 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Synergized Mamba Meets Memory Experts for All-Day Image Reflection Separation
Jan 01, 2026Image reflection separation aims to disentangle the transmission layer and the reflection layer from a blended image. Existing methods rely on limited information from a single image, tending to confuse the two layers when their contrasts are similar, a challenge more severe at night. To address this issue, we propose the Depth-Memory Decoupling Network (DMDNet). It employs the Depth-Aware Scanning (DAScan) to guide Mamba toward salient structures, promoting information flow along semantic coherence to construct stable states. Working in synergy with DAScan, the Depth-Synergized State-Space Model (DS-SSM) modulates the sensitivity of state activations by depth, suppressing the spread of ambiguous features that interfere with layer disentanglement. Furthermore, we introduce the Memory Expert Compensation Module (MECM), leveraging cross-image historical knowledge to guide experts in providing layer-specific compensation. To address the lack of datasets for nighttime reflection separation, we construct the Nighttime Image Reflection Separation (NightIRS) dataset. Extensive experiments demonstrate that DMDNet outperforms state-of-the-art methods in both daytime and nighttime.
Taming Consistency Distillation for Accelerated Human Image Animation
Apr 15, 2025



Recent advancements in human image animation have been propelled by video diffusion models, yet their reliance on numerous iterative denoising steps results in high inference costs and slow speeds. An intuitive solution involves adopting consistency models, which serve as an effective acceleration paradigm through consistency distillation. However, simply employing this strategy in human image animation often leads to quality decline, including visual blurring, motion degradation, and facial distortion, particularly in dynamic regions. In this paper, we propose the DanceLCM approach complemented by several enhancements to improve visual quality and motion continuity at low-step regime: (1) segmented consistency distillation with an auxiliary light-weight head to incorporate supervision from real video latents, mitigating cumulative errors resulting from single full-trajectory generation; (2) a motion-focused loss to centre on motion regions, and explicit injection of facial fidelity features to improve face authenticity. Extensive qualitative and quantitative experiments demonstrate that DanceLCM achieves results comparable to state-of-the-art video diffusion models with a mere 2-4 inference steps, significantly reducing the inference burden without compromising video quality. The code and models will be made publicly available.
UniAnimate-DiT: Human Image Animation with Large-Scale Video Diffusion Transformer
Apr 15, 2025


This report presents UniAnimate-DiT, an advanced project that leverages the cutting-edge and powerful capabilities of the open-source Wan2.1 model for consistent human image animation. Specifically, to preserve the robust generative capabilities of the original Wan2.1 model, we implement Low-Rank Adaptation (LoRA) technique to fine-tune a minimal set of parameters, significantly reducing training memory overhead. A lightweight pose encoder consisting of multiple stacked 3D convolutional layers is designed to encode motion information of driving poses. Furthermore, we adopt a simple concatenation operation to integrate the reference appearance into the model and incorporate the pose information of the reference image for enhanced pose alignment. Experimental results show that our approach achieves visually appearing and temporally consistent high-fidelity animations. Trained on 480p (832x480) videos, UniAnimate-DiT demonstrates strong generalization capabilities to seamlessly upscale to 720P (1280x720) during inference. The training and inference code is publicly available at https://github.com/ali-vilab/UniAnimate-DiT.
Replace Anyone in Videos
Sep 30, 2024


Recent advancements in controllable human-centric video generation, particularly with the rise of diffusion models, have demonstrated considerable progress. However, achieving precise and localized control over human motion, e.g., replacing or inserting individuals into videos while exhibiting desired motion patterns, still remains challenging. In this work, we propose the ReplaceAnyone framework, which focuses on localizing and manipulating human motion in videos with diverse and intricate backgrounds. Specifically, we formulate this task as an image-conditioned pose-driven video inpainting paradigm, employing a unified video diffusion architecture that facilitates image-conditioned pose-driven video generation and inpainting within masked video regions. Moreover, we introduce diverse mask forms involving regular and irregular shapes to avoid shape leakage and allow granular local control. Additionally, we implement a two-stage training methodology, initially training an image-conditioned pose driven video generation model, followed by joint training of the video inpainting within masked areas. In this way, our approach enables seamless replacement or insertion of characters while maintaining the desired pose motion and reference appearance within a single framework. Experimental results demonstrate the effectiveness of our method in generating realistic and coherent video content.
Holmes-VAD: Towards Unbiased and Explainable Video Anomaly Detection via Multi-modal LLM
Jun 18, 2024



