 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Accurate Object Detection via Adversarial Learning
Mar 26, 2021
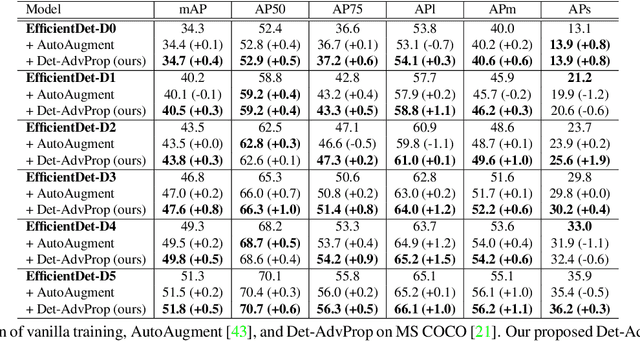
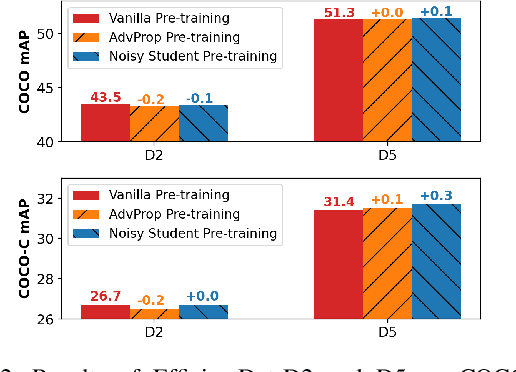
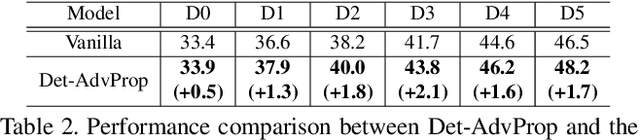
Data augmentation has become a de facto component for training high-performance deep image classifiers, but its potential is under-explored for object detection. Noting that most state-of-the-art object detectors benefit from fine-tuning a pre-trained classifier, we first study how the classifiers' gains from various data augmentations transfer to object detection. The results are discouraging; the gains diminish after fine-tuning in terms of either accuracy or robustness. This work instead augments the fine-tuning stage for object detectors by exploring adversarial examples, which can be viewed as a model-dependent data augmentation. Our method dynamically selects the stronger adversarial images sourced from a detector's classification and localization branches and evolves with the detector to ensure the augmentation policy stays current and relevant. This model-dependent augmentation generalizes to different object detectors better than AutoAugment, a model-agnostic augmentation policy searched based on one particular detector. Our approach boosts the performance of state-of-the-art EfficientDets by +1.1 mAP on the COCO object detection benchmark. It also improves the detectors' robustness against natural distortions by +3.8 mAP and against domain shift by +1.3 mAP. Models are available at https://github.com/google/automl/tree/master/efficientdet/Det-AdvProp.md
Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention
Mar 05, 2021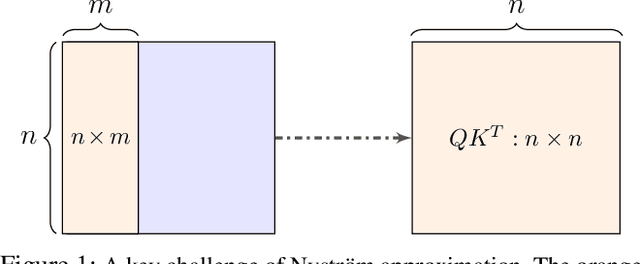

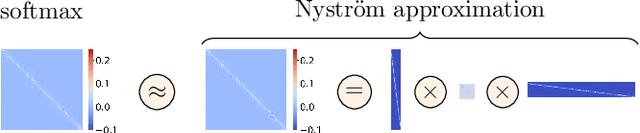

Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the input sequence length has limited its application to longer sequences -- a topic being actively studied in the community. To address this limitation, we propose Nystr\"{o}mformer -- a model that exhibits favorable scalability as a function of sequence length. Our idea is based on adapting the Nystr\"{o}m method to approximate standard self-attention with $O(n)$ complexity. The scalability of Nystr\"{o}mformer enables application to longer sequences with thousands of tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard sequence length, and find that our Nystr\"{o}mformer performs comparably, or in a few cases, even slightly better, than standard self-attention. On longer sequence tasks in the Long Range Arena (LRA) benchmark, Nystr\"{o}mformer performs favorably relative to other efficient self-attention methods. Our code is available at https://github.com/mlpen/Nystromformer.
