 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLTime: A Cross-Lingual Knowledge Transfer Framework for Temporal Expression Extraction
May 03, 2022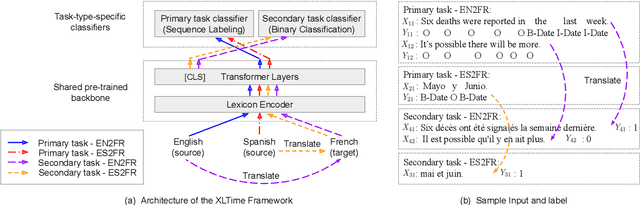
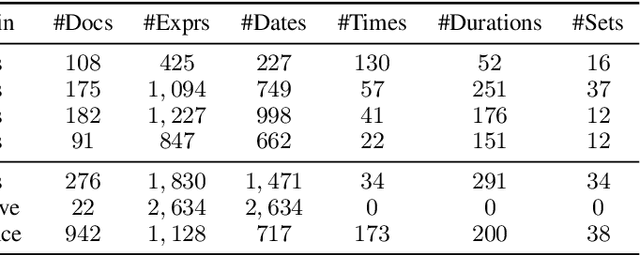
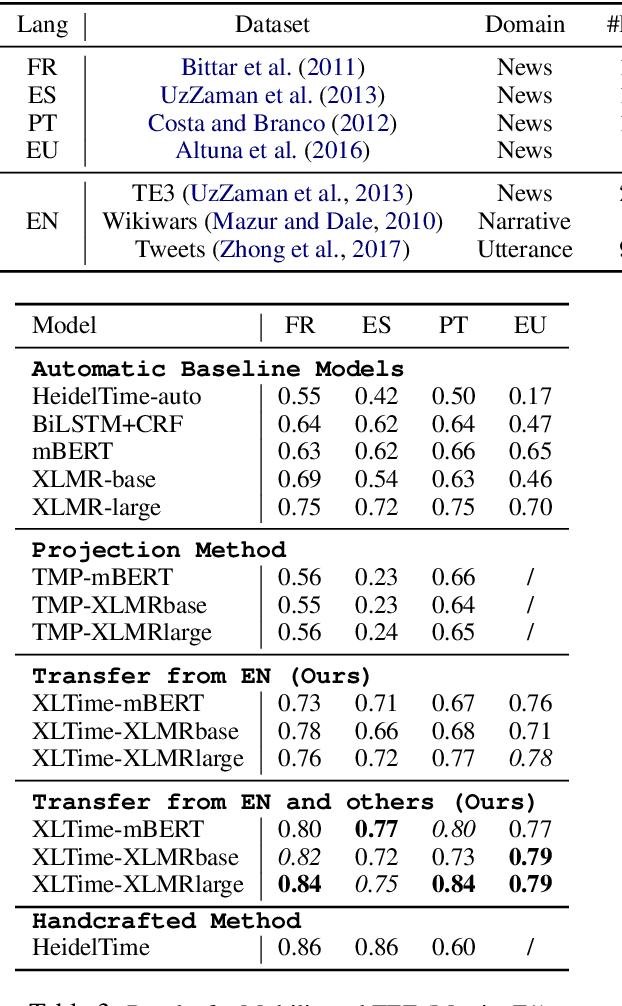
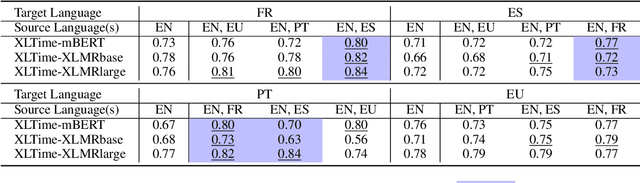
Temporal Expression Extraction (TEE) is essential for understanding time in natural language. It has applications in Natural Language Processing (NLP) tasks such as question answering, information retrieval, and causal inference. To date, work in this area has mostly focused on English as there is a scarcity of labeled data for other languages. We propose XLTime, a novel framework for multilingual TEE. XLTime works on top of pre-trained language models and leverages multi-task learning to prompt cross-language knowledge transfer both from English and within the non-English languages. XLTime alleviates problems caused by a shortage of data in the target language. We apply XLTime with different language models and show that it outperforms the previous automatic SOTA methods on French, Spanish, Portuguese, and Basque, by large margins. XLTime also closes the gap considerably on the handcrafted HeidelTime method.
