 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-AntiFake: Rethinking the Protective Perturbations Against Voice Cloning Attacks
Jul 03, 2025The rapid advancement of speech generation models has heightened privacy and security concerns related to voice cloning (VC). Recent studies have investigated disrupting unauthorized voice cloning by introducing adversarial perturbations. However, determined attackers can mitigate these protective perturbations and successfully execute VC. In this study, we conduct the first systematic evaluation of these protective perturbations against VC under realistic threat models that include perturbation purification. Our findings reveal that while existing purification methods can neutralize a considerable portion of the protective perturbations, they still lead to distortions in the feature space of VC models, which degrades the performance of VC. From this perspective, we propose a novel two-stage purification method: (1) Purify the perturbed speech; (2) Refine it using phoneme guidance to align it with the clean speech distribution. Experimental results demonstrate that our method outperforms state-of-the-art purification methods in disrupting VC defenses. Our study reveals the limitations of adversarial perturbation-based VC defenses and underscores the urgent need for more robust solutions to mitigate the security and privacy risks posed by VC. The code and audio samples are available at https://de-antifake.github.io.
ScaleCap: Inference-Time Scalable Image Captioning via Dual-Modality Debiasing
Jun 24, 2025
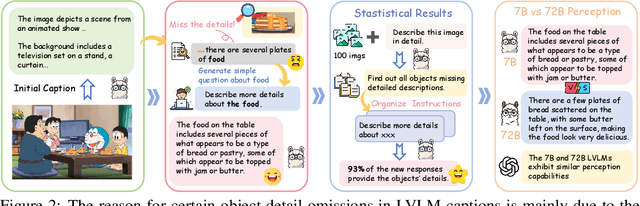

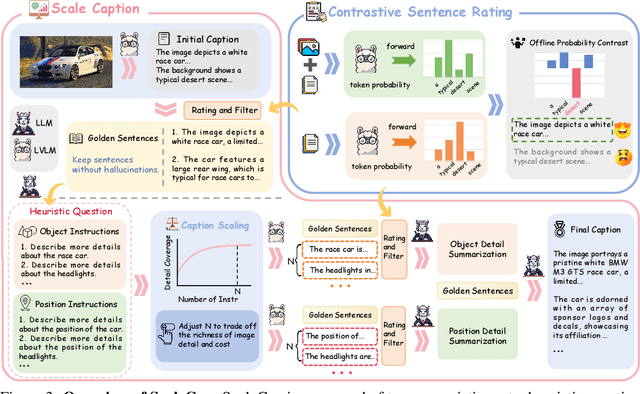
This paper presents ScaleCap, an inference-time scalable image captioning strategy that generates comprehensive and detailed image captions. The key challenges of high-quality image captioning lie in the inherent biases of LVLMs: multimodal bias resulting in imbalanced descriptive granularity, offering detailed accounts of some elements while merely skimming over others; linguistic bias leading to hallucinated descriptions of non-existent objects. To address these issues, we propose a scalable debiased captioning strategy, which continuously enriches and calibrates the caption with increased inference budget. Specifically, we propose two novel components: heuristic question answering and contrastive sentence rating. The former generates content-specific questions based on the image and answers them to progressively inject relevant information into the caption. The latter employs sentence-level offline contrastive decoding to effectively identify and eliminate hallucinations caused by linguistic biases. With increased inference cost, more heuristic questions are raised by ScaleCap to progressively capture additional visual details, generating captions that are more accurate, balanced, and informative. Extensive modality alignment experiments demonstrate the effectiveness of ScaleCap. Annotating 450K images with ScaleCap and using them for LVLM pretraining leads to consistent performance gains across 11 widely used benchmarks. Furthermore, ScaleCap showcases superb richness and fidelity of generated captions with two additional tasks: replacing images with captions in VQA task, and reconstructing images from captions to assess semantic coverage. Code is available at https://github.com/Cooperx521/ScaleCap.
