 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Survey on Long Document Summarization: Datasets, Models and Metrics
Jul 03, 2022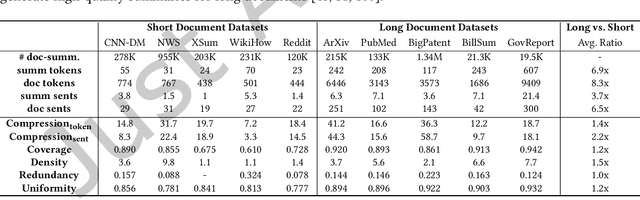
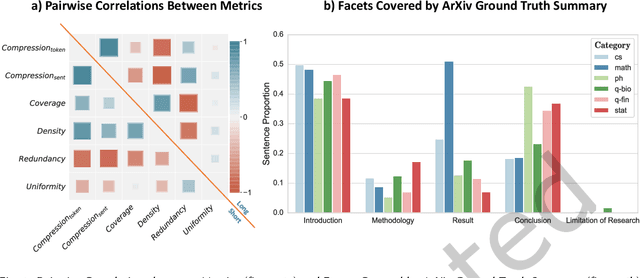
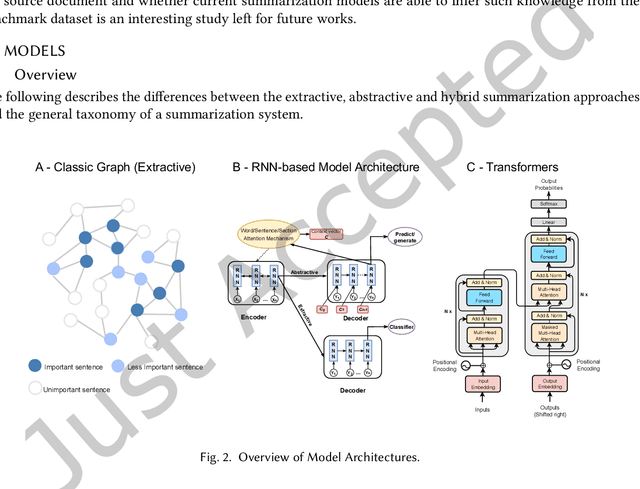
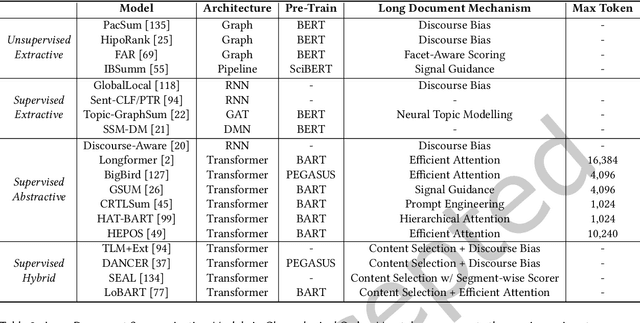
Long documents such as academic articles and business reports have been the standard format to detail out important issues and complicated subjects that require extra attention. An automatic summarization system that can effectively condense long documents into short and concise texts to encapsulate the most important information would thus be significant in aiding the reader's comprehension. Recently, with the advent of neural architectures, significant research efforts have been made to advance automatic text summarization systems, and numerous studies on the challenges of extending these systems to the long document domain have emerged. In this survey, we provide a comprehensive overview of the research on long document summarization and a systematic evaluation across the three principal components of its research setting: benchmark datasets, summarization models, and evaluation metrics. For each component, we organize the literature within the context of long document summarization and conduct an empirical analysis to broaden the perspective on current research progress. The empirical analysis includes a study on the intrinsic characteristics of benchmark datasets, a multi-dimensional analysis of summarization models, and a review of the summarization evaluation metrics. Based on the overall findings, we conclude by proposing possible directions for future exploration in this rapidly growing field.