Rethinking Co-design of Neural Architectures and Hardware Accelerators
Feb 17, 2021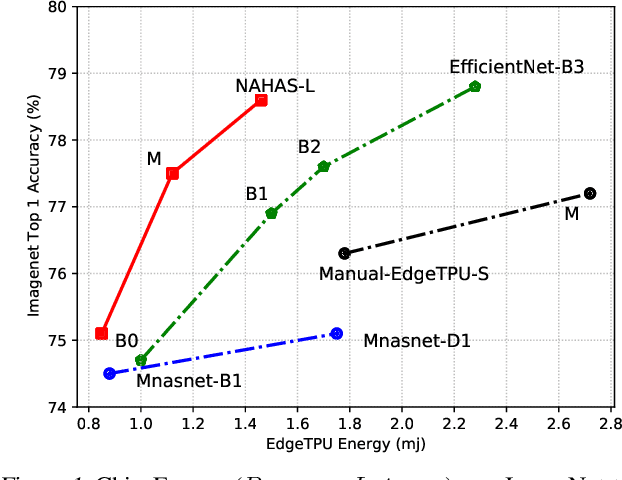
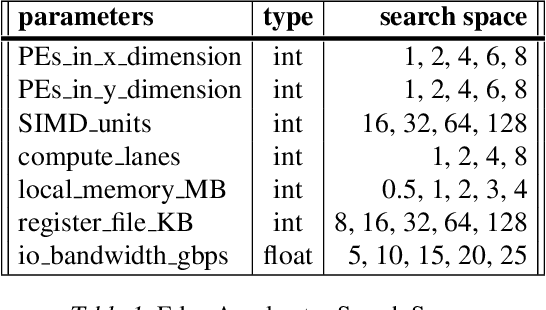
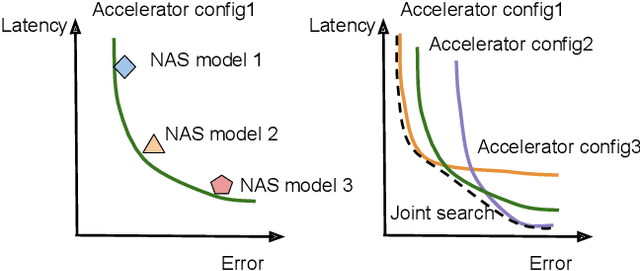
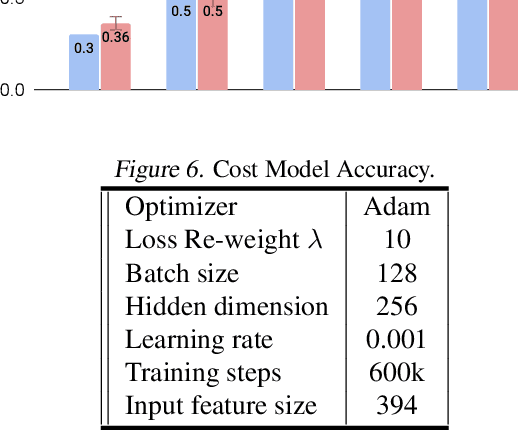
Neural architectures and hardware accelerators have been two driving forces for the progress in deep learning. Previous works typically attempt to optimize hardware given a fixed model architecture or model architecture given fixed hardware. And the dominant hardware architecture explored in this prior work is FPGAs. In our work, we target the optimization of hardware and software configurations on an industry-standard edge accelerator. We systematically study the importance and strategies of co-designing neural architectures and hardware accelerators. We make three observations: 1) the software search space has to be customized to fully leverage the targeted hardware architecture, 2) the search for the model architecture and hardware architecture should be done jointly to achieve the best of both worlds, and 3) different use cases lead to very different search outcomes. Our experiments show that the joint search method consistently outperforms previous platform-aware neural architecture search, manually crafted models, and the state-of-the-art EfficientNet on all latency targets by around 1% on ImageNet top-1 accuracy. Our method can reduce energy consumption of an edge accelerator by up to 2x under the same accuracy constraint, when co-adapting the model architecture and hardware accelerator configurations.
