 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Conditioned GAN Data Augmentation for Representation Learning
Mar 16, 2023



Data augmentation has become a crucial component to train state-of-the-art visual representation models. However, handcrafting combinations of transformations that lead to improved performances is a laborious task, which can result in visually unrealistic samples. To overcome these limitations, recent works have explored the use of generative models as learnable data augmentation tools, showing promising results in narrow application domains, e.g., few-shot learning and low-data medical imaging. In this paper, we introduce a data augmentation module, called DA_IC-GAN, which leverages instance-conditioned GAN generations and can be used off-the-shelf in conjunction with most state-of-the-art training recipes. We showcase the benefits of DA_IC-GAN by plugging it out-of-the-box into the supervised training of ResNets and DeiT models on the ImageNet dataset, and achieving accuracy boosts up to between 1%p and 2%p with the highest capacity models. Moreover, the learnt representations are shown to be more robust than the baselines when transferred to a handful of out-of-distribution datasets, and exhibit increased invariance to variations of instance and viewpoints. We additionally couple DA_IC-GAN with a self-supervised training recipe and show that we can also achieve an improvement of 1%p in accuracy in some settings. With this work, we strengthen the evidence on the potential of learnable data augmentations to improve visual representation learning, paving the road towards non-handcrafted augmentations in model training.
Learning to Substitute Ingredients in Recipes
Feb 15, 2023



Recipe personalization through ingredient substitution has the potential to help people meet their dietary needs and preferences, avoid potential allergens, and ease culinary exploration in everyone's kitchen. To address ingredient substitution, we build a benchmark, composed of a dataset of substitution pairs with standardized splits, evaluation metrics, and baselines. We further introduce Graph-based Ingredient Substitution Module (GISMo), a novel model that leverages the context of a recipe as well as generic ingredient relational information encoded within a graph to rank plausible substitutions. We show through comprehensive experimental validation that GISMo surpasses the best performing baseline by a large margin in terms of mean reciprocal rank. Finally, we highlight the benefits of GISMo by integrating it in an improved image-to-recipe generation pipeline, enabling recipe personalization through user intervention. Quantitative and qualitative results show the efficacy of our proposed system, paving the road towards truly personalized cooking and tasting experiences.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
Nov 03, 2022Deep learning vision systems are widely deployed across applications where reliability is critical. However, even today's best models can fail to recognize an object when its pose, lighting, or background varies. While existing benchmarks surface examples challenging for models, they do not explain why such mistakes arise. To address this need, we introduce ImageNet-X, a set of sixteen human annotations of factors such as pose, background, or lighting the entire ImageNet-1k validation set as well as a random subset of 12k training images. Equipped with ImageNet-X, we investigate 2,200 current recognition models and study the types of mistakes as a function of model's (1) architecture, e.g. transformer vs. convolutional, (2) learning paradigm, e.g. supervised vs. self-supervised, and (3) training procedures, e.g., data augmentation. Regardless of these choices, we find models have consistent failure modes across ImageNet-X categories. We also find that while data augmentation can improve robustness to certain factors, they induce spill-over effects to other factors. For example, strong random cropping hurts robustness on smaller objects. Together, these insights suggest to advance the robustness of modern vision models, future research should focus on collecting additional data and understanding data augmentation schemes. Along with these insights, we release a toolkit based on ImageNet-X to spur further study into the mistakes image recognition systems make.