HIT at SemEval-2022 Task 2: Pre-trained Language Model for Idioms Detection
Apr 13, 2022

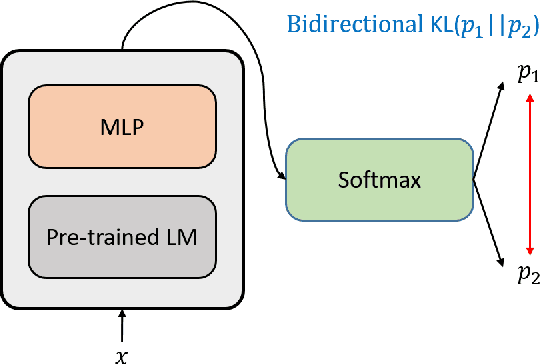

The same multi-word expressions may have different meanings in different sentences. They can be mainly divided into two categories, which are literal meaning and idiomatic meaning. Non-contextual-based methods perform poorly on this problem, and we need contextual embedding to understand the idiomatic meaning of multi-word expressions correctly. We use a pre-trained language model, which can provide a context-aware sentence embedding, to detect whether multi-word expression in the sentence is idiomatic usage.
Adaptive Network Combination for Single-Image Reflection Removal: A Domain Generalization Perspective
Apr 04, 2022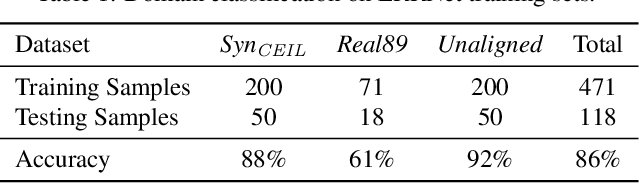
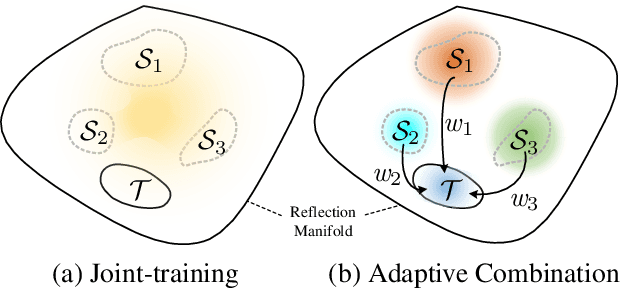
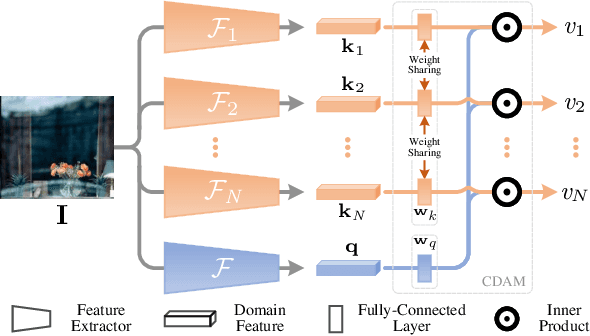

Recently, multiple synthetic and real-world datasets have been built to facilitate the training of deep single image reflection removal (SIRR) models. Meanwhile, diverse testing sets are also provided with different types of reflection and scenes. However, the non-negligible domain gaps between training and testing sets make it difficult to learn deep models generalizing well to testing images. The diversity of reflections and scenes further makes it a mission impossible to learn a single model being effective to all testing sets and real-world reflections. In this paper, we tackle these issues by learning SIRR models from a domain generalization perspective. Particularly, for each source set, a specific SIRR model is trained to serve as a domain expert of relevant reflection types. For a given reflection-contaminated image, we present a reflection type-aware weighting (RTAW) module to predict expert-wise weights. RTAW can then be incorporated with adaptive network combination (AdaNEC) for handling different reflection types and scenes, i.e., generalizing to unknown domains. Two representative AdaNEC methods, i.e., output fusion (OF) and network interpolation (NI), are provided by considering both adaptation levels and efficiency. For images from one source set, we train RTAW to only predict expert-wise weights of other domain experts for improving generalization ability, while the weights of all experts are predicted and employed during testing. An in-domain expert (IDE) loss is presented for training RTAW. Extensive experiments show the appealing performance gain of our AdaNEC on different state-of-the-art SIRR networks. Source code and pre-trained models will available at https://github.com/csmliu/AdaNEC.
