 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaypoint Models for Instruction-guided Navigation in Continuous Environments
Oct 05, 2021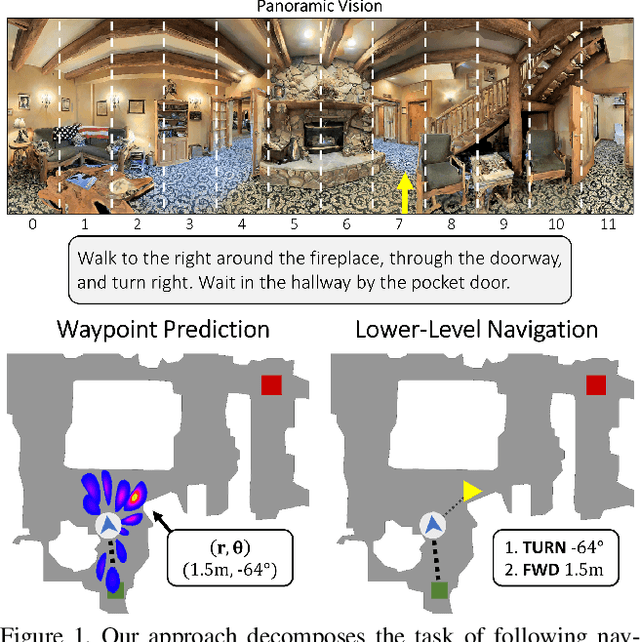
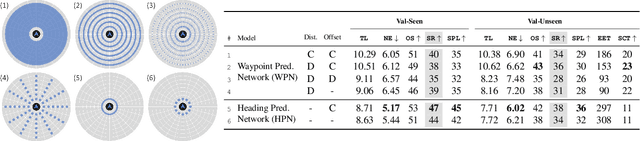
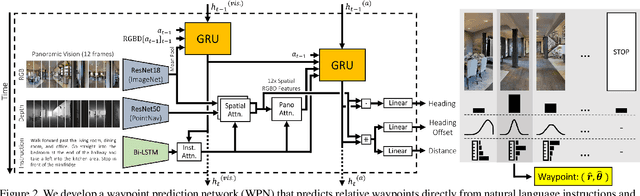

Little inquiry has explicitly addressed the role of action spaces in language-guided visual navigation -- either in terms of its effect on navigation success or the efficiency with which a robotic agent could execute the resulting trajectory. Building on the recently released VLN-CE setting for instruction following in continuous environments, we develop a class of language-conditioned waypoint prediction networks to examine this question. We vary the expressivity of these models to explore a spectrum between low-level actions and continuous waypoint prediction. We measure task performance and estimated execution time on a profiled LoCoBot robot. We find more expressive models result in simpler, faster to execute trajectories, but lower-level actions can achieve better navigation metrics by approximating shortest paths better. Further, our models outperform prior work in VLN-CE and set a new state-of-the-art on the public leaderboard -- increasing success rate by 4% with our best model on this challenging task.
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Sep 16, 2021

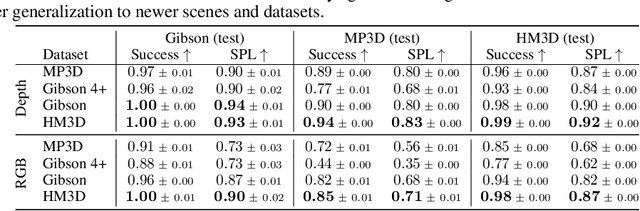
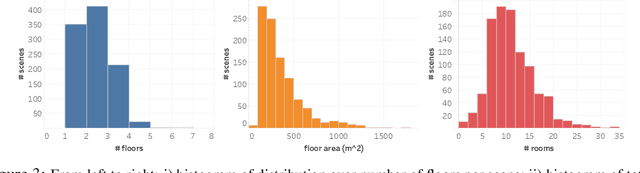
We present the Habitat-Matterport 3D (HM3D) dataset. HM3D is a large-scale dataset of 1,000 building-scale 3D reconstructions from a diverse set of real-world locations. Each scene in the dataset consists of a textured 3D mesh reconstruction of interiors such as multi-floor residences, stores, and other private indoor spaces. HM3D surpasses existing datasets available for academic research in terms of physical scale, completeness of the reconstruction, and visual fidelity. HM3D contains 112.5k m^2 of navigable space, which is 1.4 - 3.7x larger than other building-scale datasets such as MP3D and Gibson. When compared to existing photorealistic 3D datasets such as Replica, MP3D, Gibson, and ScanNet, images rendered from HM3D have 20 - 85% higher visual fidelity w.r.t. counterpart images captured with real cameras, and HM3D meshes have 34 - 91% fewer artifacts due to incomplete surface reconstruction. The increased scale, fidelity, and diversity of HM3D directly impacts the performance of embodied AI agents trained using it. In fact, we find that HM3D is `pareto optimal' in the following sense -- agents trained to perform PointGoal navigation on HM3D achieve the highest performance regardless of whether they are evaluated on HM3D, Gibson, or MP3D. No similar claim can be made about training on other datasets. HM3D-trained PointNav agents achieve 100% performance on Gibson-test dataset, suggesting that it might be time to retire that episode dataset.