PyGOD: A Python Library for Graph Outlier Detection
Apr 26, 2022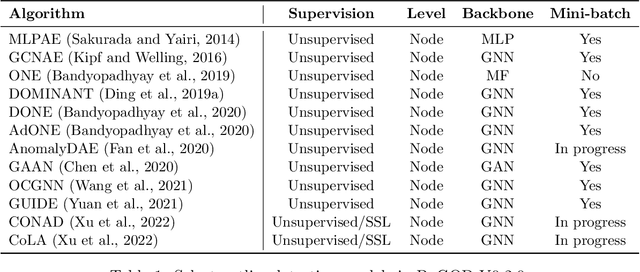
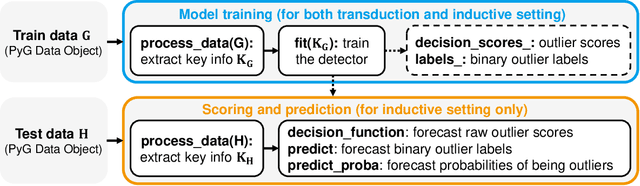
PyGOD is an open-source Python library for detecting outliers on graph data. As the first comprehensive library of its kind, PyGOD supports a wide array of leading graph-based methods for node-, edge-, subgraph-, and graph-level outlier detection, under a unified, well-documented API designed for use by both researchers and practitioners. To overcome the scalability issue in large graphs, we provide advanced functionalities for selected models, including mini-batch and sampling. PyGOD is equipped with best practices to foster code reliability and maintainability, including unit testing, continuous integration, and code coverage. To foster accessibility, PyGOD is released under a permissive BSD-license at https://github.com/pygod-team/pygod/ and the Python Package Index (PyPI).
Multifaceted Improvements for Conversational Open-Domain Question Answering
Apr 01, 2022
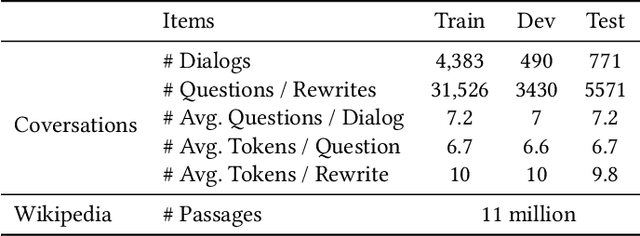
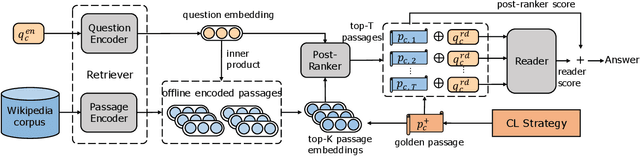
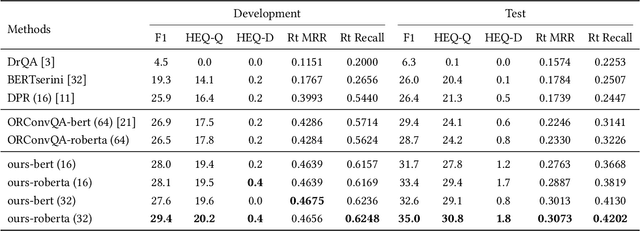
Open-domain question answering (OpenQA) is an important branch of textual QA which discovers answers for the given questions based on a large number of unstructured documents. Effectively mining correct answers from the open-domain sources still has a fair way to go. Existing OpenQA systems might suffer from the issues of question complexity and ambiguity, as well as insufficient background knowledge. Recently, conversational OpenQA is proposed to address these issues with the abundant contextual information in the conversation. Promising as it might be, there exist several fundamental limitations including the inaccurate question understanding, the coarse ranking for passage selection, and the inconsistent usage of golden passage in the training and inference phases. To alleviate these limitations, in this paper, we propose a framework with Multifaceted Improvements for Conversational open-domain Question Answering (MICQA). Specifically, MICQA has three significant advantages. First, the proposed KL-divergence based regularization is able to lead to a better question understanding for retrieval and answer reading. Second, the added post-ranker module can push more relevant passages to the top placements and be selected for reader with a two-aspect constrains. Third, the well designed curriculum learning strategy effectively narrows the gap between the golden passage settings of training and inference, and encourages the reader to find true answer without the golden passage assistance. Extensive experiments conducted on the publicly available dataset OR-QuAC demonstrate the superiority of MICQA over the state-of-the-art model in conversational OpenQA task.