Channel Self-Supervision for Online Knowledge Distillation
Mar 23, 2022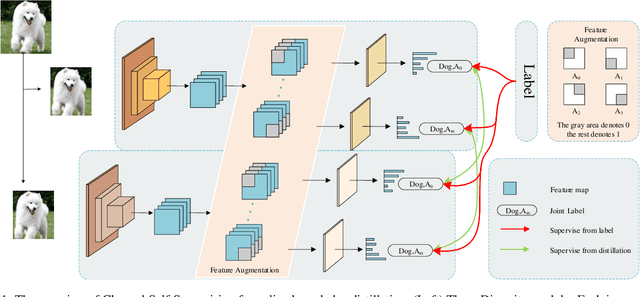
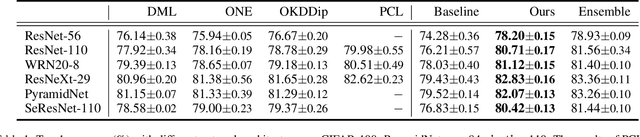
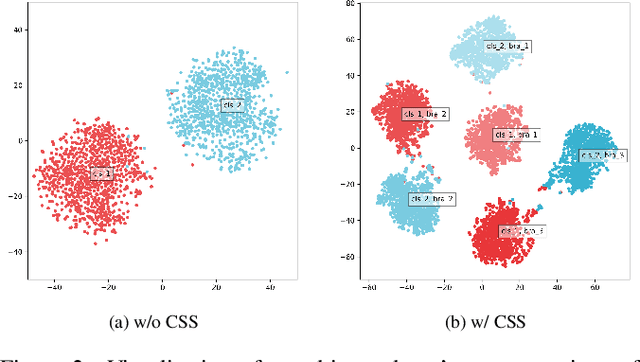
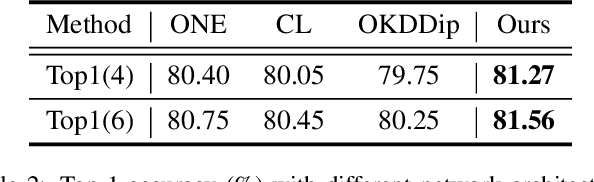
Recently, researchers have shown an increased interest in the online knowledge distillation. Adopting an one-stage and end-to-end training fashion, online knowledge distillation uses aggregated intermediated predictions of multiple peer models for training. However, the absence of a powerful teacher model may result in the homogeneity problem between group peers, affecting the effectiveness of group distillation adversely. In this paper, we propose a novel online knowledge distillation method, \textbf{C}hannel \textbf{S}elf-\textbf{S}upervision for Online Knowledge Distillation (CSS), which structures diversity in terms of input, target, and network to alleviate the homogenization problem. Specifically, we construct a dual-network multi-branch structure and enhance inter-branch diversity through self-supervised learning, adopting the feature-level transformation and augmenting the corresponding labels. Meanwhile, the dual network structure has a larger space of independent parameters to resist the homogenization problem during distillation. Extensive quantitative experiments on CIFAR-100 illustrate that our method provides greater diversity than OKDDip and we also give pretty performance improvement, even over the state-of-the-art such as PCL. The results on three fine-grained datasets (StanfordDogs, StanfordCars, CUB-200-211) also show the significant generalization capability of our approach.