Uncertainty-Driven Active Vision for Implicit Scene Reconstruction
Oct 03, 2022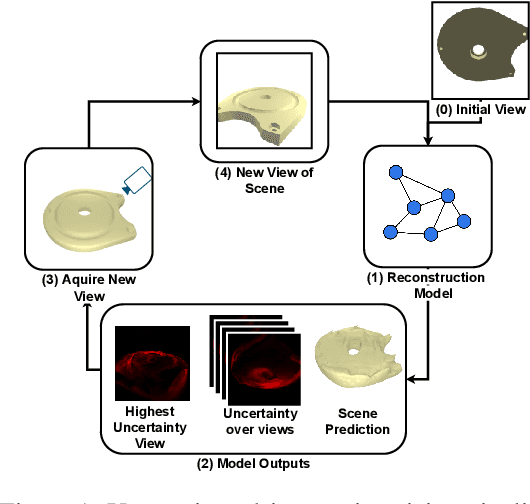
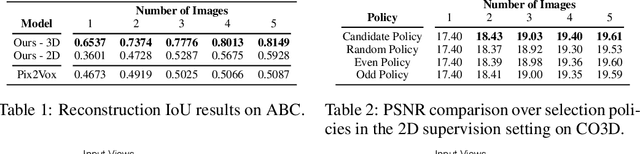
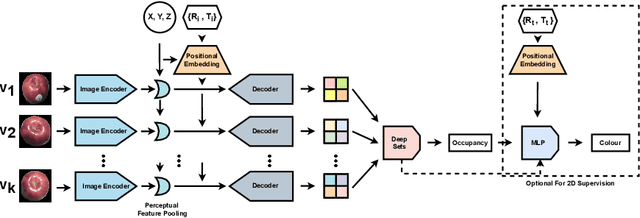

Multi-view implicit scene reconstruction methods have become increasingly popular due to their ability to represent complex scene details. Recent efforts have been devoted to improving the representation of input information and to reducing the number of views required to obtain high quality reconstructions. Yet, perhaps surprisingly, the study of which views to select to maximally improve scene understanding remains largely unexplored. We propose an uncertainty-driven active vision approach for implicit scene reconstruction, which leverages occupancy uncertainty accumulated across the scene using volume rendering to select the next view to acquire. To this end, we develop an occupancy-based reconstruction method which accurately represents scenes using either 2D or 3D supervision. We evaluate our proposed approach on the ABC dataset and the in the wild CO3D dataset, and show that: (1) we are able to obtain high quality state-of-the-art occupancy reconstructions; (2) our perspective conditioned uncertainty definition is effective to drive improvements in next best view selection and outperforms strong baseline approaches; and (3) we can further improve shape understanding by performing a gradient-based search on the view selection candidates. Overall, our results highlight the importance of view selection for implicit scene reconstruction, making it a promising avenue to explore further.
On learning adaptive acquisition policies for undersampled multi-coil MRI reconstruction
Mar 30, 2022
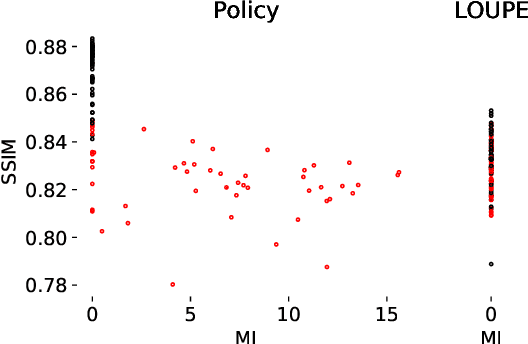
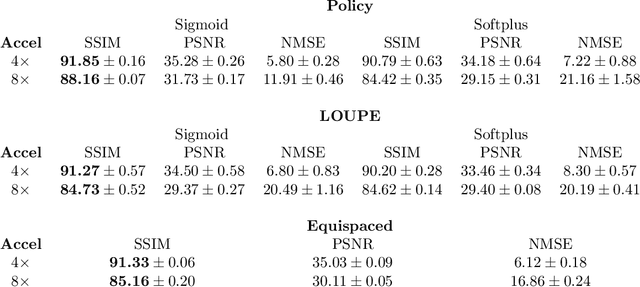
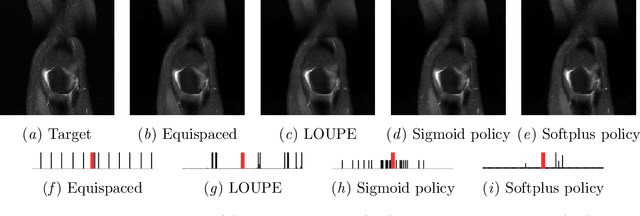
Most current approaches to undersampled multi-coil MRI reconstruction focus on learning the reconstruction model for a fixed, equidistant acquisition trajectory. In this paper, we study the problem of joint learning of the reconstruction model together with acquisition policies. To this end, we extend the End-to-End Variational Network with learnable acquisition policies that can adapt to different data points. We validate our model on a coil-compressed version of the large scale undersampled multi-coil fastMRI dataset using two undersampling factors: $4\times$ and $8\times$. Our experiments show on-par performance with the learnable non-adaptive and handcrafted equidistant strategies at $4\times$, and an observed improvement of more than $2\%$ in SSIM at $8\times$ acceleration, suggesting that potentially-adaptive $k$-space acquisition trajectories can improve reconstructed image quality for larger acceleration factors. However, and perhaps surprisingly, our best performing policies learn to be explicitly non-adaptive.