Improving Contrastive Learning with Model Augmentation
Mar 25, 2022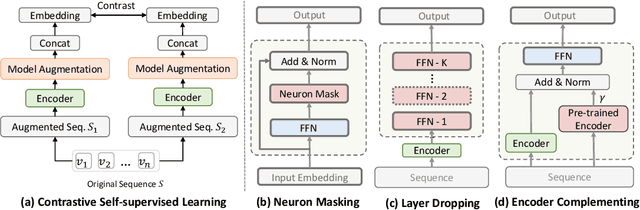
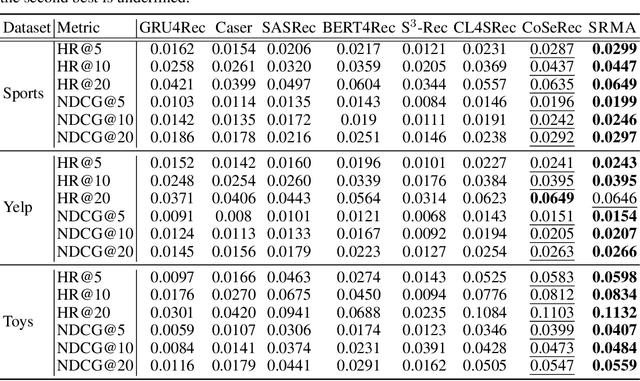
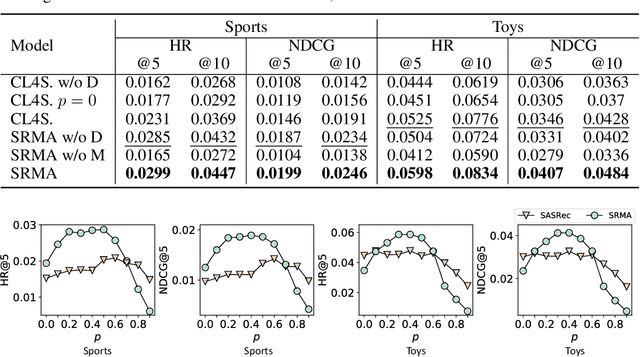
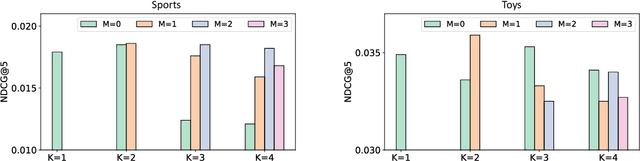
The sequential recommendation aims at predicting the next items in user behaviors, which can be solved by characterizing item relationships in sequences. Due to the data sparsity and noise issues in sequences, a new self-supervised learning (SSL) paradigm is proposed to improve the performance, which employs contrastive learning between positive and negative views of sequences. However, existing methods all construct views by adopting augmentation from data perspectives, while we argue that 1) optimal data augmentation methods are hard to devise, 2) data augmentation methods destroy sequential correlations, and 3) data augmentation fails to incorporate comprehensive self-supervised signals. Therefore, we investigate the possibility of model augmentation to construct view pairs. We propose three levels of model augmentation methods: neuron masking, layer dropping, and encoder complementing. This work opens up a novel direction in constructing views for contrastive SSL. Experiments verify the efficacy of model augmentation for the SSL in the sequential recommendation. Code is available\footnote{\url{https://github.com/salesforce/SRMA}}.
