 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Cross-lingual Pre-training for Unsupervised Machine Translation
Aug 31, 2019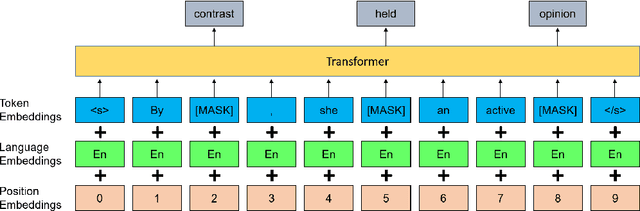
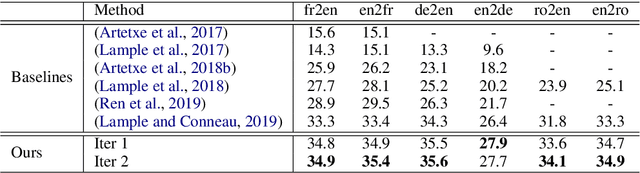
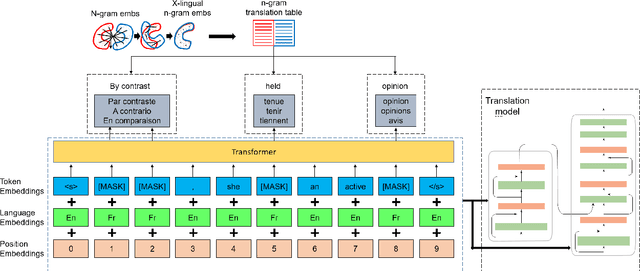
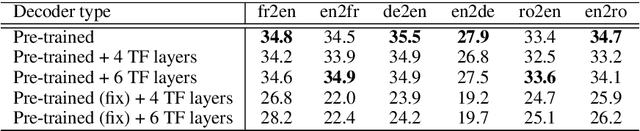
Pre-training has proven to be effective in unsupervised machine translation due to its ability to model deep context information in cross-lingual scenarios. However, the cross-lingual information obtained from shared BPE spaces is inexplicit and limited. In this paper, we propose a novel cross-lingual pre-training method for unsupervised machine translation by incorporating explicit cross-lingual training signals. Specifically, we first calculate cross-lingual n-gram embeddings and infer an n-gram translation table from them. With those n-gram translation pairs, we propose a new pre-training model called Cross-lingual Masked Language Model (CMLM), which randomly chooses source n-grams in the input text stream and predicts their translation candidates at each time step. Experiments show that our method can incorporate beneficial cross-lingual information into pre-trained models. Taking pre-trained CMLM models as the encoder and decoder, we significantly improve the performance of unsupervised machine translation.
Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training
Aug 22, 2019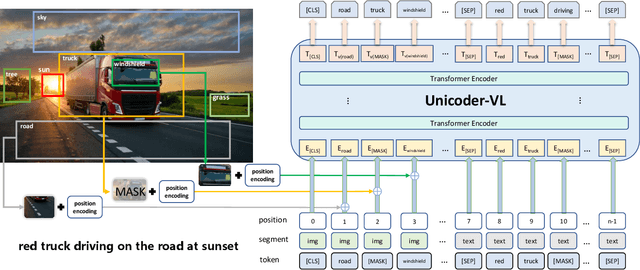
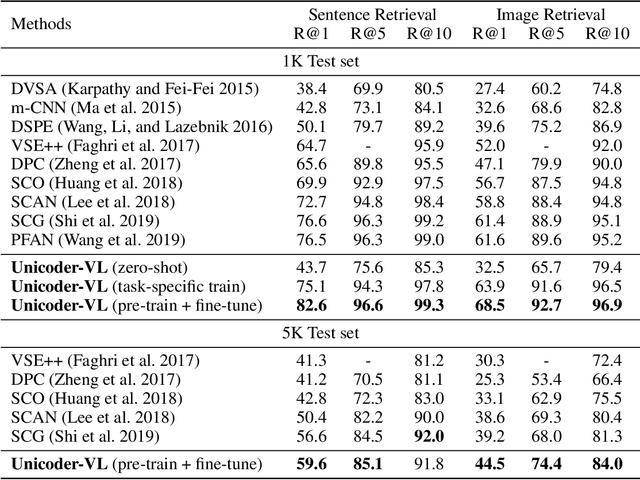
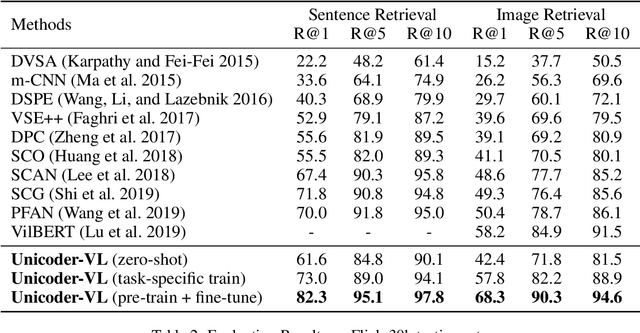
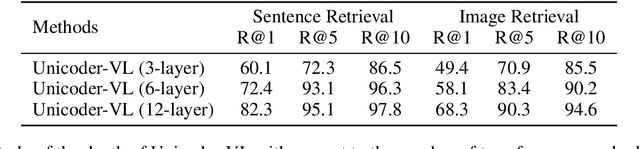
We propose Unicoder-VL, a universal encoder that aims to learn joint representations of vision and language in a pre-training manner. Borrow ideas from cross-lingual pre-trained models, such as XLM and Unicoder, both visual and linguistic contents are fed into a multi-layer transformer