Searching for Fast Model Families on Datacenter Accelerators
Feb 10, 2021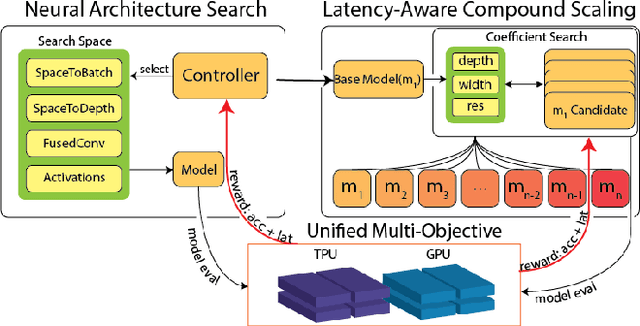
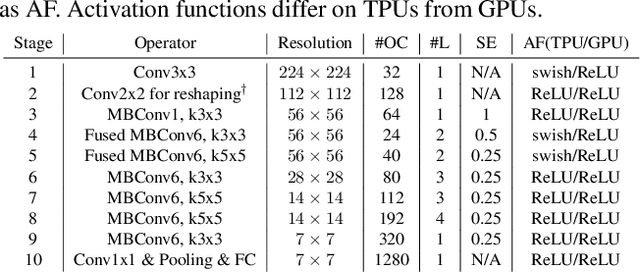
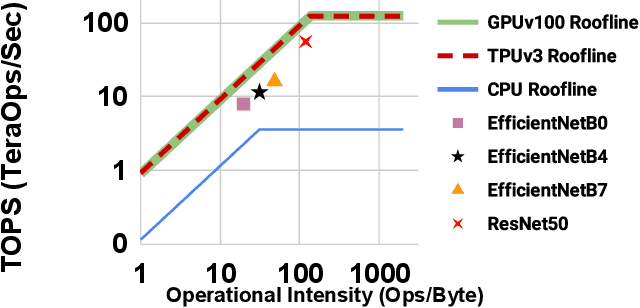

Neural Architecture Search (NAS), together with model scaling, has shown remarkable progress in designing high accuracy and fast convolutional architecture families. However, as neither NAS nor model scaling considers sufficient hardware architecture details, they do not take full advantage of the emerging datacenter (DC) accelerators. In this paper, we search for fast and accurate CNN model families for efficient inference on DC accelerators. We first analyze DC accelerators and find that existing CNNs suffer from insufficient operational intensity, parallelism, and execution efficiency. These insights let us create a DC-accelerator-optimized search space, with space-to-depth, space-to-batch, hybrid fused convolution structures with vanilla and depthwise convolutions, and block-wise activation functions. On top of our DC accelerator optimized neural architecture search space, we further propose a latency-aware compound scaling (LACS), the first multi-objective compound scaling method optimizing both accuracy and latency. Our LACS discovers that network depth should grow much faster than image size and network width, which is quite different from previous compound scaling results. With the new search space and LACS, our search and scaling on datacenter accelerators results in a new model series named EfficientNet-X. EfficientNet-X is up to more than 2X faster than EfficientNet (a model series with state-of-the-art trade-off on FLOPs and accuracy) on TPUv3 and GPUv100, with comparable accuracy. EfficientNet-X is also up to 7X faster than recent RegNet and ResNeSt on TPUv3 and GPUv100.
