 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMWSIS: Multimodal Weakly Supervised Instance Segmentation with 2D Box Annotations for Autonomous Driving
Dec 17, 2023



Instance segmentation is a fundamental research in computer vision, especially in autonomous driving. However, manual mask annotation for instance segmentation is quite time-consuming and costly. To address this problem, some prior works attempt to apply weakly supervised manner by exploring 2D or 3D boxes. However, no one has ever successfully segmented 2D and 3D instances simultaneously by only using 2D box annotations, which could further reduce the annotation cost by an order of magnitude. Thus, we propose a novel framework called Multimodal Weakly Supervised Instance Segmentation (MWSIS), which incorporates various fine-grained label generation and correction modules for both 2D and 3D modalities to improve the quality of pseudo labels, along with a new multimodal cross-supervision approach, named Consistency Sparse Cross-modal Supervision (CSCS), to reduce the inconsistency of multimodal predictions by response distillation. Particularly, transferring the 3D backbone to downstream tasks not only improves the performance of the 3D detectors, but also outperforms fully supervised instance segmentation with only 5% fully supervised annotations. On the Waymo dataset, the proposed framework demonstrates significant improvements over the baseline, especially achieving 2.59% mAP and 12.75% mAP increases for 2D and 3D instance segmentation tasks, respectively. The code is available at https://github.com/jiangxb98/mwsis-plugin.
FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network
Jan 19, 2023



Few-shot semantic segmentation is the task of learning to locate each pixel of the novel class in the query image with only a few annotated support images. The current correlation-based methods construct pair-wise feature correlations to establish the many-to-many matching because the typical prototype-based approaches cannot learn fine-grained correspondence relations. However, the existing methods still suffer from the noise contained in naive correlations and the lack of context semantic information in correlations. To alleviate these problems mentioned above, we propose a Feature-Enhanced Context-Aware Network (FECANet). Specifically, a feature enhancement module is proposed to suppress the matching noise caused by inter-class local similarity and enhance the intra-class relevance in the naive correlation. In addition, we propose a novel correlation reconstruction module that encodes extra correspondence relations between foreground and background and multi-scale context semantic features, significantly boosting the encoder to capture a reliable matching pattern. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed FECANet leads to remarkable improvement compared to previous state-of-the-arts, demonstrating its effectiveness.