Parameter Prediction for Unseen Deep Architectures
Oct 25, 2021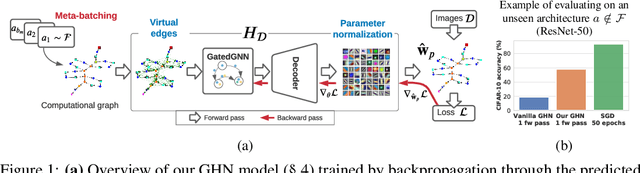
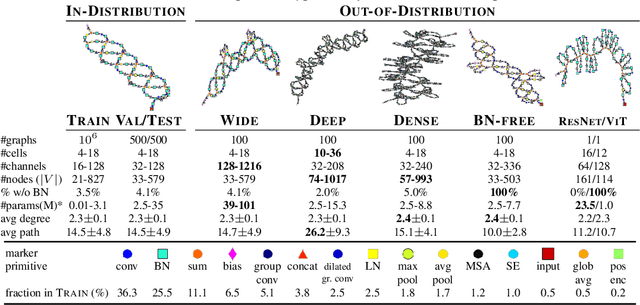


Deep learning has been successful in automating the design of features in machine learning pipelines. However, the algorithms optimizing neural network parameters remain largely hand-designed and computationally inefficient. We study if we can use deep learning to directly predict these parameters by exploiting the past knowledge of training other networks. We introduce a large-scale dataset of diverse computational graphs of neural architectures - DeepNets-1M - and use it to explore parameter prediction on CIFAR-10 and ImageNet. By leveraging advances in graph neural networks, we propose a hypernetwork that can predict performant parameters in a single forward pass taking a fraction of a second, even on a CPU. The proposed model achieves surprisingly good performance on unseen and diverse networks. For example, it is able to predict all 24 million parameters of a ResNet-50 achieving a 60% accuracy on CIFAR-10. On ImageNet, top-5 accuracy of some of our networks approaches 50%. Our task along with the model and results can potentially lead to a new, more computationally efficient paradigm of training networks. Our model also learns a strong representation of neural architectures enabling their analysis.
Instance-Conditioned GAN