PyGlove: Symbolic Programming for Automated Machine Learning
Jan 21, 2021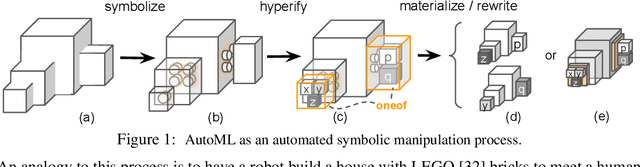
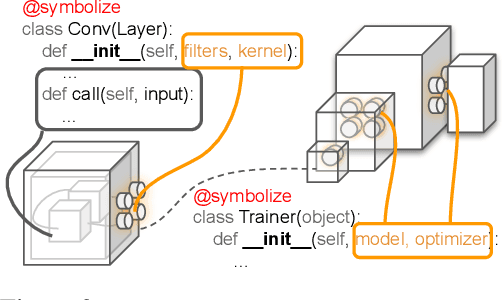
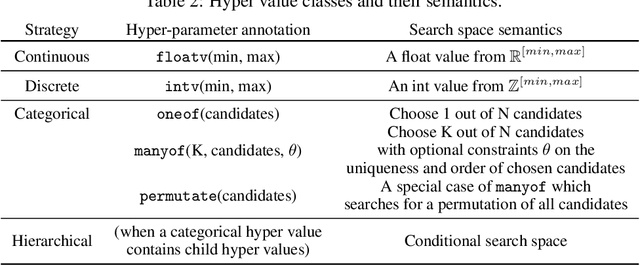

Neural networks are sensitive to hyper-parameter and architecture choices. Automated Machine Learning (AutoML) is a promising paradigm for automating these choices. Current ML software libraries, however, are quite limited in handling the dynamic interactions among the components of AutoML. For example, efficientNAS algorithms, such as ENAS and DARTS, typically require an implementation coupling between the search space and search algorithm, the two key components in AutoML. Furthermore, implementing a complex search flow, such as searching architectures within a loop of searching hardware configurations, is difficult. To summarize, changing the search space, search algorithm, or search flow in current ML libraries usually requires a significant change in the program logic. In this paper, we introduce a new way of programming AutoML based on symbolic programming. Under this paradigm, ML programs are mutable, thus can be manipulated easily by another program. As a result, AutoML can be reformulated as an automated process of symbolic manipulation. With this formulation, we decouple the triangle of the search algorithm, the search space and the child program. This decoupling makes it easy to change the search space and search algorithm (without and with weight sharing), as well as to add search capabilities to existing code and implement complex search flows. We then introduce PyGlove, a new Python library that implements this paradigm. Through case studies on ImageNet and NAS-Bench-101, we show that with PyGlove users can easily convert a static program into a search space, quickly iterate on the search spaces and search algorithms, and craft complex search flows to achieve better results.
Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour
Nov 05, 2020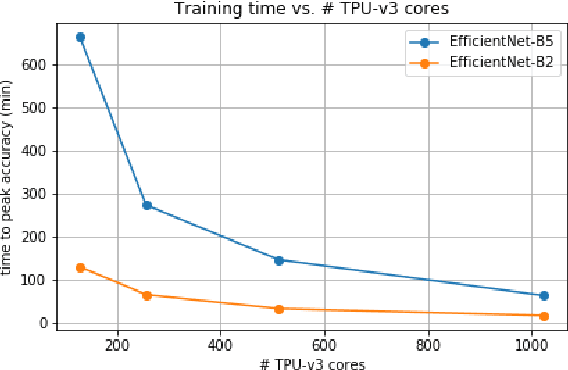
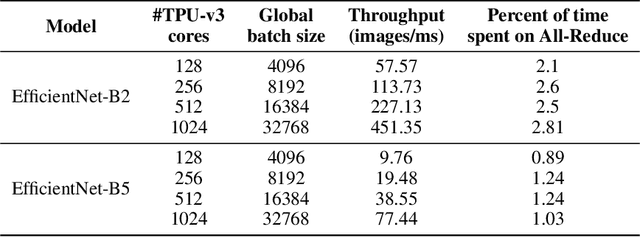
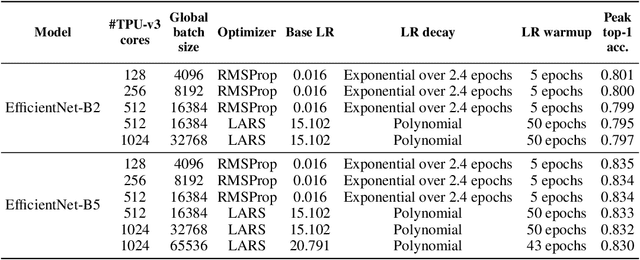
EfficientNets are a family of state-of-the-art image classification models based on efficiently scaled convolutional neural networks. Currently, EfficientNets can take on the order of days to train; for example, training an EfficientNet-B0 model takes 23 hours on a Cloud TPU v2-8 node. In this paper, we explore techniques to scale up the training of EfficientNets on TPU-v3 Pods with 2048 cores, motivated by speedups that can be achieved when training at such scales. We discuss optimizations required to scale training to a batch size of 65536 on 1024 TPU-v3 cores, such as selecting large batch optimizers and learning rate schedules as well as utilizing distributed evaluation and batch normalization techniques. Additionally, we present timing and performance benchmarks for EfficientNet models trained on the ImageNet dataset in order to analyze the behavior of EfficientNets at scale. With our optimizations, we are able to train EfficientNet on ImageNet to an accuracy of 83% in 1 hour and 4 minutes.