Locate before Answering: Answer Guided Question Localization for Video Question Answering
Oct 05, 2022
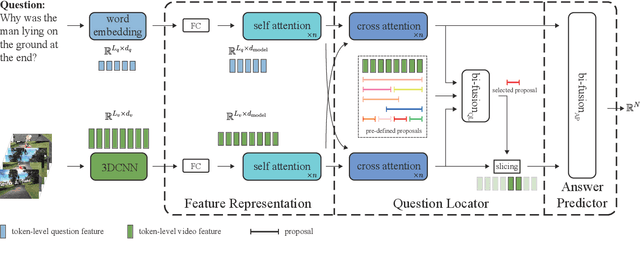
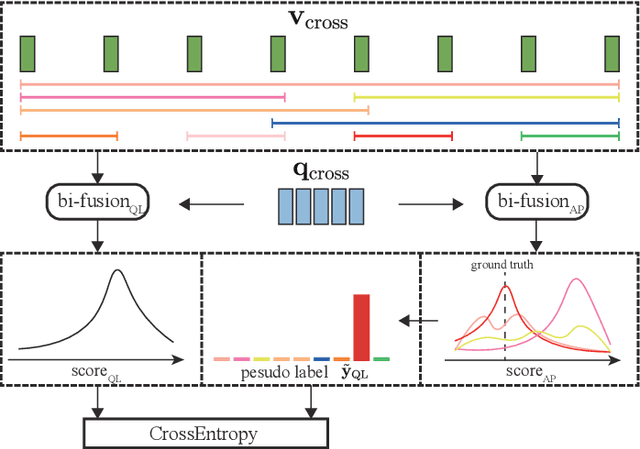
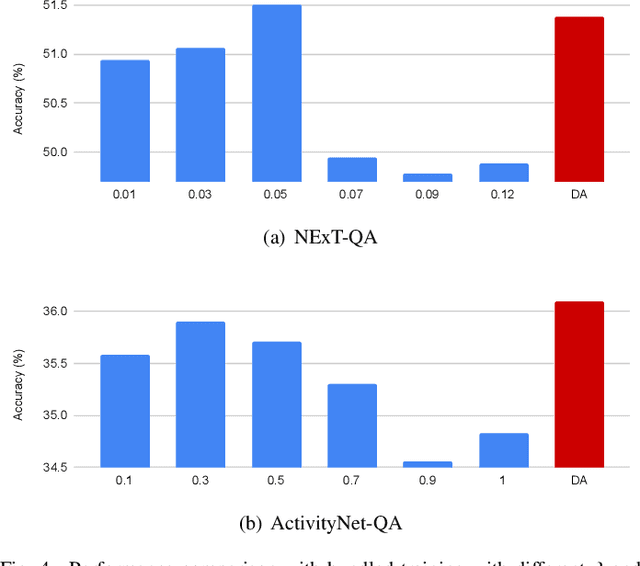
Video question answering (VideoQA) is an essential task in vision-language understanding, which has attracted numerous research attention recently. Nevertheless, existing works mostly achieve promising performances on short videos of duration within 15 seconds. For VideoQA on minute-level long-term videos, those methods are likely to fail because of lacking the ability to deal with noise and redundancy caused by scene changes and multiple actions in the video. Considering the fact that the question often remains concentrated in a short temporal range, we propose to first locate the question to a segment in the video and then infer the answer using the located segment only. Under this scheme, we propose "Locate before Answering" (LocAns), a novel approach that integrates a question locator and an answer predictor into an end-to-end model. During the training phase, the available answer label not only serves as the supervision signal of the answer predictor, but also is used to generate pseudo temporal labels for the question locator. Moreover, we design a decoupled alternative training strategy to update the two modules separately. In the experiments, LocAns achieves state-of-the-art performance on two modern long-term VideoQA datasets NExT-QA and ActivityNet-QA, and its qualitative examples show the reliable performance of the question localization.
An Efficient End-to-End Transformer with Progressive Tri-modal Attention for Multi-modal Emotion Recognition
Sep 20, 2022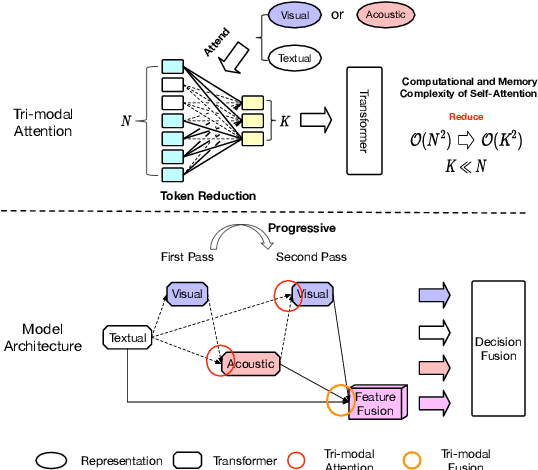
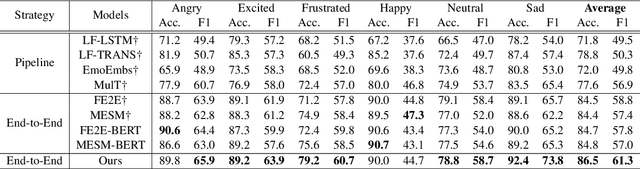
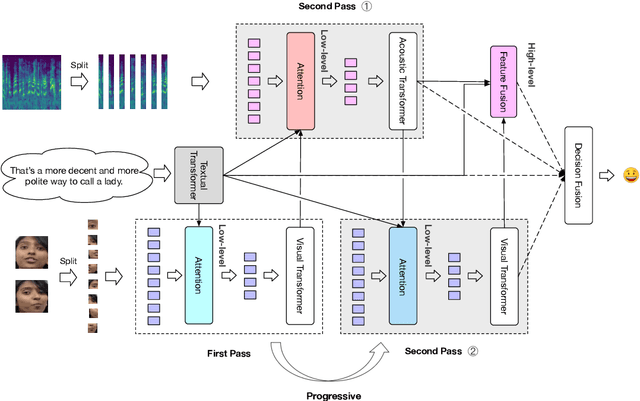
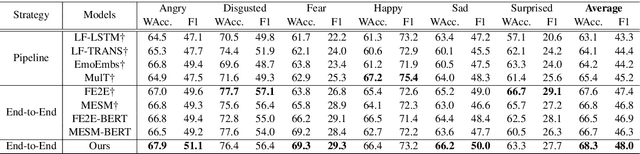
Recent works on multi-modal emotion recognition move towards end-to-end models, which can extract the task-specific features supervised by the target task compared with the two-phase pipeline. However, previous methods only model the feature interactions between the textual and either acoustic and visual modalities, ignoring capturing the feature interactions between the acoustic and visual modalities. In this paper, we propose