 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Temporal Awareness in LLMs for Temporal Point Processes
Dec 29, 2025Temporal point processes (TPPs) are crucial for analyzing events over time and are widely used in fields such as finance, healthcare, and social systems. These processes are particularly valuable for understanding how events unfold over time, accounting for their irregularity and dependencies. Despite the success of large language models (LLMs) in sequence modeling, applying them to temporal point processes remains challenging. A key issue is that current methods struggle to effectively capture the complex interaction between temporal information and semantic context, which is vital for accurate event modeling. In this context, we introduce TPP-TAL (Temporal Point Processes with Enhanced Temporal Awareness in LLMs), a novel plug-and-play framework designed to enhance temporal reasoning within LLMs. Rather than using the conventional method of simply concatenating event time and type embeddings, TPP-TAL explicitly aligns temporal dynamics with contextual semantics before feeding this information into the LLM. This alignment allows the model to better perceive temporal dependencies and long-range interactions between events and their surrounding contexts. Through comprehensive experiments on several benchmark datasets, it is shown that TPP-TAL delivers substantial improvements in temporal likelihood estimation and event prediction accuracy, highlighting the importance of enhancing temporal awareness in LLMs for continuous-time event modeling. The code is made available at https://github.com/chenlilil/TPP-TAL
Graph Attention-based Adaptive Transfer Learning for Link Prediction
Dec 24, 2025Graph neural networks (GNNs) have brought revolutionary advancements to the field of link prediction (LP), providing powerful tools for mining potential relationships in graphs. However, existing methods face challenges when dealing with large-scale sparse graphs and the need for a high degree of alignment between different datasets in transfer learning. Besides, although self-supervised methods have achieved remarkable success in many graph tasks, prior research has overlooked the potential of transfer learning to generalize across different graph datasets. To address these limitations, we propose a novel Graph Attention Adaptive Transfer Network (GAATNet). It combines the advantages of pre-training and fine-tuning to capture global node embedding information across datasets of different scales, ensuring efficient knowledge transfer and improved LP performance. To enhance the model's generalization ability and accelerate training, we design two key strategies: 1) Incorporate distant neighbor embeddings as biases in the self-attention module to capture global features. 2) Introduce a lightweight self-adapter module during fine-tuning to improve training efficiency. Comprehensive experiments on seven public datasets demonstrate that GAATNet achieves state-of-the-art performance in LP tasks. This study provides a general and scalable solution for LP tasks to effectively integrate GNNs with transfer learning. The source code and datasets are publicly available at https://github.com/DSI-Lab1/GAATNet
Event Extraction in Large Language Model
Dec 22, 2025Large language models (LLMs) and multimodal LLMs are changing event extraction (EE): prompting and generation can often produce structured outputs in zero shot or few shot settings. Yet LLM based pipelines face deployment gaps, including hallucinations under weak constraints, fragile temporal and causal linking over long contexts and across documents, and limited long horizon knowledge management within a bounded context window. We argue that EE should be viewed as a system component that provides a cognitive scaffold for LLM centered solutions. Event schemas and slot constraints create interfaces for grounding and verification; event centric structures act as controlled intermediate representations for stepwise reasoning; event links support relation aware retrieval with graph based RAG; and event stores offer updatable episodic and agent memory beyond the context window. This survey covers EE in text and multimodal settings, organizing tasks and taxonomy, tracing method evolution from rule based and neural models to instruction driven and generative frameworks, and summarizing formulations, decoding strategies, architectures, representations, datasets, and evaluation. We also review cross lingual, low resource, and domain specific settings, and highlight open challenges and future directions for reliable event centric systems. Finally, we outline open challenges and future directions that are central to the LLM era, aiming to evolve EE from static extraction into a structurally reliable, agent ready perception and memory layer for open world systems.
