 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Mining Accented Speech for Inclusive and Fair Speech Recognition
Aug 05, 2024



Modern automatic speech recognition (ASR) systems are typically trained on more than tens of thousands hours of speech data, which is one of the main factors for their great success. However, the distribution of such data is typically biased towards common accents or typical speech patterns. As a result, those systems often poorly perform on atypical accented speech. In this paper, we present accent clustering and mining schemes for fair speech recognition systems which can perform equally well on under-represented accented speech. For accent recognition, we applied three schemes to overcome limited size of supervised accent data: supervised or unsupervised pre-training, distributionally robust optimization (DRO) and unsupervised clustering. Three schemes can significantly improve the accent recognition model especially for unbalanced and small accented speech. Fine-tuning ASR on the mined Indian accent speech using the proposed supervised or unsupervised clustering schemes showed 10.0% and 5.3% relative improvements compared to fine-tuning on the randomly sampled speech, respectively.
Contrastive Siamese Network for Semi-supervised Speech Recognition
May 27, 2022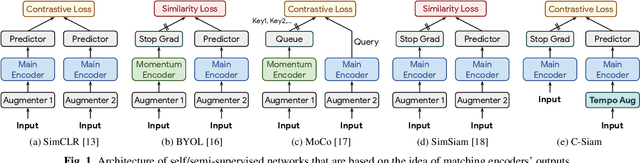
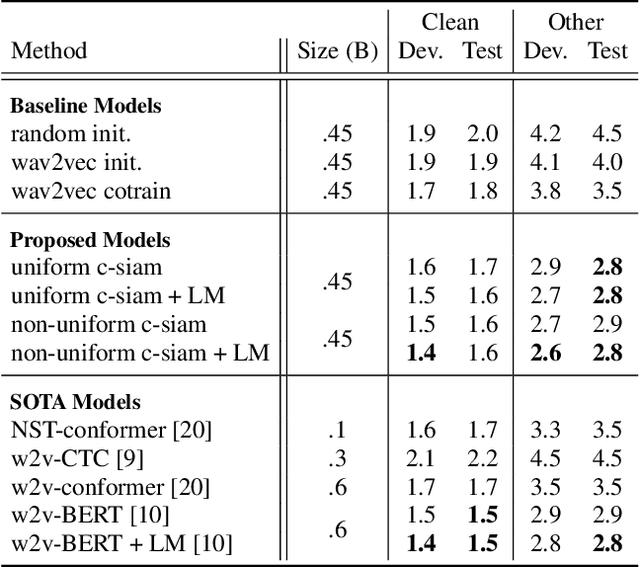
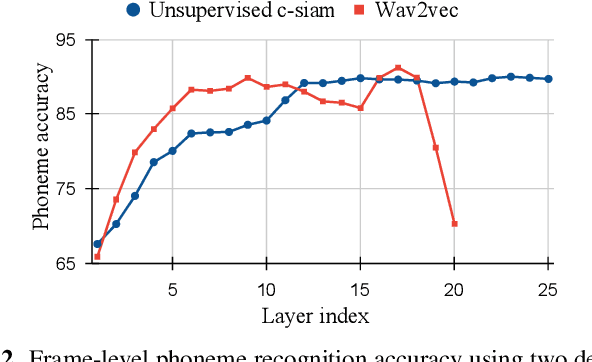
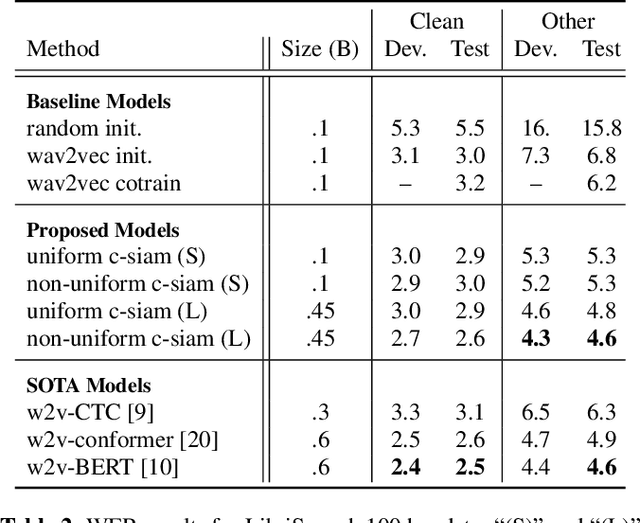
This paper introduces contrastive siamese (c-siam) network, an architecture for leveraging unlabeled acoustic data in speech recognition. c-siam is the first network that extracts high-level linguistic information from speech by matching outputs of two identical transformer