Habitat 2.0: Training Home Assistants to Rearrange their Habitat
Jun 28, 2021


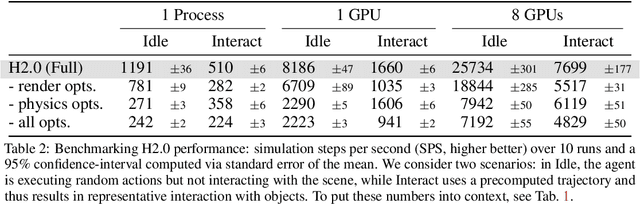
We introduce Habitat 2.0 (H2.0), a simulation platform for training virtual robots in interactive 3D environments and complex physics-enabled scenarios. We make comprehensive contributions to all levels of the embodied AI stack - data, simulation, and benchmark tasks. Specifically, we present: (i) ReplicaCAD: an artist-authored, annotated, reconfigurable 3D dataset of apartments (matching real spaces) with articulated objects (e.g. cabinets and drawers that can open/close); (ii) H2.0: a high-performance physics-enabled 3D simulator with speeds exceeding 25,000 simulation steps per second (850x real-time) on an 8-GPU node, representing 100x speed-ups over prior work; and, (iii) Home Assistant Benchmark (HAB): a suite of common tasks for assistive robots (tidy the house, prepare groceries, set the table) that test a range of mobile manipulation capabilities. These large-scale engineering contributions allow us to systematically compare deep reinforcement learning (RL) at scale and classical sense-plan-act (SPA) pipelines in long-horizon structured tasks, with an emphasis on generalization to new objects, receptacles, and layouts. We find that (1) flat RL policies struggle on HAB compared to hierarchical ones; (2) a hierarchy with independent skills suffers from 'hand-off problems', and (3) SPA pipelines are more brittle than RL policies.
