 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA PAC-Bayesian View of Generalisation for Physics-Informed Machine Learning
May 25, 2026Physics-informed machine learning (PIML) integrates mechanistic knowledge, typically in the form of partial differential equations (PDE), into data-driven models. Despite strong empirical performance, its statistical generalisation properties remain poorly understood, particularly in the regression setting with unbounded losses. Existing analyses rely on approximation or stability arguments and do not fully capture how physical structure influences generalisation from finite data. In this work, we develop a PAC-Bayesian framework for PIML that provides high-probability generalisation guarantees in the presence of unbounded losses. We adopt a multi-task perspective that jointly treats data fidelity, PDE residuals, initial and boundary conditions, avoiding the looseness induced by standard union-bound approaches. Our analysis leverages the structure of physics-informed objectives to derive novel bounds where the complexity scales with input-gradient norms of the losses, revealing a direct link between physical regularity and generalisation. We instantiate this framework under Sobolev and Poincaré-type assumptions, yielding two classes of bounds that trade off statistical complexity and smoothness in different regimes. Building on these results, we propose a self-bounding-aware learning algorithm that directly optimises tractable surrogates of the derived bounds, along with a practical procedure to estimate the associated constants in realistic settings. Empirical evaluations on standard PDE benchmarks demonstrate that our bounds are non-vacuous, significantly tighter than union-bound baselines, and can be effectively minimised during training. Overall, our results provide a principled statistical foundation for the generalisation of physics-informed models.
Cross-Domain Offshore Wind Power Forecasting: Transfer Learning Through Meteorological Clusters
Jan 27, 2026Ambitious decarbonisation targets are catalysing growth in orders of new offshore wind farms. For these newly commissioned plants to run, accurate power forecasts are needed from the onset. These allow grid stability, good reserve management and efficient energy trading. Despite machine learning models having strong performances, they tend to require large volumes of site-specific data that new farms do not yet have. To overcome this data scarcity, we propose a novel transfer learning framework that clusters power output according to covariate meteorological features. Rather than training a single, general-purpose model, we thus forecast with an ensemble of expert models, each trained on a cluster. As these pre-trained models each specialise in a distinct weather pattern, they adapt efficiently to new sites and capture transferable, climate-dependent dynamics. Through the expert models' built-in calibration to seasonal and meteorological variability, we remove the industry-standard requirement of local measurements over a year. Our contributions are two-fold - we propose this novel framework and comprehensively evaluate it on eight offshore wind farms, achieving accurate cross-domain forecasting with under five months of site-specific data. Our experiments achieve a MAE of 3.52\%, providing empirical verification that reliable forecasts do not require a full annual cycle. Beyond power forecasting, this climate-aware transfer learning method opens new opportunities for offshore wind applications such as early-stage wind resource assessment, where reducing data requirements can significantly accelerate project development whilst effectively mitigating its inherent risks.
Rapidly Varying Completely Random Measures for Modeling Extremely Sparse Networks
May 19, 2025Completely random measures (CRMs) are fundamental to Bayesian nonparametric models, with applications in clustering, feature allocation, and network analysis. A key quantity of interest is the Laplace exponent, whose asymptotic behavior determines how the random structures scale. When the Laplace exponent grows nearly linearly - known as rapid variation - the induced models exhibit approximately linear growth in the number of clusters, features, or edges with sample size or network nodes. This regime is especially relevant for modeling sparse networks, yet existing CRM constructions lack tractability under rapid variation. We address this by introducing a new class of CRMs with index of variation $\alpha\in(0,1]$, defined as mixtures of stable or generalized gamma processes. These models offer interpretable parameters, include well-known CRMs as limiting cases, and retain analytical tractability through a tractable Laplace exponent and simple size-biased representation. We analyze the asymptotic properties of this CRM class and apply it to the Caron-Fox framework for sparse graphs. The resulting models produce networks with near-linear edge growth, aligning with empirical evidence from large-scale networks. Additionally, we present efficient algorithms for simulation and posterior inference, demonstrating practical advantages through experiments on real-world sparse network datasets.
How good is PAC-Bayes at explaining generalisation?