Sep 10, 2021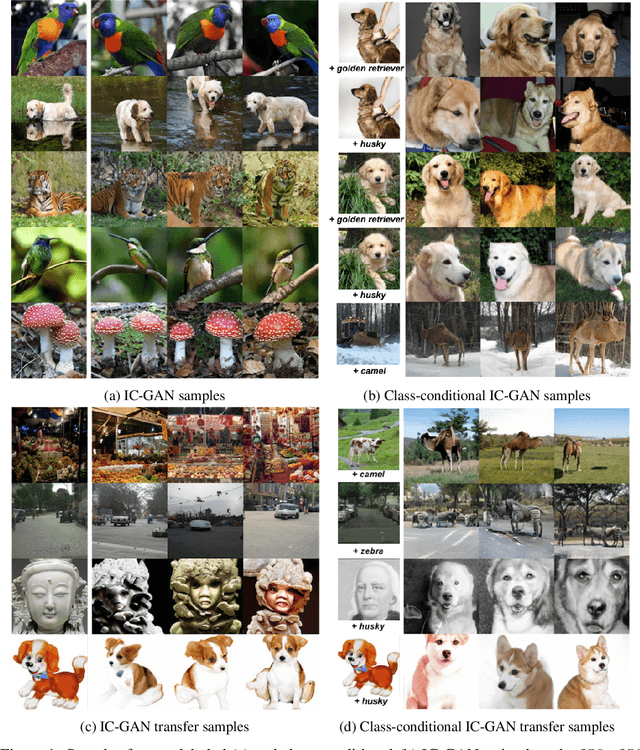
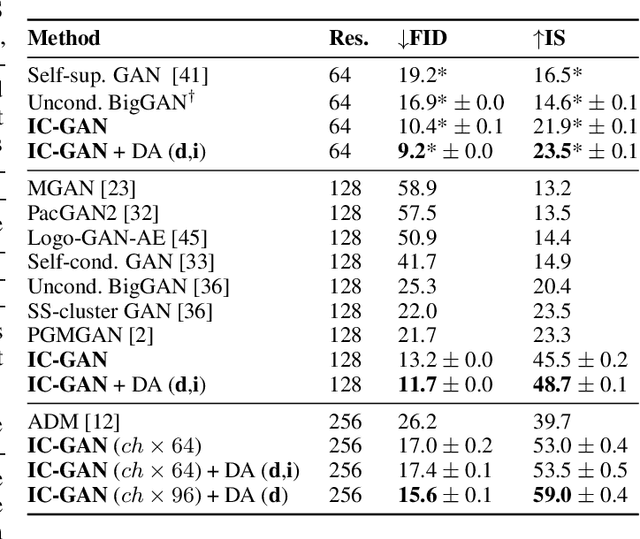
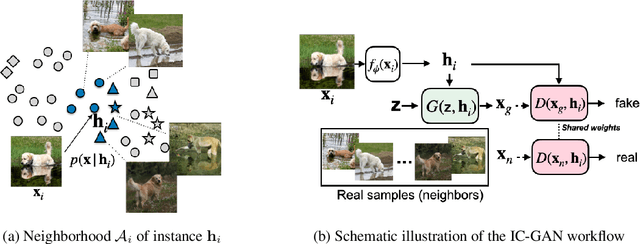
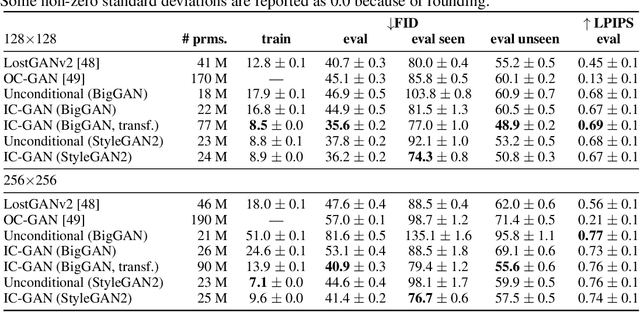
Generative Adversarial Networks (GANs) can generate near photo realistic images in narrow domains such as human faces. Yet, modeling complex distributions of datasets such as ImageNet and COCO-Stuff remains challenging in unconditional settings. In this paper, we take inspiration from kernel density estimation techniques and introduce a non-parametric approach to modeling distributions of complex datasets. We partition the data manifold into a mixture of overlapping neighborhoods described by a datapoint and its nearest neighbors, and introduce a model, called instance-conditioned GAN (IC-GAN), which learns the distribution around each datapoint. Experimental results on ImageNet and COCO-Stuff show that IC-GAN significantly improves over unconditional models and unsupervised data partitioning baselines. Moreover, we show that IC-GAN can effortlessly transfer to datasets not seen during training by simply changing the conditioning instances, and still generate realistic images. Finally, we extend IC-GAN to the class-conditional case and show semantically controllable generation and competitive quantitative results on ImageNet; while improving over BigGAN on ImageNet-LT. We will opensource our code and trained models to reproduce the reported results.
