 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasaCtrl: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing
Apr 17, 2023



Despite the success in large-scale text-to-image generation and text-conditioned image editing, existing methods still struggle to produce consistent generation and editing results. For example, generation approaches usually fail to synthesize multiple images of the same objects/characters but with different views or poses. Meanwhile, existing editing methods either fail to achieve effective complex non-rigid editing while maintaining the overall textures and identity, or require time-consuming fine-tuning to capture the image-specific appearance. In this paper, we develop MasaCtrl, a tuning-free method to achieve consistent image generation and complex non-rigid image editing simultaneously. Specifically, MasaCtrl converts existing self-attention in diffusion models into mutual self-attention, so that it can query correlated local contents and textures from source images for consistency. To further alleviate the query confusion between foreground and background, we propose a mask-guided mutual self-attention strategy, where the mask can be easily extracted from the cross-attention maps. Extensive experiments show that the proposed MasaCtrl can produce impressive results in both consistent image generation and complex non-rigid real image editing.
OSRT: Omnidirectional Image Super-Resolution with Distortion-aware Transformer
Feb 09, 2023Omnidirectional images (ODIs) have obtained lots of research interest for immersive experiences. Although ODIs require extremely high resolution to capture details of the entire scene, the resolutions of most ODIs are insufficient. Previous methods attempt to solve this issue by image super-resolution (SR) on equirectangular projection (ERP) images. However, they omit geometric properties of ERP in the degradation process, and their models can hardly generalize to real ERP images. In this paper, we propose Fisheye downsampling, which mimics the real-world imaging process and synthesizes more realistic low-resolution samples. Then we design a distortion-aware Transformer (OSRT) to modulate ERP distortions continuously and self-adaptively. Without a cumbersome process, OSRT outperforms previous methods by about 0.2dB on PSNR. Moreover, we propose a convenient data augmentation strategy, which synthesizes pseudo ERP images from plain images. This simple strategy can alleviate the over-fitting problem of large networks and significantly boost the performance of ODISR. Extensive experiments have demonstrated the state-of-the-art performance of our OSRT. Codes and models will be available at https://github.com/Fanghua-Yu/OSRT.
Blur Interpolation Transformer for Real-World Motion from Blur
Nov 21, 2022This paper studies the challenging problem of recovering motion from blur, also known as joint deblurring and interpolation or blur temporal super-resolution. The remaining challenges are twofold: 1) the current methods still leave considerable room for improvement in terms of visual quality even on the synthetic dataset, and 2) poor generalization to real-world data. To this end, we propose a blur interpolation transformer (BiT) to effectively unravel the underlying temporal correlation encoded in blur. Based on multi-scale residual Swin transformer blocks, we introduce dual-end temporal supervision and temporally symmetric ensembling strategies to generate effective features for time-varying motion rendering. In addition, we design a hybrid camera system to collect the first real-world dataset of one-to-many blur-sharp video pairs. Experimental results show that BiT has a significant gain over the state-of-the-art methods on the public dataset Adobe240. Besides, the proposed real-world dataset effectively helps the model generalize well to real blurry scenarios.