Deep Reinforcement Learning Guided Graph Neural Networks for Brain Network Analysis
Mar 18, 2022
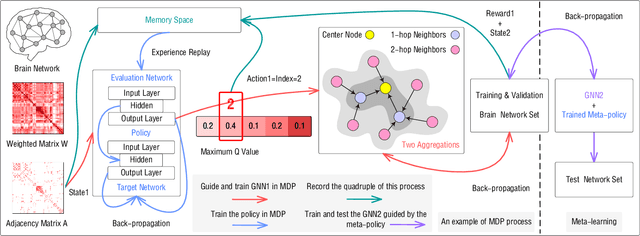

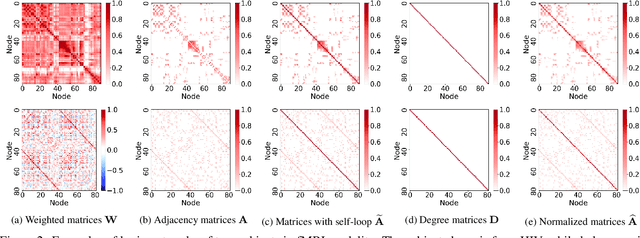
Modern neuroimaging techniques, such as diffusion tensor imaging (DTI) and functional magnetic resonance imaging (fMRI), enable us to model the human brain as a brain network or connectome. Capturing brain networks' structural information and hierarchical patterns is essential for understanding brain functions and disease states. Recently, the promising network representation learning capability of graph neural networks (GNNs) has prompted many GNN-based methods for brain network analysis to be proposed. Specifically, these methods apply feature aggregation and global pooling to convert brain network instances into meaningful low-dimensional representations used for downstream brain network analysis tasks. However, existing GNN-based methods often neglect that brain networks of different subjects may require various aggregation iterations and use GNN with a fixed number of layers to learn all brain networks. Therefore, how to fully release the potential of GNNs to promote brain network analysis is still non-trivial. To solve this problem, we propose a novel brain network representation framework, namely BN-GNN, which searches for the optimal GNN architecture for each brain network. Concretely, BN-GNN employs deep reinforcement learning (DRL) to train a meta-policy to automatically determine the optimal number of feature aggregations (reflected in the number of GNN layers) required for a given brain network. Extensive experiments on eight real-world brain network datasets demonstrate that our proposed BN-GNN improves the performance of traditional GNNs on different brain network analysis tasks.
