 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: AI Must Become Planet-Centered, Not Just Human-Centered
Jun 09, 2026This position paper argues that contemporary AI paradigms are insufficient for supporting complex global goals and introduces Planet-Centered AI (PCAI) as a design philosophy and research agenda that reorients AI toward planetary-scale socio-ecological systems and their long-term trajectories. A planet-centered approach is grounded in systems thinking, treating Earth as an interconnected whole of which humans are part. We diagnose recurring limitations across AI frameworks, many of which remain human-centered, and show why these become especially consequential under current planetary conditions characterized by systemic risk, non-stationarity, and deep uncertainty. We then articulate how PCAI reshapes the AI lifecycle, from problem formulation and model design to evaluation and deployment, by emphasizing alignment with global agendas, developing system-aware AI foundations, trajectory-oriented evaluation, and monitorability. Finally, we advance a falsifiable claim: AI systems optimized without explicit consideration of systemic consequences are more likely to exacerbate systemic instability than to mitigate it.
Assessing the Robustness of Climate Foundation Models under No-Analog Distribution Shifts
Mar 24, 2026The accelerating pace of climate change introduces profound non-stationarities that challenge the ability of Machine Learning based climate emulators to generalize beyond their training distributions. While these emulators offer computationally efficient alternatives to traditional Earth System Models, their reliability remains a potential bottleneck under "no-analog" future climate states, which we define here as regimes where external forcing drives the system into conditions outside the empirical range of the historical training data. A fundamental challenge in evaluating this reliability is data contamination; because many models are trained on simulations that already encompass future scenarios, true out-of-distribution (OOD) performance is often masked. To address this, we benchmark the OOD robustness of three state-of-the-art architectures: U-Net, ConvLSTM, and the ClimaX foundation model specifically restricted to a historical-only training regime (1850-2014). We evaluate these models using two complementary strategies: (i) temporal extrapolation to the recent climate (2015-2023) and (ii) cross-scenario forcing shifts across divergent emission pathways. Our analysis within this experimental setup reveals an accuracy vs. stability trade-off: while the ClimaX foundation model achieves the lowest absolute error, it exhibits higher relative performance changes under distribution shifts, with precipitation errors increasing by up to 8.44% under extreme forcing scenarios. These findings suggest that when restricted to historical training dynamics, even high-capacity foundation models are sensitive to external forcing trajectories. Our results underscore the necessity of scenario-aware training and rigorous OOD evaluation protocols to ensure the robustness of climate emulators under a changing climate.
AgentDrift: Unsafe Recommendation Drift Under Tool Corruption Hidden by Ranking Metrics in LLM Agents
Mar 18, 2026Tool-augmented LLM agents increasingly serve as multi-turn advisors in high-stakes domains, yet their evaluation relies on ranking-quality metrics that measure what is recommended but not whether it is safe for the user. We introduce a paired-trajectory protocol that replays real financial dialogues under clean and contaminated tool-output conditions across seven LLMs (7B to frontier) and decomposes divergence into information-channel and memory-channel mechanisms. Across the seven models tested, we consistently observe the evaluation-blindness pattern: recommendation quality is largely preserved under contamination (utility preservation ratio approximately 1.0) while risk-inappropriate products appear in 65-93% of turns, a systematic safety failure poorly reflected by standard NDCG. Safety violations are predominantly information-channel-driven, emerge at the first contaminated turn, and persist without self-correction over 23-step trajectories; no agent across 1,563 contaminated turns explicitly questions tool-data reliability. Even narrative-only corruption (biased headlines, no numerical manipulation) induces significant drift while completely evading consistency monitors. A safety-penalized NDCG variant (sNDCG) reduces preservation ratios to 0.51-0.74, indicating that much of the evaluation gap becomes visible once safety is explicitly measured. These results motivate considering trajectory-level safety monitoring, beyond single-turn quality, for deployed multi-turn agents in high-stakes settings.
