 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Object Hallucinations in MLLMs via Multi-Frequency Perturbations
Mar 19, 2025Recently, multimodal large language models (MLLMs) have demonstrated remarkable performance in visual-language tasks. However, the authenticity of the responses generated by MLLMs is often compromised by object hallucinations. We identify that a key cause of these hallucinations is the model's over-susceptibility to specific image frequency features in detecting objects. In this paper, we introduce Multi-Frequency Perturbations (MFP), a simple, cost-effective, and pluggable method that leverages both low-frequency and high-frequency features of images to perturb visual feature representations and explicitly suppress redundant frequency-domain features during inference, thereby mitigating hallucinations. Experimental results demonstrate that our method significantly mitigates object hallucinations across various model architectures. Furthermore, as a training-time method, MFP can be combined with inference-time methods to achieve state-of-the-art performance on the CHAIR benchmark.
Deep Reinforcement Learning-based Video-Haptic Radio Resource Slicing in Tactile Internet
Mar 18, 2025



Enabling video-haptic radio resource slicing in the Tactile Internet requires a sophisticated strategy to meet the distinct requirements of video and haptic data, ensure their synchronized transmission, and address the stringent latency demands of haptic feedback. This paper introduces a Deep Reinforcement Learning-based radio resource slicing framework that addresses video-haptic teleoperation challenges by dynamically balancing radio resources between the video and haptic modalities. The proposed framework employs a refined reward function that considers latency, packet loss, data rate, and the synchronization requirements of both modalities to optimize resource allocation. By catering to the specific service requirements of video-haptic teleoperation, the proposed framework achieves up to a 25% increase in user satisfaction over existing methods, while maintaining effective resource slicing with execution intervals up to 50 ms.
Highly Efficient Direct Analytics on Semantic-aware Time Series Data Compression
Mar 17, 2025



Semantic communication has emerged as a promising paradigm to tackle the challenges of massive growing data traffic and sustainable data communication. It shifts the focus from data fidelity to goal-oriented or task-oriented semantic transmission. While deep learning-based methods are commonly used for semantic encoding and decoding, they struggle with the sequential nature of time series data and high computation cost, particularly in resource-constrained IoT environments. Data compression plays a crucial role in reducing transmission and storage costs, yet traditional data compression methods fall short of the demands of goal-oriented communication systems. In this paper, we propose a novel method for direct analytics on time series data compressed by the SHRINK compression algorithm. Through experimentation using outlier detection as a case study, we show that our method outperforms baselines running on uncompressed data in multiple cases, with merely 1% difference in the worst case. Additionally, it achieves four times lower runtime on average and accesses approximately 10% of the data volume, which enables edge analytics with limited storage and computation power. These results demonstrate that our approach offers reliable, high-speed outlier detection analytics for diverse IoT applications while extracting semantics from time-series data, achieving high compression, and reducing data transmission.
U2AD: Uncertainty-based Unsupervised Anomaly Detection Framework for Detecting T2 Hyperintensity in MRI Spinal Cord
Mar 17, 2025T2 hyperintensities in spinal cord MR images are crucial biomarkers for conditions such as degenerative cervical myelopathy. However, current clinical diagnoses primarily rely on manual evaluation. Deep learning methods have shown promise in lesion detection, but most supervised approaches are heavily dependent on large, annotated datasets. Unsupervised anomaly detection (UAD) offers a compelling alternative by eliminating the need for abnormal data annotations. However, existing UAD methods rely on curated normal datasets and their performance frequently deteriorates when applied to clinical datasets due to domain shifts. We propose an Uncertainty-based Unsupervised Anomaly Detection framework, termed U2AD, to address these limitations. Unlike traditional methods, U2AD is designed to be trained and tested within the same clinical dataset, following a "mask-and-reconstruction" paradigm built on a Vision Transformer-based architecture. We introduce an uncertainty-guided masking strategy to resolve task conflicts between normal reconstruction and anomaly detection to achieve an optimal balance. Specifically, we employ a Monte-Carlo sampling technique to estimate reconstruction uncertainty mappings during training. By iteratively optimizing reconstruction training under the guidance of both epistemic and aleatoric uncertainty, U2AD reduces overall reconstruction variance while emphasizing regions. Experimental results demonstrate that U2AD outperforms existing supervised and unsupervised methods in patient-level identification and segment-level localization tasks. This framework establishes a new benchmark for incorporating uncertainty guidance into UAD, highlighting its clinical utility in addressing domain shifts and task conflicts in medical image anomaly detection. Our code is available: https://github.com/zhibaishouheilab/U2AD
MVD-HuGaS: Human Gaussians from a Single Image via 3D Human Multi-view Diffusion Prior
Mar 11, 2025



3D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating one back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction.Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.