Memory-Augmented Reinforcement Learning for Image-Goal Navigation
Jan 13, 2021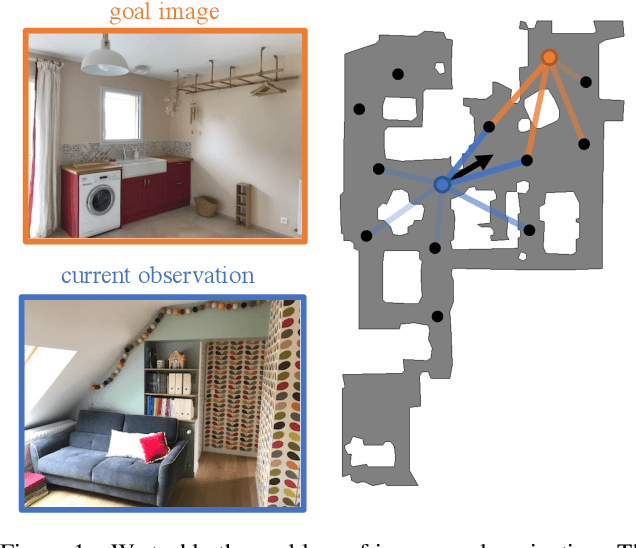
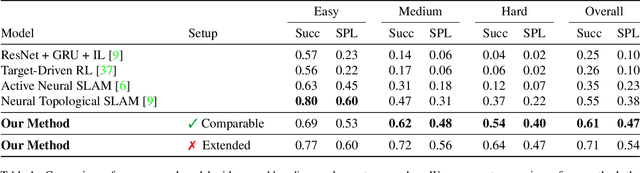
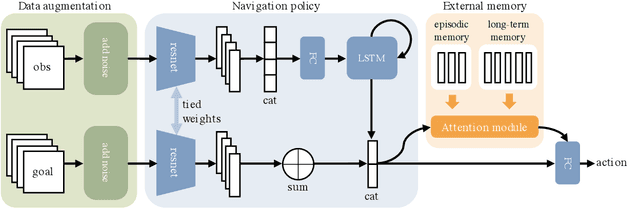
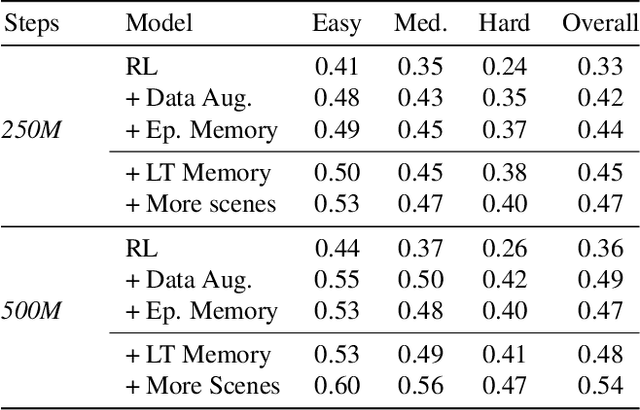
In this work, we address the problem of image-goal navigation in the context of visually-realistic 3D environments. This task involves navigating to a location indicated by a target image in a previously unseen environment. Earlier attempts, including RL-based and SLAM-based approaches, have either shown poor generalization performance, or are heavily-reliant on pose/depth sensors. We present a novel method that leverages a cross-episode memory to learn to navigate. We first train a state-embedding network in a self-supervised fashion, and then use it to embed previously-visited states into a memory. In order to avoid overfitting, we propose to use data augmentation on the RGB input during training. We validate our approach through extensive evaluations, showing that our data-augmented memory-based model establishes a new state of the art on the image-goal navigation task in the challenging Gibson dataset. We obtain this competitive performance from RGB input only, without access to additional sensors such as position or depth.
Integrating Egocentric Localization for More Realistic Point-Goal Navigation Agents
Sep 07, 2020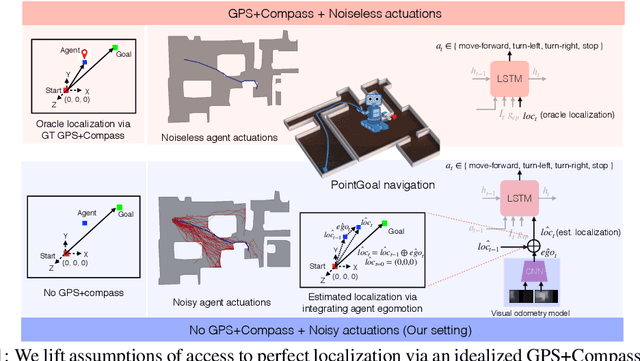
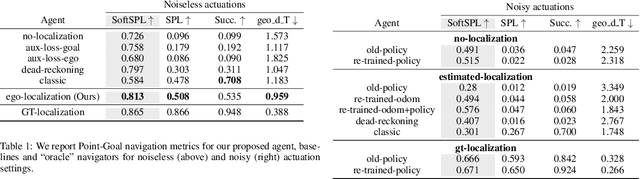
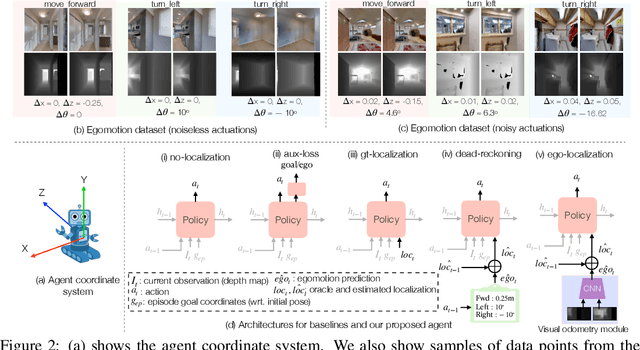
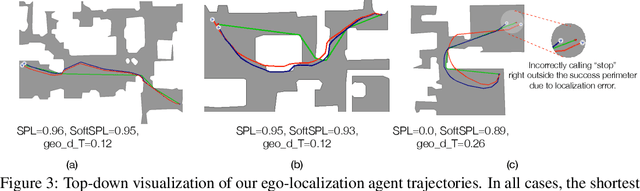
Recent work has presented embodied agents that can navigate to point-goal targets in novel indoor environments with near-perfect accuracy. However, these agents are equipped with idealized sensors for localization and take deterministic actions. This setting is practically sterile by comparison to the dirty reality of noisy sensors and actuations in the real world -- wheels can slip, motion sensors have error, actuations can rebound. In this work, we take a step towards this noisy