 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Forward Propagation for Memorized Batch Normalization
Oct 10, 2020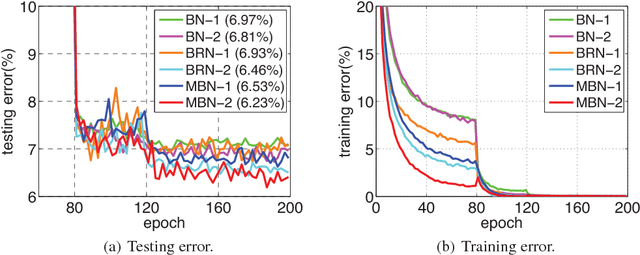

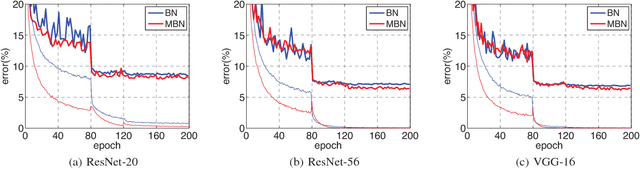

Batch Normalization (BN) has been a standard component in designing deep neural networks (DNNs). Although the standard BN can significantly accelerate the training of DNNs and improve the generalization performance, it has several underlying limitations which may hamper the performance in both training and inference. In the training stage, BN relies on estimating the mean and variance of data using a single minibatch. Consequently, BN can be unstable when the batch size is very small or the data is poorly sampled. In the inference stage, BN often uses the so called moving mean and moving variance instead of batch statistics, i.e., the training and inference rules in BN are not consistent. Regarding these issues, we propose a memorized batch normalization (MBN), which considers multiple recent batches to obtain more accurate and robust statistics. Note that after the SGD update for each batch, the model parameters will change, and the features will change accordingly, leading to the Distribution Shift before and after the update for the considered batch. To alleviate this issue, we present a simple Double-Forward scheme in MBN which can further improve the performance. Compared to related methods, the proposed MBN exhibits consistent behaviors in both training and inference. Empirical results show that the MBN based models trained with the Double-Forward scheme greatly reduce the sensitivity of data and significantly improve the generalization performance.
A Self-Supervised Gait Encoding Approach with Locality-Awareness for 3D Skeleton Based Person Re-Identification
Sep 05, 2020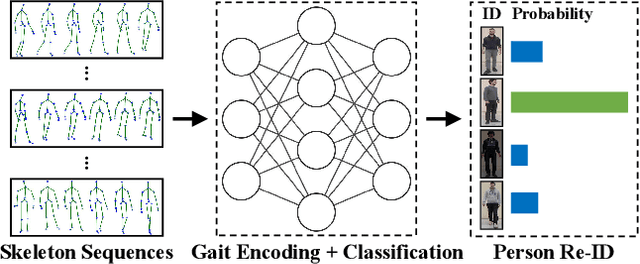
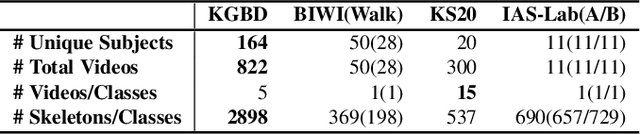
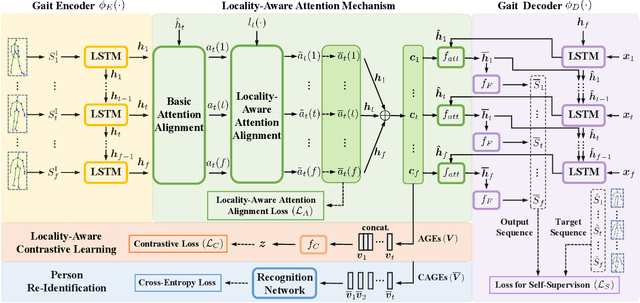
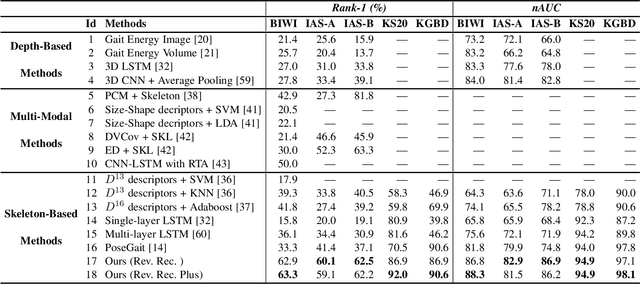
Person re-identification (Re-ID) via gait features within 3D skeleton sequences is a newly-emerging topic with several advantages. Existing solutions either rely on hand-crafted descriptors or supervised gait representation learning. This paper proposes a self-supervised gait encoding approach that can leverage unlabeled skeleton data to learn gait representations for person Re-ID. Specifically, we first create self-supervision by learning to reconstruct unlabeled skeleton sequences reversely, which involves richer high-level semantics to obtain better gait representations. Other pretext tasks are also explored to further improve self-supervised learning. Second, inspired by the fact that motion's continuity endows