encoders. It contains augmented and target branches which are trained by: (1) masking inputs and matching outputs with a contrastive loss, (2) incorporating a stop gradient operation on the target branch, (3) using an extra learnable transformation on the augmented branch, (4) introducing new temporal augment functions to prevent the shortcut learning problem. We use the Libri-light 60k unsupervised data and the LibriSpeech 100hrs/960hrs supervised data to compare c-siam and other best-performing systems. Our experiments show that c-siam provides 20% relative word error rate improvement over wav2vec baselines. A c-siam network with 450M parameters achieves competitive results compared to the state-of-the-art networks with 600M parameters.
Turn-to-Diarize: Online Speaker Diarization Constrained by Transformer Transducer Speaker Turn Detection
Oct 05, 2021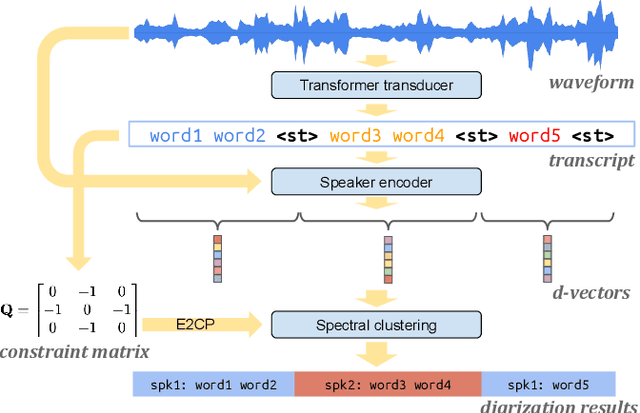

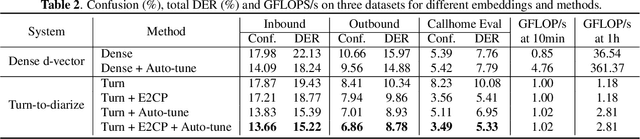
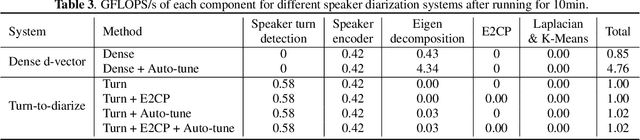
In this paper, we present a novel speaker diarization system for streaming on-device applications. In this system, we use a transformer transducer to detect the speaker turns, represent each speaker turn by a speaker embedding, then cluster these embeddings with constraints from the detected speaker turns. Compared with conventional clustering-based diarization systems, our system largely reduces the computational cost of clustering due to the sparsity of speaker turns. Unlike other supervised speaker diarization systems which require annotations of time-stamped speaker labels for training, our system only requires including speaker turn tokens during the transcribing process, which largely reduces the human efforts involved in data collection.