Detecting Hallucinations in Graph Retrieval-Augmented Generation via Attention Patterns and Semantic Alignment
Dec 09, 2025Graph-based Retrieval-Augmented Generation (GraphRAG) enhances Large Language Models (LLMs) by incorporating external knowledge from linearized subgraphs retrieved from knowledge graphs. However, LLMs struggle to interpret the relational and topological information in these inputs, resulting in hallucinations that are inconsistent with the retrieved knowledge. To analyze how LLMs attend to and retain structured knowledge during generation, we propose two lightweight interpretability metrics: Path Reliance Degree (PRD), which measures over-reliance on shortest-path triples, and Semantic Alignment Score (SAS), which assesses how well the model's internal representations align with the retrieved knowledge. Through empirical analysis on a knowledge-based QA task, we identify failure patterns associated with over-reliance on salient paths and weak semantic grounding, as indicated by high PRD and low SAS scores. We further develop a lightweight post-hoc hallucination detector, Graph Grounding and Alignment (GGA), which outperforms strong semantic and confidence-based baselines across AUC and F1. By grounding hallucination analysis in mechanistic interpretability, our work offers insights into how structural limitations in LLMs contribute to hallucinations, informing the design of more reliable GraphRAG systems in the future.
LLM-MemCluster: Empowering Large Language Models with Dynamic Memory for Text Clustering
Nov 19, 2025Large Language Models (LLMs) are reshaping unsupervised learning by offering an unprecedented ability to perform text clustering based on their deep semantic understanding. However, their direct application is fundamentally limited by a lack of stateful memory for iterative refinement and the difficulty of managing cluster granularity. As a result, existing methods often rely on complex pipelines with external modules, sacrificing a truly end-to-end approach. We introduce LLM-MemCluster, a novel framework that reconceptualizes clustering as a fully LLM-native task. It leverages a Dynamic Memory to instill state awareness and a Dual-Prompt Strategy to enable the model to reason about and determine the number of clusters. Evaluated on several benchmark datasets, our tuning-free framework significantly and consistently outperforms strong baselines. LLM-MemCluster presents an effective, interpretable, and truly end-to-end paradigm for LLM-based text clustering.
S$^2$Drug: Bridging Protein Sequence and 3D Structure in Contrastive Representation Learning for Virtual Screening
Nov 10, 2025Virtual screening (VS) is an essential task in drug discovery, focusing on the identification of small-molecule ligands that bind to specific protein pockets. Existing deep learning methods, from early regression models to recent contrastive learning approaches, primarily rely on structural data while overlooking protein sequences, which are more accessible and can enhance generalizability. However, directly integrating protein sequences poses challenges due to the redundancy and noise in large-scale protein-ligand datasets. To address these limitations, we propose \textbf{S$^2$Drug}, a two-stage framework that explicitly incorporates protein \textbf{S}equence information and 3D \textbf{S}tructure context in protein-ligand contrastive representation learning. In the first stage, we perform protein sequence pretraining on ChemBL using an ESM2-based backbone, combined with a tailored data sampling strategy to reduce redundancy and noise on both protein and ligand sides. In the second stage, we fine-tune on PDBBind by fusing sequence and structure information through a residue-level gating module, while introducing an auxiliary binding site prediction task. This auxiliary task guides the model to accurately localize binding residues within the protein sequence and capture their 3D spatial arrangement, thereby refining protein-ligand matching. Across multiple benchmarks, S$^2$Drug consistently improves virtual screening performance and achieves strong results on binding site prediction, demonstrating the value of bridging sequence and structure in contrastive learning.