Faithfulness of LLM Self-Explanations for Commonsense Tasks: Larger Is Better, and Instruction-Tuning Allows Trade-Offs but Not Pareto Dominance
Mar 17, 2025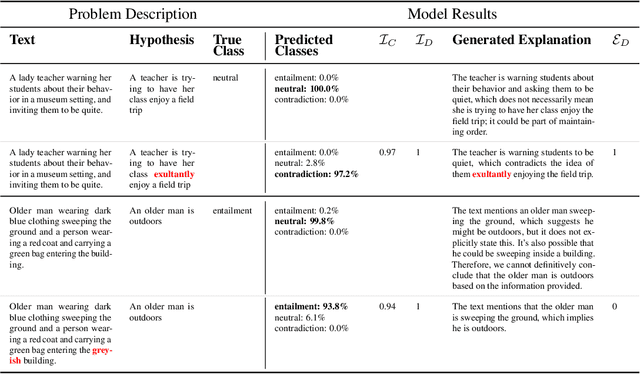
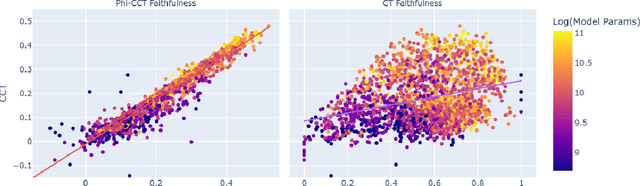
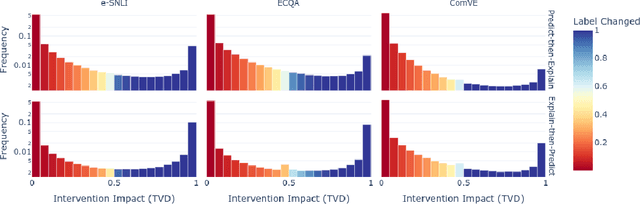
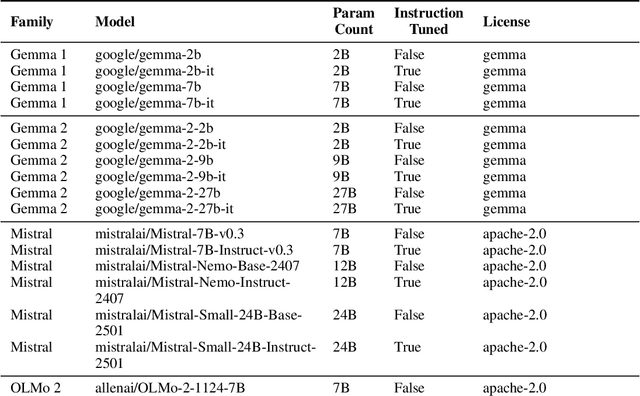
As large language models (LLMs) become increasingly capable, ensuring that their self-generated explanations are faithful to their internal decision-making process is critical for safety and oversight. In this work, we conduct a comprehensive counterfactual faithfulness analysis across 62 models from 8 families, encompassing both pretrained and instruction-tuned variants and significantly extending prior studies of counterfactual tests. We introduce phi-CCT, a simplified variant of the Correlational Counterfactual Test, which avoids the need for token probabilities while explaining most of the variance of the original test. Our findings reveal clear scaling trends: larger models are consistently more faithful on our metrics. However, when comparing instruction-tuned and human-imitated explanations, we find that observed differences in faithfulness can often be attributed to explanation verbosity, leading to shifts along the true-positive/false-positive Pareto frontier. While instruction-tuning and prompting can influence this trade-off, we find limited evidence that they fundamentally expand the frontier of explanatory faithfulness beyond what is achievable with pretrained models of comparable size. Our analysis highlights the nuanced relationship between instruction-tuning, verbosity, and the faithful representation of model decision processes.
How Can We Diagnose and Treat Bias in Large Language Models for Clinical Decision-Making?
Oct 21, 2024



Recent advancements in Large Language Models (LLMs) have positioned them as powerful tools for clinical decision-making, with rapidly expanding applications in healthcare. However, concerns about bias remain a significant challenge in the clinical implementation of LLMs, particularly regarding gender and ethnicity. This research investigates the evaluation and mitigation of bias in LLMs applied to complex clinical cases, focusing on gender and ethnicity biases. We introduce a novel Counterfactual Patient Variations (CPV) dataset derived from the JAMA Clinical Challenge. Using this dataset, we built a framework for bias evaluation, employing both Multiple Choice Questions (MCQs) and corresponding explanations. We explore prompting with eight LLMs and fine-tuning as debiasing methods. Our findings reveal that addressing social biases in LLMs requires a multidimensional approach as mitigating gender bias can occur while introducing ethnicity biases, and that gender bias in LLM embeddings varies significantly across medical specialities. We demonstrate that evaluating both MCQ response and explanation processes is crucial, as correct responses can be based on biased \textit{reasoning}. We provide a framework for evaluating LLM bias in real-world clinical cases, offer insights into the complex nature of bias in these models, and present strategies for bias mitigation.
