 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sequential Matching Framework for Multi-turn Response Selection in Retrieval-based Chatbots
Oct 31, 2017We study the problem of response selection for multi-turn conversation in retrieval-based chatbots. The task requires matching a response candidate with a conversation context, whose challenges include how to recognize important parts of the context, and how to model the relationships among utterances in the context. Existing matching methods may lose important information in contexts as we can interpret them with a unified framework in which contexts are transformed to fixed-length vectors without any interaction with responses before matching. The analysis motivates us to propose a new matching framework that can sufficiently carry the important information in contexts to matching and model the relationships among utterances at the same time. The new framework, which we call a sequential matching framework (SMF), lets each utterance in a context interacts with a response candidate at the first step and transforms the pair to a matching vector. The matching vectors are then accumulated following the order of the utterances in the context with a recurrent neural network (RNN) which models the relationships among the utterances. The context-response matching is finally calculated with the hidden states of the RNN. Under SMF, we propose a sequential convolutional network and sequential attention network and conduct experiments on two public data sets to test their performance. Experimental results show that both models can significantly outperform the state-of-the-art matching methods. We also show that the models are interpretable with visualizations that provide us insights on how they capture and leverage the important information in contexts for matching.
Question Answering and Question Generation as Dual Tasks
Aug 04, 2017
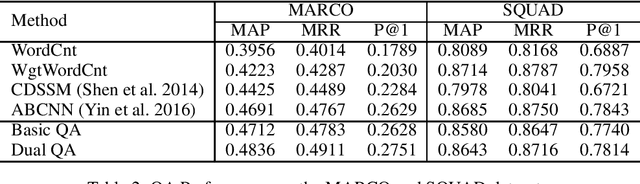

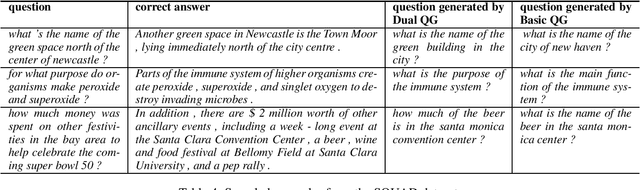
We study the problem of joint question answering (QA) and question generation (QG) in this paper. Our intuition is that QA and QG have intrinsic connections and these two tasks could improve each other. On one side, the QA model judges whether the generated question of a QG model is relevant to the answer. On the other side, the QG model provides the probability of generating a question given the answer, which is a useful evidence that in turn facilitates QA. In this paper we regard QA and QG as dual tasks. We propose a training framework that trains the models of QA and QG simultaneously, and explicitly leverages their probabilistic correlation to guide the training process of both models. We implement a QG model based on sequence-to-sequence learning, and a QA model based on recurrent neural network. As all the components of the QA and QG models are differentiable, all the parameters involved in these two models could be conventionally learned with back propagation. We conduct experiments on three datasets. Empirical results show that our training framework improves both QA and QG tasks. The improved QA model performs comparably with strong baseline approaches on all three datasets.