Reducing Streaming ASR Model Delay with Self Alignment
May 06, 2021
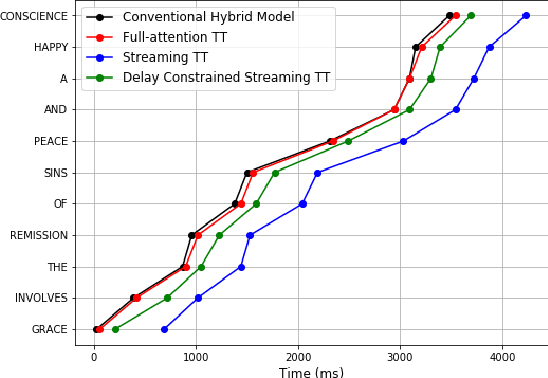
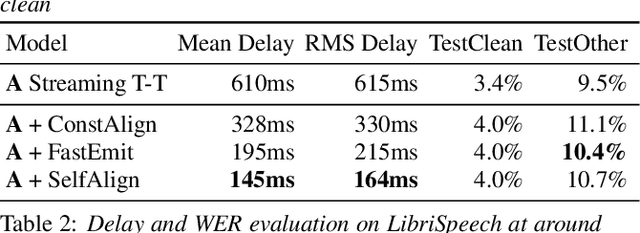
Reducing prediction delay for streaming end-to-end ASR models with minimal performance regression is a challenging problem. Constrained alignment is a well-known existing approach that penalizes predicted word boundaries using external low-latency acoustic models. On the contrary, recently proposed FastEmit is a sequence-level delay regularization scheme encouraging vocabulary tokens over blanks without any reference alignments. Although all these schemes are successful in reducing delay, ASR word error rate (WER) often severely degrades after applying these delay constraining schemes. In this paper, we propose a novel delay constraining method, named self alignment. Self alignment does not require external alignment models. Instead, it utilizes Viterbi forced-alignments from the trained model to find the lower latency alignment direction. From LibriSpeech evaluation, self alignment outperformed existing schemes: 25% and 56% less delay compared to FastEmit and constrained alignment at the similar word error rate. For Voice Search evaluation,12% and 25% delay reductions were achieved compared to FastEmit and constrained alignment with more than 2% WER improvements.
Transformer Transducer: One Model Unifying Streaming and Non-streaming Speech Recognition
Oct 07, 2020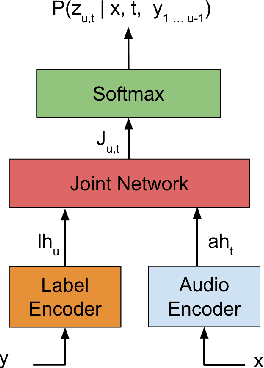
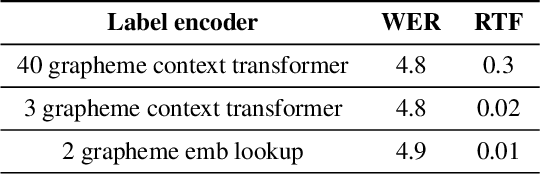
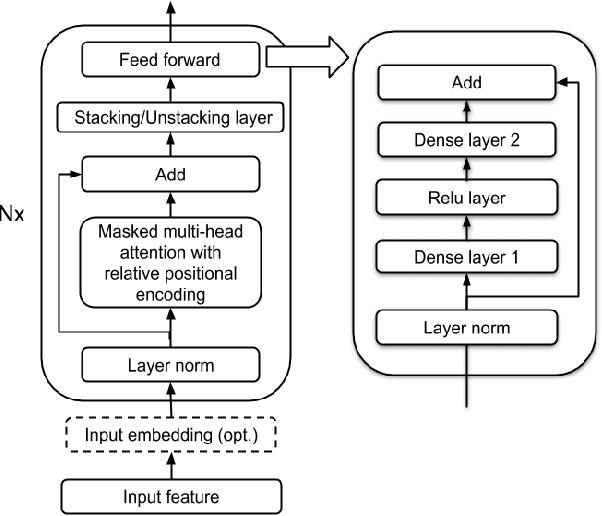
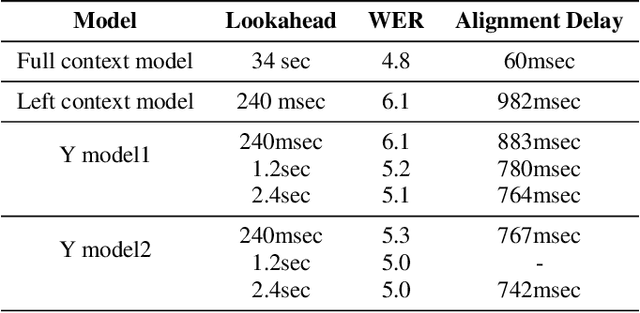
In this paper we present a Transformer-Transducer model architecture and a training technique to unify streaming and non-streaming speech recognition models into one model. The model is composed of a stack of transformer layers for audio encoding with no lookahead or right context and an additional stack of transformer layers on top trained with variable right context. In inference time, the context length for the variable context layers can be changed to trade off the latency and the accuracy of