 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarlow Twins: Self-Supervised Learning via Redundancy Reduction
Mar 04, 2021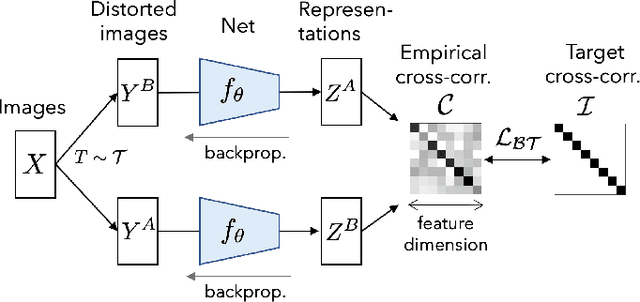
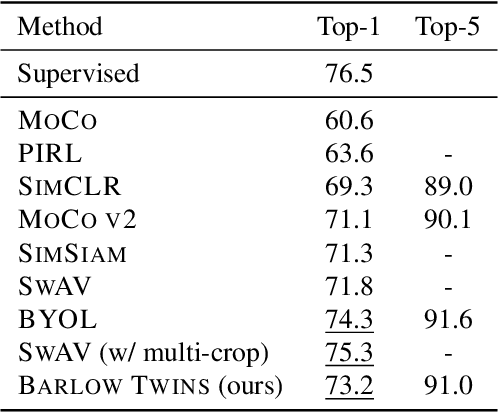
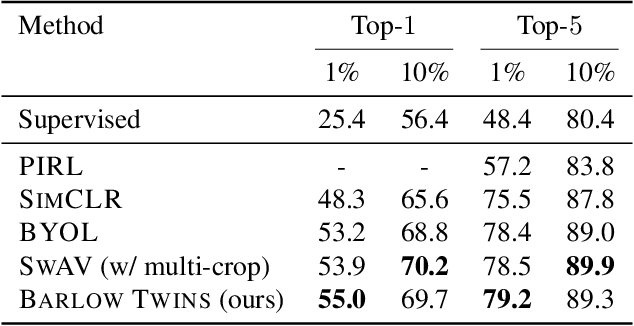
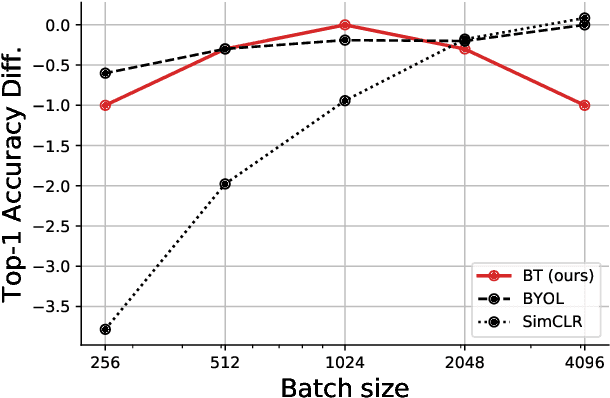
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant representations. Most current methods avoid such collapsed solutions by careful implementation details. We propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow's redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. It allows the use of very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the art for ImageNet classification with a linear classifier head, and for transfer tasks of classification and object detection.