the multi-modal end-to-end transformer (ME2ET), which can effectively model the tri-modal features interaction among the textual, acoustic, and visual modalities at the low-level and high-level. At the low-level, we propose the progressive tri-modal attention, which can model the tri-modal feature interactions by adopting a two-pass strategy and can further leverage such interactions to significantly reduce the computation and memory complexity through reducing the input token length. At the high-level, we introduce the tri-modal feature fusion layer to explicitly aggregate the semantic representations of three modalities. The experimental results on the CMU-MOSEI and IEMOCAP datasets show that ME2ET achieves the state-of-the-art performance. The further in-depth analysis demonstrates the effectiveness, efficiency, and interpretability of the proposed progressive tri-modal attention, which can help our model to achieve better performance while significantly reducing the computation and memory cost. Our code will be publicly available.
Video Moment Retrieval from Text Queries via Single Frame Annotation
Apr 26, 2022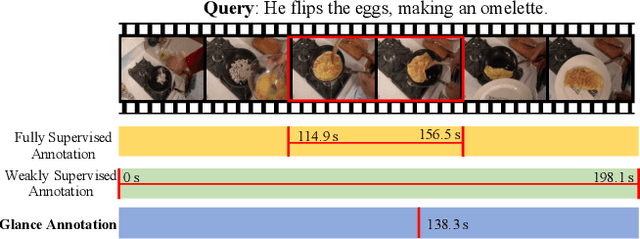
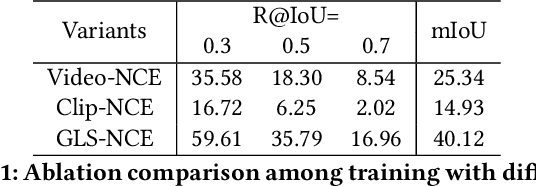
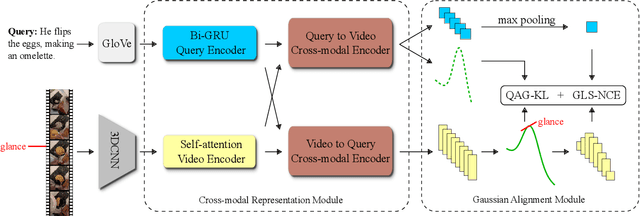
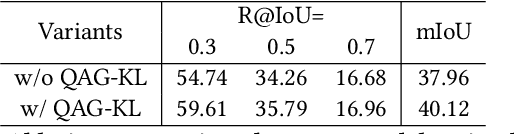
Video moment retrieval aims at finding the start and end timestamps of a moment (part of a video) described by a given natural language query. Fully supervised methods need complete temporal boundary annotations to achieve promising results, which is costly since the annotator needs to watch the whole moment. Weakly supervised methods only rely on the paired video and query, but the performance is relatively poor. In this paper, we look closer into the annotation process and propose a new paradigm called "glance annotation". This paradigm requires the timestamp of only one single random frame, which we refer to as a "glance", within the temporal boundary of the fully supervised counterpart. We argue this is beneficial because comparing to weak supervision, trivial cost is added yet more potential in performance is provided. Under the glance annotation setting, we propose a method named as Video moment retrieval via Glance Annotation (ViGA) based on contrastive learning. ViGA cuts the input video into clips and contrasts between clips and queries, in which glance guided Gaussian distributed weights are assigned to all clips. Our extensive experiments indicate that ViGA achieves better results than the state-of-the-art weakly supervised methods by a large margin, even comparable to fully supervised methods in some cases.
