 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Dependent Safety Failures in Multi-Turn Language Model Interaction
Mar 15, 2026Safety alignment in large language models is typically evaluated under isolated queries, yet real-world use is inherently multi-turn. Although multi-turn jailbreaks are empirically effective, the structure of conversational safety failure remains insufficiently understood. In this work, we study safety failures from a state-space perspective and show that many multi-turn failures arise from structured contextual state evolution rather than isolated prompt vulnerabilities. We introduce STAR, a state-oriented diagnostic framework that treats dialogue history as a state transition operator and enables controlled analysis of safety behavior along interaction trajectories. Rather than optimizing attack strength, STAR provides a principled probe of how aligned models traverse the safety boundary under autoregressive conditioning. Across multiple frontier language models, we find that systems that appear robust under static evaluation can undergo rapid and reproducible safety collapse under structured multi-turn interaction. Mechanistic analysis reveals monotonic drift away from refusal-related representations and abrupt phase transitions induced by role-conditioned context. Together, these findings motivate viewing language model safety as a dynamic, state-dependent process defined over conversational trajectories.
PointCoT: A Multi-modal Benchmark for Explicit 3D Geometric Reasoning
Feb 27, 2026While Multimodal Large Language Models (MLLMs) demonstrate proficiency in 2D scenes, extending their perceptual intelligence to 3D point cloud understanding remains a significant challenge. Current approaches focus primarily on aligning 3D features with pre-trained models. However, they typically treat geometric reasoning as an implicit mapping process. These methods bypass intermediate logical steps and consequently suffer from geometric hallucinations. They confidently generate plausible responses that fail to ground in precise structural details. To bridge this gap, we present PointCoT, a novel framework that empowers MLLMs with explicit Chain-of-Thought (CoT) reasoning for 3D data. We advocate for a \textit{Look, Think, then Answer} paradigm. In this approach, the model is supervised to generate geometry-grounded rationales before predicting final answers. To facilitate this, we construct Point-Reason-Instruct, a large-scale benchmark comprising $\sim$86k instruction-tuning samples with hierarchical CoT annotations. By leveraging a dual-stream multi-modal architecture, our method synergizes semantic appearance with geometric truth. Extensive experiments demonstrate that PointCoT achieves state-of-the-art performance on complex reasoning tasks.
AIVD: Adaptive Edge-Cloud Collaboration for Accurate and Efficient Industrial Visual Detection
Jan 08, 2026Multimodal large language models (MLLMs) demonstrate exceptional capabilities in semantic understanding and visual reasoning, yet they still face challenges in precise object localization and resource-constrained edge-cloud deployment. To address this, this paper proposes the AIVD framework, which achieves unified precise localization and high-quality semantic generation through the collaboration between lightweight edge detectors and cloud-based MLLMs. To enhance the cloud MLLM's robustness against edge cropped-box noise and scenario variations, we design an efficient fine-tuning strategy with visual-semantic collaborative augmentation, significantly improving classification accuracy and semantic consistency. Furthermore, to maintain high throughput and low latency across heterogeneous edge devices and dynamic network conditions, we propose a heterogeneous resource-aware dynamic scheduling algorithm. Experimental results demonstrate that AIVD substantially reduces resource consumption while improving MLLM classification performance and semantic generation quality. The proposed scheduling strategy also achieves higher throughput and lower latency across diverse scenarios.
ThinkDrive: Chain-of-Thought Guided Progressive Reinforcement Learning Fine-Tuning for Autonomous Driving
Jan 08, 2026With the rapid advancement of large language models (LLMs) technologies, their application in the domain of autonomous driving has become increasingly widespread. However, existing methods suffer from unstructured reasoning, poor generalization, and misalignment with human driving intent. While Chain-of-Thought (CoT) reasoning enhances decision transparency, conventional supervised fine-tuning (SFT) fails to fully exploit its potential, and reinforcement learning (RL) approaches face instability and suboptimal reasoning depth. We propose ThinkDrive, a CoT guided progressive RL fine-tuning framework for autonomous driving that synergizes explicit reasoning with difficulty-aware adaptive policy optimization. Our method employs a two-stage training strategy. First, we perform SFT using CoT explanations. Then, we apply progressive RL with a difficulty-aware adaptive policy optimizer that dynamically adjusts learning intensity based on sample complexity. We evaluate our approach on a public dataset. The results show that ThinkDrive outperforms strong RL baselines by 1.45%, 1.95%, and 1.01% on exam, easy-exam, and accuracy, respectively. Moreover, a 2B-parameter model trained with our method surpasses the much larger GPT-4o by 3.28% on the exam metric.