Kirin: A Quadruped Robot with High Payload Carrying Capability
Feb 21, 2022The quadruped robot is a versatile mobile platform with potential ability for high payload carrying. However, most of the existing quadruped robots aim at high maneuverability, highly dynamic and agile locomotion. In spite of this, payload carrying is still an indispensable ability for the quadruped robots. Design of a quadruped robot with high payload capacity is yet deeply explored. In this study, a 50 kg electrically-actuated quadruped robot, Kirin, is presented to leverage the payload carrying capability. Kirin is an characterized with prismatic quasi-direct-drive (QDD) leg. This mechanism greatly augments the payload carrying capability. This study presents several design principles for the payload-carrying-oriented quadruped robots, including the mechanical design, actuator parameters selection, and locomotion control method. The theoretical analysis implies that the lifting task tends to be a bottleneck for the existing robots with the articulated knee joints. By using prismatic QDD leg, the payload carrying capability of Kirin is enhanced greatly. To demonstrate Kirin's payload carrying capability, in preliminary experiment, up to 125 kg payload lifting in static stance and 50 kg payload carrying in dynamic trotting are tested. Whole body compliance with payload carrying is also demonstrated.
RNGDet: Road Network Graph Detection by Transformer in Aerial Images
Feb 16, 2022



Road network graphs provide critical information for autonomous vehicle applications, such as motion planning on drivable areas. However, manually annotating road network graphs is inefficient and labor-intensive. Automatically detecting road network graphs could alleviate this issue, but existing works are either segmentation-based approaches that could not ensure satisfactory topology correctness, or graph-based approaches that could not present precise enough detection results. To provide a solution to these problems, we propose a novel approach based on transformer and imitation learning named RNGDet (\underline{R}oad \underline{N}etwork \underline{G}raph \underline{Det}ection by Transformer) in this paper. In view of that high-resolution aerial images could be easily accessed all over the world nowadays, we make use of aerial images in our approach. Taken as input an aerial image, our approach iteratively generates road network graphs vertex-by-vertex. Our approach can handle complicated intersection points of various numbers of road segments. We evaluate our approach on a publicly available dataset. The superiority of our approach is demonstrated through the comparative experiments.
Why-So-Deep: Towards Boosting Previously Trained Models for Visual Place Recognition
Jan 10, 2022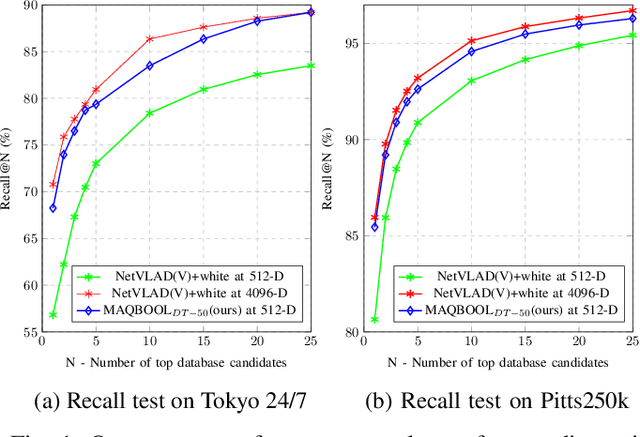

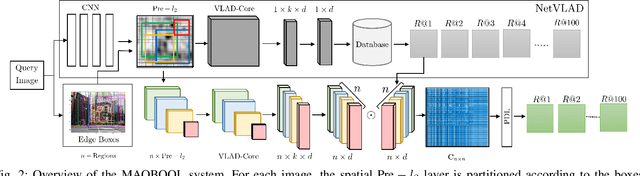

Deep learning-based image retrieval techniques for the loop closure detection demonstrate satisfactory performance. However, it is still challenging to achieve high-level performance based on previously trained models in different geographical regions. This paper addresses the problem of their deployment with simultaneous localization and mapping (SLAM) systems in the new environment. The general baseline approach uses additional information, such as GPS, sequential keyframes tracking, and re-training the whole environment to enhance the recall rate. We propose a novel approach for improving image retrieval based on previously trained models. We present an intelligent method, MAQBOOL, to amplify the power of pre-trained models for better image recall and its application to real-time multiagent SLAM systems. We achieve comparable image retrieval results at a low descriptor dimension (512-D), compared to the high descriptor dimension (4096-D) of state-of-the-art methods. We use spatial information to improve the recall rate in image retrieval on pre-trained models.