for the cross-modal pre-training, where three pre-trained tasks are employed, including masked language model, masked object label prediction and visual-linguistic matching. The first two tasks learn context-aware representations for input tokens based on linguistic and visual contents jointly. The last task tries to predict whether an image and a text describe each other. After pretraining on large amounts of image-caption pairs, we transfer Unicoder-VL to image-text retrieval tasks with just one additional output layer, and achieve state-of-the-art performances on both MSCOCO and Flicker30K.
A Tensorized Transformer for Language Modeling
Aug 09, 2019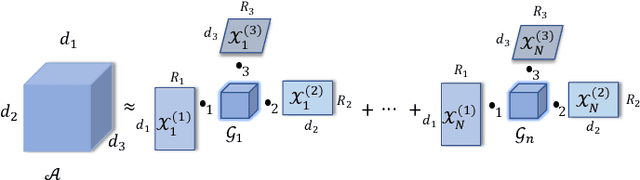
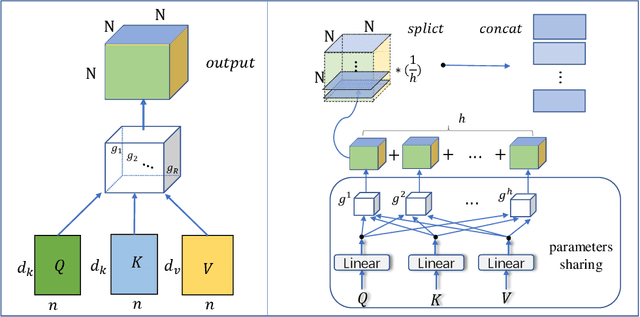
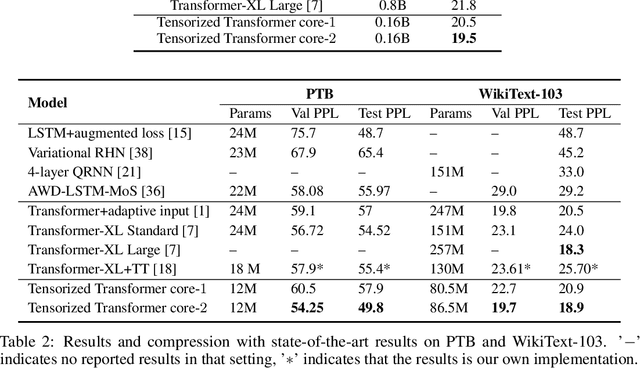

Latest development of neural models has connected the encoder and decoder through a self-attention mechanism. In particular, Transformer, which is solely based on self-attention, has led to breakthroughs in Natural Language Processing (NLP) tasks. However, the multi-head attention mechanism, as a key component of Transformer, limits the effective deployment of the model to a limited resource setting. In this paper, based on the ideas of tensor decomposition and parameters sharing, we propose a novel self-attention model (namely Multi-linear attention) with Block-Term Tensor Decomposition (BTD). We test and verify the proposed attention method on three language modeling tasks (i.e., PTB, WikiText-103 and One-billion) and a neural machine translation task (i.e., WMT-2016 English-German). Multi-linear attention can not only largely compress the model parameters but also obtain performance improvements, compared with a number of language modeling approaches, such as Transformer, Transformer-XL, and Transformer with tensor train decomposition.