the model. We also show that we can run this model in a Y-model architecture with the top layers running in parallel in low latency and high latency modes. This allows us to have streaming speech recognition results with limited latency and delayed speech recognition results with large improvements in accuracy (20% relative improvement for voice-search task). We show that with limited right context (1-2 seconds of audio) and small additional latency (50-100 milliseconds) at the end of decoding, we can achieve similar accuracy with models using unlimited audio right context. We also present optimizations for audio and label encoders to speed up the inference in streaming and non-streaming speech decoding.
A Density Ratio Approach to Language Model Fusion in End-To-End Automatic Speech Recognition
Feb 28, 2020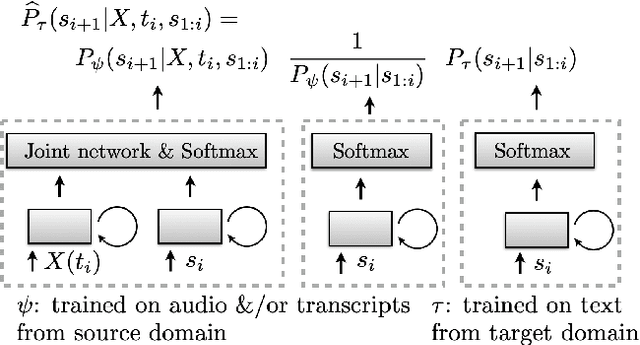
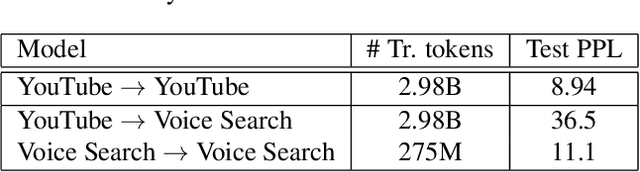
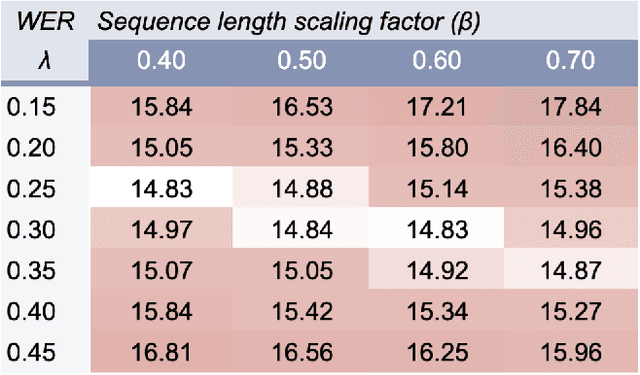
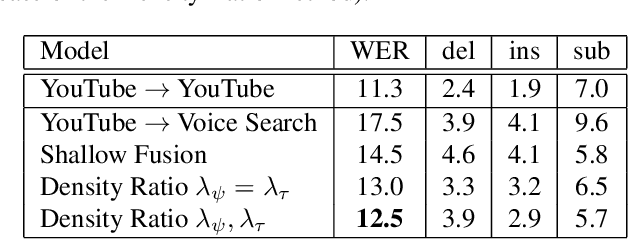
This article describes a density ratio approach to integrating external Language Models (LMs) into end-to-end models for Automatic Speech Recognition (ASR). Applied to a Recurrent Neural Network Transducer (RNN-T) ASR model trained on a given domain, a matched in-domain RNN-LM, and a target domain RNN-LM, the proposed method uses Bayes' Rule to define RNN-T posteriors for the target domain, in a manner directly analogous to the classic hybrid model for ASR based on Deep Neural Networks (DNNs) or LSTMs in the Hidden Markov Model (HMM) framework (Bourlard & Morgan, 1994). The proposed approach is evaluated in cross-domain and limited-data scenarios, for which a significant amount of target domain text data is used for LM training, but only limited (or no) {audio, transcript} training data pairs are used to train the RNN-T. Specifically, an RNN-T model trained on paired audio & transcript data from YouTube is evaluated for its ability to generalize to Voice Search data. The Density Ratio method was found to consistently outperform the dominant approach to LM and end-to-end ASR integration, Shallow Fusion.