G$^3$SR: Global Graph Guided Session-based Recommendation
Mar 12, 2022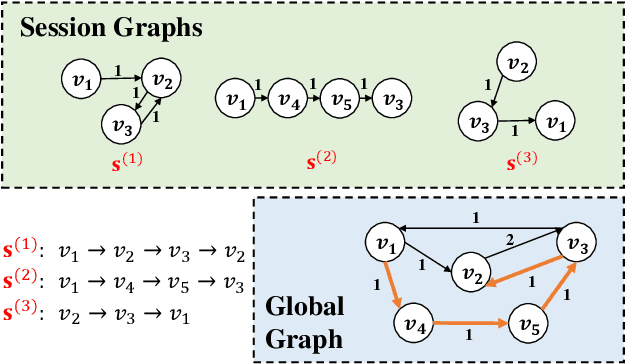
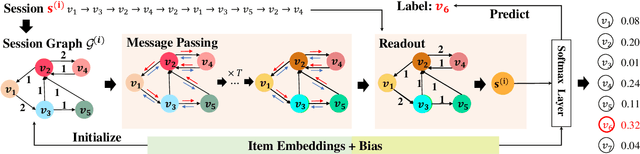
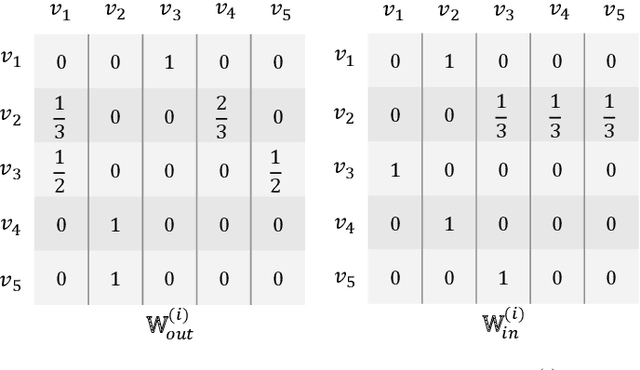
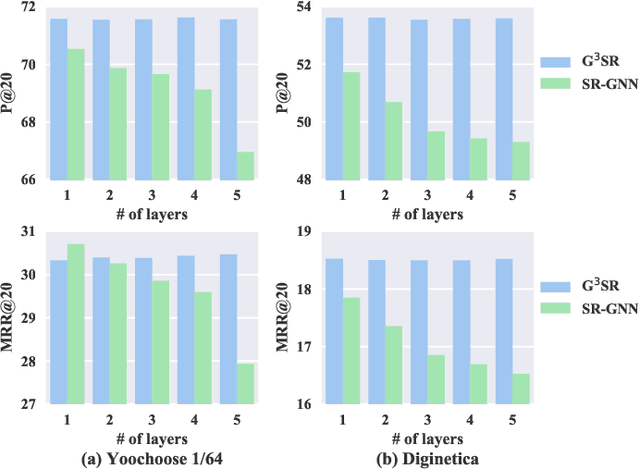
Session-based recommendation tries to make use of anonymous session data to deliver high-quality recommendation under the condition that user-profiles and the complete historical behavioral data of a target user are unavailable. Previous works consider each session individually and try to capture user interests within a session. Despite their encouraging results, these models can only perceive intra-session items and cannot draw upon the massive historical relational information. To solve this problem, we propose a novel method named G$^3$SR (Global Graph Guided Session-based Recommendation). G$^3$SR decomposes the session-based recommendation workflow into two steps. First, a global graph is built upon all session data, from which the global item representations are learned in an unsupervised manner. Then, these representations are refined on session graphs under the graph networks, and a readout function is used to generate session representations for each session. Extensive experiments on two real-world benchmark datasets show remarkable and consistent improvements of the G$^3$SR method over the state-of-the-art methods, especially for cold items.
