 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: A Simple Training-free Approach for Recommendations using Large Language Models
Oct 21, 2024Recent progress in large language models (LLMs) offers promising new approaches for recommendation system (RecSys) tasks. While the current state-of-the-art methods rely on fine-tuning LLMs to achieve optimal results, this process is costly and introduces significant engineering complexities. Conversely, methods that bypass fine-tuning and use LLMs directly are less resource-intensive but often fail to fully capture both semantic and collaborative information, resulting in sub-optimal performance compared to their fine-tuned counterparts. In this paper, we propose a Simple Training-free Approach for Recommendation (STAR), a framework that utilizes LLMs and can be applied to various recommendation tasks without the need for fine-tuning. Our approach involves a retrieval stage that uses semantic embeddings from LLMs combined with collaborative user information to retrieve candidate items. We then apply an LLM for pairwise ranking to enhance next-item prediction. Experimental results on the Amazon Review dataset show competitive performance for next item prediction, even with our retrieval stage alone. Our full method achieves Hits@10 performance of +23.8% on Beauty, +37.5% on Toys and Games, and -1.8% on Sports and Outdoors relative to the best supervised models. This framework offers an effective alternative to traditional supervised models, highlighting the potential of LLMs in recommendation systems without extensive training or custom architectures.
Leveraging LLM Reasoning Enhances Personalized Recommender Systems
Jul 22, 2024



Recent advancements have showcased the potential of Large Language Models (LLMs) in executing reasoning tasks, particularly facilitated by Chain-of-Thought (CoT) prompting. While tasks like arithmetic reasoning involve clear, definitive answers and logical chains of thought, the application of LLM reasoning in recommendation systems (RecSys) presents a distinct challenge. RecSys tasks revolve around subjectivity and personalized preferences, an under-explored domain in utilizing LLMs' reasoning capabilities. Our study explores several aspects to better understand reasoning for RecSys and demonstrate how task quality improves by utilizing LLM reasoning in both zero-shot and finetuning settings. Additionally, we propose RecSAVER (Recommender Systems Automatic Verification and Evaluation of Reasoning) to automatically assess the quality of LLM reasoning responses without the requirement of curated gold references or human raters. We show that our framework aligns with real human judgment on the coherence and faithfulness of reasoning responses. Overall, our work shows that incorporating reasoning into RecSys can improve personalized tasks, paving the way for further advancements in recommender system methodologies.
PyGlove: Symbolic Programming for Automated Machine Learning
Jan 21, 2021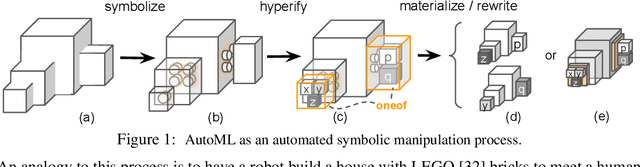
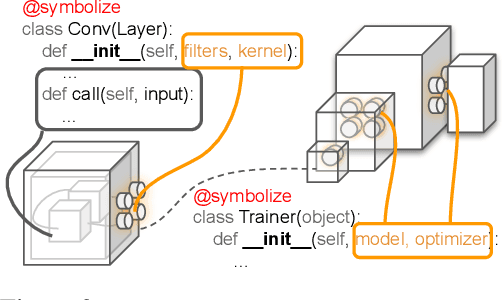
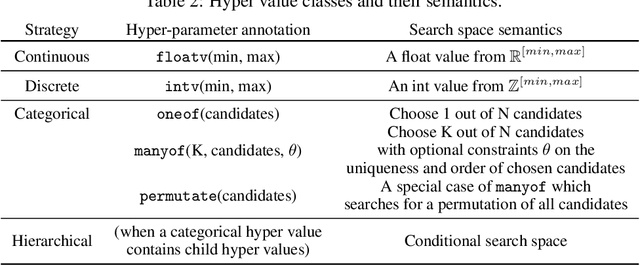