Pathologist-Level Grading of Prostate Biopsies with Artificial Intelligence
Jul 02, 2019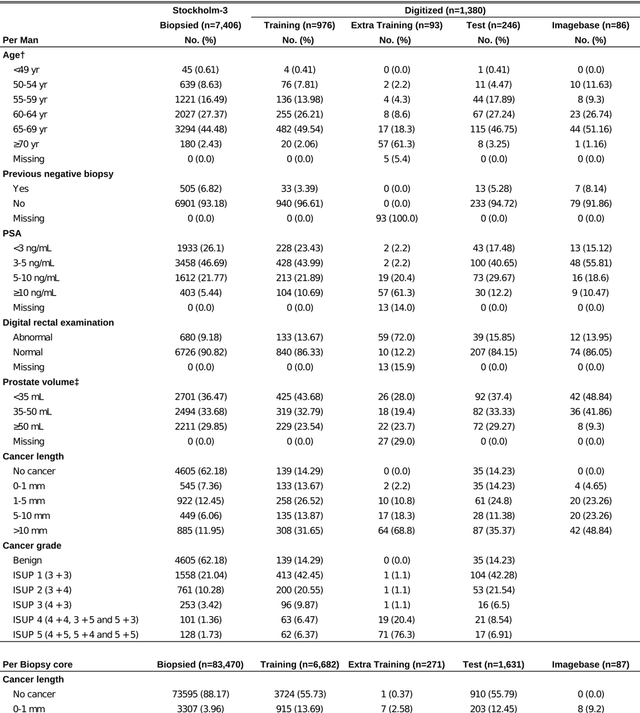
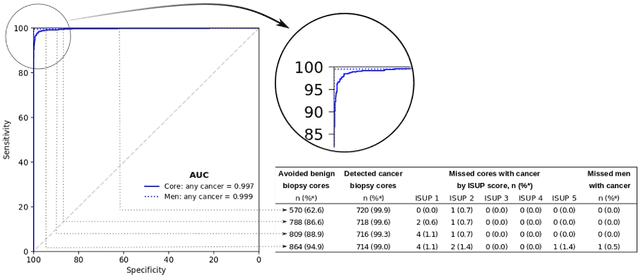
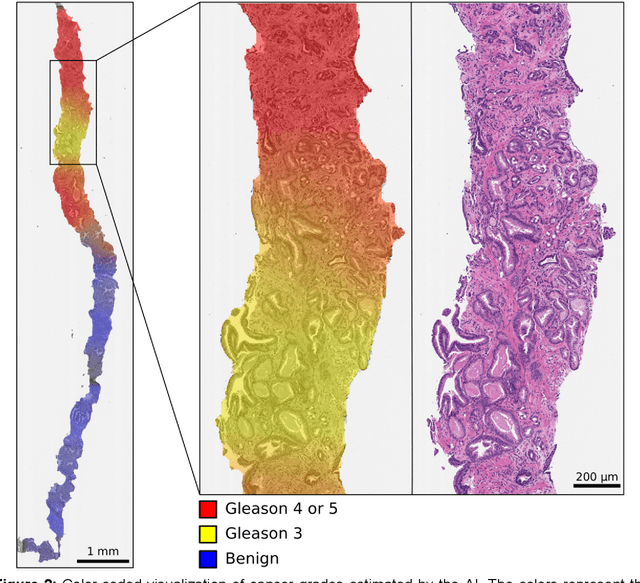
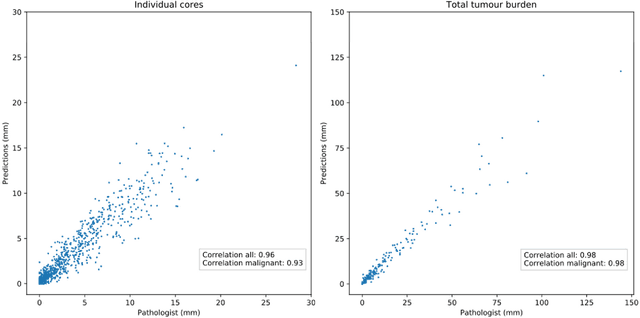
Background: An increasing volume of prostate biopsies and a world-wide shortage of uro-pathologists puts a strain on pathology departments. Additionally, the high intra- and inter-observer variability in grading can result in over- and undertreatment of prostate cancer. Artificial intelligence (AI) methods may alleviate these problems by assisting pathologists to reduce workload and harmonize grading. Methods: We digitized 6,682 needle biopsies from 976 participants in the population based STHLM3 diagnostic study to train deep neural networks for assessing prostate biopsies. The networks were evaluated by predicting the presence, extent, and Gleason grade of malignant tissue for an independent test set comprising 1,631 biopsies from 245 men. We additionally evaluated grading performance on 87 biopsies individually graded by 23 experienced urological pathologists from the International Society of Urological Pathology. We assessed discriminatory performance by receiver operating characteristics (ROC) and tumor extent predictions by correlating predicted millimeter cancer length against measurements by the reporting pathologist. We quantified the concordance between grades assigned by the AI and the expert urological pathologists