JobFair: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Jun 17, 2024



This paper presents a novel framework for benchmarking hierarchical gender hiring bias in Large Language Models (LLMs) for resume scoring, revealing significant issues of reverse bias and overdebiasing. Our contributions are fourfold: First, we introduce a framework using a real, anonymized resume dataset from the Healthcare, Finance, and Construction industries, meticulously used to avoid confounding factors. It evaluates gender hiring biases across hierarchical levels, including Level bias, Spread bias, Taste-based bias, and Statistical bias. This framework can be generalized to other social traits and tasks easily. Second, we propose novel statistical and computational hiring bias metrics based on a counterfactual approach, including Rank After Scoring (RAS), Rank-based Impact Ratio, Permutation Test-Based Metrics, and Fixed Effects Model-based Metrics. These metrics, rooted in labor economics, NLP, and law, enable holistic evaluation of hiring biases. Third, we analyze hiring biases in ten state-of-the-art LLMs. Six out of ten LLMs show significant biases against males in healthcare and finance. An industry-effect regression reveals that the healthcare industry is the most biased against males. GPT-4o and GPT-3.5 are the most biased models, showing significant bias in all three industries. Conversely, Gemini-1.5-Pro, Llama3-8b-Instruct, and Llama3-70b-Instruct are the least biased. The hiring bias of all LLMs, except for Llama3-8b-Instruct and Claude-3-Sonnet, remains consistent regardless of random expansion or reduction of resume content. Finally, we offer a user-friendly demo to facilitate adoption and practical application of the framework.
The Probabilities Also Matter: A More Faithful Metric for Faithfulness of Free-Text Explanations in Large Language Models
Apr 04, 2024



In order to oversee advanced AI systems, it is important to understand their underlying decision-making process. When prompted, large language models (LLMs) can provide natural language explanations or reasoning traces that sound plausible and receive high ratings from human annotators. However, it is unclear to what extent these explanations are faithful, i.e., truly capture the factors responsible for the model's predictions. In this work, we introduce Correlational Explanatory Faithfulness (CEF), a metric that can be used in faithfulness tests based on input interventions. Previous metrics used in such tests take into account only binary changes in the predictions. Our metric accounts for the total shift in the model's predicted label distribution, more accurately reflecting the explanations' faithfulness. We then introduce the Correlational Counterfactual Test (CCT) by instantiating CEF on the Counterfactual Test (CT) from Atanasova et al. (2023). We evaluate the faithfulness of free-text explanations generated by few-shot-prompted LLMs from the Llama2 family on three NLP tasks. We find that our metric measures aspects of faithfulness which the CT misses.
Auditing Large Language Models for Enhanced Text-Based Stereotype Detection and Probing-Based Bias Evaluation
Apr 02, 2024



Recent advancements in Large Language Models (LLMs) have significantly increased their presence in human-facing Artificial Intelligence (AI) applications. However, LLMs could reproduce and even exacerbate stereotypical outputs from training data. This work introduces the Multi-Grain Stereotype (MGS) dataset, encompassing 51,867 instances across gender, race, profession, religion, and stereotypical text, collected by fusing multiple previously publicly available stereotype detection datasets. We explore different machine learning approaches aimed at establishing baselines for stereotype detection, and fine-tune several language models of various architectures and model sizes, presenting in this work a series of stereotypes classifier models for English text trained on MGS. To understand whether our stereotype detectors capture relevant features (aligning with human common sense) we utilise a variety of explanainable AI tools, including SHAP, LIME, and BertViz, and analyse a series of example cases discussing the results. Finally, we develop a series of stereotype elicitation prompts and evaluate the presence of stereotypes in text generation tasks with popular LLMs, using one of our best performing previously presented stereotypes detectors. Our experiments yielded several key findings: i) Training stereotype detectors in a multi-dimension setting yields better results than training multiple single-dimension classifiers.ii) The integrated MGS Dataset enhances both the in-dataset and cross-dataset generalisation ability of stereotype detectors compared to using the datasets separately. iii) There is a reduction in stereotypes in the content generated by GPT Family LLMs with newer versions.