reality, developing point-goal navigation agents that rely on visual estimates of egomotion under noisy action dynamics. We find these agents outperform naive adaptions of current point-goal agents to this setting as well as those incorporating classic localization baselines. Further, our model conceptually divides learning agent dynamics or odometry (where am I?) from task-specific navigation policy (where do I want to go?). This enables a seamless adaption to changing dynamics (a different robot or floor type) by simply re-calibrating the visual odometry model -- circumventing the expense of re-training of the navigation policy. Our agent was the runner-up in the PointNav track of CVPR 2020 Habitat Challenge.
ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects
Jun 23, 2020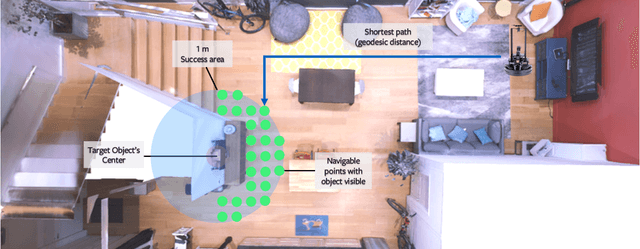

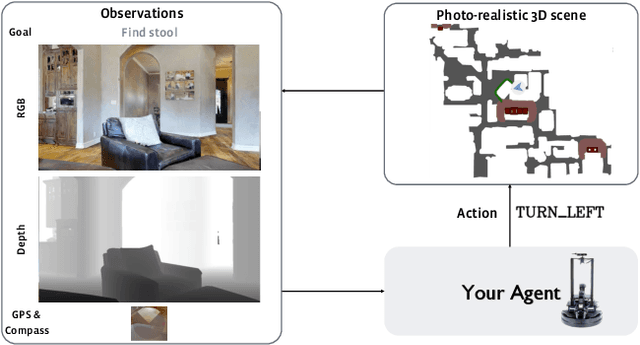
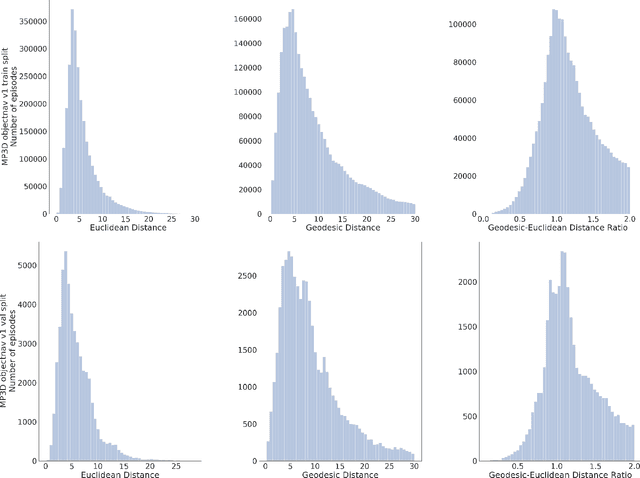
We revisit the problem of Object-Goal Navigation (ObjectNav). In its simplest form, ObjectNav is defined as the task of navigating to an object, specified by its label, in an unexplored environment. In particular, the agent is initialized at a random location and pose in an environment and asked to find an instance of an object category, e.g., find a chair, by navigating to it. As the community begins to show increased interest in semantic goal specification for navigation tasks, a number of different often-inconsistent interpretations of this task are emerging. This document summarizes the consensus recommendations of this working group on ObjectNav. In particular, we make recommendations on subtle but important details of evaluation criteria (for measuring success when navigating towards a target object), the agent's embodiment parameters, and the characteristics of the environments within which the task is carried out. Finally, we provide a detailed description of the instantiation of these recommendations in challenges organized at the Embodied AI workshop at CVPR 2020 \url{http://embodied-ai.org} .