using Cohen's kappa. Results: The performance of the AI to detect and grade cancer in prostate needle biopsy samples was comparable to that of international experts in prostate pathology. The AI achieved an area under the ROC curve of 0.997 for distinguishing between benign and malignant biopsy cores, and 0.999 for distinguishing between men with or without prostate cancer. The correlation between millimeter cancer predicted by the AI and assigned by the reporting pathologist was 0.96. For assigning Gleason grades, the AI achieved an average pairwise kappa of 0.62. This was within the range of the corresponding values for the expert pathologists (0.60 to 0.73).
Coupling Retrieval and Meta-Learning for Context-Dependent Semantic Parsing
Jun 17, 2019
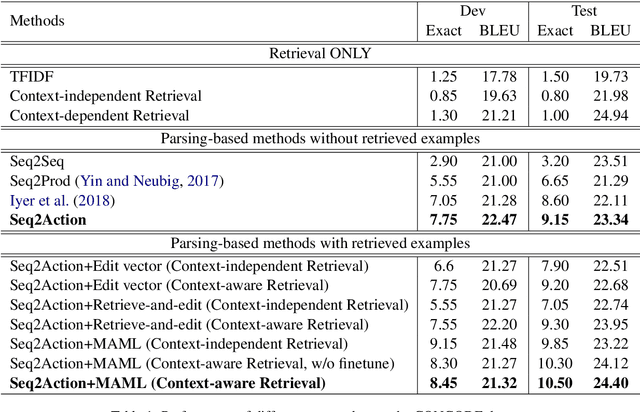
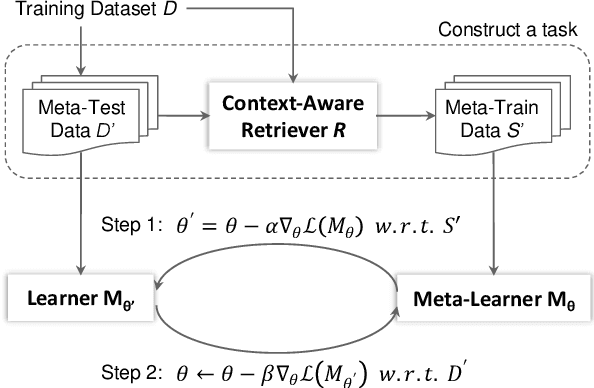
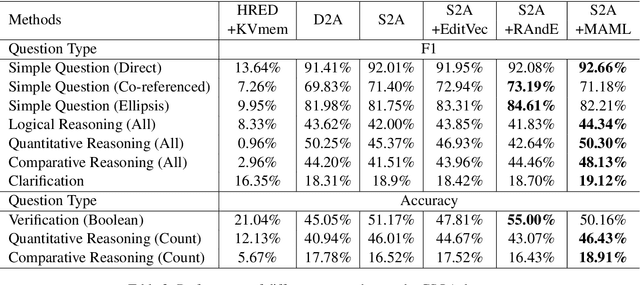
In this paper, we present an approach to incorporate retrieved datapoints as supporting evidence for context-dependent semantic parsing, such as generating source code conditioned on the class environment. Our approach naturally combines a retrieval model and a meta-learner, where the former learns to find similar datapoints from the training data, and the latter considers retrieved datapoints as a pseudo task for fast adaptation. Specifically, our retriever is a context-aware encoder-decoder model with a latent variable which takes context environment into consideration, and our meta-learner learns to utilize