adjacent skeletons in one skeleton sequence and temporally consecutive skeleton sequences with higher correlations (referred as locality in 3D skeleton data), we propose a locality-aware attention mechanism and a locality-aware contrastive learning scheme, which aim to preserve locality-awareness on intra-sequence level and inter-sequence level respectively during self-supervised learning. Last, with context vectors learned by our locality-aware attention mechanism and contrastive learning scheme, a novel feature named Constrastive Attention-based Gait Encodings (CAGEs) is designed to represent gait effectively. Empirical evaluations show that our approach significantly outperforms skeleton-based counterparts by 15-40% Rank-1 accuracy, and it even achieves superior performance to numerous multi-modal methods with extra RGB or depth information. Our codes are available at https://github.com/Kali-Hac/Locality-Awareness-SGE.
Self-Supervised Gait Encoding with Locality-Aware Attention for Person Re-Identification
Aug 21, 2020
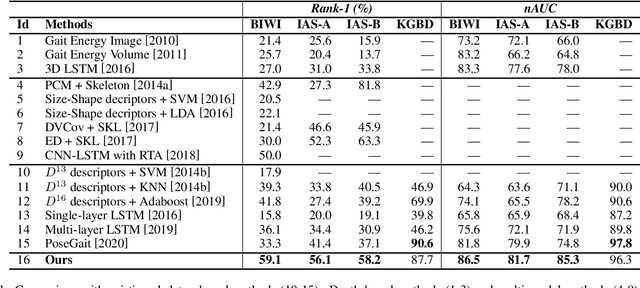
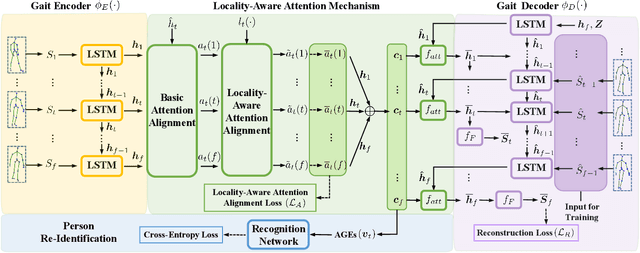

Gait-based person re-identification (Re-ID) is valuable for safety-critical applications, and using only 3D skeleton data to extract discriminative gait features for person Re-ID is an emerging open topic. Existing methods either adopt hand-crafted features or learn gait features by traditional supervised learning paradigms. Unlike previous methods, we for the first time propose a generic gait encoding approach that can utilize unlabeled skeleton data to learn gait representations in a self-supervised manner. Specifically, we first propose to introduce self-supervision by learning to reconstruct input skeleton sequences in reverse order, which facilitates learning richer high-level semantics and better gait representations. Second, inspired by the fact that motion's continuity endows temporally adjacent skeletons with higher correlations ("locality"), we propose a locality-aware attention mechanism that encourages learning larger attention weights for temporally adjacent skeletons when reconstructing current skeleton, so as to learn locality when encoding gait. Finally, we propose Attention-based Gait Encodings (AGEs), which are built using context vectors learned by locality-aware attention, as final gait representations. AGEs are directly utilized to realize effective person Re-ID. Our approach typically improves existing skeleton-based methods by 10-20% Rank-1 accuracy, and it achieves comparable or even superior performance to multi-modal methods with extra RGB or depth information. Our codes are available at https://github.com/Kali-Hac/SGE-LA.