Towards open-ended Video Anomaly Detection (VAD), existing methods often exhibit biased detection when faced with challenging or unseen events and lack interpretability. To address these drawbacks, we propose Holmes-VAD, a novel framework that leverages precise temporal supervision and rich multimodal instructions to enable accurate anomaly localization and comprehensive explanations. Firstly, towards unbiased and explainable VAD system, we construct the first large-scale multimodal VAD instruction-tuning benchmark, i.e., VAD-Instruct50k. This dataset is created using a carefully designed semi-automatic labeling paradigm. Efficient single-frame annotations are applied to the collected untrimmed videos, which are then synthesized into high-quality analyses of both abnormal and normal video clips using a robust off-the-shelf video captioner and a large language model (LLM). Building upon the VAD-Instruct50k dataset, we develop a customized solution for interpretable video anomaly detection. We train a lightweight temporal sampler to select frames with high anomaly response and fine-tune a multimodal large language model (LLM) to generate explanatory content. Extensive experimental results validate the generality and interpretability of the proposed Holmes-VAD, establishing it as a novel interpretable technique for real-world video anomaly analysis. To support the community, our benchmark and model will be publicly available at https://github.com/pipixin321/HolmesVAD.
GlanceVAD: Exploring Glance Supervision for Label-efficient Video Anomaly Detection
Mar 12, 2024