Attend, Memorize and Generate: Towards Faithful Table-to-Text Generation in Few Shots
Mar 01, 2022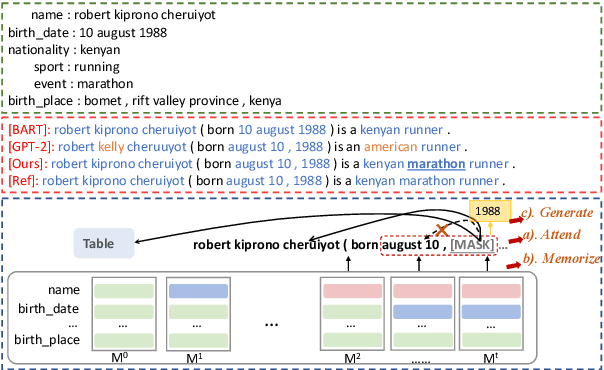
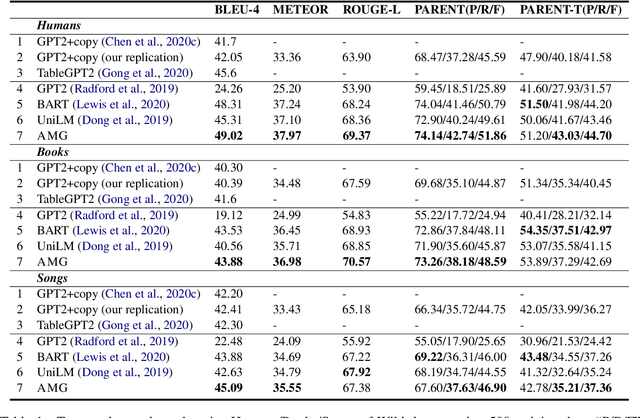
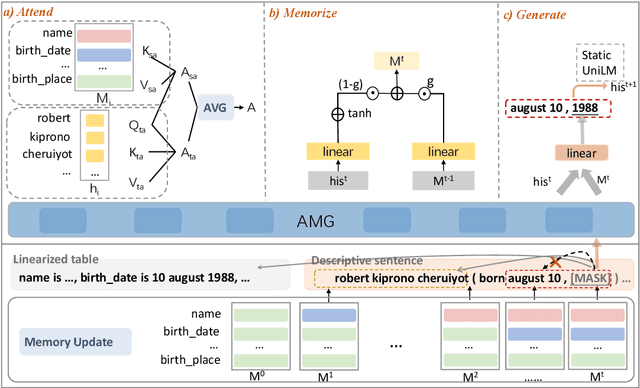

Few-shot table-to-text generation is a task of composing fluent and faithful sentences to convey table content using limited data. Despite many efforts having been made towards generating impressive fluent sentences by fine-tuning powerful pre-trained language models, the faithfulness of generated content still needs to be improved. To this end, this paper proposes a novel approach Attend, Memorize and Generate (called AMG), inspired by the text generation process of humans. In particular, AMG (1) attends over the multi-granularity of context using a novel strategy based on table slot level and traditional token-by-token level attention to exploit both the table structure and natural linguistic information; (2) dynamically memorizes the table slot allocation states; and (3) generates faithful sentences according to both the context and memory allocation states. Comprehensive experiments with human evaluation on three domains (i.e., humans, songs, and books) of the Wiki dataset show that our model can generate higher qualified texts when compared with several state-of-the-art baselines, in both fluency and faithfulness.
TaSPM: Targeted Sequential Pattern Mining
Feb 26, 2022
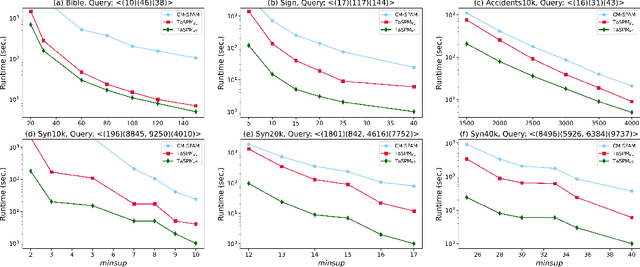
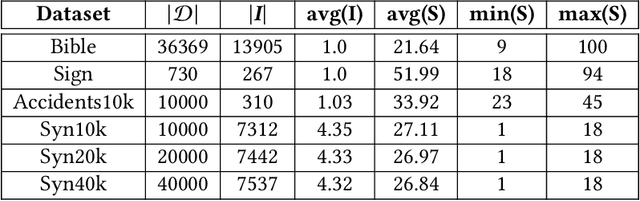
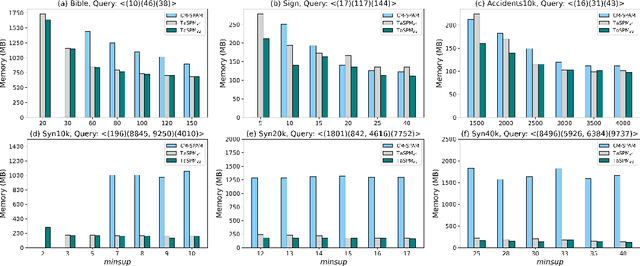
Sequential pattern mining (SPM) is an important technique of pattern mining, which has many applications in reality. Although many efficient sequential pattern mining algorithms have been proposed, there are few studies can focus on target sequences. Targeted querying sequential patterns can not only reduce the number of sequences generated by SPM, but also improve the efficiency of users in performing pattern analysis. The current algorithms available on targeted sequence querying are based on specific scenarios and cannot be generalized to other applications. In this paper, we formulate the problem of targeted