* Accepted at IJCAI 2020 Main Track. Sole copyright holder is IJCAI. Codes are available at https://github.com/Kali-Hac/SGE-LA
SkeletonNet: A Topology-Preserving Solution for Learning Mesh Reconstruction of Object Surfaces from RGB Images
Aug 13, 2020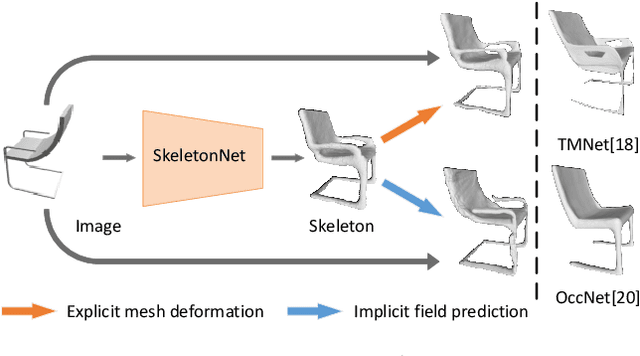
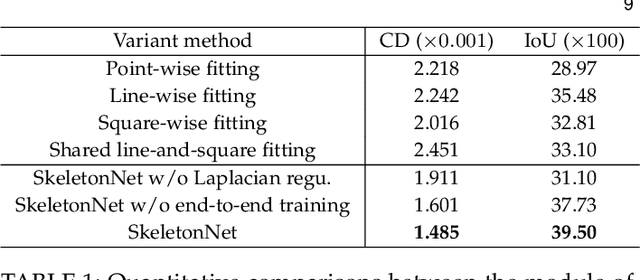
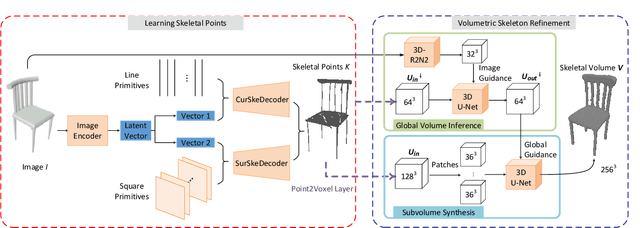

This paper focuses on the challenging task of learning 3D object surface reconstructions from RGB images. Existingmethods achieve varying degrees of success by using different surface representations. However, they all have their own drawbacks,and cannot properly reconstruct the surface shapes of complex topologies, arguably due to a lack of constraints on the topologicalstructures in their learning frameworks. To this end, we propose to learn and use the topology-preserved, skeletal shape representationto assist the downstream task of object surface reconstruction from RGB images. Technically, we propose the novelSkeletonNetdesign that learns a volumetric representation of a skeleton via a bridged learning of a skeletal point set, where we use paralleldecoders each responsible for the learning of points on 1D skeletal curves and 2D skeletal sheets, as well as an efficient module ofglobally guided subvolume synthesis for a refined, high-resolution skeletal volume; we present a differentiablePoint2Voxellayer tomake SkeletonNet end-to-end and trainable. With the learned skeletal volumes, we propose two models, the Skeleton-Based GraphConvolutional Neural Network (SkeGCNN) and the Skeleton-Regularized Deep Implicit Surface Network (SkeDISN), which respectivelybuild upon and improve over the existing frameworks of explicit mesh deformation and implicit field learning for the downstream surfacereconstruction task. We conduct thorough experiments that verify the efficacy of our proposed SkeletonNet. SkeGCNN and SkeDISNoutperform existing methods as well, and they have their own merits when measured by different metrics. Additional results ingeneralized task settings further demonstrate the usefulness of our proposed methods. We have made both our implementation codeand the ShapeNet-Skeleton dataset publicly available at ble at https://github.com/tangjiapeng/SkeletonNet.