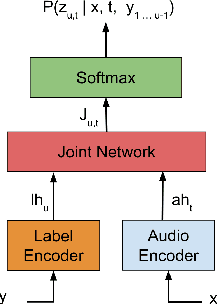
Transformer Transducer: A Streamable Speech Recognition Model with Transformer Encoders and RNN-T Loss
Feb 14, 2020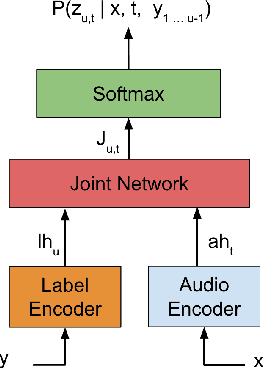

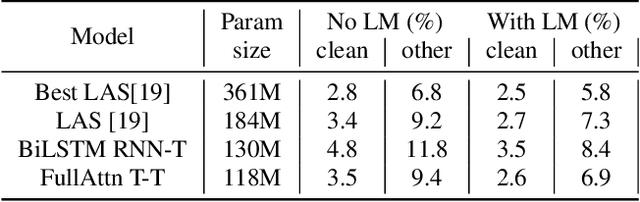
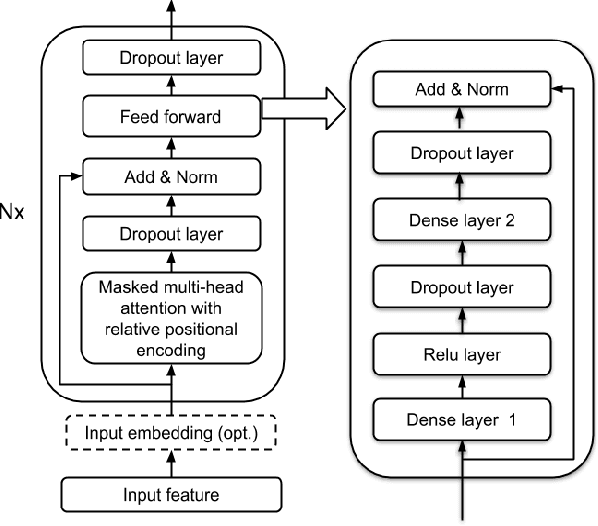
In this paper we present an end-to-end speech recognition model with Transformer encoders that can be used in a streaming speech recognition system. Transformer computation blocks based on self-attention are used to encode both audio and label sequences independently. The activations from both audio and label encoders are combined with a feed-forward layer to compute a probability distribution over the label space for every combination of acoustic frame position and label history. This is similar to the Recurrent Neural Network Transducer (RNN-T) model, which uses RNNs for information encoding instead of Transformer encoders. The model is trained with the RNN-T loss well-suited to streaming decoding. We present results on the LibriSpeech dataset showing that limiting the left context for self-attention in the Transformer layers makes decoding computationally tractable for streaming, with only a slight degradation in accuracy. We also show that the full attention version of our model beats the-state-of-the art accuracy on the LibriSpeech benchmarks. Our results also show that we can bridge the gap between full attention and limited attention versions of our model by attending to a limited number of future frames.