Implicit Rank-Minimizing Autoencoder
Oct 14, 2020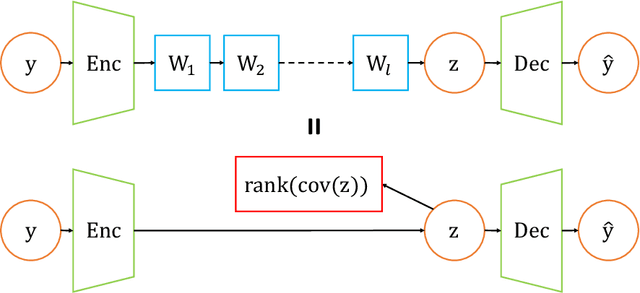
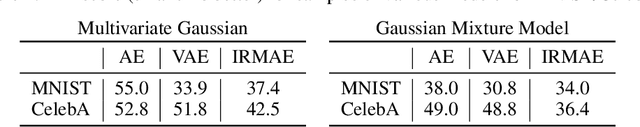
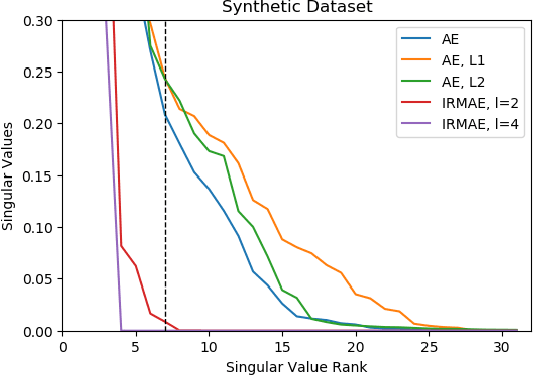
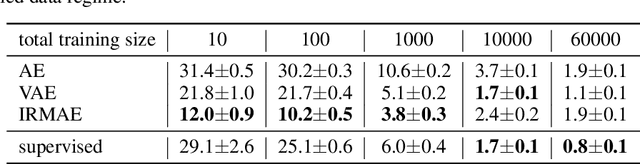
An important component of autoencoders is the method by which the information capacity of the latent representation is minimized or limited. In this work, the rank of the covariance matrix of the codes is implicitly minimized by relying on the fact that gradient descent learning in multi-layer linear networks leads to minimum-rank solutions. By inserting a number of extra linear layers between the encoder and the decoder, the system spontaneously learns representations with a low effective dimension. The model, dubbed Implicit Rank-Minimizing Autoencoder (IRMAE), is simple, deterministic, and learns compact latent spaces. We demonstrate the validity of the method on several image generation and representation learning tasks.
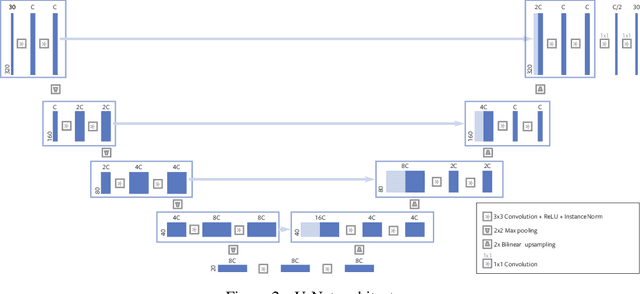