Location-aware Graph Convolutional Networks for Video Question Answering
Aug 07, 2020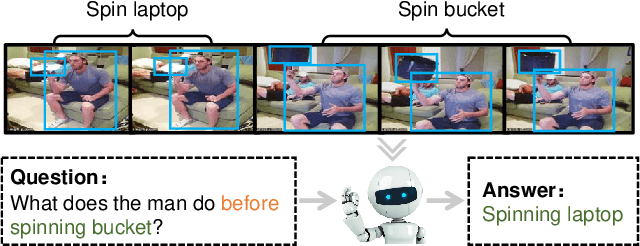

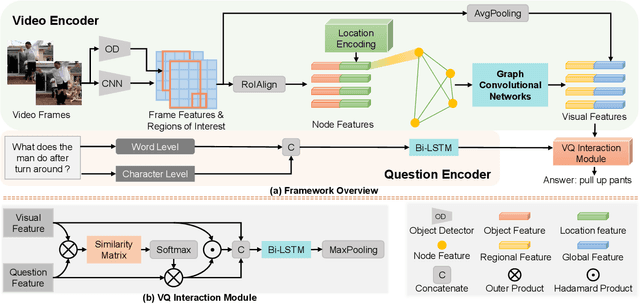
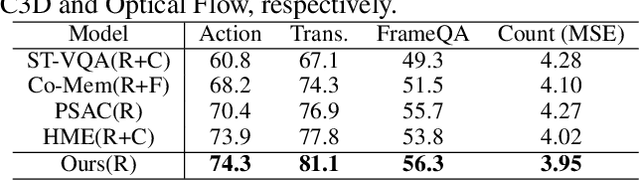
We addressed the challenging task of video question answering, which requires machines to answer questions about videos in a natural language form. Previous state-of-the-art methods attempt to apply spatio-temporal attention mechanism on video frame features without explicitly modeling the location and relations among object interaction occurred in videos. However, the relations between object interaction and their location information are very critical for both action recognition and question reasoning. In this work, we propose to represent the contents in the video as a location-aware graph by incorporating the location information of an object into the graph construction. Here, each node is associated with an object represented by its appearance and location features. Based on the constructed graph, we propose to use graph convolution to infer both the category and temporal locations of an action. As the graph is built on objects, our method is able to focus on the foreground action contents for better video question answering. Lastly, we leverage an attention mechanism to combine the output of graph convolution and encoded question features for final answer reasoning. Extensive experiments demonstrate the effectiveness of the proposed methods. Specifically, our method significantly outperforms state-of-the-art methods on TGIF-QA, Youtube2Text-QA, and MSVD-QA datasets. Code and pre-trained models are publicly available at: https://github.com/SunDoge/L-GCN
AQD: Towards Accurate Quantized Object Detection
Aug 03, 2020
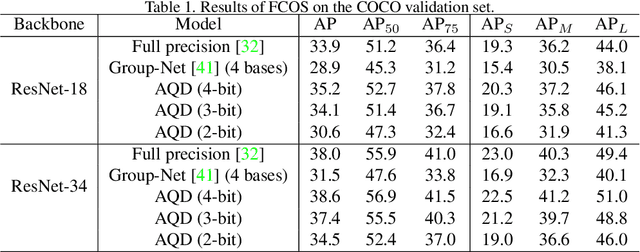
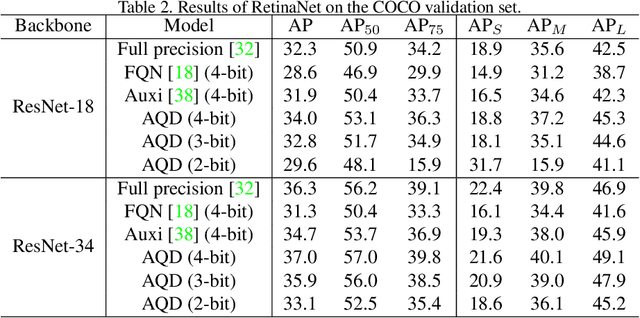

Network quantization aims to lower the bitwidth of weights and activations and hence reduce the model size and accelerate the inference of deep networks. Even though existing quantization methods have achieved promising performance on image classification, applying aggressively low bitwidth quantization on object detection while preserving the performance is still a challenge. In this paper, we demonstrate that the poor performance of the quantized network on object detection comes from the inaccurate batch statistics of batch normalization. To solve this, we propose an accurate quantized object detection (AQD) method. Specifically, we propose to employ multi-level batch normalization (multi-level BN) to estimate the batch statistics of each detection head separately. We further propose a learned interval quantization method to improve how the quantizer itself is configured. To evaluate the performance of the proposed methods, we apply AQD to two one-stage detectors (i.e., RetinaNet and FCOS). Experimental results on COCO show that our methods achieve near-lossless performance compared with the full-precision model by using extremely low bitwidth regimes such as 3-bit. In particular, we even outperform the full-precision counterpart by a large margin with a 4-bit detector, which is of great practical value.