Efficient Scale-Permuted Backbone with Learned Resource Distribution
Oct 22, 2020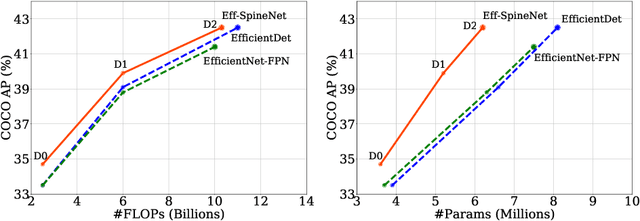
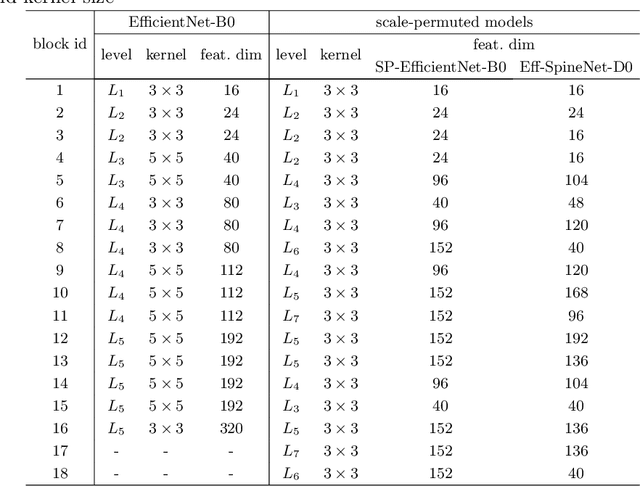
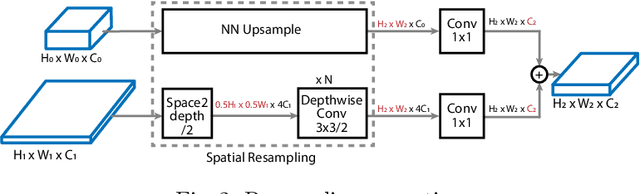

Recently, SpineNet has demonstrated promising results on object detection and image classification over ResNet model. However, it is unclear if the improvement adds up when combining scale-permuted backbone with advanced efficient operations and compound scaling. Furthermore, SpineNet is built with a uniform resource distribution over operations. While this strategy seems to be prevalent for scale-decreased models, it may not be an optimal design for scale-permuted models. In this work, we propose a simple technique to combine efficient operations and compound scaling with a previously learned scale-permuted architecture. We demonstrate the efficiency of scale-permuted model can be further improved by learning a resource distribution over the entire network. The resulting efficient scale-permuted models outperform state-of-the-art EfficientNet-based models on object detection and achieve competitive performance on image classification and semantic segmentation. Code and models will be open-sourced soon.