Reprint: a randomized extrapolation based on principal components for data augmentation
Apr 26, 2022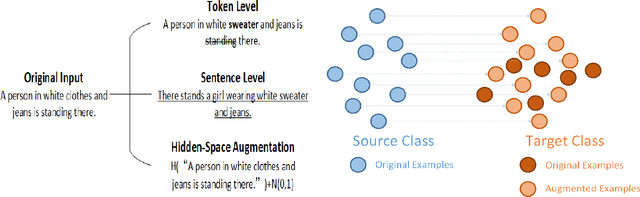
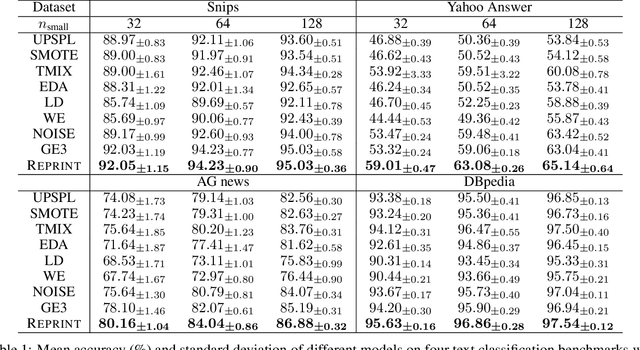
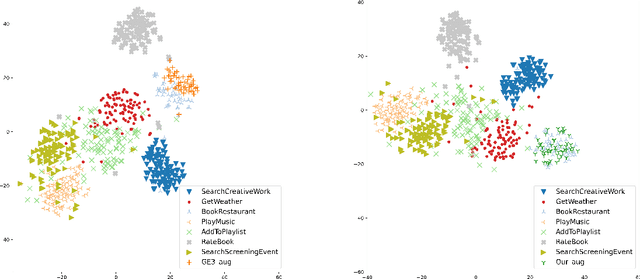

Data scarcity and data imbalance have attracted a lot of attention in many fields. Data augmentation, explored as an effective approach to tackle them, can improve the robustness and efficiency of classification models by generating new samples. This paper presents REPRINT, a simple and effective hidden-space data augmentation method for imbalanced data classification. Given hidden-space representations of samples in each class, REPRINT extrapolates, in a randomized fashion, augmented examples for target class by using subspaces spanned by principal components to summarize distribution structure of both source and target class. Consequently, the examples generated would diversify the target while maintaining the original geometry of target distribution. Besides, this method involves a label refinement component which allows to synthesize new soft labels for augmented examples. Compared with different NLP data augmentation approaches under a range of data imbalanced scenarios on four text classification benchmark, REPRINT shows prominent improvements. Moreover, through comprehensive ablation studies, we show that label refinement is better than label-preserving for augmented examples, and that our method suggests stable and consistent improvements in terms of suitable choices of principal components. Moreover, REPRINT is appealing for its easy-to-use since it contains only one hyperparameter determining the dimension of subspace and requires low computational resource.