retrieved datapoints in a model-agnostic meta-learning paradigm for fast adaptation. We conduct experiments on CONCODE and CSQA datasets, where the context refers to class environment in JAVA codes and conversational history, respectively. We use sequence-to-action model as the base semantic parser, which performs the state-of-the-art accuracy on both datasets. Results show that both the context-aware retriever and the meta-learning strategy improve accuracy, and our approach performs better than retrieve-and-edit baselines.
HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization
May 16, 2019
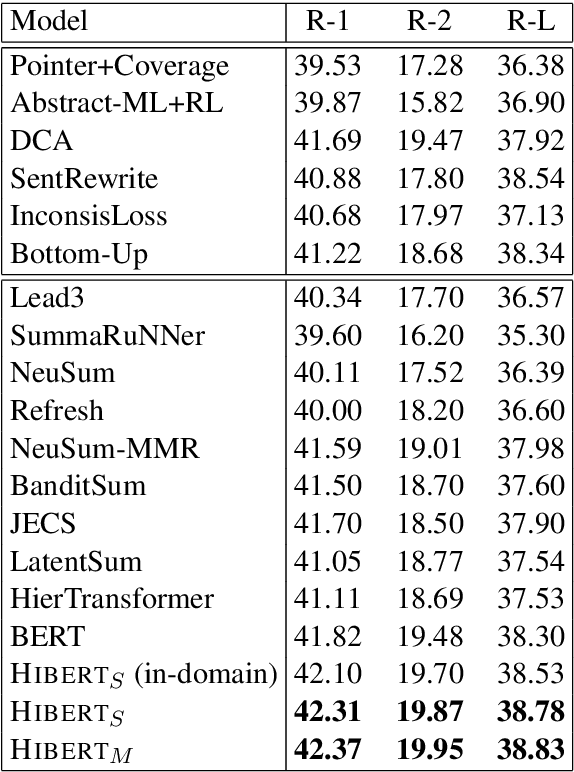
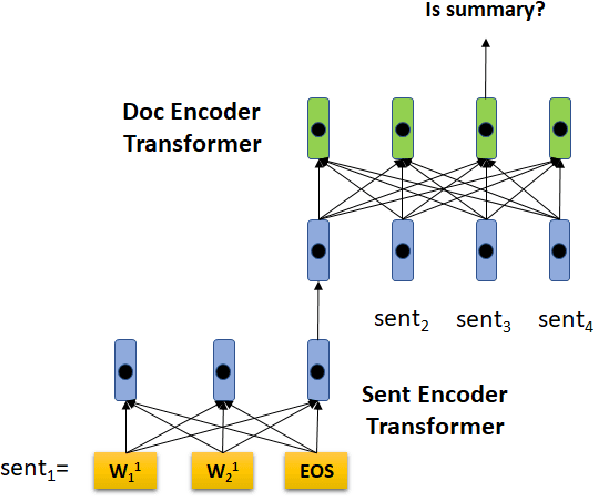
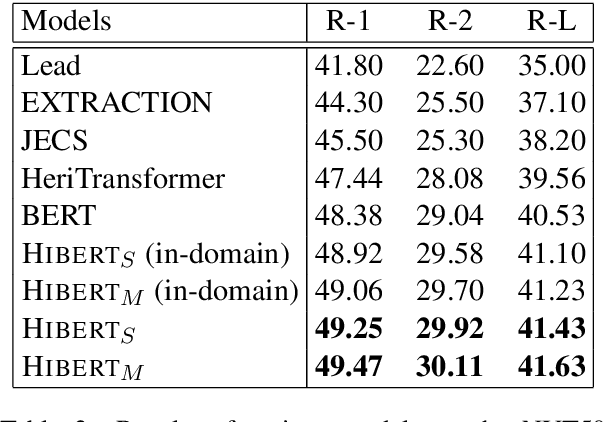
Neural extractive summarization models usually employ a hierarchical encoder for document encoding and they are trained using sentence-level labels, which are created heuristically using rule-based methods. Training the hierarchical encoder with these \emph{inaccurate} labels is challenging. Inspired by the recent work on pre-training transformer sentence encoders \cite{devlin:2018:arxiv}, we propose {\sc Hibert} (as shorthand for {\bf HI}erachical {\bf B}idirectional {\bf E}ncoder {\bf R}epresentations from {\bf T}ransformers) for document encoding and a method to pre-train it using unlabeled data. We apply the pre-trained {\sc Hibert} to our summarization model and it outperforms its randomly initialized counterpart by 1.25 ROUGE on the CNN/Dailymail dataset and by 2.0 ROUGE on a version of New York Times dataset. We also achieve the state-of-the-art performance on these two datasets.