Active 3D Shape Reconstruction from Vision and Touch
Jul 20, 2021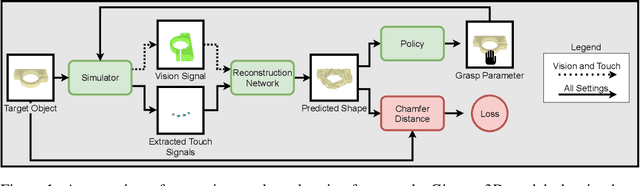
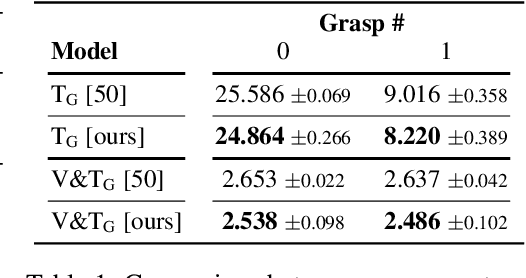
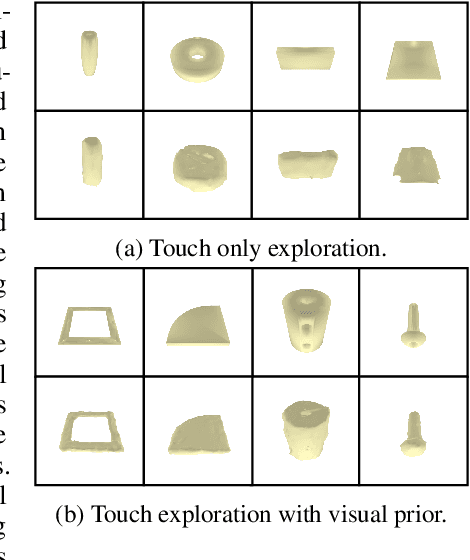
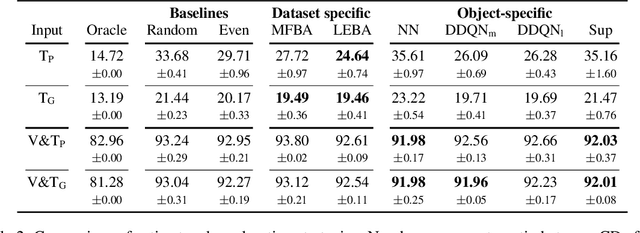
Humans build 3D understandings of the world through active object exploration, using jointly their senses of vision and touch. However, in 3D shape reconstruction, most recent progress has relied on static datasets of limited sensory data such as RGB images, depth maps or haptic readings, leaving the active exploration of the shape largely unexplored. In active touch sensing for 3D reconstruction, the goal is to actively select the tactile readings that maximize the improvement in shape reconstruction accuracy. However, the development of deep learning-based active touch models is largely limited by the lack of frameworks for shape exploration. In this paper, we focus on this problem and introduce a system composed of: 1) a haptic simulator leveraging high spatial resolution vision-based tactile sensors for active touching of 3D objects; 2) a mesh-based 3D shape reconstruction model that relies on tactile or visuotactile signals; and 3) a set of data-driven solutions with either tactile or visuotactile priors to guide the shape exploration. Our framework enables the development of the first fully data-driven solutions to active touch on top of learned models for object understanding. Our experiments show the benefits of such solutions in the task of 3D shape understanding where our models consistently outperform natural baselines. We provide our framework as a tool to foster future research in this direction.
Generating unseen complex scenes: are we there yet?
Dec 07, 2020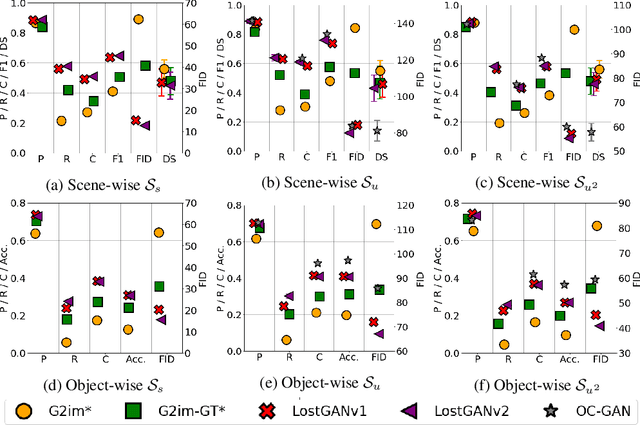
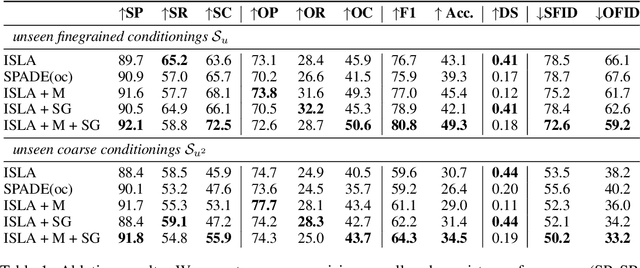
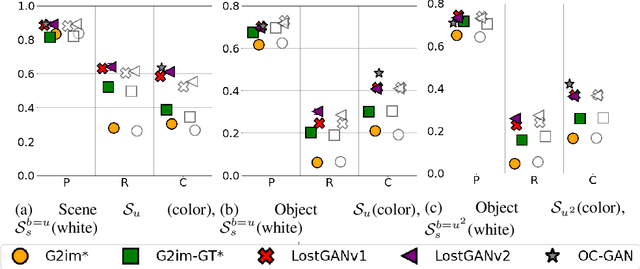
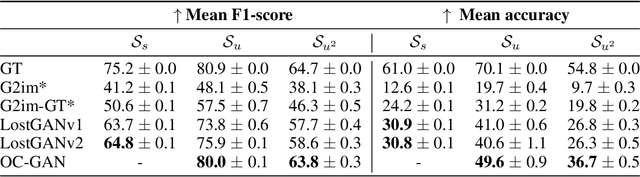
Although recent complex scene conditional generation models generate increasingly appealing scenes, it is very hard to assess which models perform better and why. This is often due to models being trained to fit different data splits, and defining their own experimental setups. In this paper, we propose a methodology to compare complex scene conditional generation models, and provide an in-depth analysis that assesses the ability of each model to (1) fit the training distribution and hence perform well on seen conditionings, (2) to generalize to unseen conditionings composed of seen object combinations, and (3) generalize to unseen conditionings composed of unseen object combinations. As a result, we