Adversarial Training for Multilingual Acoustic Modeling
Jun 17, 2019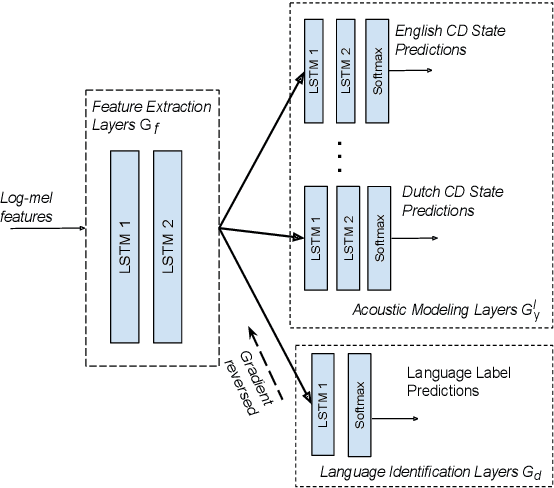
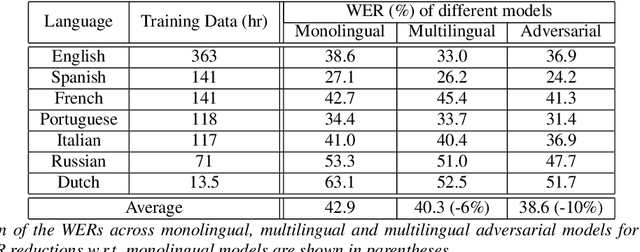
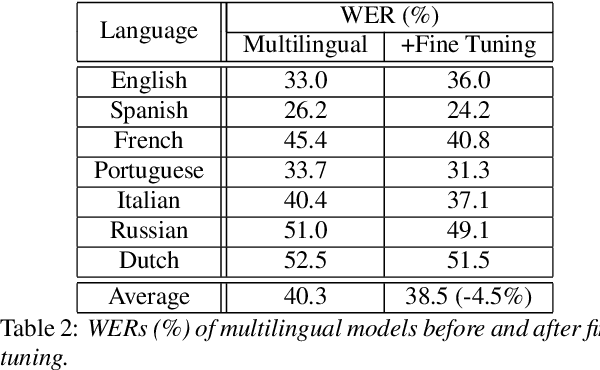
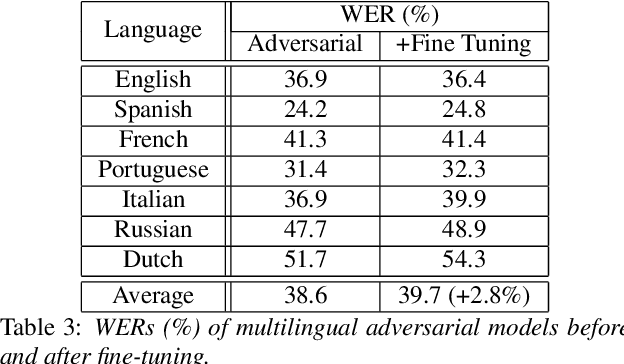
Multilingual training has been shown to improve acoustic modeling performance by sharing and transferring knowledge in modeling different languages. Knowledge sharing is usually achieved by using common lower-level layers for different languages in a deep neural network. Recently, the domain adversarial network was proposed to reduce domain mismatch of training data and learn domain-invariant features. It is thus worth exploring whether adversarial training can further promote knowledge sharing in multilingual models. In this work, we apply the domain adversarial network to encourage the shared layers of a multilingual model to learn language-invariant features. Bidirectional Long Short-Term Memory (LSTM) recurrent neural networks (RNN) are used as building blocks. We show that shared layers learned this way contain less language identification information and lead to better performance. In an automatic speech recognition task for seven languages, the resultant acoustic model improves the word error rate (WER) of the multilingual model by 4% relative on average, and the monolingual models by 10%.