End-to-End Variational Networks for Accelerated MRI Reconstruction
Apr 15, 2020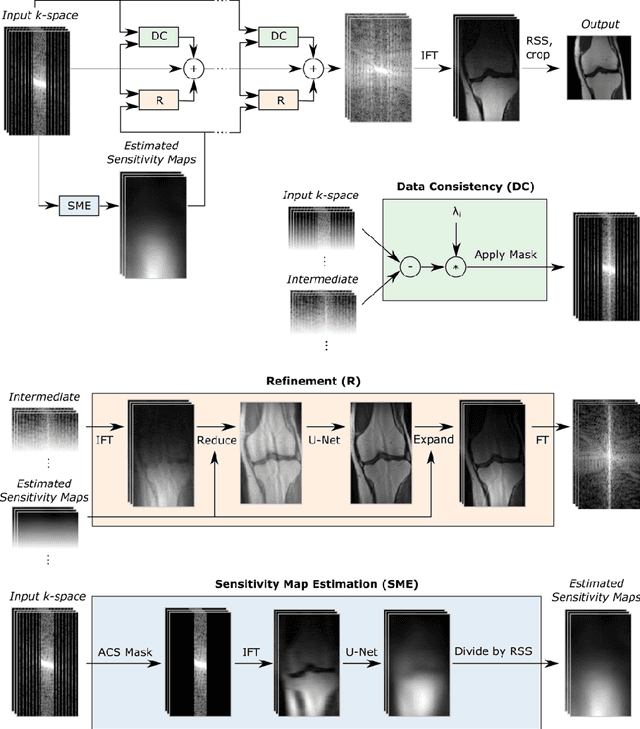
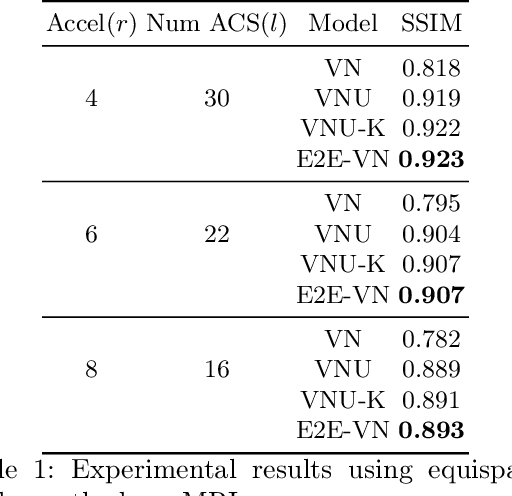
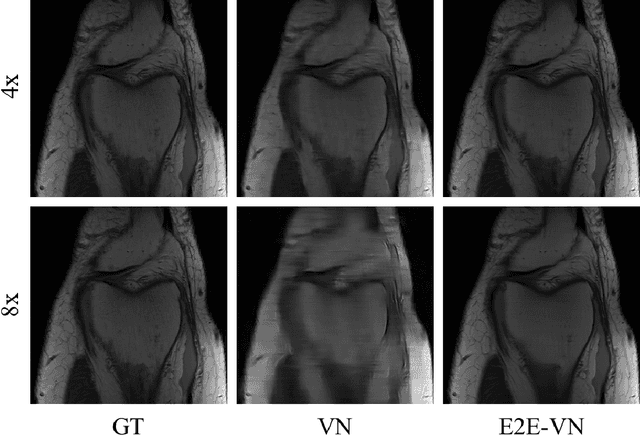
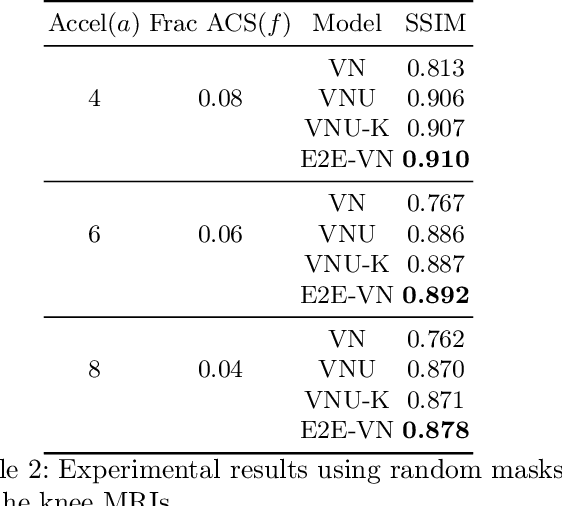
The slow acquisition speed of magnetic resonance imaging (MRI) has led to the development of two complementary methods: acquiring multiple views of the anatomy simultaneously (parallel imaging) and acquiring fewer samples than necessary for traditional signal processing methods (compressed sensing). While the combination of these methods has the potential to allow much faster scan times, reconstruction from such undersampled multi-coil data has remained an open problem. In this paper, we present a new approach to this problem that extends previously proposed variational methods by learning fully end-to-end. Our method obtains new state-of-the-art results on the fastMRI dataset for both brain and knee MRIs.