Embodied Question Answering in Photorealistic Environments with Point Cloud Perception
Apr 06, 2019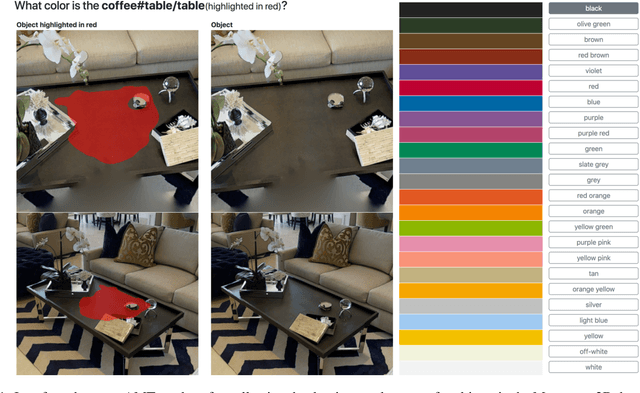
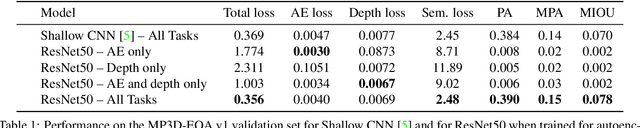
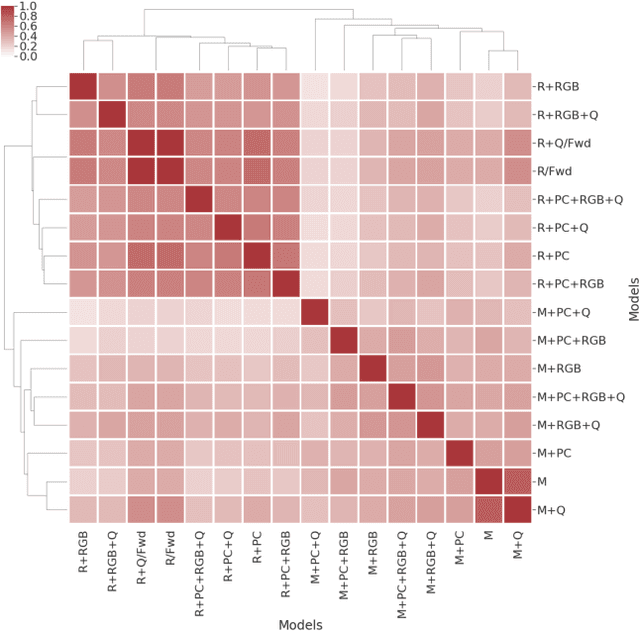
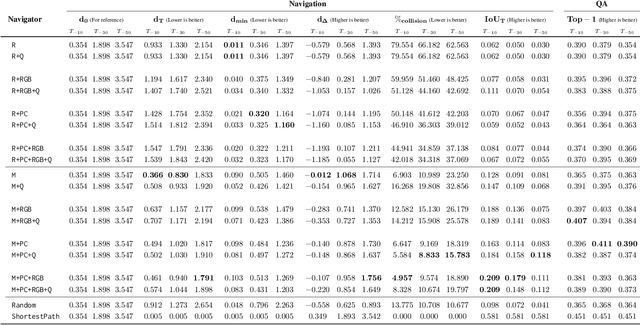
To help bridge the gap between internet vision-style problems and the goal of vision for embodied perception we instantiate a large-scale navigation task -- Embodied Question Answering [1] in photo-realistic environments (Matterport 3D). We thoroughly study navigation policies that utilize 3D point clouds, RGB images, or their combination. Our analysis of these models reveals several key findings. We find that two seemingly naive navigation baselines, forward-only and random, are strong navigators and challenging to outperform, due to the specific choice of the evaluation setting presented by [1]. We find a novel loss-weighting scheme we call Inflection Weighting to be important when training recurrent models for navigation with behavior cloning and are able to out perform the baselines with this technique. We find that point clouds provide a richer signal than RGB images for learning obstacle avoidance, motivating the use (and continued study) of 3D deep learning models for embodied navigation.