MARS-Bench: A Multi-turn Athletic Real-world Scenario Benchmark for Dialogue Evaluation
May 27, 2025Large Language Models (\textbf{LLMs}), e.g. ChatGPT, have been widely adopted in real-world dialogue applications. However, LLMs' robustness, especially in handling long complex dialogue sessions, including frequent motivation transfer, sophisticated cross-turn dependency, is criticized all along. Nevertheless, no existing benchmarks can fully reflect these weaknesses. We present \textbf{MARS-Bench}, a \textbf{M}ulti-turn \textbf{A}thletic \textbf{R}eal-world \textbf{S}cenario Dialogue \textbf{Bench}mark, designed to remedy the gap. MARS-Bench is constructed from play-by-play text commentary so to feature realistic dialogues specifically designed to evaluate three critical aspects of multi-turn conversations: Ultra Multi-turn, Interactive Multi-turn, and Cross-turn Tasks. Extensive experiments on MARS-Bench also reveal that closed-source LLMs significantly outperform open-source alternatives, explicit reasoning significantly boosts LLMs' robustness on handling long complex dialogue sessions, and LLMs indeed face significant challenges when handling motivation transfer and sophisticated cross-turn dependency. Moreover, we provide mechanistic interpretability on how attention sinks due to special tokens lead to LLMs' performance degradation when handling long complex dialogue sessions based on attention visualization experiment in Qwen2.5-7B-Instruction.
Gaussian Shading++: Rethinking the Realistic Deployment Challenge of Performance-Lossless Image Watermark for Diffusion Models
Apr 21, 2025



Ethical concerns surrounding copyright protection and inappropriate content generation pose challenges for the practical implementation of diffusion models. One effective solution involves watermarking the generated images. Existing methods primarily focus on ensuring that watermark embedding does not degrade the model performance. However, they often overlook critical challenges in real-world deployment scenarios, such as the complexity of watermark key management, user-defined generation parameters, and the difficulty of verification by arbitrary third parties. To address this issue, we propose Gaussian Shading++, a diffusion model watermarking method tailored for real-world deployment. We propose a double-channel design that leverages pseudorandom error-correcting codes to encode the random seed required for watermark pseudorandomization, achieving performance-lossless watermarking under a fixed watermark key and overcoming key management challenges. Additionally, we model the distortions introduced during generation and inversion as an additive white Gaussian noise channel and employ a novel soft decision decoding strategy during extraction, ensuring strong robustness even when generation parameters vary. To enable third-party verification, we incorporate public key signatures, which provide a certain level of resistance against forgery attacks even when model inversion capabilities are fully disclosed. Extensive experiments demonstrate that Gaussian Shading++ not only maintains performance losslessness but also outperforms existing methods in terms of robustness, making it a more practical solution for real-world deployment.
Clean Image May be Dangerous: Data Poisoning Attacks Against Deep Hashing
Mar 27, 2025Large-scale image retrieval using deep hashing has become increasingly popular due to the exponential growth of image data and the remarkable feature extraction capabilities of deep neural networks (DNNs). However, deep hashing methods are vulnerable to malicious attacks, including adversarial and backdoor attacks. It is worth noting that these attacks typically involve altering the query images, which is not a practical concern in real-world scenarios. In this paper, we point out that even clean query images can be dangerous, inducing malicious target retrieval results, like undesired or illegal images. To the best of our knowledge, we are the first to study data \textbf{p}oisoning \textbf{a}ttacks against \textbf{d}eep \textbf{hash}ing \textbf{(\textit{PADHASH})}. Specifically, we first train a surrogate model to simulate the behavior of the target deep hashing model. Then, a strict gradient matching strategy is proposed to generate the poisoned images. Extensive experiments on different models, datasets, hash methods, and hash code lengths demonstrate the effectiveness and generality of our attack method.
Context-Aware Weakly Supervised Image Manipulation Localization with SAM Refinement
Mar 26, 2025Malicious image manipulation poses societal risks, increasing the importance of effective image manipulation detection methods. Recent approaches in image manipulation detection have largely been driven by fully supervised approaches, which require labor-intensive pixel-level annotations. Thus, it is essential to explore weakly supervised image manipulation localization methods that only require image-level binary labels for training. However, existing weakly supervised image manipulation methods overlook the importance of edge information for accurate localization, leading to suboptimal localization performance. To address this, we propose a Context-Aware Boundary Localization (CABL) module to aggregate boundary features and learn context-inconsistency for localizing manipulated areas. Furthermore, by leveraging Class Activation Mapping (CAM) and Segment Anything Model (SAM), we introduce the CAM-Guided SAM Refinement (CGSR) module to generate more accurate manipulation localization maps. By integrating two modules, we present a novel weakly supervised framework based on a dual-branch Transformer-CNN architecture. Our method achieves outstanding localization performance across multiple datasets.