observe that recent methods are able to generate recognizable scenes given seen conditionings, and exploit compositionality to generalize to unseen conditionings with seen object combinations. However, all methods suffer from noticeable image quality degradation when asked to generate images from conditionings composed of unseen object combinations. Moreover, through our analysis, we identify the advantages of different pipeline components, and find that (1) encouraging compositionality through instance-wise spatial conditioning normalizations increases robustness to both types of unseen conditionings, (2) using semantically aware losses such as the scene-graph perceptual similarity helps improve some dimensions of the generation process, and (3) enhancing the quality of generated masks and the quality of the individual objects are crucial steps to improve robustness to both types of unseen conditionings.
Instance Selection for GANs
Jul 30, 2020
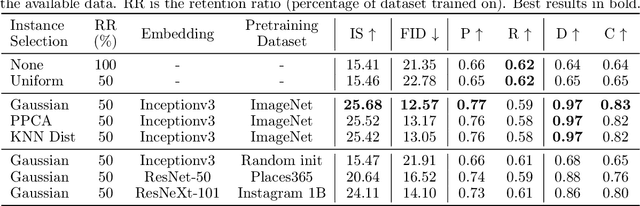
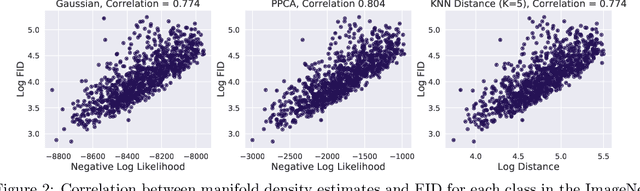
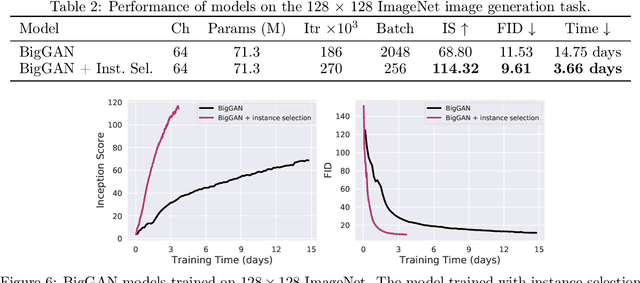
Recent advances in Generative Adversarial Networks (GANs) have led to their widespread adoption for the purposes of generating high quality synthetic imagery. While capable of generating photo-realistic images, these models often produce unrealistic samples which fall outside of the data manifold. Several recently proposed techniques attempt to avoid spurious samples, either by rejecting them after generation, or by truncating the model's latent space. While effective, these methods are inefficient, as large portions of model capacity are dedicated towards representing samples that will ultimately go unused. In this work we propose a novel approach to improve sample quality: altering the training dataset via instance selection before model training has taken place. To this end, we embed data points into a perceptual feature space and use a simple density model to remove low density regions from the data manifold. By refining the empirical data distribution before training we redirect model capacity towards high-density regions, which ultimately improves sample fidelity. We evaluate our method by training a Self-Attention GAN on ImageNet at 64x64 resolution, where we outperform the current state-of-the-art models on this task while using 1/2 of the parameters. We also highlight training time savings by training a BigGAN on ImageNet at 128x128 resolution, achieving a 66% increase in Inception Score and a 16% improvement in FID over the baseline model with less than 1/4 the training time.