Can Reinforcement Learning support policy makers? A preliminary study with Integrated Assessment Models
Dec 11, 2023Governments around the world aspire to ground decision-making on evidence. Many of the foundations of policy making - e.g. sensing patterns that relate to societal needs, developing evidence-based programs, forecasting potential outcomes of policy changes, and monitoring effectiveness of policy programs - have the potential to benefit from the use of large-scale datasets or simulations together with intelligent algorithms. These could, if designed and deployed in a way that is well grounded on scientific evidence, enable a more comprehensive, faster, and rigorous approach to policy making. Integrated Assessment Models (IAM) is a broad umbrella covering scientific models that attempt to link main features of society and economy with the biosphere into one modelling framework. At present, these systems are probed by policy makers and advisory groups in a hypothesis-driven manner. In this paper, we empirically demonstrate that modern Reinforcement Learning can be used to probe IAMs and explore the space of solutions in a more principled manner. While the implication of our results are modest since the environment is simplistic, we believe that this is a stepping stone towards more ambitious use cases, which could allow for effective exploration of policies and understanding of their consequences and limitations.
Can Population-based Engagement Improve Personalisation? A Novel Dataset and Experiments
Jun 22, 2022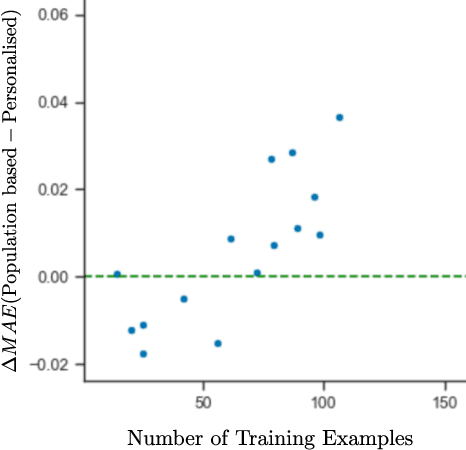
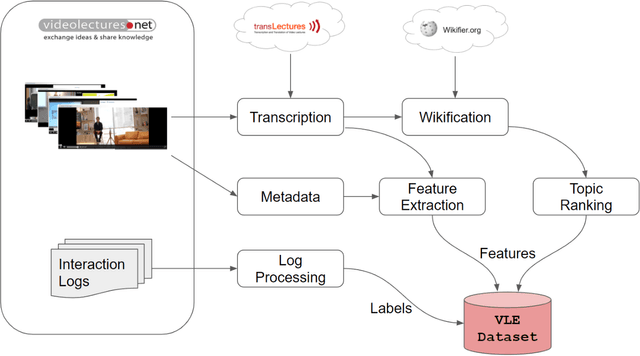
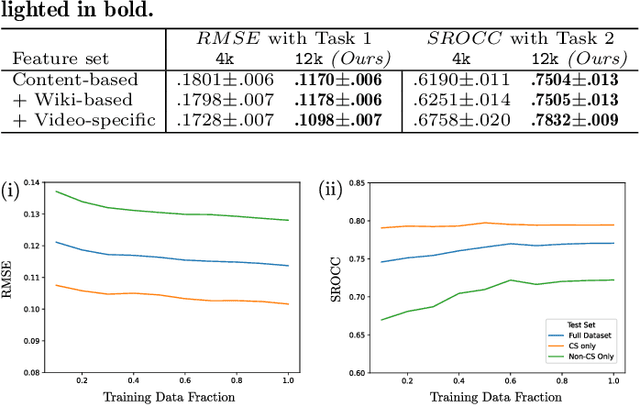
This work explores how population-based engagement prediction can address cold-start at scale in large learning resource collections. The paper introduces i) VLE, a novel dataset that consists of content and video based features extracted from publicly available scientific video lectures coupled with implicit and explicit signals related to learner engagement, ii) two standard tasks related to predicting and ranking context-agnostic engagement in video lectures with preliminary baselines and iii) a set of experiments that validate the usefulness of the proposed dataset. Our experimental results indicate that the newly proposed VLE dataset leads to building context-agnostic engagement prediction models that are significantly performant than ones based on previous datasets, mainly attributing to the increase of training examples. VLE dataset's suitability in building models towards Computer Science/ Artificial Intelligence education focused on e-learning/ MOOC use-cases is also evidenced. Further experiments in combining the built model with a personalising algorithm show promising improvements in addressing the cold-start problem encountered in educational recommenders. This is the largest and most diverse publicly available dataset to our knowledge that deals with learner engagement prediction tasks. The dataset, helper tools, descriptive statistics and example code snippets are available publicly.