PR-Net: Preference Reasoning for Personalized Video Highlight Detection
Sep 04, 2021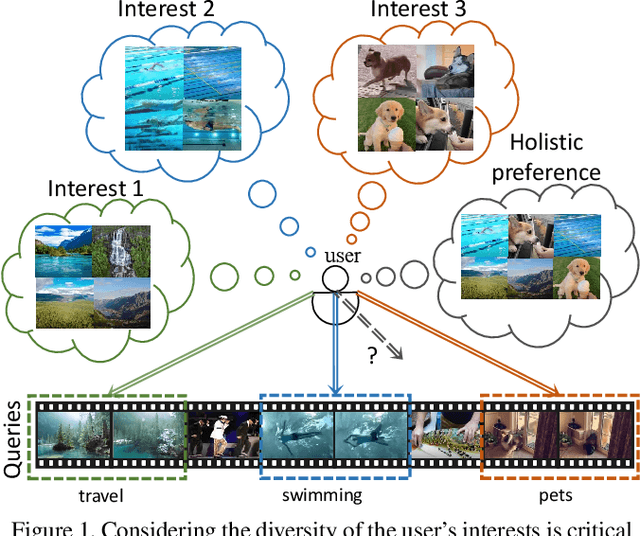
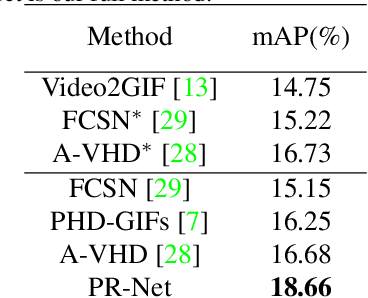
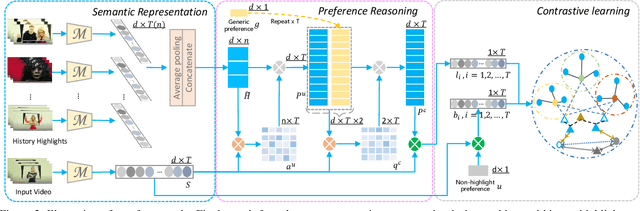
Personalized video highlight detection aims to shorten a long video to interesting moments according to a user's preference, which has recently raised the community's attention. Current methods regard the user's history as holistic information to predict the user's preference but negating the inherent diversity of the user's interests, resulting in vague preference representation. In this paper, we propose a simple yet efficient preference reasoning framework (PR-Net) to explicitly take the diverse interests into account for frame-level highlight prediction. Specifically, distinct user-specific preferences for each input query frame are produced, presented as the similarity weighted sum of history highlights to the corresponding query frame. Next, distinct comprehensive preferences are formed by the user-specific preferences and a learnable generic preference for more overall highlight measurement. Lastly, the degree of highlight and non-highlight for each query frame is calculated as semantic similarity to its comprehensive and non-highlight preferences, respectively. Besides, to alleviate the ambiguity due to the incomplete annotation, a new bi-directional contrastive loss is proposed to ensure a compact and differentiable metric space. In this way, our method significantly outperforms state-of-the-art methods with a relative improvement of 12% in mean accuracy precision.
Part2Whole: Iteratively Enrich Detail for Cross-Modal Retrieval with Partial Query
Mar 02, 2021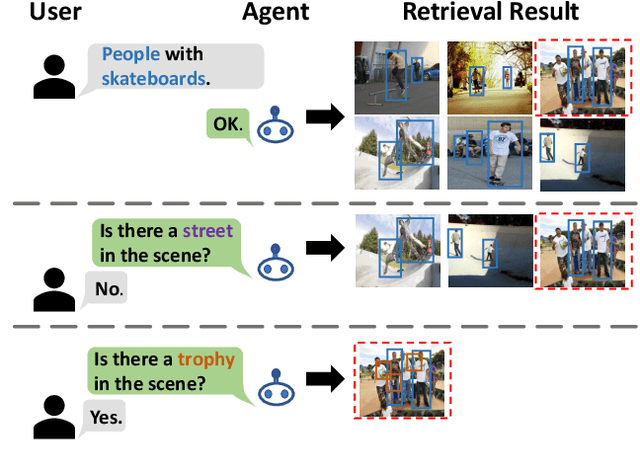

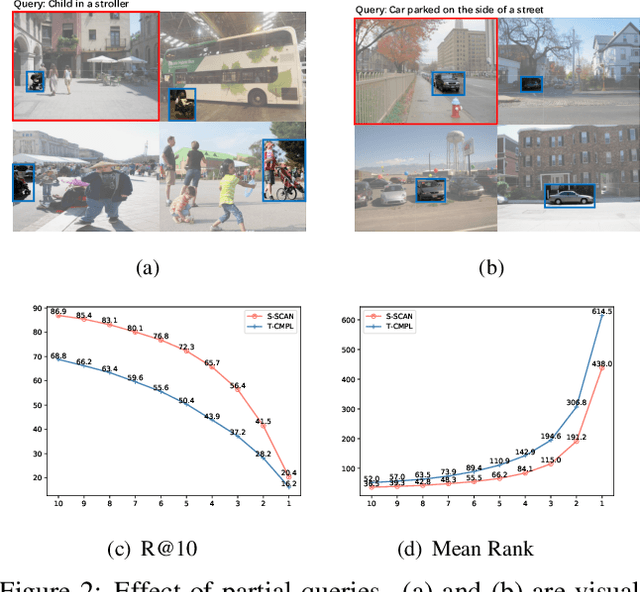
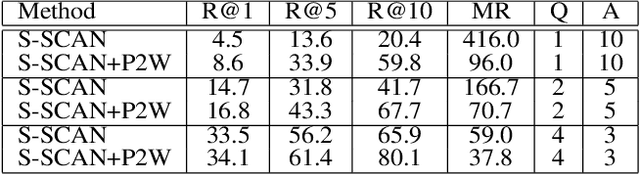