Large-Scale Visual Speech Recognition
Oct 01, 2018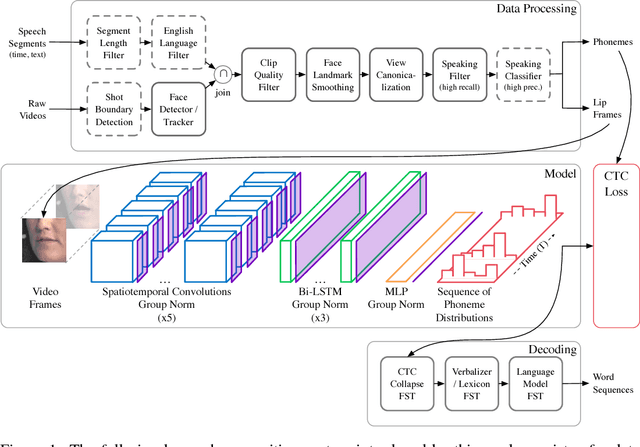
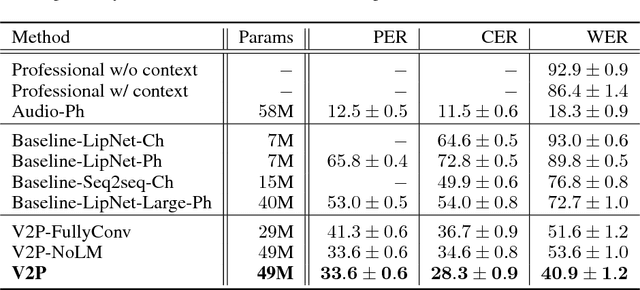


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.
Speech recognition for medical conversations
Jun 20, 2018
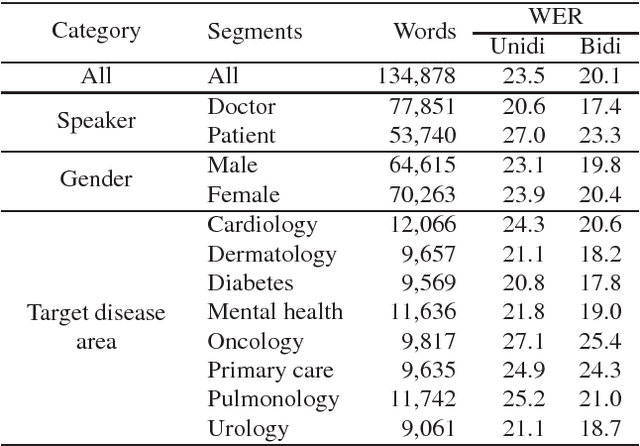
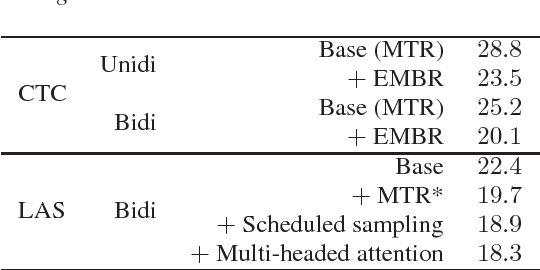
In this work we explored building automatic speech recognition models for transcribing doctor patient conversation. We collected a large scale dataset of clinical conversations ($14,000$ hr), designed the task to represent the real word scenario, and explored several alignment approaches to iteratively improve data quality. We explored both CTC and LAS systems for building speech recognition models. The LAS was more resilient to noisy data and CTC required more data clean up. A detailed analysis is provided for understanding the performance for clinical tasks. Our analysis showed the speech recognition models performed well on important medical utterances, while errors occurred in causal conversations. Overall we believe the resulting models can provide reasonable quality in practice.