of an animal's nervous system. Neurons as well as distributed computing cores of neuromorphic hardware use single bit data, called a spike, for inter-communication. To construct a spiking model for neuromorphic hardware, the conventional approach is to build spiking neural networks (SNNs). SNN replaces the nonlinearity part of artificial neural networks (ANNs) in the realm of deep learning with spiking neurons, where the spiking neuron mimic the basic behavior of bio-neurons. However, there is still a performance gap between SNN and ANN counterpart. In this paper, we explore a new path from ANN to neuromorphic hardware. The SDANN framework is proposed to directly implement quantized ANN on hardware, eliminating the need for tuning the trainable parameters or any performance degradation. With the power of quantized ANN, our SDANN provides a lower bound of the functionality of neuromorphic hardware. Meanwhile, we have also proposed scaling methods in case of the limited bit-width support in hardware. Spike sparsity methods are also provided for further energy optimization. Experiments on various tasks demonstrate the usefulness of our SDANN framework. Beyond toy examples and software implementation, we successfully deploy the spiking models of SDANN on real neuromorphic hardware, demonstrating the feasibility of the SDANN framework.
Bidirectional Distillation: A Mixed-Play Framework for Multi-Agent Generalizable Behaviors
May 16, 2025Population-population generalization is a challenging problem in multi-agent reinforcement learning (MARL), particularly when agents encounter unseen co-players. However, existing self-play-based methods are constrained by the limitation of inside-space generalization. In this study, we propose Bidirectional Distillation (BiDist), a novel mixed-play framework, to overcome this limitation in MARL. BiDist leverages knowledge distillation in two alternating directions: forward distillation, which emulates the historical policies' space and creates an implicit self-play, and reverse distillation, which systematically drives agents towards novel distributions outside the known policy space in a non-self-play manner. In addition, BiDist operates as a concise and efficient solution without the need for the complex and costly storage of past policies. We provide both theoretical analysis and empirical evidence to support BiDist's effectiveness. Our results highlight its remarkable generalization ability across a variety of cooperative, competitive, and social dilemma tasks, and reveal that BiDist significantly diversifies the policy distribution space. We also present comprehensive ablation studies to reinforce BiDist's effectiveness and key success factors. Source codes are available in the supplementary material.
How to Build a Pre-trained Multimodal model for Simultaneously Chatting and Decision-making?
Oct 21, 2024



Existing large pre-trained models typically map text input to text output in an end-to-end manner, such as ChatGPT, or map a segment of text input to a hierarchy of action decisions, such as OpenVLA. However, humans can simultaneously generate text and actions when receiving specific input signals. For example, a driver can make precise driving decisions while conversing with a friend in the passenger seat. Motivated by this observation, we consider the following question in this work: is it possible to construct a pre-trained model that can provide both language interaction and precise decision-making capabilities in dynamic open scenarios. We provide a definitive answer to this question by developing a new model architecture termed Visual Language Action model for Chatting and Decision Making (VLA4CD), and further demonstrating its performance in challenging autonomous driving tasks. Specifically, we leverage LoRA to fine-tune a pre-trained LLM with data of multiple modalities covering language, visual, and action. Unlike the existing LoRA operations used for LLM fine-tuning, we have designed new computational modules and training cost functions for VLA4CD. These designs enable VLA4CD to provide continuous-valued action decisions while outputting text responses. In contrast, existing LLMs can only output text responses, and current VLA models can only output action decisions. Moreover, these VLA models handle action data by discretizing and then tokenizing the discretized actions, a method unsuitable for complex decision-making tasks involving high-dimensional continuous-valued action vectors, such as autonomous driving. The experimental results on CARLA validate that: (1) our proposed model construction method is effective; (2) compared to the SOTA VLA model, VLA4CD can provide more accurate real-time decision-making while retaining the text interaction capability inherent to LLMs.
Spiking GS: Towards High-Accuracy and Low-Cost Surface Reconstruction via Spiking Neuron-based Gaussian Splatting
Oct 09, 20243D Gaussian Splatting is capable of reconstructing 3D scenes in minutes. Despite recent advances in improving surface reconstruction accuracy, the reconstructed results still exhibit bias and suffer from inefficiency in storage and training. This paper provides a different observation on the cause of the inefficiency and the reconstruction bias, which is attributed to the integration of the low-opacity parts (LOPs) of the generated Gaussians. We show that LOPs consist of Gaussians with overall low-opacity (LOGs) and the low-opacity tails (LOTs) of Gaussians. We propose Spiking GS to reduce such two types of LOPs by integrating spiking neurons into the Gaussian Splatting pipeline. Specifically, we introduce global and local full-precision integrate-and-fire spiking neurons to the opacity and representation function of flattened 3D Gaussians, respectively. Furthermore, we enhance the density control strategy with spiking neurons' thresholds and an new criterion on the scale of Gaussians. Our method can represent more accurate reconstructed surfaces at a lower cost. The code is available at \url{https://github.com/shippoT/Spiking_GS}.
An Asynchronous Multi-core Accelerator for SNN inference
Jul 30, 2024