SOFTooth: Semantics-Enhanced Order-Aware Fusion for Tooth Instance Segmentation
Dec 29, 2025Three-dimensional (3D) tooth instance segmentation remains challenging due to crowded arches, ambiguous tooth-gingiva boundaries, missing teeth, and rare yet clinically important third molars. Native 3D methods relying on geometric cues often suffer from boundary leakage, center drift, and inconsistent tooth identities, especially for minority classes and complex anatomies. Meanwhile, 2D foundation models such as the Segment Anything Model (SAM) provide strong boundary-aware semantics, but directly applying them in 3D is impractical in clinical workflows. To address these issues, we propose SOFTooth, a semantics-enhanced, order-aware 2D-3D fusion framework that leverages frozen 2D semantics without explicit 2D mask supervision. First, a point-wise residual gating module injects occlusal-view SAM embeddings into 3D point features to refine tooth-gingiva and inter-tooth boundaries. Second, a center-guided mask refinement regularizes consistency between instance masks and geometric centroids, reducing center drift. Furthermore, an order-aware Hungarian matching strategy integrates anatomical tooth order and center distance into similarity-based assignment, ensuring coherent labeling even under missing or crowded dentitions. On 3DTeethSeg'22, SOFTooth achieves state-of-the-art overall accuracy and mean IoU, with clear gains on cases involving third molars, demonstrating that rich 2D semantics can be effectively transferred to 3D tooth instance segmentation without 2D fine-tuning.
SD2AIL: Adversarial Imitation Learning from Synthetic Demonstrations via Diffusion Models
Dec 21, 2025Adversarial Imitation Learning (AIL) is a dominant framework in imitation learning that infers rewards from expert demonstrations to guide policy optimization. Although providing more expert demonstrations typically leads to improved performance and greater stability, collecting such demonstrations can be challenging in certain scenarios. Inspired by the success of diffusion models in data generation, we propose SD2AIL, which utilizes synthetic demonstrations via diffusion models. We first employ a diffusion model in the discriminator to generate synthetic demonstrations as pseudo-expert data that augment the expert demonstrations. To selectively replay the most valuable demonstrations from the large pool of (pseudo-) expert demonstrations, we further introduce a prioritized expert demonstration replay strategy (PEDR). The experimental results on simulation tasks demonstrate the effectiveness and robustness of our method. In particular, in the Hopper task, our method achieves an average return of 3441, surpassing the state-of-the-art method by 89. Our code will be available at https://github.com/positron-lpc/SD2AIL.
EMO-RL: Emotion-Rule-Based Reinforcement Learning Enhanced Audio-Language Model for Generalized Speech Emotion Recognition
Sep 19, 2025Although Large Audio-Language Models (LALMs) have exhibited outstanding performance in auditory understanding, their performance in affective computing scenarios, particularly in emotion recognition, reasoning, and subtle sentiment differentiation, remains suboptimal. Recent advances in Reinforcement Learning (RL) have shown promise in improving LALMs' reasoning abilities. However, two critical challenges hinder the direct application of RL techniques to Speech Emotion Recognition (SER) tasks: (1) convergence instability caused by ambiguous emotional boundaries and (2) limited reasoning ability when using relatively small models (e.g., 7B-parameter architectures). To overcome these limitations, we introduce EMO-RL, a novel framework incorporating reinforcement learning with two key innovations: Emotion Similarity-Weighted Reward (ESWR) and Explicit Structured Reasoning (ESR). Built upon pretrained LALMs, our method employs group-relative policy optimization with emotion constraints. Comprehensive experiments demonstrate that our EMO-RL training strategies can significantly enhance the emotional reasoning capabilities of LALMs, attaining state-of-the-art results on both the MELD and IEMOCAP datasets, and cross-dataset experiments prove the strong superiority of generalization.
