 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrimination-aware Network Pruning for Deep Model Compression
Paper and Code
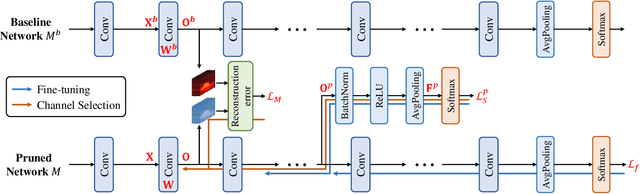
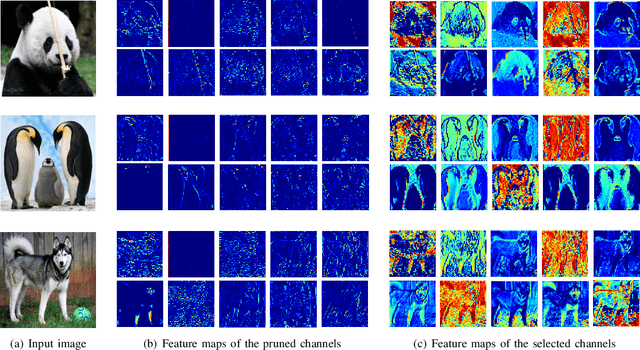
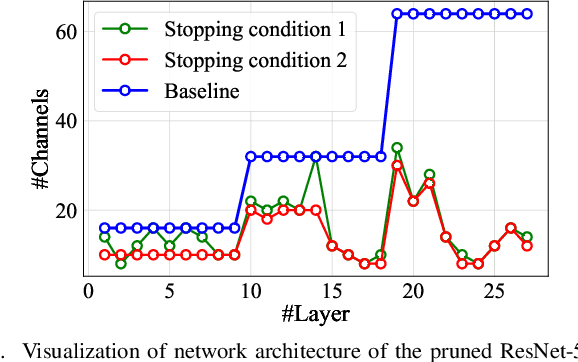
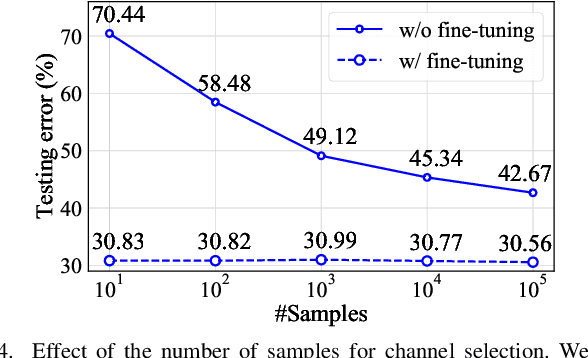
We study network pruning which aims to remove redundant channels/kernels and hence speed up the inference of deep networks. Existing pruning methods either train from scratch with sparsity constraints or minimize the reconstruction error between the feature maps of the pre-trained models and the compressed ones. Both strategies suffer from some limitations: the former kind is computationally expensive and difficult to converge, while the latter kind optimizes the reconstruction error but ignores the discriminative power of channels. In this paper, we propose a simple-yet-effective method called discrimination-aware channel pruning (DCP) to choose the channels that actually contribute to the discriminative power. Note that a channel often consists of a set of kernels. Besides the redundancy in channels, some kernels in a channel may also be redundant and fail to contribute to the discriminative power of the network, resulting in kernel level redundancy. To solve this, we propose a discrimination-aware kernel pruning (DKP) method to further compress deep networks by removing redundant kernels. To prevent DCP/DKP from selecting redundant channels/kernels, we propose a new adaptive stopping condition, which helps to automatically determine the number of selected channels/kernels and often results in more compact models with better performance. Extensive experiments on both image classification and face recognition demonstrate the effectiveness of our methods. For example, on ILSVRC-12, the resultant ResNet-50 model with 30% reduction of channels even outperforms the baseline model by 0.36% in terms of Top-1 accuracy. The pruned MobileNetV1 and MobileNetV2 achieve 1.93x and 1.42x inference acceleration on a mobile device, respectively, with negligible performance degradation. The source code and the pre-trained models are available at https://github.com/SCUT-AILab/DCP.