Content-Based Table Retrieval for Web Queries
Jun 08, 2017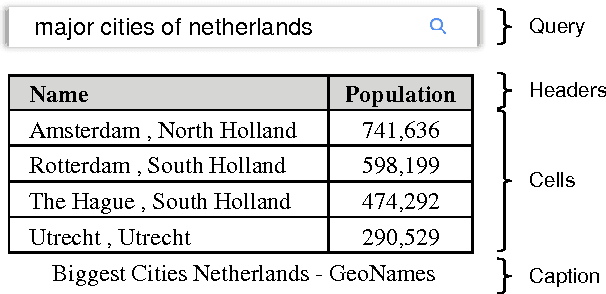
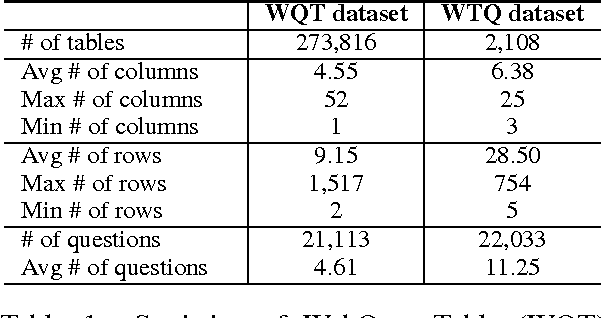
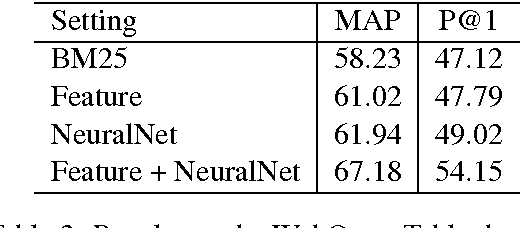
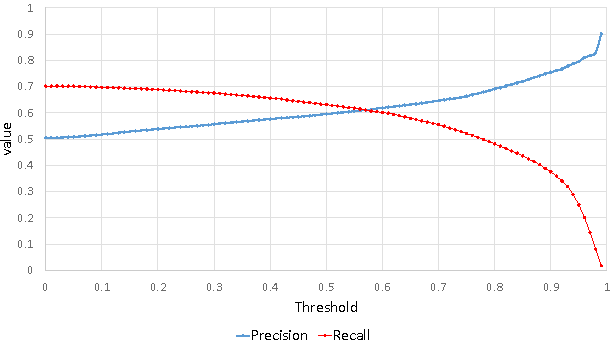
Understanding the connections between unstructured text and semi-structured table is an important yet neglected problem in natural language processing. In this work, we focus on content-based table retrieval. Given a query, the task is to find the most relevant table from a collection of tables. Further progress towards improving this area requires powerful models of semantic matching and richer training and evaluation resources. To remedy this, we present a ranking based approach, and implement both carefully designed features and neural network architectures to measure the relevance between a query and the content of a table. Furthermore, we release an open-domain dataset that includes 21,113 web queries for 273,816 tables. We conduct comprehensive experiments on both real world and synthetic datasets. Results verify the effectiveness of our approach and present the challenges for this task.
Entity Linking for Queries by Searching Wikipedia Sentences
May 18, 2017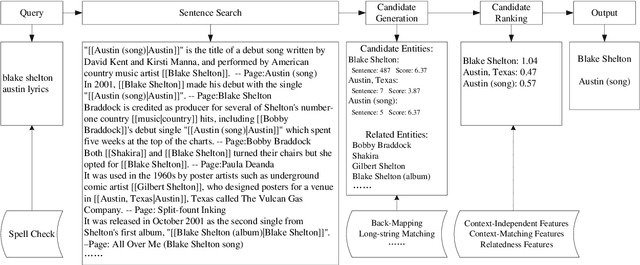
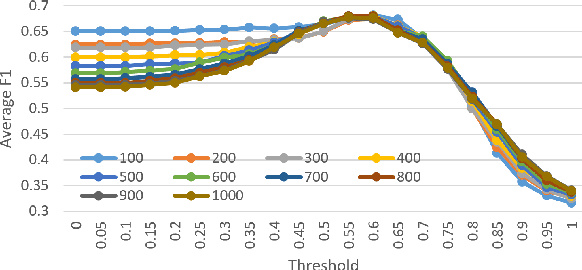

We present a simple yet effective approach for linking entities in queries. The key idea is to search sentences similar to a query from Wikipedia articles and directly use the human-annotated entities in the similar sentences as candidate entities for the query. Then, we employ a rich set of features, such as link-probability, context-matching, word embeddings, and relatedness among candidate entities as well as their related entities, to rank the candidates under a regression based framework. The advantages of our approach lie in two aspects, which contribute to the ranking process and final linking result. First, it can greatly reduce the number of candidate entities by filtering out irrelevant entities with the words in the query. Second, we can obtain the query sensitive prior probability in addition to the static link-probability derived from all Wikipedia articles. We conduct experiments on two benchmark datasets on entity linking for queries, namely the ERD14 dataset and the GERDAQ dataset. Experimental results show that our method outperforms state-of-the-art systems and yields 75.0% in F1 on the ERD14 dataset and 56.9% on the GERDAQ dataset.
Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-based Chatbots
May 15, 2017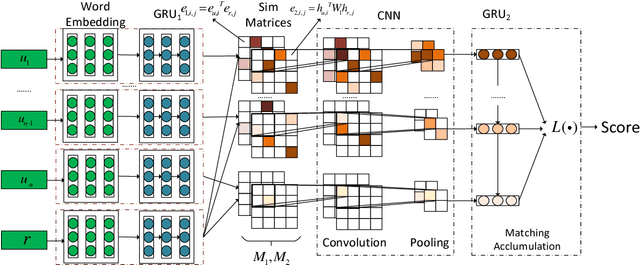
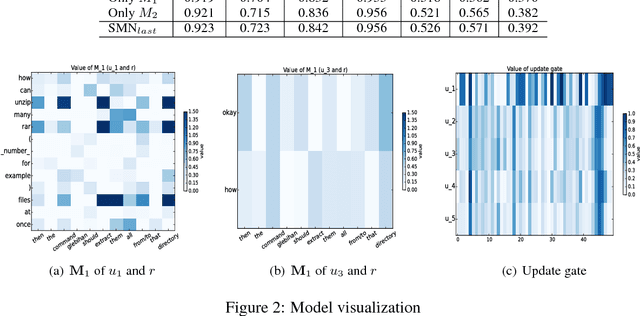
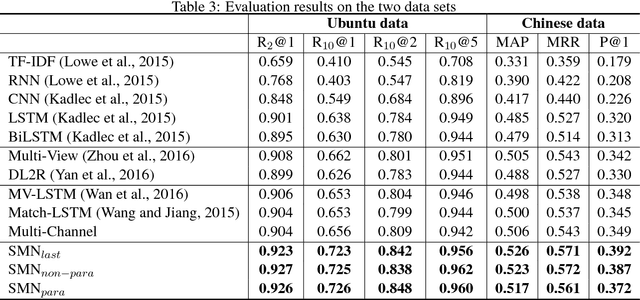
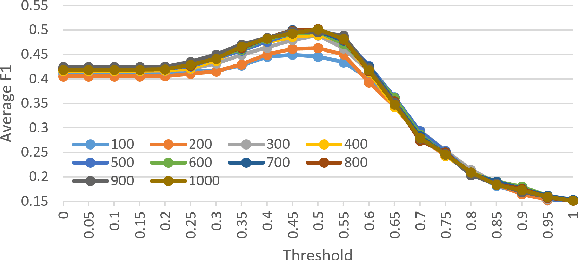
We study response selection for multi-turn conversation in retrieval-based chatbots. Existing work either concatenates utterances in context or matches a response with a highly abstract context vector finally, which may lose relationships among utterances or important contextual information. We propose a sequential matching network (SMN) to address both problems. SMN first matches a response with each utterance in the context on multiple levels of granularity, and distills important matching information from each pair as a vector with convolution and pooling operations. The vectors are then accumulated in a chronological order through a recurrent neural network (RNN) which models relationships among utterances. The final matching score is calculated with the hidden states of the RNN. An empirical study on two public data sets shows that SMN can significantly outperform state-of-the-art methods for response selection in multi-turn conversation.
Selective Encoding for Abstractive Sentence Summarization
Apr 24, 2017
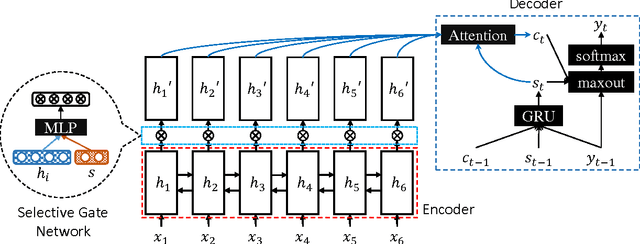
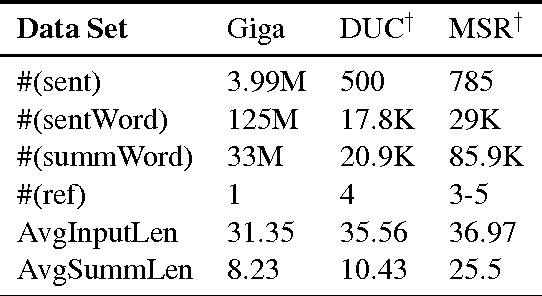
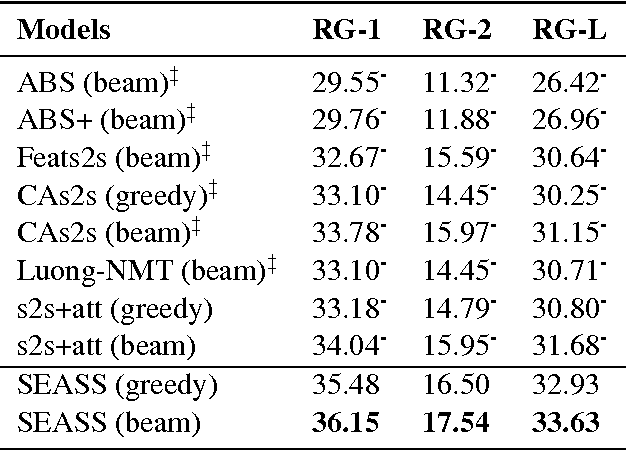
We propose a selective encoding model to extend the sequence-to-sequence framework for abstractive sentence summarization. It consists of a sentence encoder, a selective gate network, and an attention equipped decoder. The sentence encoder and decoder are built with recurrent neural networks. The selective gate network constructs a second level sentence representation by controlling the information flow from encoder to decoder. The second level representation is tailored for sentence summarization task, which leads to better performance. We evaluate our model on the English Gigaword, DUC 2004 and MSR abstractive sentence summarization datasets. The experimental results show that the proposed selective encoding model outperforms the state-of-the-art baseline models.
