 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequent subgraph-based persistent homology for graph classification
Dec 31, 2025Persistent homology (PH) has recently emerged as a powerful tool for extracting topological features. Integrating PH into machine learning and deep learning models enhances topology awareness and interpretability. However, most PH methods on graphs rely on a limited set of filtrations, such as degree-based or weight-based filtrations, which overlook richer features like recurring information across the dataset and thus restrict expressive power. In this work, we propose a novel graph filtration called Frequent Subgraph Filtration (FSF), which is derived from frequent subgraphs and produces stable and information-rich frequency-based persistent homology (FPH) features. We study the theoretical properties of FSF and provide both proofs and experimental validation. Beyond persistent homology itself, we introduce two approaches for graph classification: an FPH-based machine learning model (FPH-ML) and a hybrid framework that integrates FPH with graph neural networks (FPH-GNNs) to enhance topology-aware graph representation learning. Our frameworks bridge frequent subgraph mining and topological data analysis, offering a new perspective on topology-aware feature extraction. Experimental results show that FPH-ML achieves competitive or superior accuracy compared with kernel-based and degree-based filtration methods. When integrated into graph neural networks, FPH yields relative performance gains ranging from 0.4 to 21 percent, with improvements of up to 8.2 percentage points over GCN and GIN backbones across benchmarks.
Graph Attention-based Adaptive Transfer Learning for Link Prediction
Dec 24, 2025Graph neural networks (GNNs) have brought revolutionary advancements to the field of link prediction (LP), providing powerful tools for mining potential relationships in graphs. However, existing methods face challenges when dealing with large-scale sparse graphs and the need for a high degree of alignment between different datasets in transfer learning. Besides, although self-supervised methods have achieved remarkable success in many graph tasks, prior research has overlooked the potential of transfer learning to generalize across different graph datasets. To address these limitations, we propose a novel Graph Attention Adaptive Transfer Network (GAATNet). It combines the advantages of pre-training and fine-tuning to capture global node embedding information across datasets of different scales, ensuring efficient knowledge transfer and improved LP performance. To enhance the model's generalization ability and accelerate training, we design two key strategies: 1) Incorporate distant neighbor embeddings as biases in the self-attention module to capture global features. 2) Introduce a lightweight self-adapter module during fine-tuning to improve training efficiency. Comprehensive experiments on seven public datasets demonstrate that GAATNet achieves state-of-the-art performance in LP tasks. This study provides a general and scalable solution for LP tasks to effectively integrate GNNs with transfer learning. The source code and datasets are publicly available at https://github.com/DSI-Lab1/GAATNet
Towards Revenue Maximization with Popular and Profitable Products
Feb 26, 2022

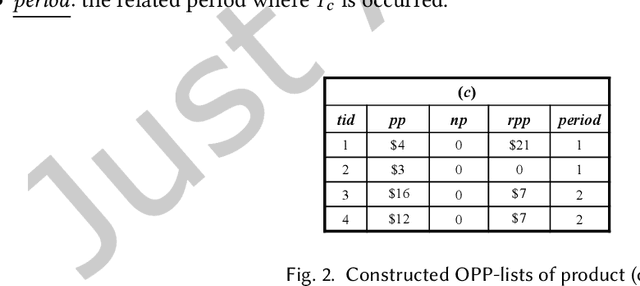
Economic-wise, a common goal for companies conducting marketing is to maximize the return revenue/profit by utilizing the various effective marketing strategies. Consumer behavior is crucially important in economy and targeted marketing, in which behavioral economics can provide valuable insights to identify the biases and profit from customers. Finding credible and reliable information on products' profitability is, however, quite difficult since most products tends to peak at certain times w.r.t. seasonal sales cycle in a year. On-Shelf Availability (OSA) plays a key factor for performance evaluation. Besides, staying ahead of hot product trends means we can increase marketing efforts without selling out the inventory. To fulfill this gap, in this paper, we first propose a general profit-oriented framework to address the problem of revenue maximization based on economic behavior, and compute the 0n-shelf Popular and most Profitable Products (OPPPs) for the targeted marketing. To tackle the revenue maximization problem, we model the k-satisfiable product concept and propose an algorithmic framework for searching OPPP and its variants. Extensive experiments are conducted on several real-world datasets to evaluate the effectiveness and efficiency of the proposed algorithm.