Distilled Dual-Encoder Model for Vision-Language Understanding
Dec 16, 2021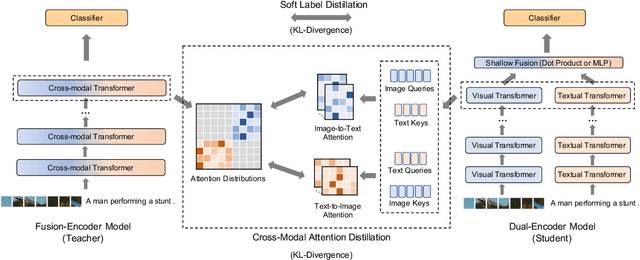
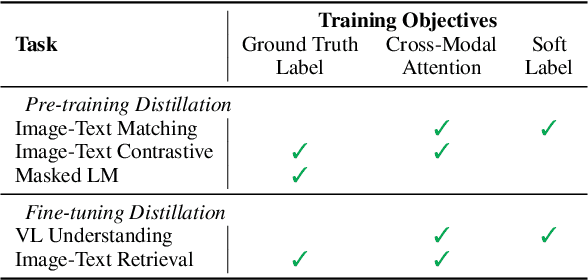

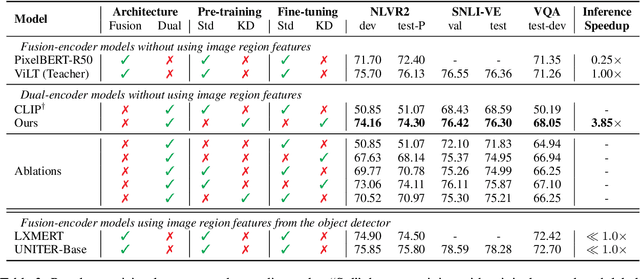
We propose a cross-modal attention distillation framework to train a dual-encoder model for vision-language understanding tasks, such as visual reasoning and visual question answering. Dual-encoder models have a faster inference speed than fusion-encoder models and enable the pre-computation of images and text during inference. However, the shallow interaction module used in dual-encoder models is insufficient to handle complex vision-language understanding tasks. In order to learn deep interactions of images and text, we introduce cross-modal attention distillation, which uses the image-to-text and text-to-image attention distributions of a fusion-encoder model to guide the training of our dual-encoder model. In addition, we show that applying the cross-modal attention distillation for both pre-training and fine-tuning stages achieves further improvements. Experimental results demonstrate that the distilled dual-encoder model achieves competitive performance for visual reasoning, visual entailment and visual question answering tasks while enjoying a much faster inference speed than fusion-encoder models. Our code and models will be publicly available at https://github.com/kugwzk/Distilled-DualEncoder.
Open-set 3D Object Detection
Dec 02, 2021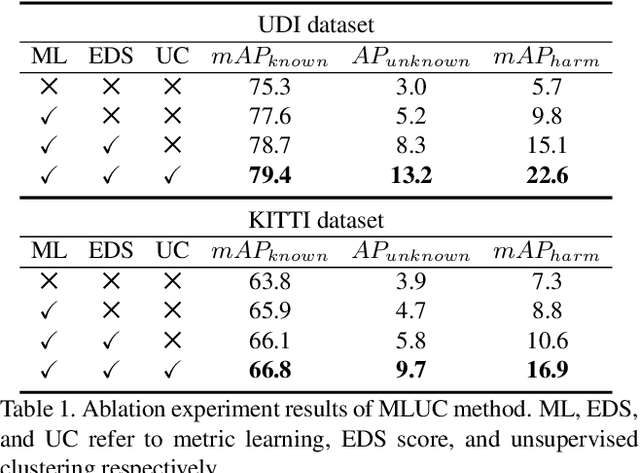
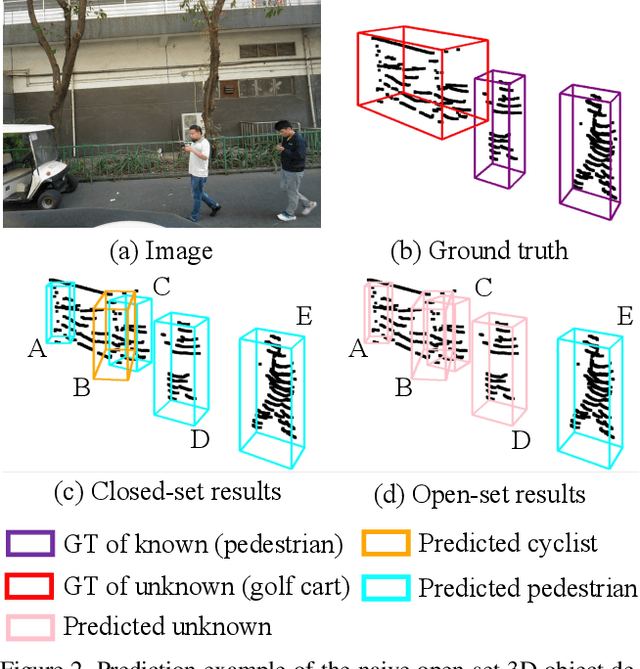