Spiking Neural Networks (SNNs) are extensively utilized in brain-inspired computing and neuroscience research. To enhance the speed and energy efficiency of SNNs, several many-core accelerators have been developed. However, maintaining the accuracy of SNNs often necessitates frequent explicit synchronization among all cores, which presents a challenge to overall efficiency. In this paper, we propose an asynchronous architecture for Spiking Neural Networks (SNNs) that eliminates the need for inter-core synchronization, thus enhancing speed and energy efficiency. This approach leverages the pre-determined dependencies of neuromorphic cores established during compilation. Each core is equipped with a scheduler that monitors the status of its dependencies, allowing it to safely advance to the next timestep without waiting for other cores. This eliminates the necessity for global synchronization and minimizes core waiting time despite inherent workload imbalances. Comprehensive evaluations using five different SNN workloads show that our architecture achieves a 1.86x speedup and a 1.55x increase in energy efficiency compared to state-of-the-art synchronization architectures.
EAS-SNN: End-to-End Adaptive Sampling and Representation for Event-based Detection with Recurrent Spiking Neural Networks
Mar 19, 2024



Event cameras, with their high dynamic range and temporal resolution, are ideally suited for object detection, especially under scenarios with motion blur and challenging lighting conditions. However, while most existing approaches prioritize optimizing spatiotemporal representations with advanced detection backbones and early aggregation functions, the crucial issue of adaptive event sampling remains largely unaddressed. Spiking Neural Networks (SNNs), which operate on an event-driven paradigm through sparse spike communication, emerge as a natural fit for addressing this challenge. In this study, we discover that the neural dynamics of spiking neurons align closely with the behavior of an ideal temporal event sampler. Motivated by this insight, we propose a novel adaptive sampling module that leverages recurrent convolutional SNNs enhanced with temporal memory, facilitating a fully end-to-end learnable framework for event-based detection. Additionally, we introduce Residual Potential Dropout (RPD) and Spike-Aware Training (SAT) to regulate potential distribution and address performance degradation encountered in spike-based sampling modules. Through rigorous testing on neuromorphic datasets for event-based detection, our approach demonstrably surpasses existing state-of-the-art spike-based methods, achieving superior performance with significantly fewer parameters and time steps. For instance, our method achieves a 4.4\% mAP improvement on the Gen1 dataset, while requiring 38\% fewer parameters and three time steps. Moreover, the applicability and effectiveness of our adaptive sampling methodology extend beyond SNNs, as demonstrated through further validation on conventional non-spiking detection models.
Learning to Manipulate Artistic Images
Jan 25, 2024Recent advancement in computer vision has significantly lowered the barriers to artistic creation. Exemplar-based image translation methods have attracted much attention due to flexibility and controllability. However, these methods hold assumptions regarding semantics or require semantic information as the input, while accurate semantics is not easy to obtain in artistic images. Besides, these methods suffer from cross-domain artifacts due to training data prior and generate imprecise structure due to feature compression in the spatial domain. In this paper, we propose an arbitrary Style Image Manipulation Network (SIM-Net), which leverages semantic-free information as guidance and a region transportation strategy in a self-supervised manner for image generation. Our method balances computational efficiency and high resolution to a certain extent. Moreover, our method facilitates zero-shot style image manipulation. Both qualitative and quantitative experiments demonstrate the superiority of our method over state-of-the-art methods.Code is available at https://github.com/SnailForce/SIM-Net.
Darwin3: A large-scale neuromorphic chip with a Novel ISA and On-Chip Learning
Dec 29, 2023