MES-RAG: Bringing Multi-modal, Entity-Storage, and Secure Enhancements to RAG
Mar 17, 2025



Retrieval-Augmented Generation (RAG) improves Large Language Models (LLMs) by using external knowledge, but it struggles with precise entity information retrieval. In this paper, we proposed MES-RAG framework, which enhances entity-specific query handling and provides accurate, secure, and consistent responses. MES-RAG introduces proactive security measures that ensure system integrity by applying protections prior to data access. Additionally, the system supports real-time multi-modal outputs, including text, images, audio, and video, seamlessly integrating into existing RAG architectures. Experimental results demonstrate that MES-RAG significantly improves both accuracy and recall, highlighting its effectiveness in advancing the security and utility of question-answering, increasing accuracy to 0.83 (+0.25) on targeted task. Our code and data are available at https://github.com/wpydcr/MES-RAG.
Exploiting Vulnerabilities in Speech Translation Systems through Targeted Adversarial Attacks
Mar 05, 2025As speech translation (ST) systems become increasingly prevalent, understanding their vulnerabilities is crucial for ensuring robust and reliable communication. However, limited work has explored this issue in depth. This paper explores methods of compromising these systems through imperceptible audio manipulations. Specifically, we present two innovative approaches: (1) the injection of perturbation into source audio, and (2) the generation of adversarial music designed to guide targeted translation, while also conducting more practical over-the-air attacks in the physical world. Our experiments reveal that carefully crafted audio perturbations can mislead translation models to produce targeted, harmful outputs, while adversarial music achieve this goal more covertly, exploiting the natural imperceptibility of music. These attacks prove effective across multiple languages and translation models, highlighting a systemic vulnerability in current ST architectures. The implications of this research extend beyond immediate security concerns, shedding light on the interpretability and robustness of neural speech processing systems. Our findings underscore the need for advanced defense mechanisms and more resilient architectures in the realm of audio systems. More details and samples can be found at https://adv-st.github.io.
M3-AGIQA: Multimodal, Multi-Round, Multi-Aspect AI-Generated Image Quality Assessment
Feb 21, 2025The rapid advancement of AI-generated image (AGI) models has introduced significant challenges in evaluating their quality, which requires considering multiple dimensions such as perceptual quality, prompt correspondence, and authenticity. To address these challenges, we propose M3-AGIQA, a comprehensive framework for AGI quality assessment that is Multimodal, Multi-Round, and Multi-Aspect. Our approach leverages the capabilities of Multimodal Large Language Models (MLLMs) as joint text and image encoders and distills advanced captioning capabilities from online MLLMs into a local model via Low-Rank Adaptation (LoRA) fine-tuning. The framework includes a structured multi-round evaluation mechanism, where intermediate image descriptions are generated to provide deeper insights into the quality, correspondence, and authenticity aspects. To align predictions with human perceptual judgments, a predictor constructed by an xLSTM and a regression head is incorporated to process sequential logits and predict Mean Opinion Scores (MOSs). Extensive experiments conducted on multiple benchmark datasets demonstrate that M3-AGIQA achieves state-of-the-art performance, effectively capturing nuanced aspects of AGI quality. Furthermore, cross-dataset validation confirms its strong generalizability. The code is available at https://github.com/strawhatboy/M3-AGIQA.
FaceTracer: Unveiling Source Identities from Swapped Face Images and Videos for Fraud Prevention
Dec 11, 2024



Face-swapping techniques have advanced rapidly with the evolution of deep learning, leading to widespread use and growing concerns about potential misuse, especially in cases of fraud. While many efforts have focused on detecting swapped face images or videos, these methods are insufficient for tracing the malicious users behind fraudulent activities. Intrusive watermark-based approaches also fail to trace unmarked identities, limiting their practical utility. To address these challenges, we introduce FaceTracer, the first non-intrusive framework specifically designed to trace the identity of the source person from swapped face images or videos. Specifically, FaceTracer leverages a disentanglement module that effectively suppresses identity information related to the target person while isolating the identity features of the source person. This allows us to extract robust identity information that can directly link the swapped face back to the original individual, aiding in uncovering the actors behind fraudulent activities. Extensive experiments demonstrate FaceTracer's effectiveness across various face-swapping techniques, successfully identifying the source person in swapped content and enabling the tracing of malicious actors involved in fraudulent activities. Additionally, FaceTracer shows strong transferability to unseen face-swapping methods including commercial applications and robustness against transmission distortions and adaptive attacks.