Towards Real-World Video Deblurring by Exploring Blur Formation Process
Aug 28, 2022

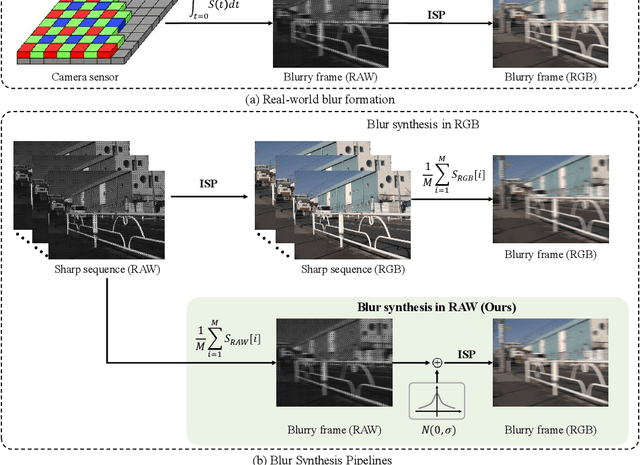
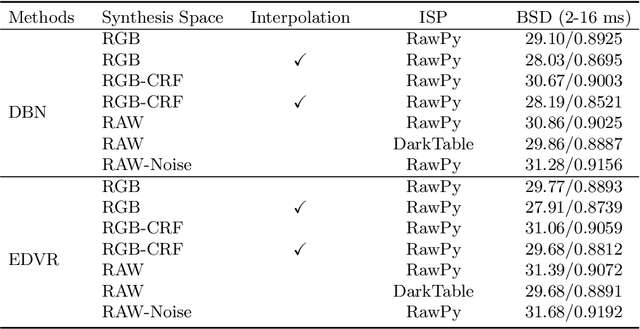
This paper aims at exploring how to synthesize close-to-real blurs that existing video deblurring models trained on them can generalize well to real-world blurry videos. In recent years, deep learning-based approaches have achieved promising success on video deblurring task. However, the models trained on existing synthetic datasets still suffer from generalization problems over real-world blurry scenarios with undesired artifacts. The factors accounting for the failure remain unknown. Therefore, we revisit the classical blur synthesis pipeline and figure out the possible reasons, including shooting parameters, blur formation space, and image signal processor~(ISP). To analyze the effects of these potential factors, we first collect an ultra-high frame-rate (940 FPS) RAW video dataset as the data basis to synthesize various kinds of blurs. Then we propose a novel realistic blur synthesis pipeline termed as RAW-Blur by leveraging blur formation cues. Through numerous experiments, we demonstrate that synthesizing blurs in the RAW space and adopting the same ISP as the real-world testing data can effectively eliminate the negative effects of synthetic data. Furthermore, the shooting parameters of the synthesized blurry video, e.g., exposure time and frame-rate play significant roles in improving the performance of deblurring models. Impressively, the models trained on the blurry data synthesized by the proposed RAW-Blur pipeline can obtain more than 5dB PSNR gain against those trained on the existing synthetic blur datasets. We believe the novel realistic synthesis pipeline and the corresponding RAW video dataset can help the community to easily construct customized blur datasets to improve real-world video deblurring performance largely, instead of laboriously collecting real data pairs.
Learning Adaptive Warping for Real-World Rolling Shutter Correction
Apr 29, 2022
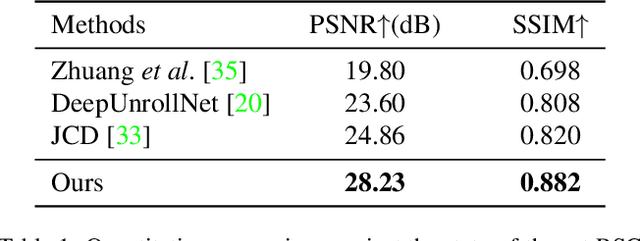
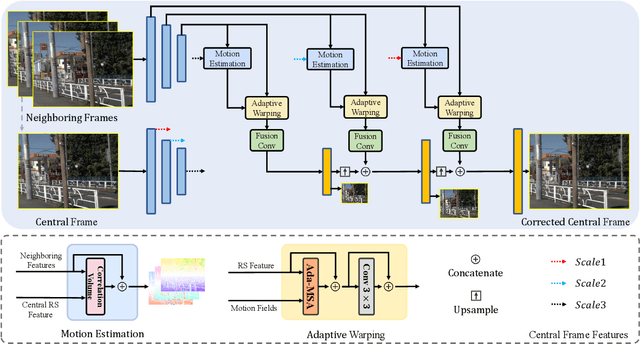
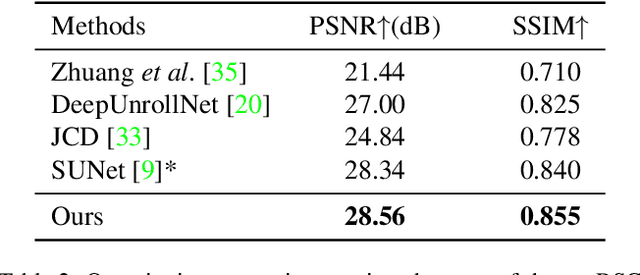
This paper proposes the first real-world rolling shutter (RS) correction dataset, BS-RSC, and a corresponding model to correct the RS frames in a distorted video. Mobile devices in the consumer market with CMOS-based sensors for video capture often result in rolling shutter effects when relative movements occur during the video acquisition process, calling for RS effect removal techniques. However, current state-of-the-art RS correction methods often fail to remove RS effects in real scenarios since the motions are various and hard to model. To address this issue, we propose a real-world RS correction dataset BS-RSC. Real distorted videos with corresponding ground truth are recorded simultaneously via a well-designed beam-splitter-based acquisition system. BS-RSC contains various motions of both camera and objects in dynamic scenes. Further, an RS correction model with adaptive warping is proposed. Our model can warp the learned RS features into global shutter counterparts adaptively with predicted multiple displacement fields. These warped features are aggregated and then reconstructed into high-quality global shutter frames in a coarse-to-fine strategy. Experimental results demonstrate the effectiveness of the proposed method, and our dataset can improve the model's ability to remove the RS effects in the real world.
MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment
Apr 21, 2022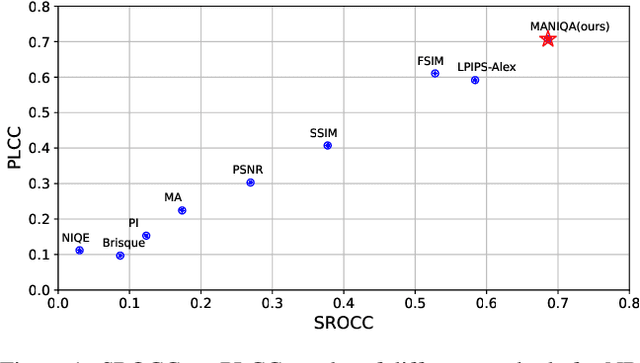
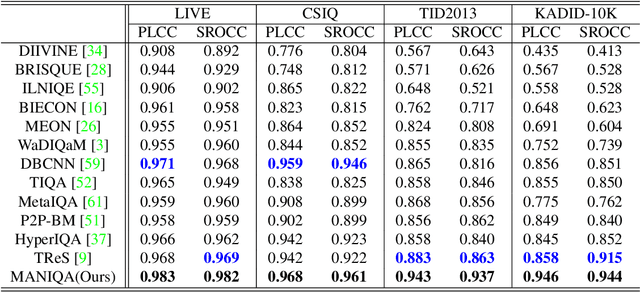
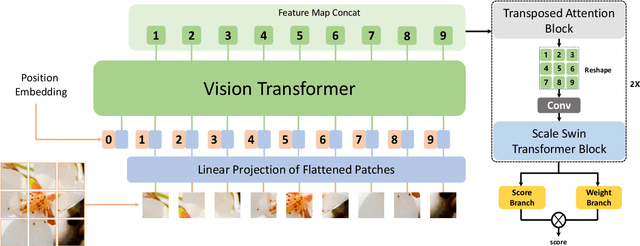
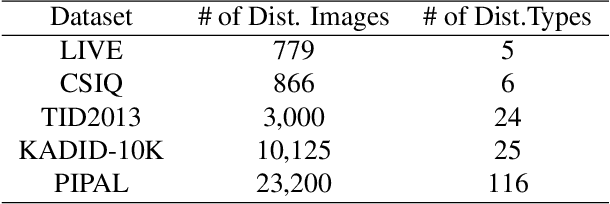
No-Reference Image Quality Assessment (NR-IQA) aims to assess the perceptual quality of images in accordance with human subjective perception. Unfortunately, existing NR-IQA methods are far from meeting the needs of predicting accurate quality scores on GAN-based distortion images. To this end, we propose Multi-dimension Attention Network for no-reference Image Quality Assessment (MANIQA) to improve the performance on GAN-based distortion. We firstly extract features via ViT, then to strengthen global and local interactions, we propose the Transposed Attention Block (TAB) and the Scale Swin Transformer Block (SSTB). These two modules apply attention mechanisms across the channel and spatial dimension, respectively. In this multi-dimensional manner, the modules cooperatively increase the interaction among different regions of images globally and locally. Finally, a dual branch structure for patch-weighted quality prediction is applied to predict the final score depending on the weight of each patch's score. Experimental results demonstrate that MANIQA outperforms state-of-the-art methods on four standard datasets (LIVE, TID2013, CSIQ, and KADID-10K) by a large margin. Besides, our method ranked first place in the final testing phase of the NTIRE 2022 Perceptual Image Quality Assessment Challenge Track 2: No-Reference. Codes and models are available at https://github.com/IIGROUP/MANIQA.