Neural Question Generation from Text: A Preliminary Study
Apr 18, 2017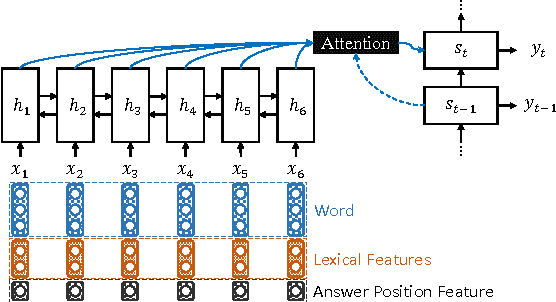
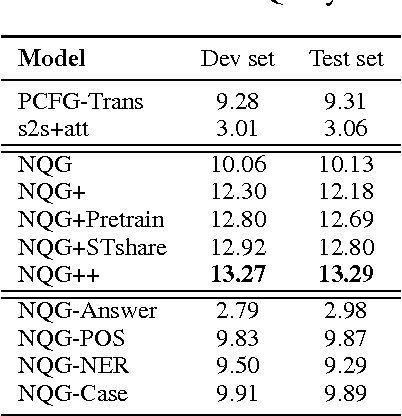
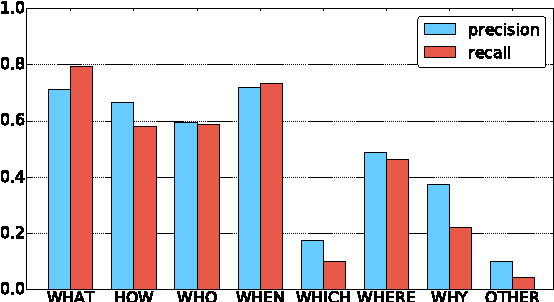

Automatic question generation aims to generate questions from a text passage where the generated questions can be answered by certain sub-spans of the given passage. Traditional methods mainly use rigid heuristic rules to transform a sentence into related questions. In this work, we propose to apply the neural encoder-decoder model to generate meaningful and diverse questions from natural language sentences. The encoder reads the input text and the answer position, to produce an answer-aware input representation, which is fed to the decoder to generate an answer focused question. We conduct a preliminary study on neural question generation from text with the SQuAD dataset, and the experiment results show that our method can produce fluent and diverse questions.
Hierarchical Recurrent Attention Network for Response Generation
Jan 25, 2017

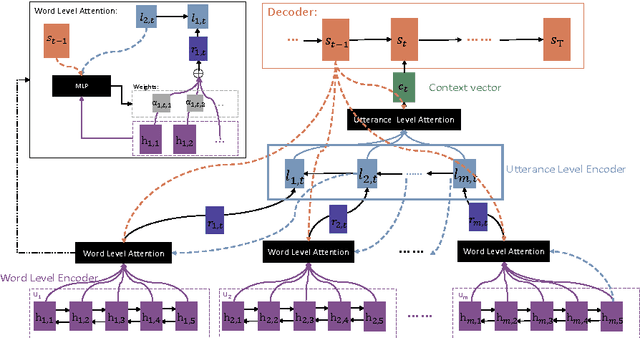
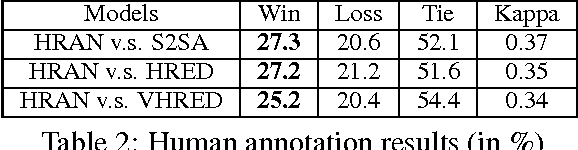
We study multi-turn response generation in chatbots where a response is generated according to a conversation context. Existing work has modeled the hierarchy of the context, but does not pay enough attention to the fact that words and utterances in the context are differentially important. As a result, they may lose important information in context and generate irrelevant responses. We propose a hierarchical recurrent attention network (HRAN) to model both aspects in a unified framework. In HRAN, a hierarchical attention mechanism attends to important parts within and among utterances with word level attention and utterance level attention respectively. With the word level attention, hidden vectors of a word level encoder are synthesized as utterance vectors and fed to an utterance level encoder to construct hidden representations of the context. The hidden vectors of the context are then processed by the utterance level attention and formed as context vectors for decoding the response. Empirical studies on both automatic evaluation and human judgment show that HRAN can significantly outperform state-of-the-art models for multi-turn response generation.