Unified Language Model Pre-training for Natural Language Understanding and Generation
May 08, 2019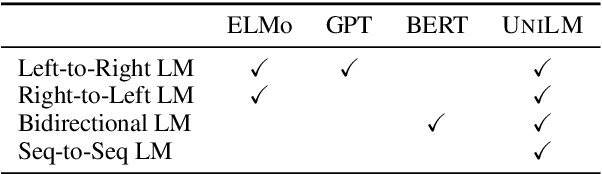
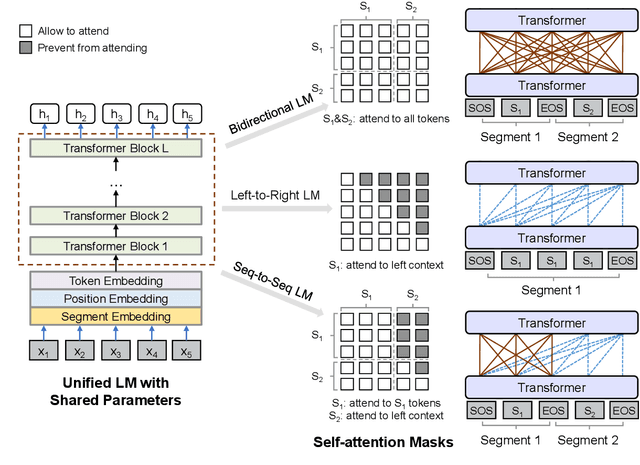


This paper presents a new Unified pre-trained Language Model (UniLM) that can be fine-tuned for both natural language understanding and generation tasks. The model is pre-trained using three types of language modeling objectives: unidirectional (both left-to-right and right-to-left), bidirectional, and sequence-to-sequence prediction. The unified modeling is achieved by employing a shared Transformer network and utilizing specific self-attention masks to control what context the prediction conditions on. We can fine-tune UniLM as a unidirectional decoder, a bidirectional encoder, or a sequence-to-sequence model to support various downstream natural language understanding and generation tasks. UniLM compares favorably with BERT on the GLUE benchmark, and the SQuAD 2.0 and CoQA question answering tasks. Moreover, our model achieves new state-of-the-art results on three natural language generation tasks, including improving the CNN/DailyMail abstractive summarization ROUGE-L to 40.63 (2.16 absolute improvement), pushing the CoQA generative question answering F1 score to 82.5 (37.1 absolute improvement), and the SQuAD question generation BLEU-4 to 22.88 (6.50 absolute improvement).