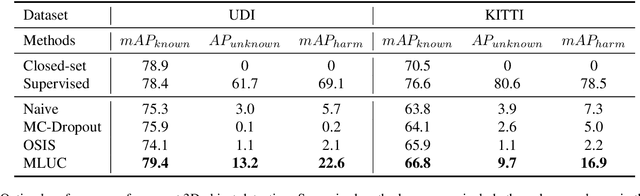
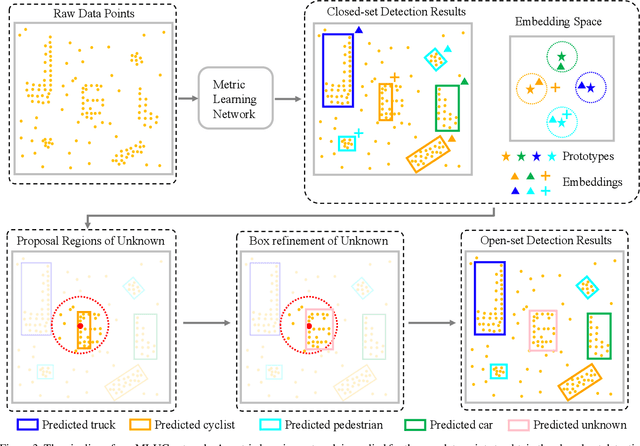
3D object detection has been wildly studied in recent years, especially for robot perception systems. However, existing 3D object detection is under a closed-set condition, meaning that the network can only output boxes of trained classes. Unfortunately, this closed-set condition is not robust enough for practical use, as it will identify unknown objects as known by mistake. Therefore, in this paper, we propose an open-set 3D object detector, which aims to (1) identify known objects, like the closed-set detection, and (2) identify unknown objects and give their accurate bounding boxes. Specifically, we divide the open-set 3D object detection problem into two steps: (1) finding out the regions containing the unknown objects with high probability and (2) enclosing the points of these regions with proper bounding boxes. The first step is solved by the finding that unknown objects are often classified as known objects with low confidence, and we show that the Euclidean distance sum based on metric learning is a better confidence score than the naive softmax probability to differentiate unknown objects from known objects. On this basis, unsupervised clustering is used to refine the bounding boxes of unknown objects. The proposed method combining metric learning and unsupervised clustering is called the MLUC network. Our experiments show that our MLUC network achieves state-of-the-art performance and can identify both known and unknown objects as expected.