Improving Generative Adversarial Networks with Local Coordinate Coding
Jul 28, 2020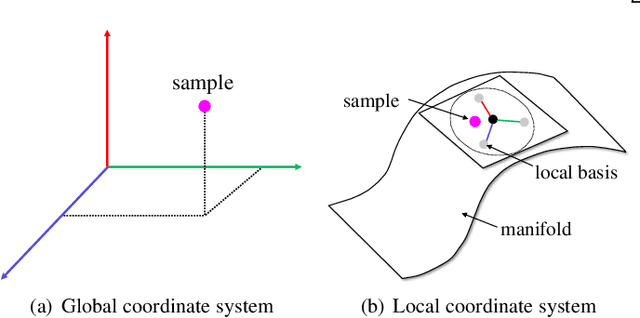
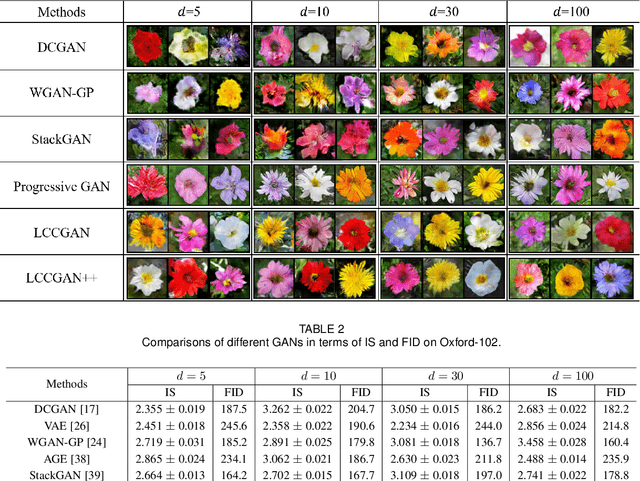
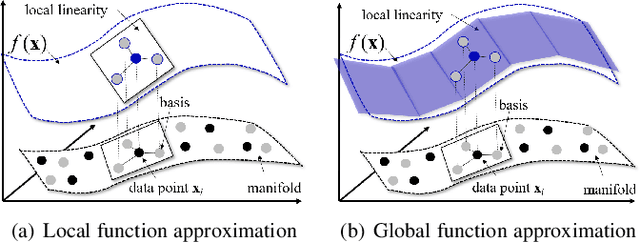
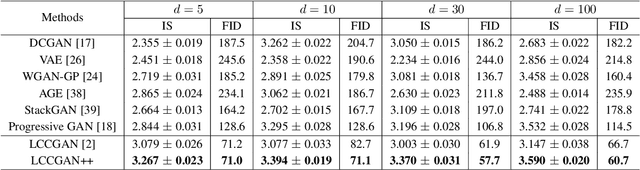
Generative adversarial networks (GANs) have shown remarkable success in generating realistic data from some predefined prior distribution (e.g., Gaussian noises). However, such prior distribution is often independent of real data and thus may lose semantic information (e.g., geometric structure or content in images) of data. In practice, the semantic information might be represented by some latent distribution learned from data. However, such latent distribution may incur difficulties in data sampling for GANs. In this paper, rather than sampling from the predefined prior distribution, we propose an LCCGAN model with local coordinate coding (LCC) to improve the performance of generating data. First, we propose an LCC sampling method in LCCGAN to sample meaningful points from the latent manifold. With the LCC sampling method, we can exploit the local information on the latent manifold and thus produce new data with promising quality. Second, we propose an improved version, namely LCCGAN++, by introducing a higher-order term in the generator approximation. This term is able to achieve better approximation and thus further improve the performance. More critically, we derive the generalization bound for both LCCGAN and LCCGAN++ and prove that a low-dimensional input is sufficient to achieve good generalization performance. Extensive experiments on four benchmark datasets demonstrate the superiority of the proposed method over existing GANs.