Text-based image retrieval has seen considerable progress in recent years. However, the performance of existing methods suffers in real life since the user is likely to provide an incomplete description of a complex scene, which often leads to results filled with false positives that fit the incomplete description. In this work, we introduce the partial-query problem and extensively analyze its influence on text-based image retrieval. We then propose an interactive retrieval framework called Part2Whole to tackle this problem by iteratively enriching the missing details. Specifically, an Interactive Retrieval Agent is trained to build an optimal policy to refine the initial query based on a user-friendly interaction and statistical characteristics of the gallery. Compared to other dialog-based methods that rely heavily on the user to feed back differentiating information, we let AI take over the optimal feedback searching process and hint the user with confirmation-based questions about details. Furthermore, since fully-supervised training is often infeasible due to the difficulty of obtaining human-machine dialog data, we present a weakly-supervised reinforcement learning method that needs no human-annotated data other than the text-image dataset. Experiments show that our framework significantly improves the performance of text-based image retrieval under complex scenes.
Contextual Non-Local Alignment over Full-Scale Representation for Text-Based Person Search
Jan 08, 2021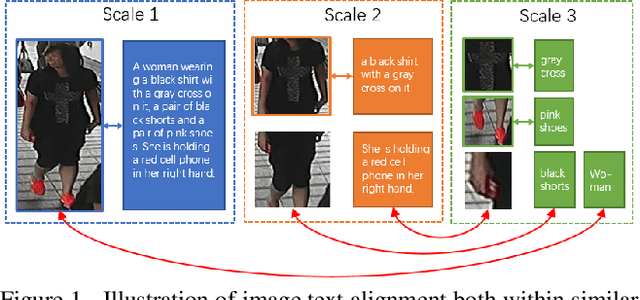
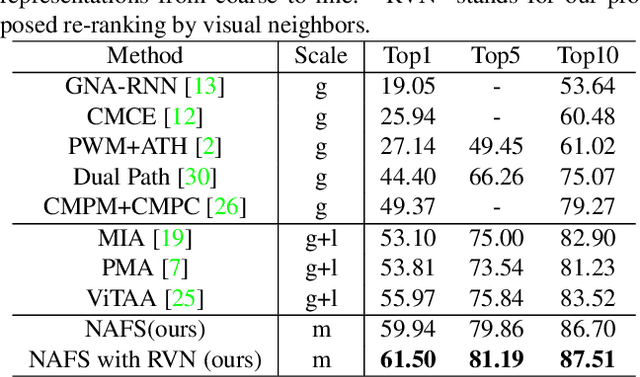
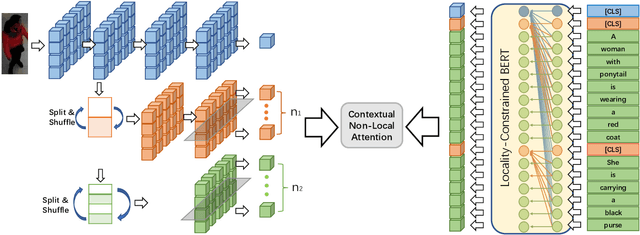
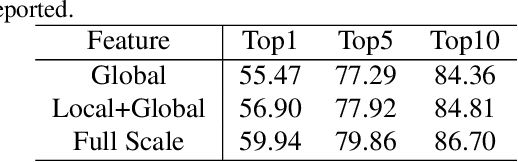
Text-based person search aims at retrieving target person in an image gallery using a descriptive sentence of that person. It is very challenging since modal gap makes effectively extracting discriminative features more difficult. Moreover, the inter-class variance of both pedestrian images and descriptions is small. So comprehensive information is needed to align visual and textual clues across all scales. Most existing methods merely consider the local alignment between images and texts within a single scale (e.g. only global scale or only partial scale) then simply construct alignment at each