sequential pattern mining and propose a generic framework namely TaSPM, based on the fast CM-SPAM algorithm. What's more, to improve the efficiency of TaSPM on large-scale datasets and multiple-items-based sequence datasets, we propose several pruning strategies to reduce meaningless operations in mining processes. Totally four pruning strategies are designed in TaSPM, and hence it can terminate unnecessary pattern extensions quickly and achieve better performance. Finally, we conduct extensive experiments on different datasets to compare the existing SPM algorithms with TaSPM. Experiments show that the novel targeted mining algorithm TaSPM can achieve faster running time and less memory consumption.
Towards Revenue Maximization with Popular and Profitable Products
Feb 26, 2022
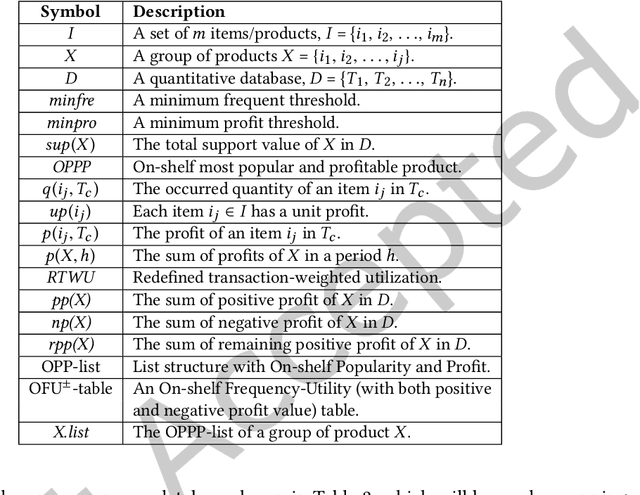

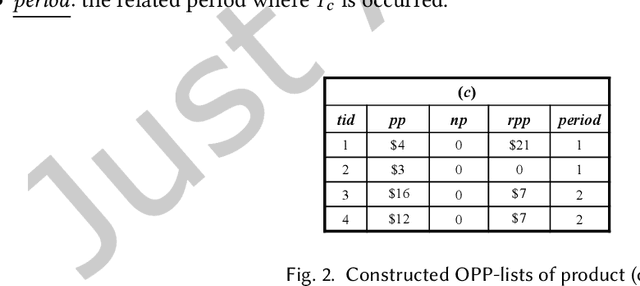
Economic-wise, a common goal for companies conducting marketing is to maximize the return revenue/profit by utilizing the various effective marketing strategies. Consumer behavior is crucially important in economy and targeted marketing, in which behavioral economics can provide valuable insights to identify the biases and profit from customers. Finding credible and reliable information on products' profitability is, however, quite difficult since most products tends to peak at certain times w.r.t. seasonal sales cycle in a year. On-Shelf Availability (OSA) plays a key factor for performance evaluation. Besides, staying ahead of hot product trends means we can increase marketing efforts without selling out the inventory. To fulfill this gap, in this paper, we first propose a general profit-oriented framework to address the problem of revenue maximization based on economic behavior, and compute the 0n-shelf Popular and most Profitable Products (OPPPs) for the targeted marketing. To tackle the revenue maximization problem, we model the k-satisfiable product concept and propose an algorithmic framework for searching OPPP and its variants. Extensive experiments are conducted on several real-world datasets to evaluate the effectiveness and efficiency of the proposed algorithm.