Mar 11, 2025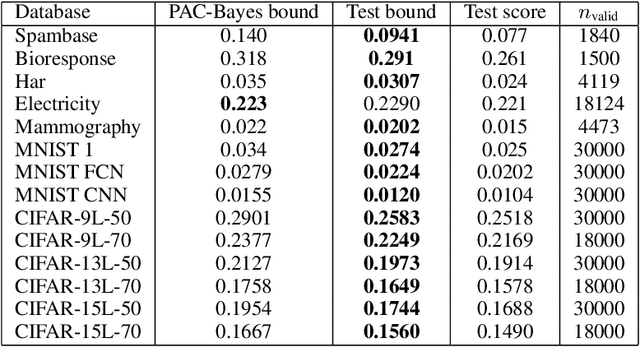
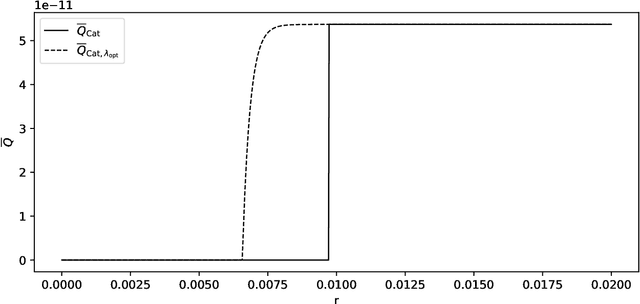
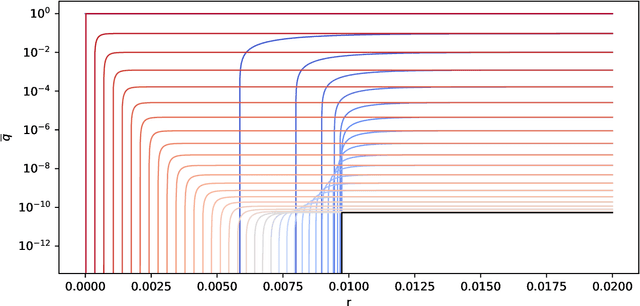
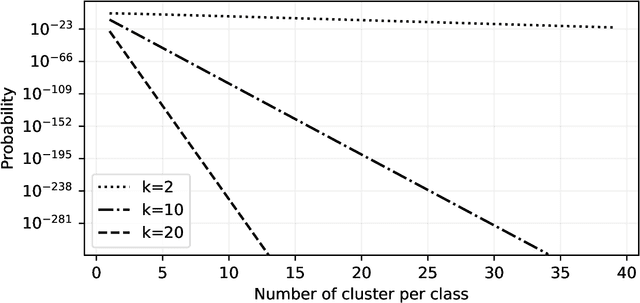
We discuss necessary conditions for a PAC-Bayes bound to provide a meaningful generalisation guarantee. Our analysis reveals that the optimal generalisation guarantee depends solely on the distribution of the risk induced by the prior distribution. In particular, achieving a target generalisation level is only achievable if the prior places sufficient mass on high-performing predictors. We relate these requirements to the prevalent practice of using data-dependent priors in deep learning PAC-Bayes applications, and discuss the implications for the claim that PAC-Bayes ``explains'' generalisation.
Learning via Surrogate PAC-Bayes
Oct 14, 2024



PAC-Bayes learning is a comprehensive setting for (i) studying the generalisation ability of learning algorithms and (ii) deriving new learning algorithms by optimising a generalisation bound. However, optimising generalisation bounds might not always be viable for tractable or computational reasons, or both. For example, iteratively querying the empirical risk might prove computationally expensive. In response, we introduce a novel principled strategy for building an iterative learning algorithm via the optimisation of a sequence of surrogate training objectives, inherited from PAC-Bayes generalisation bounds. The key argument is to replace the empirical risk (seen as a function of hypotheses) in the generalisation bound by its projection onto a constructible low dimensional functional space: these projections can be queried much more efficiently than the initial risk. On top of providing that generic recipe for learning via surrogate PAC-Bayes bounds, we (i) contribute theoretical results establishing that iteratively optimising our surrogates implies the optimisation of the original generalisation bounds, (ii) instantiate this strategy to the framework of meta-learning, introducing a meta-objective offering a closed form expression for meta-gradient, (iii) illustrate our approach with numerical experiments inspired by an industrial biochemical problem.