scale separately. To address this problem, we propose a method that is able to adaptively align image and textual features across all scales, called NAFS (i.e.Non-local Alignment over Full-Scale representations). Firstly, a novel staircase network structure is proposed to extract full-scale image features with better locality. Secondly, a BERT with locality-constrained attention is proposed to obtain representations of descriptions at different scales. Then, instead of separately aligning features at each scale, a novel contextual non-local attention mechanism is applied to simultaneously discover latent alignments across all scales. The experimental results show that our method outperforms the state-of-the-art methods by 5.53% in terms of top-1 and 5.35% in terms of top-5 on text-based person search dataset. The code is available at https://github.com/TencentYoutuResearch/PersonReID-NAFS
Global2Local: Efficient Structure Search for Video Action Segmentation
Jan 04, 2021

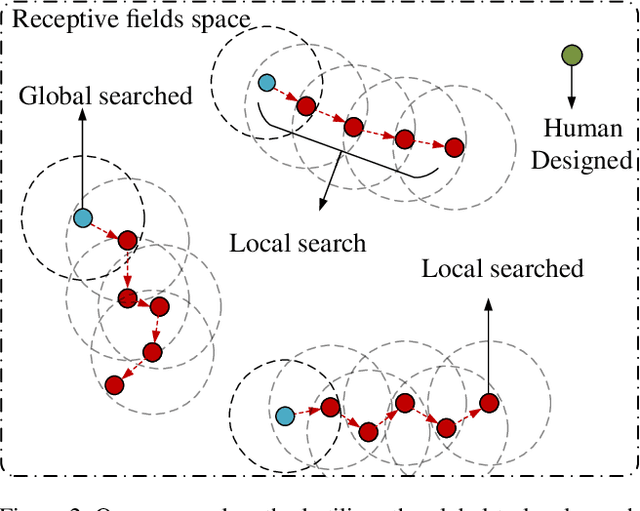

Temporal receptive fields of models play an important role in action segmentation. Large receptive fields facilitate the long-term relations among video clips while small receptive fields help capture the local details. Existing methods construct models with hand-designed receptive fields in layers. Can we effectively search for receptive field combinations to replace hand-designed patterns? To answer this question, we propose to find better receptive field combinations through a global-to-local search scheme. Our search scheme exploits both global search to find the coarse combinations and local search to get the refined receptive field combination patterns further. The global search finds possible coarse combinations other than human-designed patterns. On top of the global search, we propose an expectation guided iterative local search scheme to refine combinations effectively. Our global-to-local search can be plugged into existing action segmentation methods to achieve state-of-the-art performance.