Graph Neural Networks for Graphs with Heterophily: A Survey
Feb 14, 2022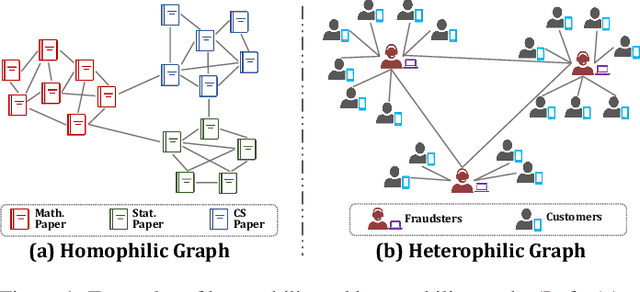
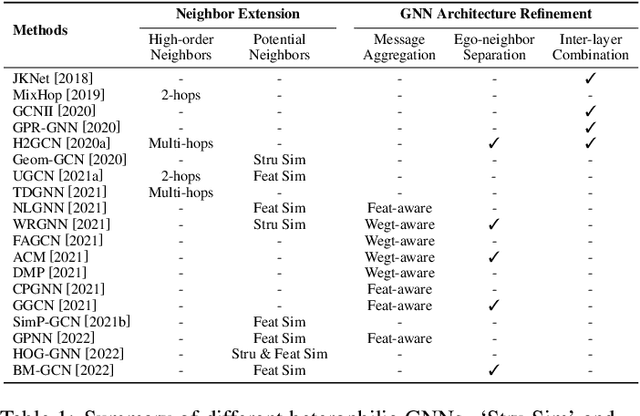
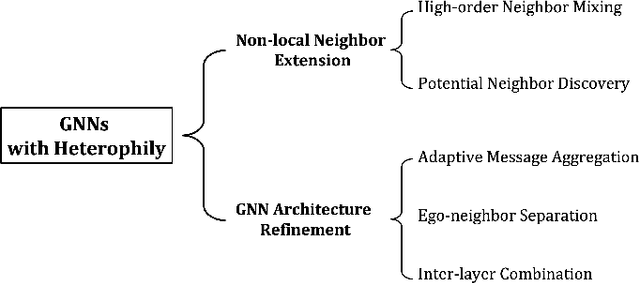
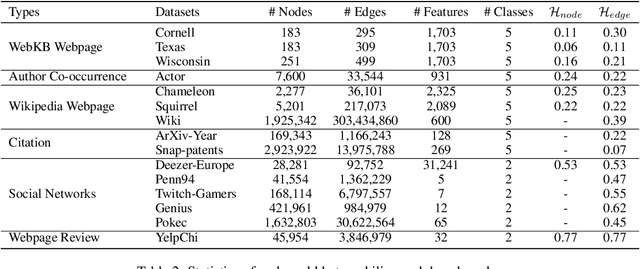
Recent years have witnessed fast developments of graph neural networks (GNNs) that have benefited myriads of graph analytic tasks and applications. In general, most GNNs depend on the homophily assumption that nodes belonging to the same class are more likely to be connected. However, as a ubiquitous graph property in numerous real-world scenarios, heterophily, i.e., nodes with different labels tend to be linked, significantly limits the performance of tailor-made homophilic GNNs. Hence, \textit{GNNs for heterophilic graphs} are gaining increasing attention in this community. To the best of our knowledge, in this paper, we provide a comprehensive review of GNNs for heterophilic graphs for the first time. Specifically, we propose a systematic taxonomy that essentially governs existing heterophilic GNN models, along with a general summary and detailed analysis. Furthermore, we summarize the mainstream heterophilic graph benchmarks to facilitate robust and fair evaluations. In the end, we point out the potential directions to advance and stimulate future research and applications on heterophilic graphs.