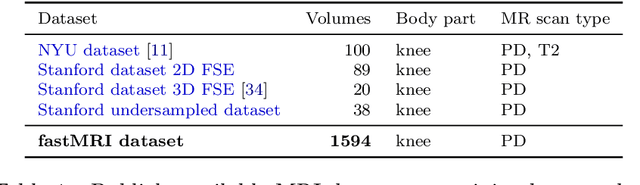
Advancing machine learning for MR image reconstruction with an open competition: Overview of the 2019 fastMRI challenge
Jan 06, 2020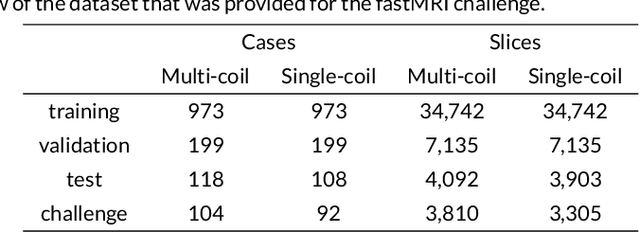
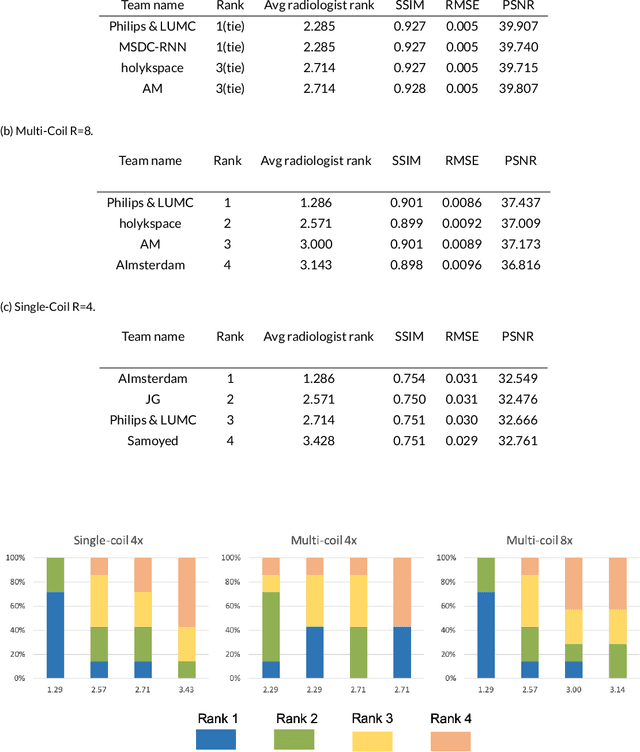

Purpose: To advance research in the field of machine learning for MR image reconstruction with an open challenge. Methods: We provided participants with a dataset of raw k-space data from 1,594 consecutive clinical exams of the knee. The goal of the challenge was to reconstruct images from these data. In order to strike a balance between realistic data and a shallow learning curve for those not already familiar with MR image reconstruction, we ran multiple tracks for multi-coil and single-coil data. We performed a two-stage evaluation based on quantitative image metrics followed by evaluation by a panel of radiologists. The challenge ran from June to December of 2019. Results: We received a total of 33 challenge submissions. All participants chose to submit results from supervised machine learning approaches. Conclusion: The challenge led to new developments in machine learning for image reconstruction, provided insight into the current state of the art in the field, and highlighted remaining hurdles for clinical adoption.
GrappaNet: Combining Parallel Imaging with Deep Learning for Multi-Coil MRI Reconstruction
Nov 04, 2019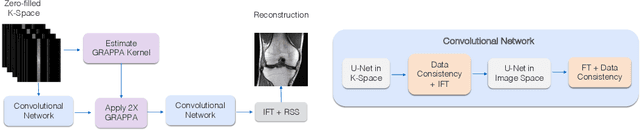
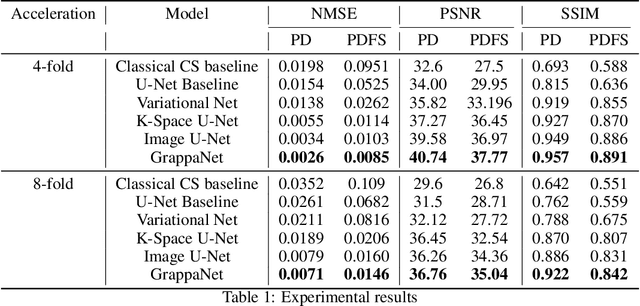
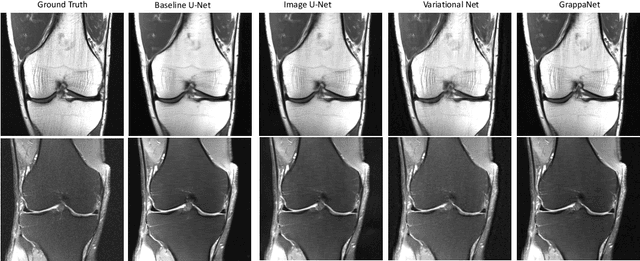
Magnetic Resonance Image (MRI) acquisition is an inherently slow process which has spurred the development of two different acceleration methods: acquiring multiple correlated samples simultaneously (parallel imaging) and acquiring fewer samples than necessary for traditional signal processing methods (compressed sensing). Both methods provide complementary approaches to accelerating the speed of MRI acquisition. In this paper, we present a novel method to integrate traditional parallel imaging methods into deep neural networks that is able to generate high quality reconstructions even for high acceleration factors. The proposed method, called GrappaNet, performs progressive reconstruction by first mapping the reconstruction problem to a simpler one that can be solved by a traditional parallel imaging methods using a neural network, followed by an application of a parallel imaging method, and finally fine-tuning the output with another neural network. The entire network can be trained end-to-end. We present experimental results on the recently released fastMRI dataset and show that GrappaNet can generate higher quality reconstructions than competing methods for both $4\times$ and $8\times$ acceleration.