Predicting Artificial Neural Network Representations to Learn Recognition Model for Music Identification from Brain Recordings
Dec 20, 2024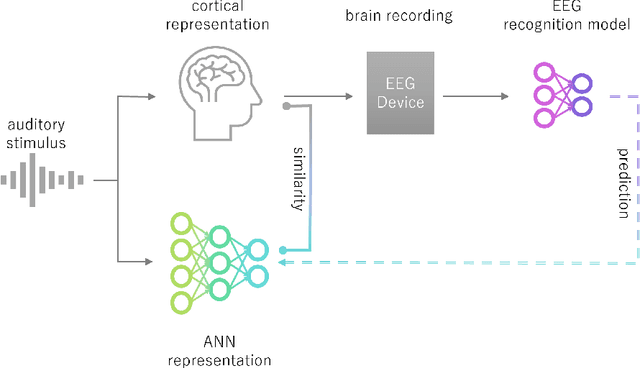


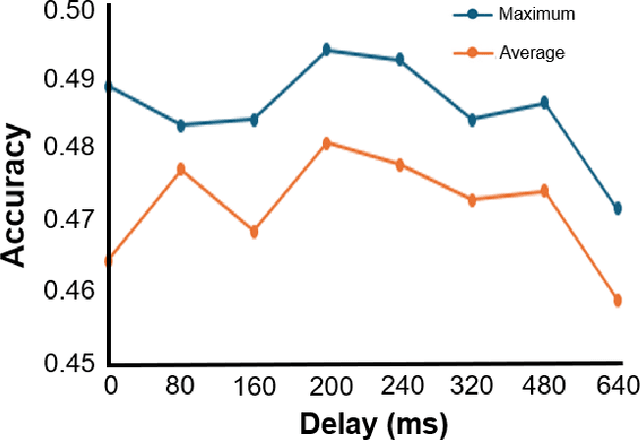
Recent studies have demonstrated that the representations of artificial neural networks (ANNs) can exhibit notable similarities to cortical representations when subjected to identical auditory sensory inputs. In these studies, the ability to predict cortical representations is probed by regressing from ANN representations to cortical representations. Building upon this concept, our approach reverses the direction of prediction: we utilize ANN representations as a supervisory signal to train recognition models using noisy brain recordings obtained through non-invasive measurements. Specifically, we focus on constructing a recognition model for music identification, where electroencephalography (EEG) brain recordings collected during music listening serve as input. By training an EEG recognition model to predict ANN representations-representations associated with music identification-we observed a substantial improvement in classification accuracy. This study introduces a novel approach to developing recognition models for brain recordings in response to external auditory stimuli. It holds promise for advancing brain-computer interfaces (BCI), neural decoding techniques, and our understanding of music cognition. Furthermore, it provides new insights into the relationship between auditory brain activity and ANN representations.
IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding
Sep 29, 2024



The audio watermarking technique embeds messages into audio and accurately extracts messages from the watermarked audio. Traditional methods develop algorithms based on expert experience to embed watermarks into the time-domain or transform-domain of signals. With the development of deep neural networks, deep learning-based neural audio watermarking has emerged. Compared to traditional algorithms, neural audio watermarking achieves better robustness by considering various attacks during training. However, current neural watermarking methods suffer from low capacity and unsatisfactory imperceptibility. Additionally, the issue of watermark locating, which is extremely important and even more pronounced in neural audio watermarking, has not been adequately studied. In this paper, we design a dual-embedding watermarking model for efficient locating. We also consider the impact of the attack layer on the invertible neural network in robustness training, improving the model to enhance both its reasonableness and stability. Experiments show that the proposed model, IDEAW, can withstand various attacks with higher capacity and more efficient locating ability compared to existing methods.
TG-LLaVA: Text Guided LLaVA via Learnable Latent Embeddings
Sep 15, 2024



Currently, inspired by the success of vision-language models (VLMs), an increasing number of researchers are focusing on improving VLMs and have achieved promising results. However, most existing methods concentrate on optimizing the connector and enhancing the language model component, while neglecting improvements to the vision encoder itself. In contrast, we propose Text Guided LLaVA (TG-LLaVA) in this paper, which optimizes VLMs by guiding the vision encoder with text, offering a new and orthogonal optimization direction. Specifically, inspired by the purpose-driven logic inherent in human behavior, we use learnable latent embeddings as a bridge to analyze textual instruction and add the analysis results to the vision encoder as guidance, refining it. Subsequently, another set of latent embeddings extracts additional detailed text-guided information from high-resolution local patches as auxiliary information. Finally, with the guidance of text, the vision encoder can extract text-related features, similar to how humans focus on the most relevant parts of an image when considering a question. This results in generating better answers. Experiments on various datasets validate the effectiveness of the proposed method. Remarkably, without the need for additional training data, our propsoed method can bring more benefits to the baseline (LLaVA-1.5) compared with other concurrent methods. Furthermore, the proposed method consistently brings improvement in different settings.