Length-Controllable Image Captioning
Jul 19, 2020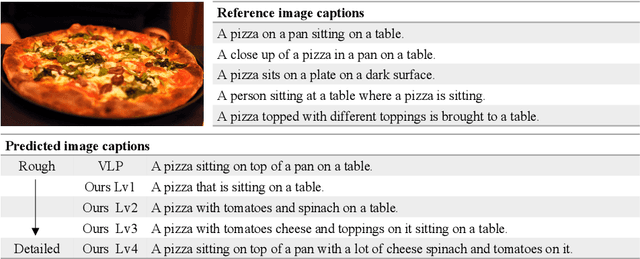
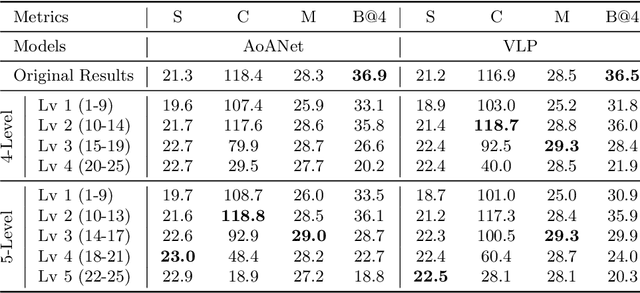
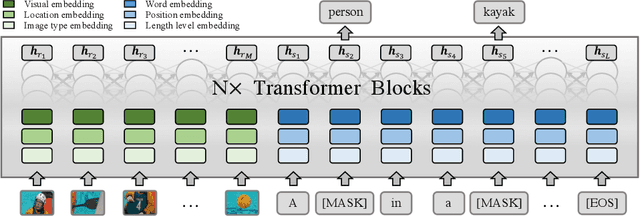

The last decade has witnessed remarkable progress in the image captioning task; however, most existing methods cannot control their captions, \emph{e.g.}, choosing to describe the image either roughly or in detail. In this paper, we propose to use a simple length level embedding to endow them with this ability. Moreover, due to their autoregressive nature, the computational complexity of existing models increases linearly as the length of the generated captions grows. Thus, we further devise a non-autoregressive image captioning approach that can generate captions in a length-irrelevant complexity. We verify the merit of the proposed length level embedding on three models: two state-of-the-art (SOTA) autoregressive models with different types of decoder, as well as our proposed non-autoregressive model, to show its generalization ability. In the experiments, our length-controllable image captioning models not only achieve SOTA performance on the challenging MS COCO dataset but also generate length-controllable and diverse image captions. Specifically, our non-autoregressive model outperforms the autoregressive baselines in terms of controllability and diversity, and also significantly improves the decoding efficiency for long captions. Our code and models are released at \textcolor{magenta}{\texttt{https://github.com/bearcatt/LaBERT}}.
Retinal Image Segmentation with a Structure-Texture Demixing Network
Jul 15, 2020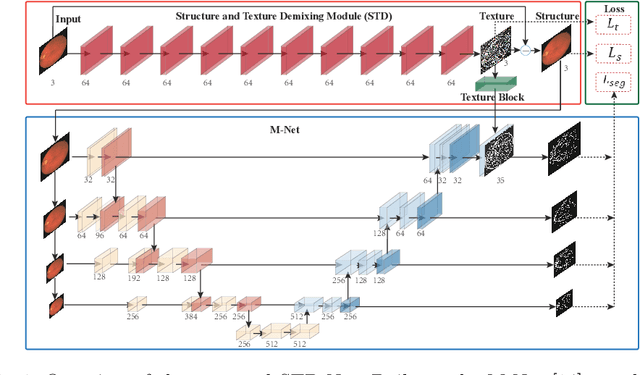
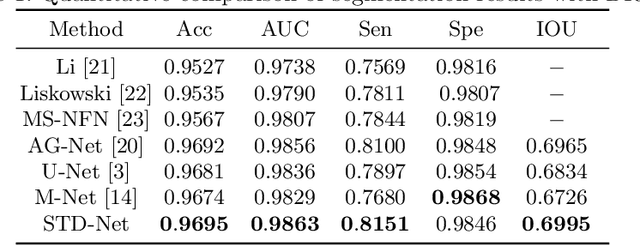
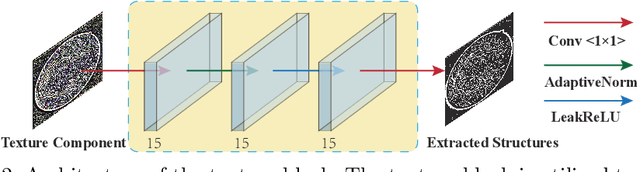
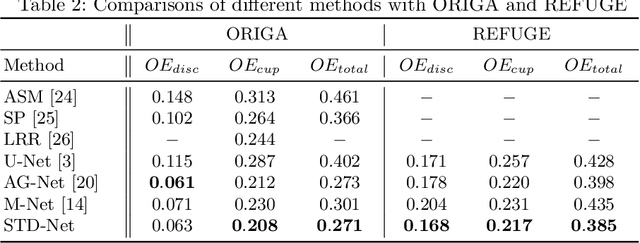
Retinal image segmentation plays an important role in automatic disease diagnosis. This task is very challenging because the complex structure and texture information are mixed in a retinal image, and distinguishing the information is difficult. Existing methods handle texture and structure jointly, which may lead biased models toward recognizing textures and thus results in inferior segmentation performance. To address it, we propose