TableBank: A Benchmark Dataset for Table Detection and Recognition
Mar 05, 2019
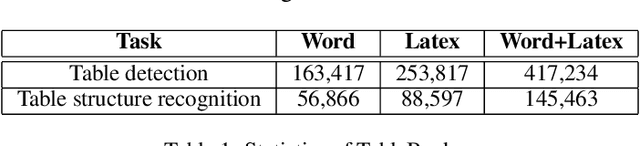
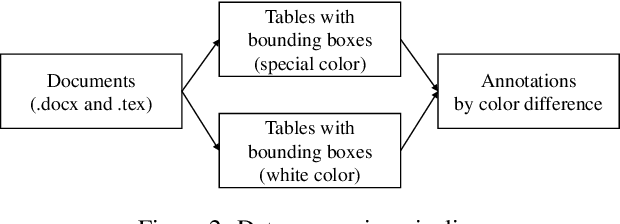
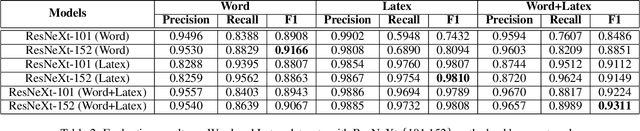
We present TableBank, a new image-based table detection and recognition dataset built with novel weak supervision from Word and Latex documents on the internet. Existing research for image-based table detection and recognition usually fine-tunes pre-trained models on out-of-domain data with a few thousands human labeled examples, which is difficult to generalize on real world applications. With TableBank that contains 417K high-quality labeled tables, we build several strong baselines using state-of-the-art models with deep neural networks. We make TableBank publicly available (https://github.com/doc-analysis/TableBank) and hope it will empower more deep learning approaches in the table detection and recognition task.
Unsupervised Neural Machine Translation with SMT as Posterior Regularization
Jan 14, 2019
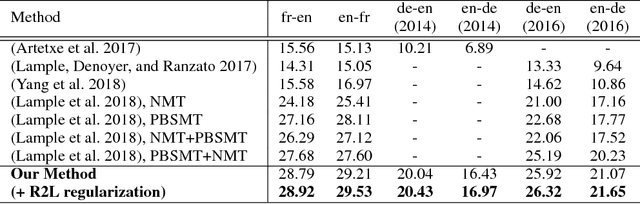
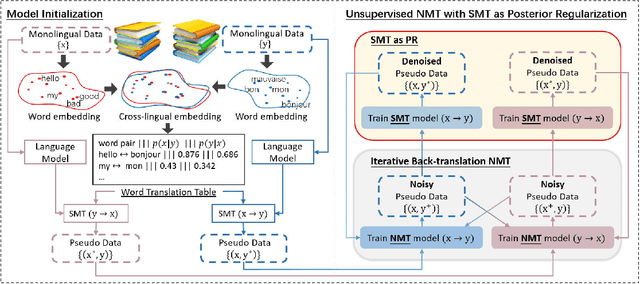
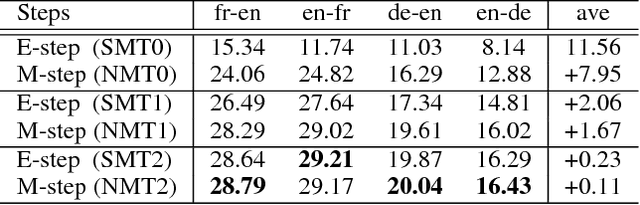
Without real bilingual corpus available, unsupervised Neural Machine Translation (NMT) typically requires pseudo parallel data generated with the back-translation method for the model training. However, due to weak supervision, the pseudo data inevitably contain noises and errors that will be accumulated and reinforced in the subsequent training process, leading to bad translation performance. To address this issue, we introduce phrase based Statistic Machine Translation (SMT) models which are robust to noisy data, as posterior regularizations to guide the training of unsupervised NMT models in the iterative back-translation process. Our method starts from SMT models built with pre-trained language models and word-level translation tables inferred from cross-lingual embeddings. Then SMT and NMT models are optimized jointly and boost each other incrementally in a unified EM framework. In this way, (1) the negative effect caused by errors in the iterative back-translation process can be alleviated timely by SMT filtering noises from its phrase tables; meanwhile, (2) NMT can compensate for the deficiency of fluency inherent in SMT. Experiments conducted on en-fr and en-de translation tasks show that our method outperforms the strong baseline and achieves new state-of-the-art unsupervised machine translation performance.