In recent years, video anomaly detection has been extensively investigated in both unsupervised and weakly supervised settings to alleviate costly temporal labeling. Despite significant progress, these methods still suffer from unsatisfactory results such as numerous false alarms, primarily due to the absence of precise temporal anomaly annotation. In this paper, we present a novel labeling paradigm, termed "glance annotation", to achieve a better balance between anomaly detection accuracy and annotation cost. Specifically, glance annotation is a random frame within each abnormal event, which can be easily accessed and is cost-effective. To assess its effectiveness, we manually annotate the glance annotations for two standard video anomaly detection datasets: UCF-Crime and XD-Violence. Additionally, we propose a customized GlanceVAD method, that leverages gaussian kernels as the basic unit to compose the temporal anomaly distribution, enabling the learning of diverse and robust anomaly representations from the glance annotations. Through comprehensive analysis and experiments, we verify that the proposed labeling paradigm can achieve an excellent trade-off between annotation cost and model performance. Extensive experimental results also demonstrate the effectiveness of our GlanceVAD approach, which significantly outperforms existing advanced unsupervised and weakly supervised methods. Code and annotations will be publicly available at https://github.com/pipixin321/GlanceVAD.
MAR: Masked Autoencoders for Efficient Action Recognition
Jul 24, 2022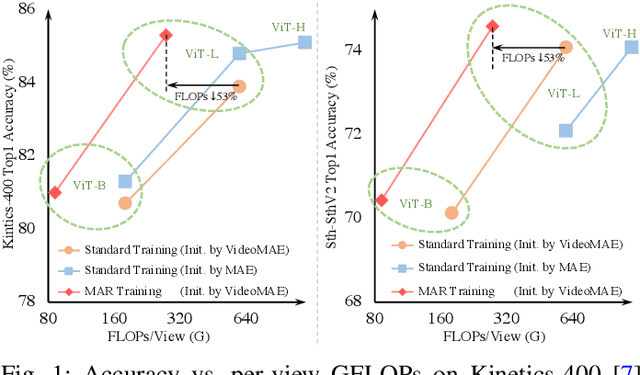
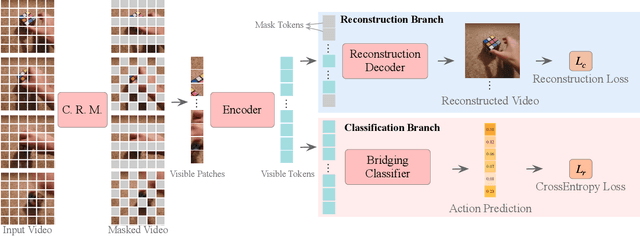
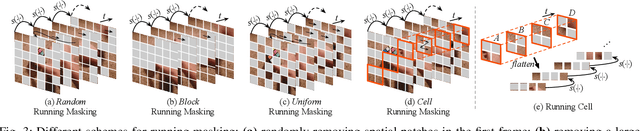
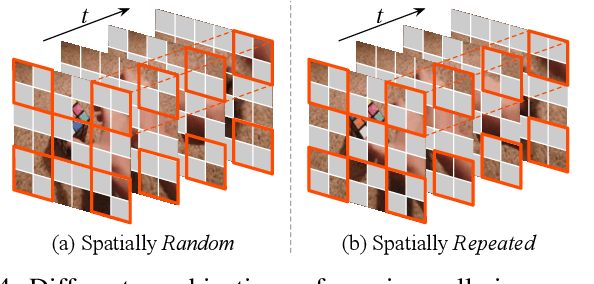
Standard approaches for video recognition usually operate on the full input videos, which is inefficient due to the widely present spatio-temporal redundancy in videos. Recent progress in masked video modelling, i.e., VideoMAE, has shown the ability of vanilla Vision Transformers (ViT) to complement spatio-temporal contexts given only limited visual contents. Inspired by this, we propose propose Masked Action Recognition (MAR), which reduces the redundant computation by discarding a proportion of patches and operating only on a part of the videos. MAR contains the following two indispensable components: cell running masking and bridging classifier. Specifically, to enable the ViT to perceive the details beyond the visible patches easily, cell running masking is presented to preserve the spatio-temporal correlations in videos, which ensures the patches at the same spatial location can be observed in turn for easy reconstructions. Additionally, we notice that, although the partially observed features can reconstruct semantically explicit invisible patches, they fail to achieve accurate classification. To address this, a bridging classifier is proposed to bridge the semantic gap between the ViT encoded features for reconstruction and the features specialized for classification. Our proposed MAR reduces the computational cost of ViT by 53% and extensive experiments show that MAR consistently outperforms existing ViT models with a notable margin. Especially, we found a ViT-Large trained by MAR outperforms the ViT-Huge trained by a standard training scheme by convincing margins on both Kinetics-400 and Something-Something v2 datasets, while our computation overhead of ViT-Large is only 14.5% of ViT-Huge.
Spatio-Temporal Matching for Siamese Visual Tracking
May 06, 2021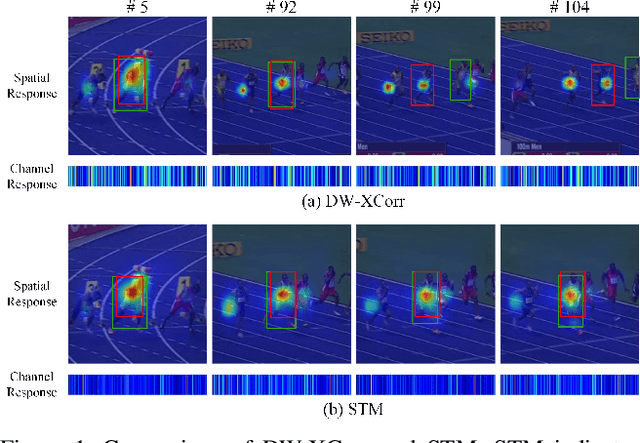
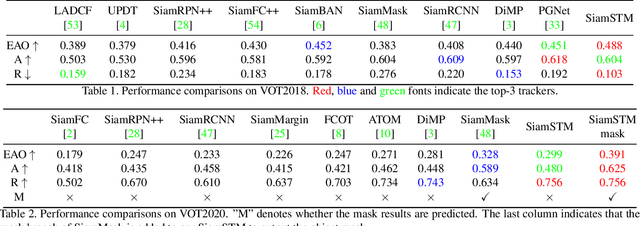
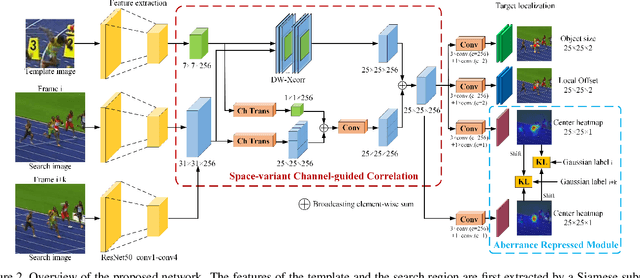
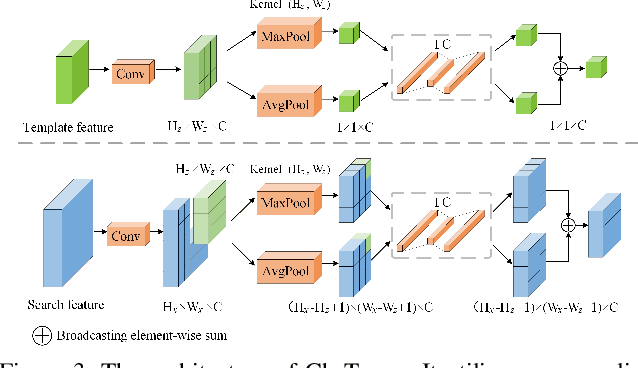
Similarity matching is a core operation in Siamese trackers. Most Siamese trackers carry out similarity learning via cross correlation that originates from the image matching field. However, unlike 2-D image matching, the matching network in object tracking requires 4-D information (height, width, channel and time). Cross correlation neglects the information from channel and time dimensions, and thus produces ambiguous matching. This paper proposes a spatio-temporal matching process to thoroughly explore the capability of 4-D matching in space (height, width and channel) and time. In spatial matching, we introduce a space-variant channel-guided correlation (SVC-Corr) to recalibrate channel-wise feature responses for each spatial location, which can guide the generation of the target-aware matching features. In temporal matching, we investigate the time-domain context relations of the target and the background and develop an aberrance repressed module (ARM). By restricting the abrupt alteration in the interframe response maps, our ARM can clearly suppress aberrances and thus enables more robust and accurate object tracking. Furthermore, a novel anchor-free tracking framework is presented to accommodate these innovations. Experiments on challenging benchmarks including OTB100, VOT2018, VOT2020, GOT-10k, and LaSOT demonstrate the state-of-the-art performance of the proposed method.