Spiking Neural Networks (SNNs) are gaining increasing attention for their biological plausibility and potential for improved computational efficiency. To match the high spatial-temporal dynamics in SNNs, neuromorphic chips are highly desired to execute SNNs in hardware-based neuron and synapse circuits directly. This paper presents a large-scale neuromorphic chip named Darwin3 with a novel instruction set architecture(ISA), which comprises 10 primary instructions and a few extended instructions. It supports flexible neuron model programming and local learning rule designs. The Darwin3 chip architecture is designed in a mesh of computing nodes with an innovative routing algorithm. We used a compression mechanism to represent synaptic connections, significantly reducing memory usage. The Darwin3 chip supports up to 2.35 million neurons, making it the largest of its kind in neuron scale. The experimental results showed that code density was improved up to 28.3x in Darwin3, and neuron core fan-in and fan-out were improved up to 4096x and 3072x by connection compression compared to the physical memory depth. Our Darwin3 chip also provided memory saving between 6.8X and 200.8X when mapping convolutional spiking neural networks (CSNN) onto the chip, demonstrating state-of-the-art performance in accuracy and latency compared to other neuromorphic chips.
Multi-Level Firing with Spiking DS-ResNet: Enabling Better and Deeper Directly-Trained Spiking Neural Networks
Oct 12, 2022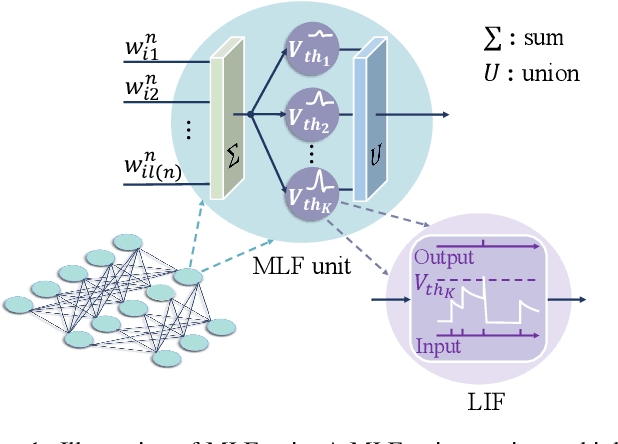
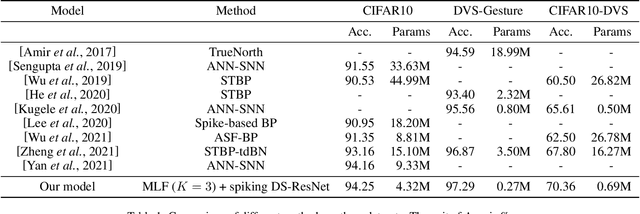
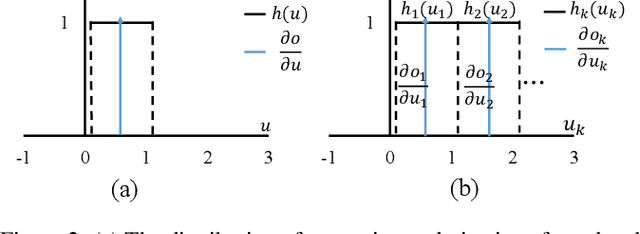

Spiking neural networks (SNNs) are bio-inspired neural networks with asynchronous discrete and sparse characteristics, which have increasingly manifested their superiority in low energy consumption. Recent research is devoted to utilizing spatio-temporal information to directly train SNNs by backpropagation. However, the binary and non-differentiable properties of spike activities force directly trained SNNs to suffer from serious gradient vanishing and network degradation, which greatly limits the performance of directly trained SNNs and prevents them from going deeper. In this paper, we propose a multi-level firing (MLF) method based on the existing spatio-temporal back propagation (STBP) method, and spiking dormant-suppressed residual network (spiking DS-ResNet). MLF enables more efficient gradient propagation and the incremental expression ability of the neurons. Spiking DS-ResNet can efficiently perform identity mapping of discrete spikes, as well as provide a more suitable connection for gradient propagation in deep SNNs. With the proposed method, our model achieves superior performances on a non-neuromorphic dataset and two neuromorphic datasets with much fewer trainable parameters and demonstrates the great ability to combat the gradient vanishing and degradation problem in deep SNNs.