Predicting Electricity Consumption with Random Walks on Gaussian Processes
Sep 09, 2024



We consider time-series forecasting problems where data is scarce, difficult to gather, or induces a prohibitive computational cost. As a first attempt, we focus on short-term electricity consumption in France, which is of strategic importance for energy suppliers and public stakeholders. The complexity of this problem and the many levels of geospatial granularity motivate the use of an ensemble of Gaussian Processes (GPs). Whilst GPs are remarkable predictors, they are computationally expensive to train, which calls for a frugal few-shot learning approach. By taking into account performance on GPs trained on a dataset and designing a random walk on these, we mitigate the training cost of our entire Bayesian decision-making procedure. We introduce our algorithm called \textsc{Domino} (ranDOM walk on gaussIaN prOcesses) and present numerical experiments to support its merits.
Closed-form Filtering for Non-linear Systems
Feb 15, 2024Sequential Bayesian Filtering aims to estimate the current state distribution of a Hidden Markov Model, given the past observations. The problem is well-known to be intractable for most application domains, except in notable cases such as the tabular setting or for linear dynamical systems with gaussian noise. In this work, we propose a new class of filters based on Gaussian PSD Models, which offer several advantages in terms of density approximation and computational efficiency. We show that filtering can be efficiently performed in closed form when transitions and observations are Gaussian PSD Models. When the transition and observations are approximated by Gaussian PSD Models, we show that our proposed estimator enjoys strong theoretical guarantees, with estimation error that depends on the quality of the approximation and is adaptive to the regularity of the transition probabilities. In particular, we identify regimes in which our proposed filter attains a TV $\epsilon$-error with memory and computational complexity of $O(\epsilon^{-1})$ and $O(\epsilon^{-3/2})$ respectively, including the offline learning step, in contrast to the $O(\epsilon^{-2})$ complexity of sampling methods such as particle filtering.
A PAC-Bayesian Link Between Generalisation and Flat Minima
Feb 13, 2024
Modern machine learning usually involves predictors in the overparametrised setting (number of trained parameters greater than dataset size), and their training yield not only good performances on training data, but also good generalisation capacity. This phenomenon challenges many theoretical results, and remains an open problem. To reach a better understanding, we provide novel generalisation bounds involving gradient terms. To do so, we combine the PAC-Bayes toolbox with Poincar\'e and Log-Sobolev inequalities, avoiding an explicit dependency on dimension of the predictor space. Our results highlight the positive influence of \emph{flat minima} (being minima with a neighbourhood nearly minimising the learning problem as well) on generalisation performances, involving directly the benefits of the optimisation phase.
Tighter Generalisation Bounds via Interpolation
Feb 07, 2024



This paper contains a recipe for deriving new PAC-Bayes generalisation bounds based on the $(f, \Gamma)$-divergence, and, in addition, presents PAC-Bayes generalisation bounds where we interpolate between a series of probability divergences (including but not limited to KL, Wasserstein, and total variation), making the best out of many worlds depending on the posterior distributions properties. We explore the tightness of these bounds and connect them to earlier results from statistical learning, which are specific cases. We also instantiate our bounds as training objectives, yielding non-trivial guarantees and practical performances.
A note on regularised NTK dynamics with an application to PAC-Bayesian training
Dec 20, 2023We establish explicit dynamics for neural networks whose training objective has a regularising term that constrains the parameters to remain close to their initial value. This keeps the network in a lazy training regime, where the dynamics can be linearised around the initialisation. The standard neural tangent kernel (NTK) governs the evolution during the training in the infinite-width limit, although the regularisation yields an additional term appears in the differential equation describing the dynamics. This setting provides an appropriate framework to study the evolution of wide networks trained to optimise generalisation objectives such as PAC-Bayes bounds, and hence potentially contribute to a deeper theoretical understanding of such networks.