Knowledge Enhanced Hybrid Neural Network for Text Matching
Nov 15, 2016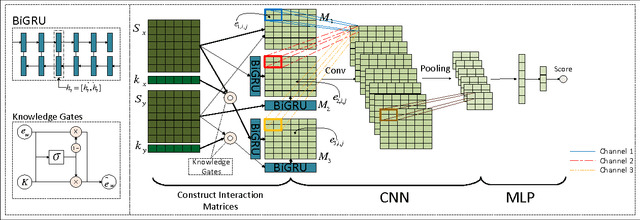
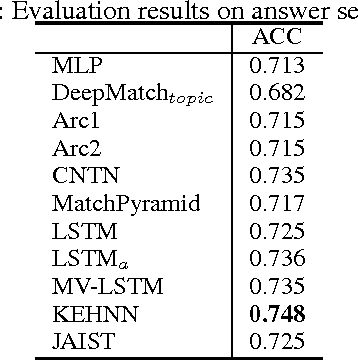
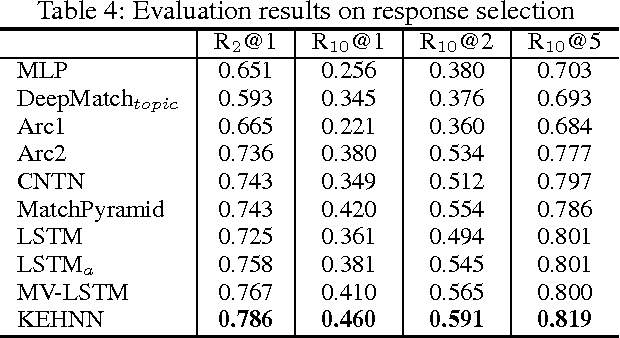
Long text brings a big challenge to semantic matching due to their complicated semantic and syntactic structures. To tackle the challenge, we consider using prior knowledge to help identify useful information and filter out noise to matching in long text. To this end, we propose a knowledge enhanced hybrid neural network (KEHNN). The model fuses prior knowledge into word representations by knowledge gates and establishes three matching channels with words, sequential structures of sentences given by Gated Recurrent Units (GRU), and knowledge enhanced representations. The three channels are processed by a convolutional neural network to generate high level features for matching, and the features are synthesized as a matching score by a multilayer perceptron. The model extends the existing methods by conducting matching on words, local structures of sentences, and global context of sentences. Evaluation results from extensive experiments on public data sets for question answering and conversation show that KEHNN can significantly outperform the-state-of-the-art matching models and particularly improve the performance on pairs with long text.
Detecting Context Dependent Messages in a Conversational Environment
Nov 03, 2016
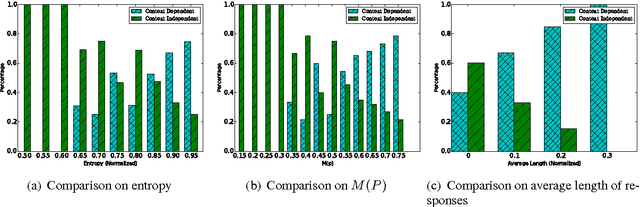

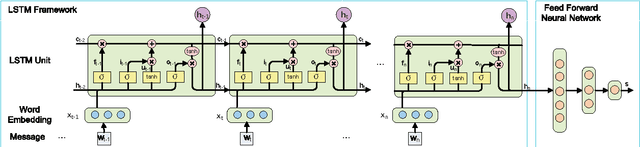
While automatic response generation for building chatbot systems has drawn a lot of attention recently, there is limited understanding on when we need to consider the linguistic context of an input text in the generation process. The task is challenging, as messages in a conversational environment are short and informal, and evidence that can indicate a message is context dependent is scarce. After a study of social conversation data crawled from the web, we observed that some characteristics estimated from the responses of messages are discriminative for identifying context dependent messages. With the characteristics as weak supervision, we propose using a Long Short Term Memory (LSTM) network to learn a classifier. Our method carries out text representation and classifier learning in a unified framework. Experimental results show that the proposed method can significantly outperform baseline methods on accuracy of classification.