Mitigating Ambiguities in 3D Classification with Gaussian Splatting
Mar 11, 20253D classification with point cloud input is a fundamental problem in 3D vision. However, due to the discrete nature and the insufficient material description of point cloud representations, there are ambiguities in distinguishing wire-like and flat surfaces, as well as transparent or reflective objects. To address these issues, we propose Gaussian Splatting (GS) point cloud-based 3D classification. We find that the scale and rotation coefficients in the GS point cloud help characterize surface types. Specifically, wire-like surfaces consist of multiple slender Gaussian ellipsoids, while flat surfaces are composed of a few flat Gaussian ellipsoids. Additionally, the opacity in the GS point cloud represents the transparency characteristics of objects. As a result, ambiguities in point cloud-based 3D classification can be mitigated utilizing GS point cloud as input. To verify the effectiveness of GS point cloud input, we construct the first real-world GS point cloud dataset in the community, which includes 20 categories with 200 objects in each category. Experiments not only validate the superiority of GS point cloud input, especially in distinguishing ambiguous objects, but also demonstrate the generalization ability across different classification methods.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
PFDial: A Structured Dialogue Instruction Fine-tuning Method Based on UML Flowcharts
Mar 09, 2025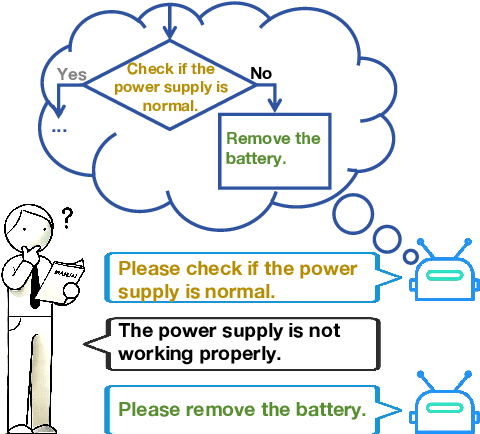
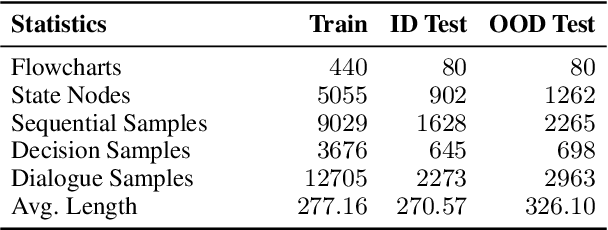
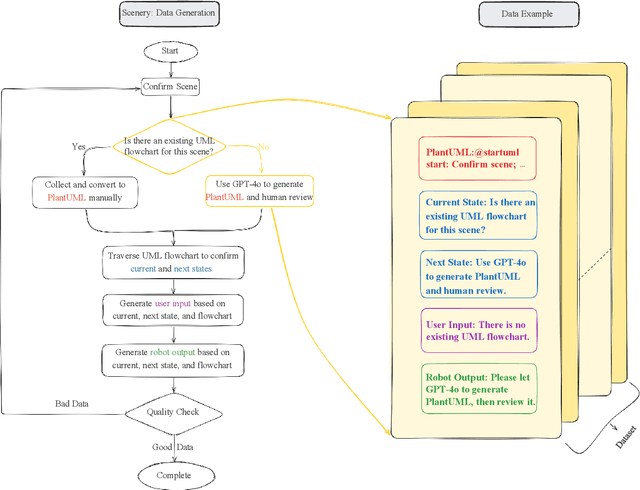
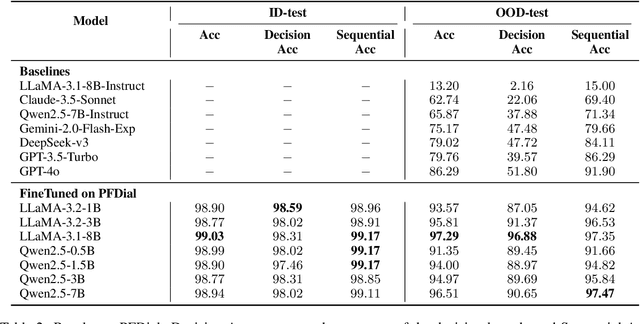
Process-driven dialogue systems, which operate under strict predefined process constraints, are essential in customer service and equipment maintenance scenarios. Although Large Language Models (LLMs) have shown remarkable progress in dialogue and reasoning, they still struggle to solve these strictly constrained dialogue tasks. To address this challenge, we construct Process Flow Dialogue (PFDial) dataset, which contains 12,705 high-quality Chinese dialogue instructions derived from 440 flowcharts containing 5,055 process nodes. Based on PlantUML specification, each UML flowchart is converted into atomic dialogue units i.e., structured five-tuples. Experimental results demonstrate that a 7B model trained with merely 800 samples, and a 0.5B model trained on total data both can surpass 90% accuracy. Additionally, the 8B model can surpass GPT-4o up to 43.88% with an average of 11.00%. We further evaluate models' performance on challenging backward transitions in process flows and conduct an in-depth analysis of various dataset formats to reveal their impact on model performance in handling decision and sequential branches. The data is released in https://github.com/KongLongGeFDU/PFDial.