a segmentation strategy that seeks to separate structure and texture components and significantly improve the performance. To this end, we design a structure-texture demixing network (STD-Net) that can process structures and textures differently and better. Extensive experiments on two retinal image segmentation tasks (i.e., blood vessel segmentation, optic disc and cup segmentation) demonstrate the effectiveness of the proposed method.
Generating Visually Aligned Sound from Videos
Jul 14, 2020
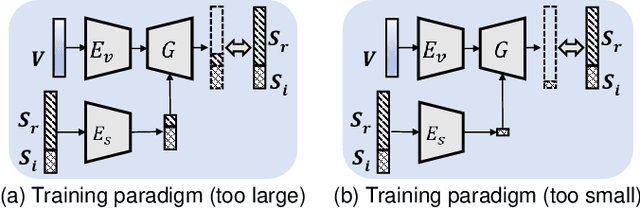
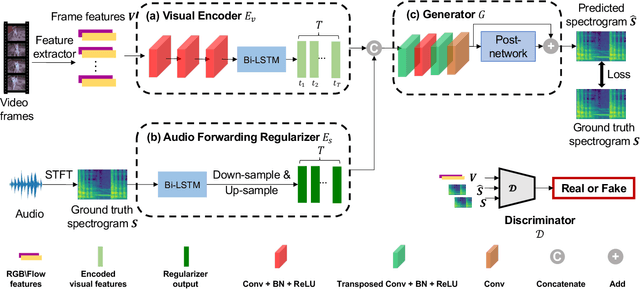
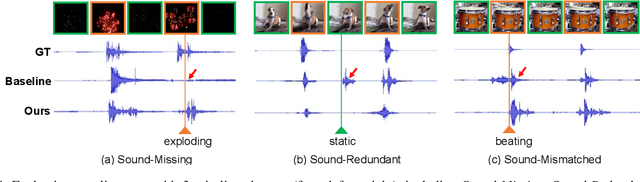
We focus on the task of generating sound from natural videos, and the sound should be both temporally and content-wise aligned with visual signals. This task is extremely challenging because some sounds generated \emph{outside} a camera can not be inferred from video content. The model may be forced to learn an incorrect mapping between visual content and these irrelevant sounds. To address this challenge, we propose a framework named REGNET. In this framework, we first extract appearance and motion features from video frames to better distinguish the object that emits sound from complex background information. We then introduce an innovative audio forwarding regularizer that directly considers the real sound as input and outputs bottlenecked sound features. Using both visual and bottlenecked sound features for sound prediction during training provides stronger supervision for the sound prediction. The audio forwarding regularizer can control the irrelevant sound component and thus prevent the model from learning an incorrect mapping between video frames and sound emitted by the object that is out of the screen. During testing, the audio forwarding regularizer is removed to ensure that REGNET can produce purely aligned sound only from visual features. Extensive evaluations based on Amazon Mechanical Turk demonstrate that our method significantly improves both temporal and content-wise alignment. Remarkably, our generated sound can fool the human with a 68.12% success rate. Code and pre-trained models are publicly available at https://github.com/PeihaoChen/regnet