fastMRI: An Open Dataset and Benchmarks for Accelerated MRI
Nov 21, 2018
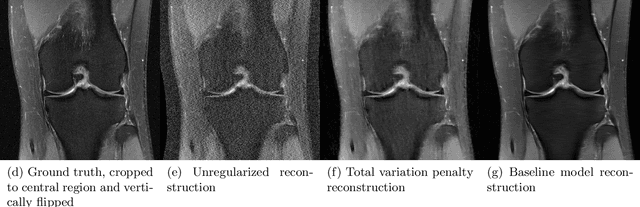
Accelerating Magnetic Resonance Imaging (MRI) by taking fewer measurements has the potential to reduce medical costs, minimize stress to patients and make MRI possible in applications where it is currently prohibitively slow or expensive. We introduce the fastMRI dataset, a large-scale collection of both raw MR measurements and clinical MR images, that can be used for training and evaluation of machine-learning approaches to MR image reconstruction. By introducing standardized evaluation criteria and a freely-accessible dataset, our goal is to help the community make rapid advances in the state of the art for MR image reconstruction. We also provide a self-contained introduction to MRI for machine learning researchers with no medical imaging background.
Fast Incremental Learning for Off-Road Robot Navigation
Jun 26, 2016

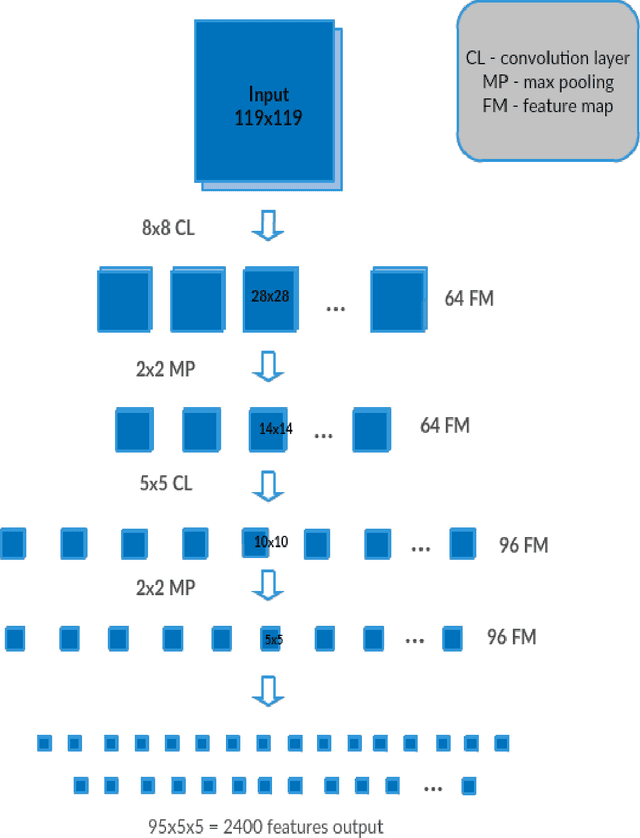

A promising approach to autonomous driving is machine learning. In such systems, training datasets are created that capture the sensory input to a vehicle as well as the desired response. A disadvantage of using a learned navigation system is that the learning process itself may require a huge number of training examples and a large amount of computing. To avoid the need to collect a large training set of driving examples, we describe a system that takes advantage of the huge number of training examples provided by ImageNet, but is able to adapt quickly using a small training set for the specific driving environment.