Pathology-Guided AI System for Accurate Segmentation and Diagnosis of Cervical Spondylosis
Mar 08, 2025



Cervical spondylosis, a complex and prevalent condition, demands precise and efficient diagnostic techniques for accurate assessment. While MRI offers detailed visualization of cervical spine anatomy, manual interpretation remains labor-intensive and prone to error. To address this, we developed an innovative AI-assisted Expert-based Diagnosis System that automates both segmentation and diagnosis of cervical spondylosis using MRI. Leveraging a dataset of 960 cervical MRI images from patients with cervical disc herniation, our system features a pathology-guided segmentation model capable of accurately segmenting key cervical anatomical structures. The segmentation is followed by an expert-based diagnostic framework that automates the calculation of critical clinical indicators. Our segmentation model achieved an impressive average Dice coefficient exceeding 0.90 across four cervical spinal anatomies and demonstrated enhanced accuracy in herniation areas. Diagnostic evaluation further showcased the system precision, with a mean absolute error (MAE) of 2.44 degree for the C2-C7 Cobb angle and 3.60 precentage for the Maximum Spinal Cord Compression (MSCC) coefficient. In addition, our method delivered high accuracy, precision, recall, and F1 scores in herniation localization, K-line status assessment, and T2 hyperintensity detection. Comparative analysis demonstrates that our system outperforms existing methods, establishing a new benchmark for segmentation and diagnostic tasks for cervical spondylosis.
HealthiVert-GAN: A Novel Framework of Pseudo-Healthy Vertebral Image Synthesis for Interpretable Compression Fracture Grading
Mar 08, 2025Osteoporotic vertebral compression fractures (VCFs) are prevalent in the elderly population, typically assessed on computed tomography (CT) scans by evaluating vertebral height loss. This assessment helps determine the fracture's impact on spinal stability and the need for surgical intervention. However, clinical data indicate that many VCFs exhibit irregular compression, complicating accurate diagnosis. While deep learning methods have shown promise in aiding VCFs screening, they often lack interpretability and sufficient sensitivity, limiting their clinical applicability. To address these challenges, we introduce a novel vertebra synthesis-height loss quantification-VCFs grading framework. Our proposed model, HealthiVert-GAN, utilizes a coarse-to-fine synthesis network designed to generate pseudo-healthy vertebral images that simulate the pre-fracture state of fractured vertebrae. This model integrates three auxiliary modules that leverage the morphology and height information of adjacent healthy vertebrae to ensure anatomical consistency. Additionally, we introduce the Relative Height Loss of Vertebrae (RHLV) as a quantification metric, which divides each vertebra into three sections to measure height loss between pre-fracture and post-fracture states, followed by fracture severity classification using a Support Vector Machine (SVM). Our approach achieves state-of-the-art classification performance on both the Verse2019 dataset and our private dataset, and it provides cross-sectional distribution maps of vertebral height loss. This practical tool enhances diagnostic sensitivity in clinical settings and assisting in surgical decision-making. Our code is available: https://github.com/zhibaishouheilab/HealthiVert-GAN.