 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTable-to-Text: Describing Table Region with Natural Language
May 29, 2018
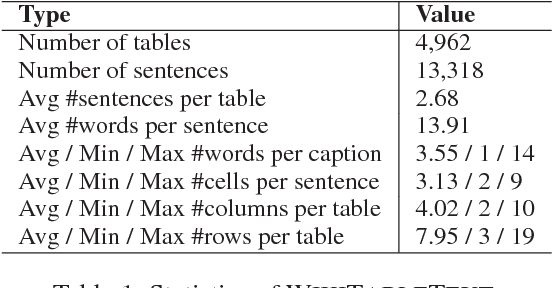
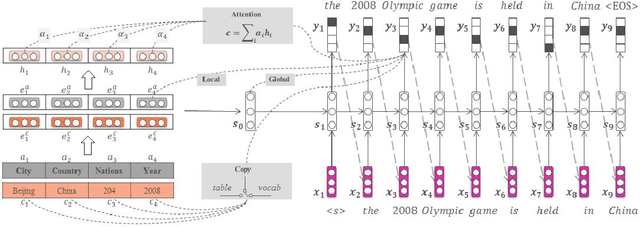

In this paper, we present a generative model to generate a natural language sentence describing a table region, e.g., a row. The model maps a row from a table to a continuous vector and then generates a natural language sentence by leveraging the semantics of a table. To deal with rare words appearing in a table, we develop a flexible copying mechanism that selectively replicates contents from the table in the output sequence. Extensive experiments demonstrate the accuracy of the model and the power of the copying mechanism. On two synthetic datasets, WIKIBIO and SIMPLEQUESTIONS, our model improves the current state-of-the-art BLEU-4 score from 34.70 to 40.26 and from 33.32 to 39.12, respectively. Furthermore, we introduce an open-domain dataset WIKITABLETEXT including 13,318 explanatory sentences for 4,962 tables. Our model achieves a BLEU-4 score of 38.23, which outperforms template based and language model based approaches.
Content-Based Table Retrieval for Web Queries
Jun 08, 2017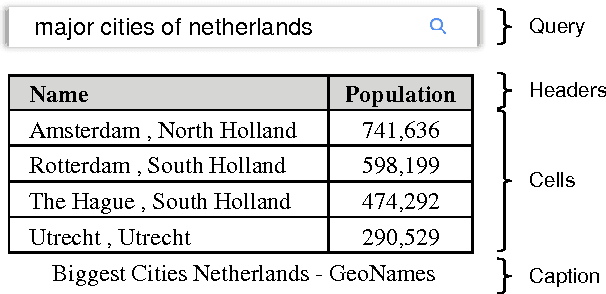
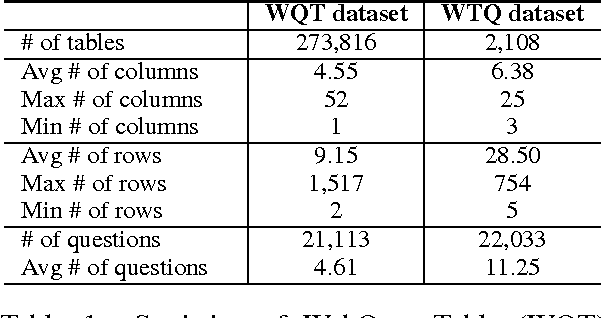
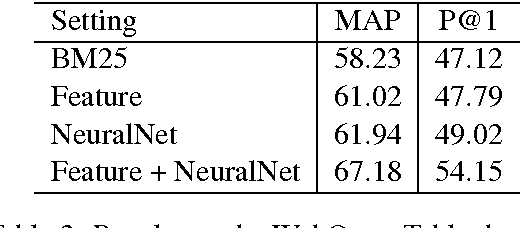
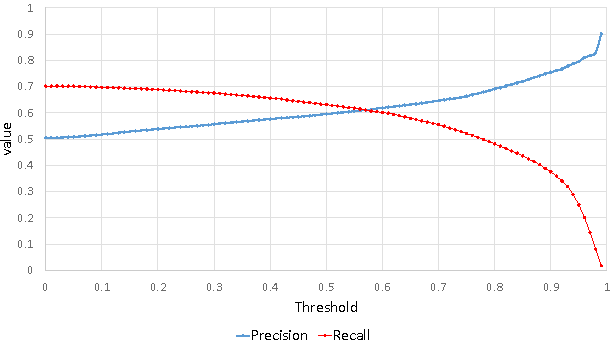
Understanding the connections between unstructured text and semi-structured table is an important yet neglected problem in natural language processing. In this work, we focus on content-based table retrieval. Given a query, the task is to find the most relevant table from a collection of tables. Further progress towards improving this area requires powerful models of semantic matching and richer training and evaluation resources. To remedy this, we present a ranking based approach, and implement both carefully designed features and neural network architectures to measure the relevance between a query and the content of a table. Furthermore, we release an open-domain dataset that includes 21,113 web queries for 273,816 tables. We conduct comprehensive experiments on both real world and synthetic datasets. Results verify the effectiveness of our approach and present the challenges for this task.