Habitat: A Platform for Embodied AI Research
Apr 02, 2019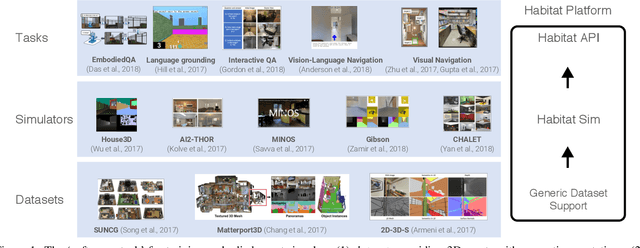
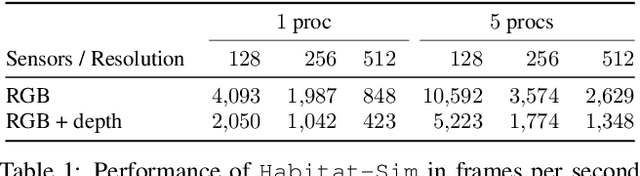

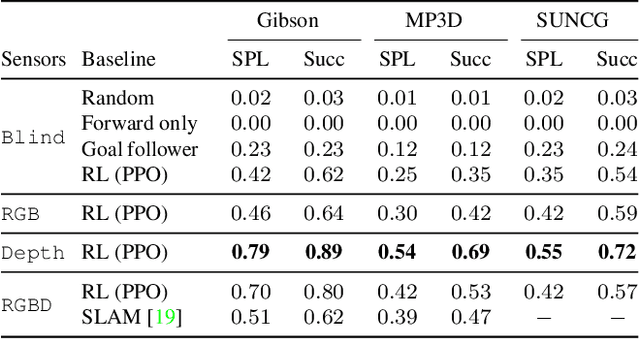
We present Habitat, a new platform for research in embodied artificial intelligence (AI). Habitat enables training embodied agents (virtual robots) in highly efficient photorealistic 3D simulation, before transferring the learned skills to reality. Specifically, Habitat consists of the following: 1. Habitat-Sim: a flexible, high-performance 3D simulator with configurable agents, multiple sensors, and generic 3D dataset handling (with built-in support for SUNCG, Matterport3D, Gibson datasets). Habitat-Sim is fast -- when rendering a scene from the Matterport3D dataset, Habitat-Sim achieves several thousand frames per second (fps) running single-threaded, and can reach over 10,000 fps multi-process on a single GPU, which is orders of magnitude faster than the closest simulator. 2. Habitat-API: a modular high-level library for end-to-end development of embodied AI algorithms -- defining embodied AI tasks (e.g. navigation, instruction following, question answering), configuring and training embodied agents (via imitation or reinforcement learning, or via classic SLAM), and benchmarking using standard metrics. These large-scale engineering contributions enable us to answer scientific questions requiring experiments that were till now impracticable or `merely' impractical. Specifically, in the context of point-goal navigation (1) we revisit the comparison between learning and SLAM approaches from two recent works and find evidence for the opposite conclusion -- that learning outperforms SLAM, if scaled to total experience far surpassing that of previous investigations, and (2) we conduct the first cross-dataset generalization experiments {train, test} x {Matterport3D, Gibson} for multiple sensors {blind, RGB, RGBD, D} and find that only agents with depth (D) sensors generalize across datasets. We hope that our open-source platform and these findings will advance research in embodied AI.