GRAVER: Generative Graph Vocabularies for Robust Graph Foundation Models Fine-tuning
Nov 05, 2025



Inspired by the remarkable success of foundation models in language and vision, Graph Foundation Models (GFMs) hold significant promise for broad applicability across diverse graph tasks and domains. However, existing GFMs struggle with unstable few-shot fine-tuning, where both performance and adaptation efficiency exhibit significant fluctuations caused by the randomness in the support sample selection and structural discrepancies between the pre-trained and target graphs. How to fine-tune GFMs robustly and efficiently to enable trustworthy knowledge transfer across domains and tasks is the major challenge. In this paper, we propose GRAVER, a novel Generative gRAph VocabulariEs for Robust GFM fine-tuning framework that tackles the aforementioned instability via generative augmentations. Specifically, to identify transferable units, we analyze and extract key class-specific subgraph patterns by ego-graph disentanglement and validate their transferability both theoretically and empirically. To enable effective pre-training across diverse domains, we leverage a universal task template based on ego-graph similarity and construct graph vocabularies via graphon-based generative experts. To facilitate robust and efficient prompt fine-tuning, we grave the support samples with in-context vocabularies, where the lightweight MoE-CoE network attentively routes knowledge from source domains. Extensive experiments demonstrate the superiority of GRAVER over effectiveness, robustness, and efficiency on downstream few-shot node and graph classification tasks compared with 15 state-of-the-art baselines.
Robust Graph Condensation via Classification Complexity Mitigation
Oct 30, 2025Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of \ModelName\ across diverse attack scenarios.
Glocal Information Bottleneck for Time Series Imputation
Oct 06, 2025



Time Series Imputation (TSI), which aims to recover missing values in temporal data, remains a fundamental challenge due to the complex and often high-rate missingness in real-world scenarios. Existing models typically optimize the point-wise reconstruction loss, focusing on recovering numerical values (local information). However, we observe that under high missing rates, these models still perform well in the training phase yet produce poor imputations and distorted latent representation distributions (global information) in the inference phase. This reveals a critical optimization dilemma: current objectives lack global guidance, leading models to overfit local noise and fail to capture global information of the data. To address this issue, we propose a new training paradigm, Glocal Information Bottleneck (Glocal-IB). Glocal-IB is model-agnostic and extends the standard IB framework by introducing a Global Alignment loss, derived from a tractable mutual information approximation. This loss aligns the latent representations of masked inputs with those of their originally observed counterparts. It helps the model retain global structure and local details while suppressing noise caused by missing values, giving rise to better generalization under high missingness. Extensive experiments on nine datasets confirm that Glocal-IB leads to consistently improved performance and aligned latent representations under missingness. Our code implementation is available in https://github.com/Muyiiiii/NeurIPS-25-Glocal-IB.
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025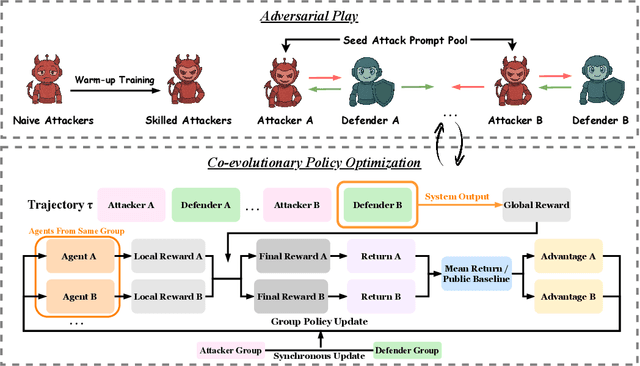

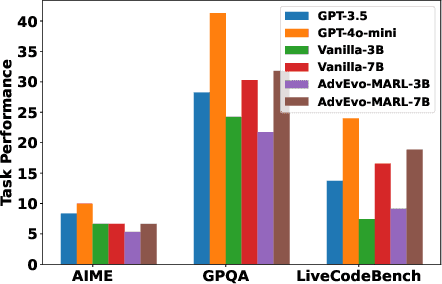
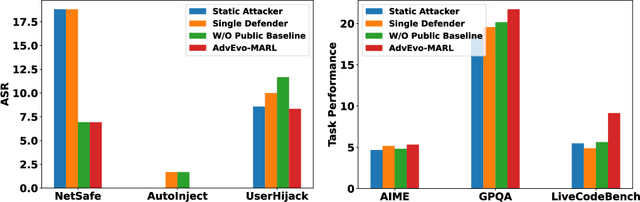
LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.