Exponential convergence rates for Batch Normalization: The power of length-direction decoupling in non-convex optimization
Oct 06, 2018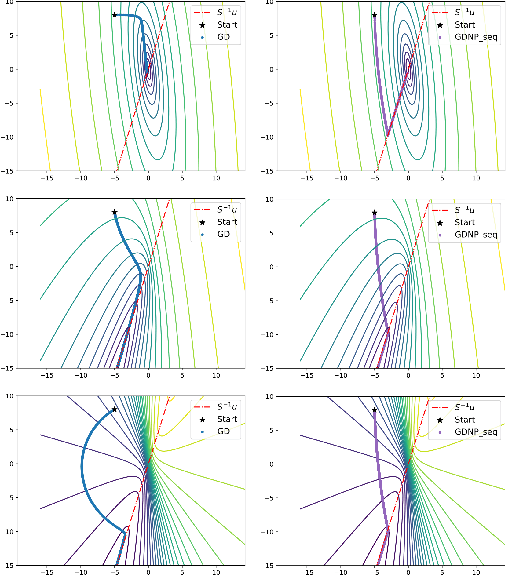

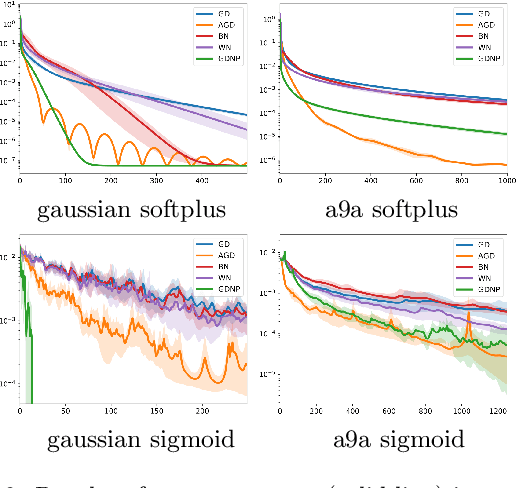
Normalization techniques such as Batch Normalization have been applied successfully for training deep neural networks. Yet, despite its apparent empirical benefits, the reasons behind the success of Batch Normalization are mostly hypothetical. We here aim to provide a more thorough theoretical understanding from a classical optimization perspective. Our main contribution towards this goal is the identification of various problem instances in the realm of machine learning where % -- under certain assumptions-- Batch Normalization can provably accelerate optimization. We argue that this acceleration is due to the fact that Batch Normalization splits the optimization task into optimizing length and direction of the parameters separately. This allows gradient-based methods to leverage a favourable global structure in the loss landscape that we prove to exist in Learning Halfspace problems and neural network training with Gaussian inputs. We thereby turn Batch Normalization from an effective practical heuristic into a provably converging algorithm for these settings. Furthermore, we substantiate our analysis with empirical evidence that suggests the validity of our theoretical results in a broader context.