Temporally Resolution Decrement: Utilizing the Shape Consistency for Higher Computational Efficiency
Dec 02, 2021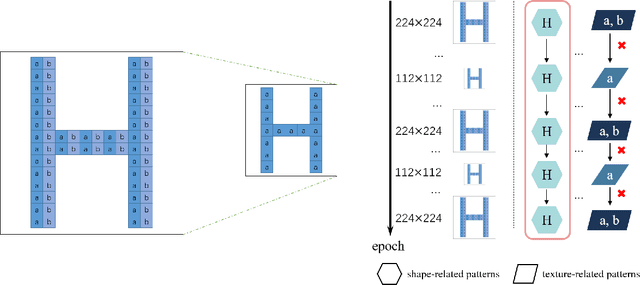
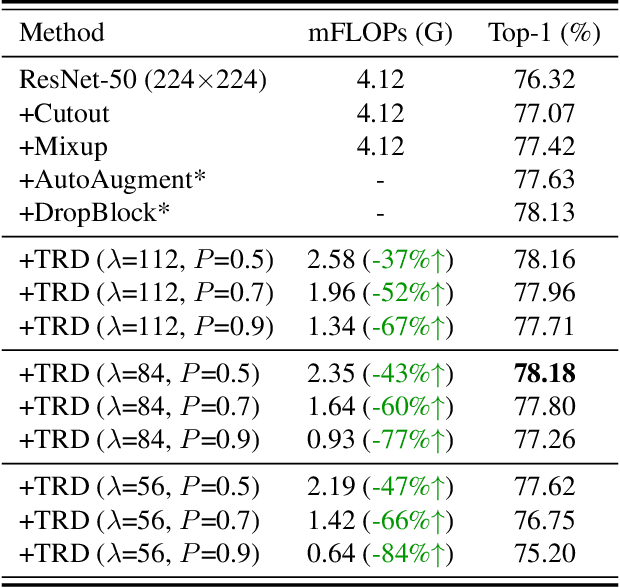
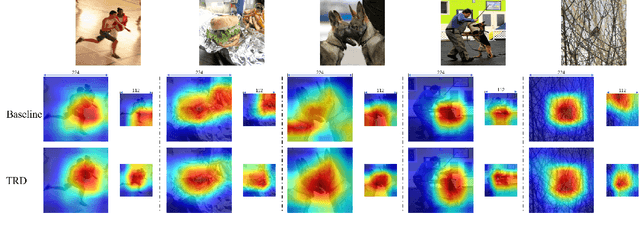
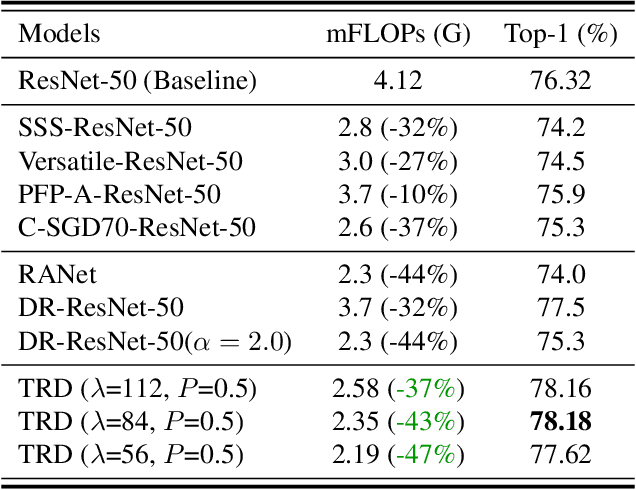
Image resolution that has close relations with accuracy and computational cost plays a pivotal role in network training. In this paper, we observe that the reduced image retains relatively complete shape semantics but loses extensive texture information. Inspired by the consistency of the shape semantics as well as the fragility of the texture information, we propose a novel training strategy named Temporally Resolution Decrement. Wherein, we randomly reduce the training images to a smaller resolution in the time domain. During the alternate training with the reduced images and the original images, the unstable texture information in the images results in a weaker correlation between the texture-related patterns and the correct label, naturally enforcing the model to rely more on shape properties that are robust and conform to the human decision rule. Surprisingly, our approach greatly improves the computational efficiency of convolutional neural networks. On ImageNet classification, using only 33% calculation quantity (randomly reducing the training image to 112$\times$112 within 90% epochs) can still improve ResNet-50 from 76.32% to 77.71%, and using 63% calculation quantity (randomly reducing the training image to 112 x 112 within 50% epochs) can improve ResNet-50 to 78.18%.