Neural networks are sensitive to hyper-parameter and architecture choices. Automated Machine Learning (AutoML) is a promising paradigm for automating these choices. Current ML software libraries, however, are quite limited in handling the dynamic interactions among the components of AutoML. For example, efficientNAS algorithms, such as ENAS and DARTS, typically require an implementation coupling between the search space and search algorithm, the two key components in AutoML. Furthermore, implementing a complex search flow, such as searching architectures within a loop of searching hardware configurations, is difficult. To summarize, changing the search space, search algorithm, or search flow in current ML libraries usually requires a significant change in the program logic. In this paper, we introduce a new way of programming AutoML based on symbolic programming. Under this paradigm, ML programs are mutable, thus can be manipulated easily by another program. As a result, AutoML can be reformulated as an automated process of symbolic manipulation. With this formulation, we decouple the triangle of the search algorithm, the search space and the child program. This decoupling makes it easy to change the search space and search algorithm (without and with weight sharing), as well as to add search capabilities to existing code and implement complex search flows. We then introduce PyGlove, a new Python library that implements this paradigm. Through case studies on ImageNet and NAS-Bench-101, we show that with PyGlove users can easily convert a static program into a search space, quickly iterate on the search spaces and search algorithms, and craft complex search flows to achieve better results.
A Weakly Supervised Approach for Estimating Spatial Density Functions from High-Resolution Satellite Imagery
Oct 22, 2018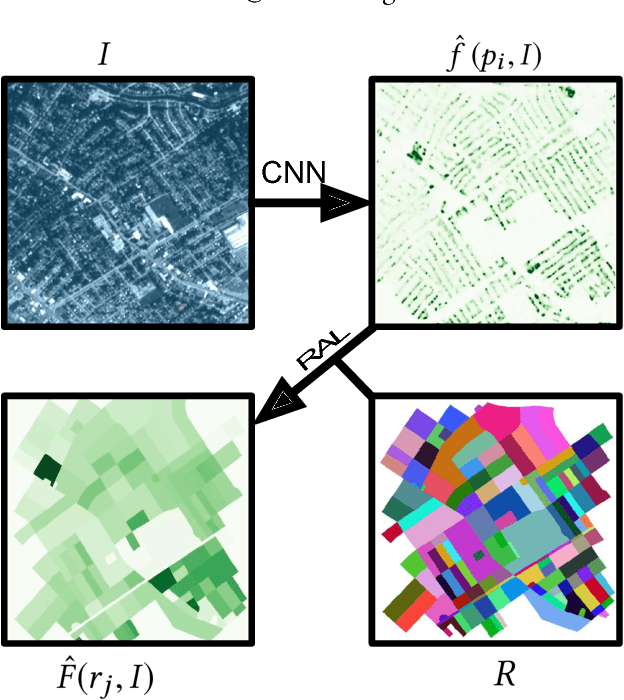
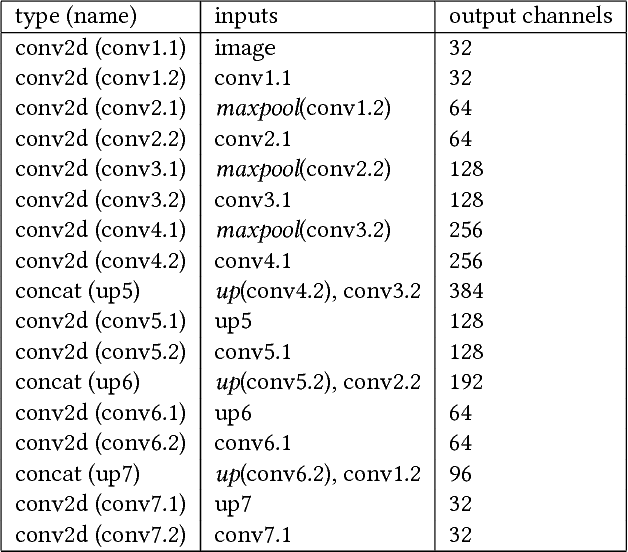

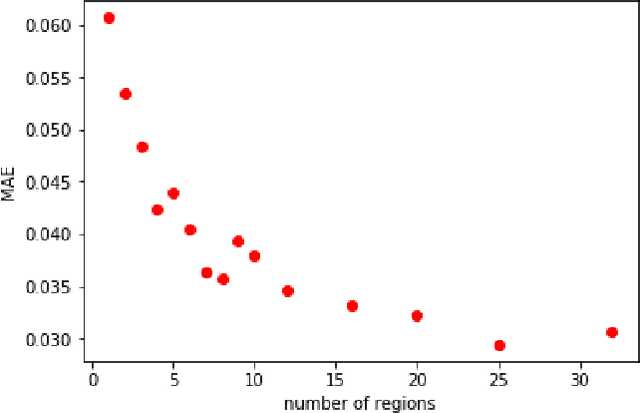
We propose a neural network component, the regional aggregation layer, that makes it possible to train a pixel-level density estimator using only coarse-grained density aggregates, which reflect the number of objects in an image region. Our approach is simple to use and does not require domain-specific assumptions about the nature of the density function. We evaluate our approach on several synthetic datasets. In addition, we use this approach to learn to estimate high-resolution population and housing density from satellite imagery. In all cases, we find that our approach results in better density estimates than a commonly used baseline. We also show how our housing density estimator can be used to classify buildings as residential or non-residential.
* 10 pages, 8 figures. ACM SIGSPATIAL 2018, Seattle, USA