VDTR: Video Deblurring with Transformer
Apr 17, 2022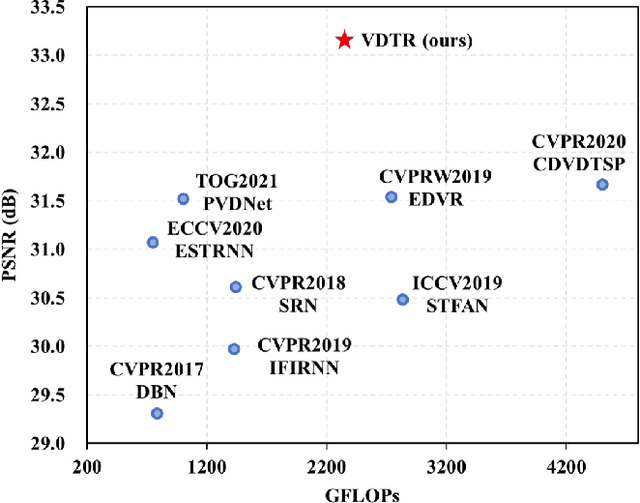


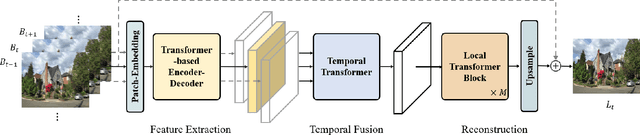
Video deblurring is still an unsolved problem due to the challenging spatio-temporal modeling process. While existing convolutional neural network-based methods show a limited capacity for effective spatial and temporal modeling for video deblurring. This paper presents VDTR, an effective Transformer-based model that makes the first attempt to adapt Transformer for video deblurring. VDTR exploits the superior long-range and relation modeling capabilities of Transformer for both spatial and temporal modeling. However, it is challenging to design an appropriate Transformer-based model for video deblurring due to the complicated non-uniform blurs, misalignment across multiple frames and the high computational costs for high-resolution spatial modeling. To address these problems, VDTR advocates performing attention within non-overlapping windows and exploiting the hierarchical structure for long-range dependencies modeling. For frame-level spatial modeling, we propose an encoder-decoder Transformer that utilizes multi-scale features for deblurring. For multi-frame temporal modeling, we adapt Transformer to fuse multiple spatial features efficiently. Compared with CNN-based methods, the proposed method achieves highly competitive results on both synthetic and real-world video deblurring benchmarks, including DVD, GOPRO, REDS and BSD. We hope such a Transformer-based architecture can serve as a powerful alternative baseline for video deblurring and other video restoration tasks. The source code will be available at \url{https://github.com/ljzycmd/VDTR}.
StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Mar 17, 2022
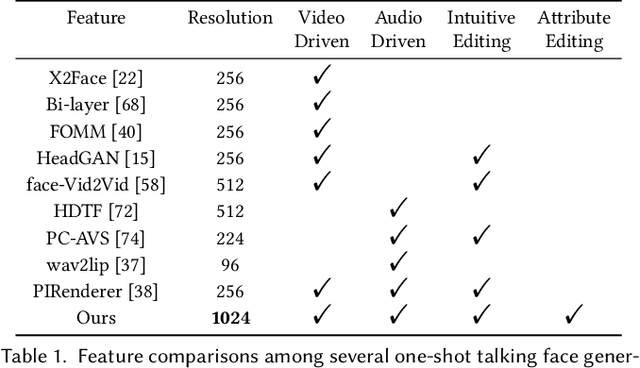

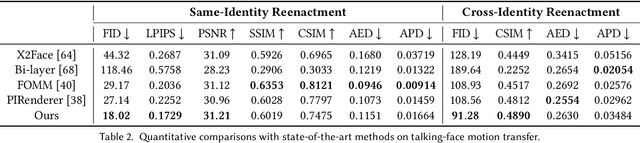
One-shot talking face generation aims at synthesizing a high-quality talking face video from an arbitrary portrait image, driven by a video or an audio segment. One challenging quality factor is the resolution of the output video: higher resolution conveys more details. In this work, we investigate the latent feature space of a pre-trained StyleGAN and discover some excellent spatial transformation properties. Upon the observation, we explore the possibility of using a pre-trained StyleGAN to break through the resolution limit of training datasets. We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing. Our framework elevates the resolution of the synthesized talking face to 1024*1024 for the first time, even though the training dataset has a lower resolution. We design a video-based motion generation module and an audio-based one, which can be plugged into the framework either individually or jointly to drive the video generation. The predicted motion is used to transform the latent features of StyleGAN for visual animation. To compensate for the transformation distortion, we propose a calibration network as well as a domain loss to refine the features. Moreover, our framework allows two types of facial editing, i.e., global editing via GAN inversion and intuitive editing based on 3D morphable models. Comprehensive experiments show superior video quality, flexible controllability, and editability over state-of-the-art methods.
Bringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 15, 2022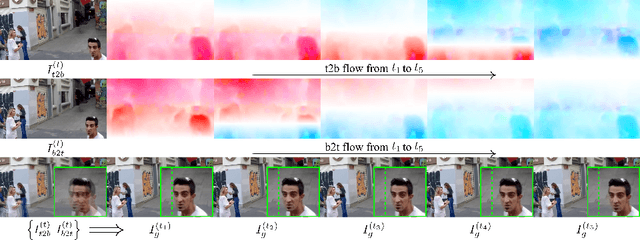

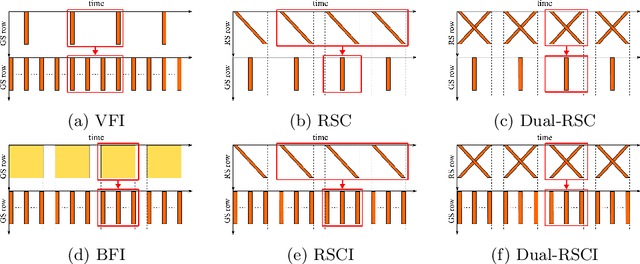
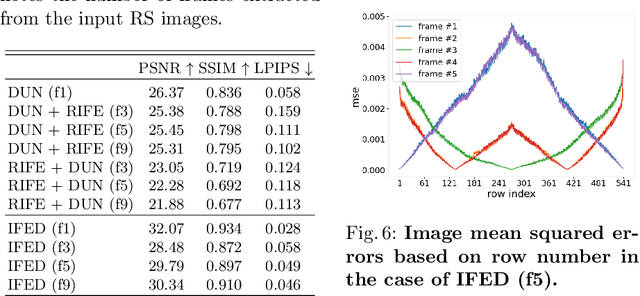
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021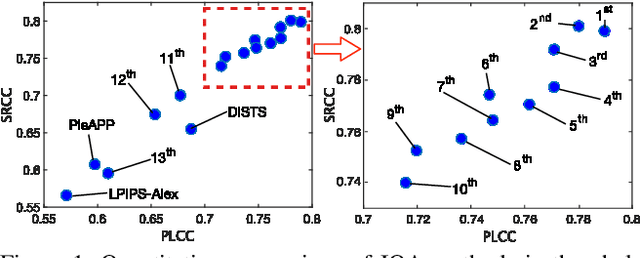
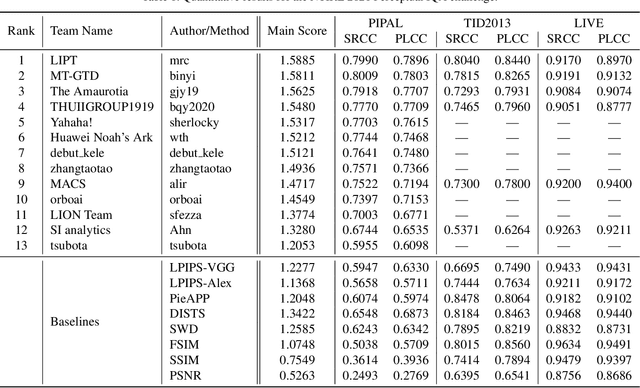

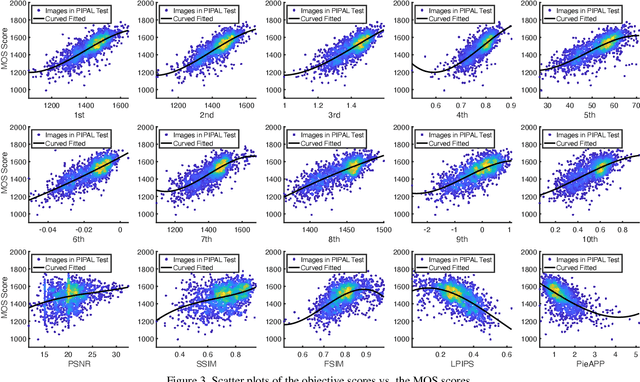
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.