Shape-Texture Debiased Neural Network Training
Oct 12, 2020

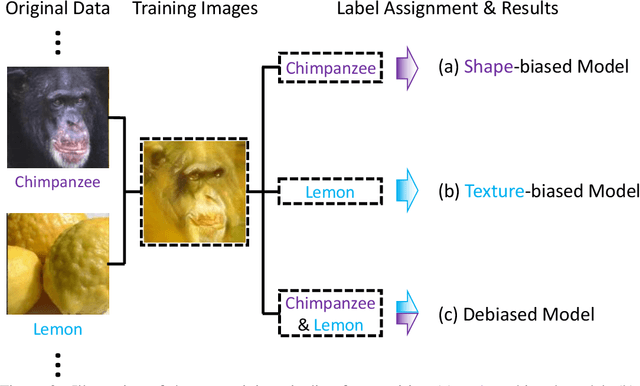
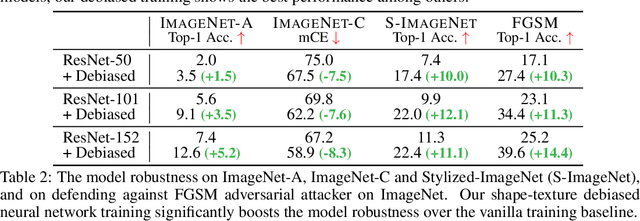
Shape and texture are two prominent and complementary cues for recognizing objects. Nonetheless, Convolutional Neural Networks are often biased towards either texture or shape, depending on the training dataset. Our ablation shows that such bias degenerates model performance. Motivated by this observation, we develop a simple algorithm for shape-texture debiased learning. To prevent models from exclusively attending on a single cue in representation learning, we augment training data with images with conflicting shape and texture information (e.g., an image of chimpanzee shape but with lemon texture) and, most importantly, provide the corresponding supervisions from shape and texture simultaneously. Experiments show that our method successfully improves model performance on several image recognition benchmarks and adversarial robustness. For example, by training on ImageNet, it helps ResNet-152 achieve substantial improvements on ImageNet (+1.2%), ImageNet-A (+5.2%), ImageNet-C (+8.3%) and Stylized-ImageNet (+11.1%), and on defending against FGSM adversarial attacker on ImageNet (+14.4%). Our method also claims to be compatible to other advanced data augmentation strategies, e.g., Mixup and CutMix. The code is available here: https://github.com/LiYingwei/ShapeTextureDebiasedTraining.
Go Wide, Then Narrow: Efficient Training of Deep Thin Networks
Jul 01, 2020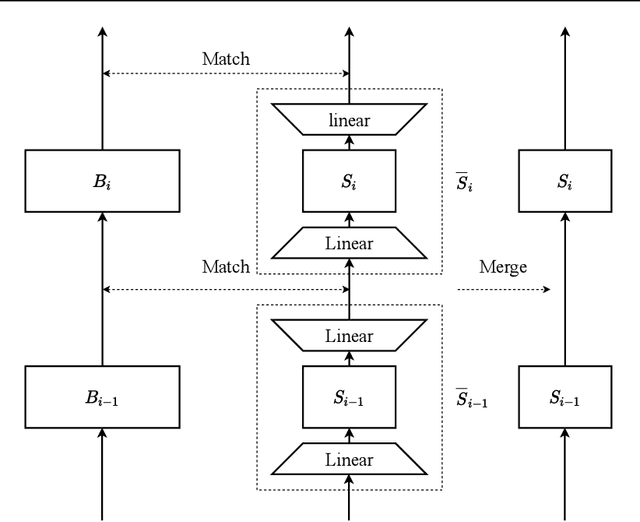
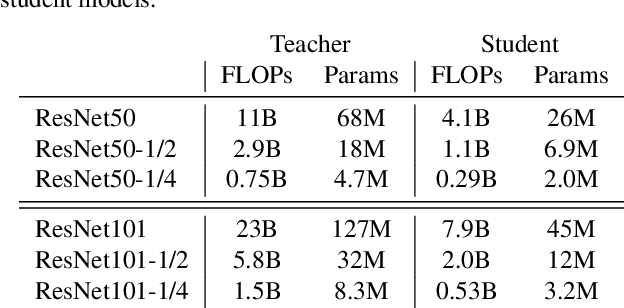
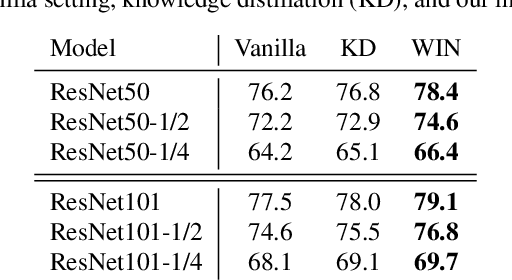
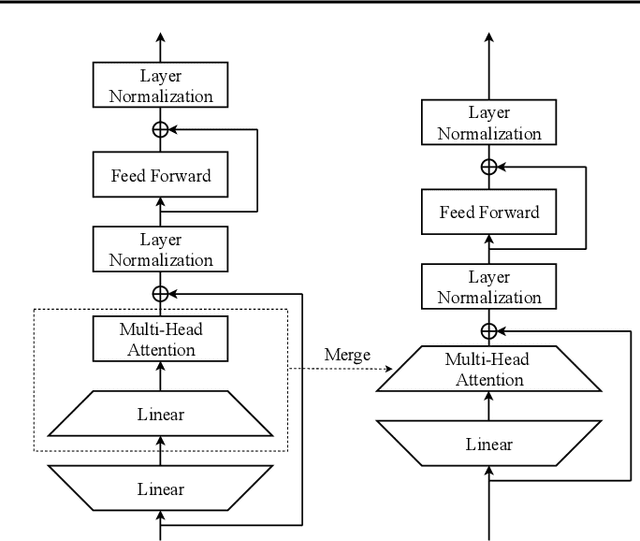
For deploying a deep learning model into production, it needs to be both accurate and compact to meet the latency and memory constraints. This usually results in a network that is deep (to ensure performance) and yet thin (to improve computational efficiency). In this paper, we propose an efficient method to train a deep thin network with a theoretic guarantee. Our method is motivated by model compression. It consists of three stages. In the first stage, we sufficiently widen the deep thin network and train it until convergence. In the second stage, we use this well-trained deep wide network to warm up (or initialize) the original deep thin network. This is achieved by letting the thin network imitate the immediate outputs of the wide network from layer to layer. In the last stage, we further fine tune this well initialized deep thin network. The theoretical guarantee is established by using mean field analysis, which shows the advantage of layerwise imitation over traditional training deep thin networks from scratch by backpropagation. We also conduct large-scale empirical experiments to validate our approach. By training with our method, ResNet50 can outperform ResNet101, and BERT_BASE can be comparable with BERT_LARGE, where both the latter models are trained via the standard training procedures as in the literature.
Smooth Adversarial Training
Jun 25, 2020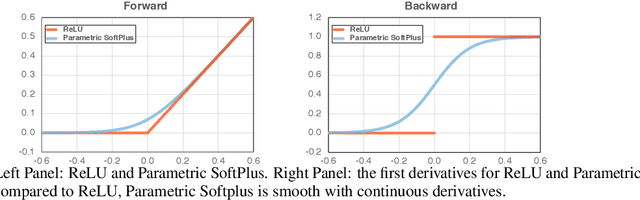

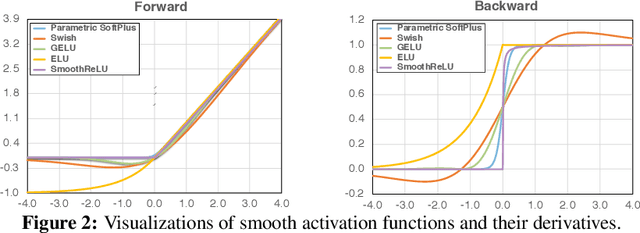
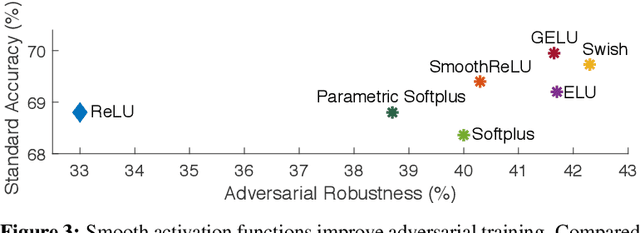
It is commonly believed that networks cannot be both accurate and robust, that gaining robustness means losing accuracy. It is also generally believed that, unless making networks larger, network architectural elements would otherwise matter little in improving adversarial robustness. Here we present evidence to challenge these common beliefs by a careful study about adversarial training. Our key observation is that the widely-used ReLU activation function significantly weakens adversarial training due to its non-smooth nature. Hence we propose smooth adversarial training (SAT), in which we replace ReLU with its smooth approximations to strengthen adversarial training. The purpose of smooth activation functions in SAT is to allow it to find harder adversarial examples and compute better gradient updates during adversarial training. Compared to standard adversarial training, SAT improves adversarial robustness for "free", i.e., no drop in accuracy and no increase in computational cost. For example, without introducing additional computations, SAT significantly enhances ResNet-50's robustness from 33.0% to 42.3%, while also improving accuracy by 0.9% on ImageNet. SAT also works well with larger networks: it helps EfficientNet-L1 to achieve 82.2% accuracy and 58.6% robustness on ImageNet, outperforming the previous state-of-the-art defense by 9.5% for accuracy and 11.6% for robustness.