 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-based Multi-Scale Feature Learning Network for Multimodal Medical Image Fusion
Dec 09, 2022



Medical images play an important role in clinical applications. Multimodal medical images could provide rich information about patients for physicians to diagnose. The image fusion technique is able to synthesize complementary information from multimodal images into a single image. This technique will prevent radiologists switch back and forth between different images and save lots of time in the diagnostic process. In this paper, we introduce a novel Dilated Residual Attention Network for the medical image fusion task. Our network is capable to extract multi-scale deep semantic features. Furthermore, we propose a novel fixed fusion strategy termed Softmax-based weighted strategy based on the Softmax weights and matrix nuclear norm. Extensive experiments show our proposed network and fusion strategy exceed the state-of-the-art performance compared with reference image fusion methods on four commonly used fusion metrics.
Towards Theoretical Analysis of Transformation Complexity of ReLU DNNs
May 04, 2022
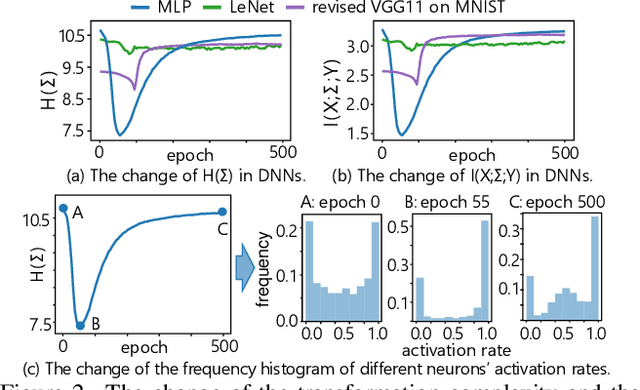
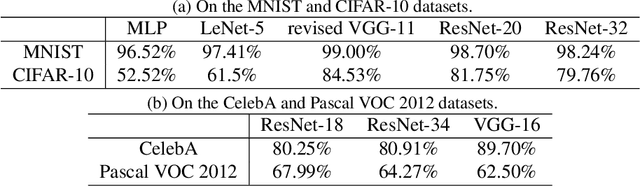
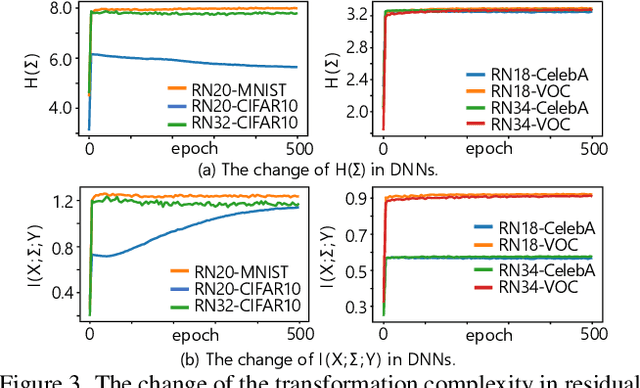
This paper aims to theoretically analyze the complexity of feature transformations encoded in DNNs with ReLU layers. We propose metrics to measure three types of complexities of transformations based on the information theory. We further discover and prove the strong correlation between the complexity and the disentanglement of transformations. Based on the proposed metrics, we analyze two typical phenomena of the change of the transformation complexity during the training process, and explore the ceiling of a DNN's complexity. The proposed metrics can also be used as a loss to learn a DNN with the minimum complexity, which also controls the over-fitting level of the DNN and influences adversarial robustness, adversarial transferability, and knowledge consistency. Comprehensive comparative studies have provided new perspectives to understand the DNN.
Enhancing Cross-lingual Prompting with Mask Token Augmentation
Feb 15, 2022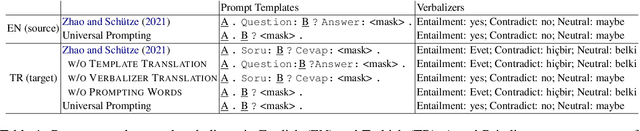
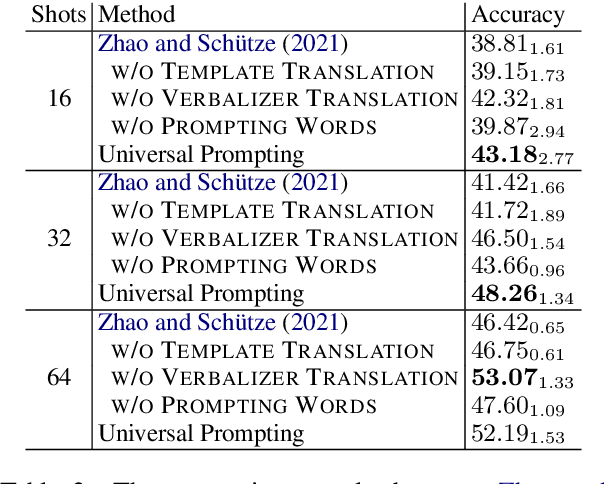
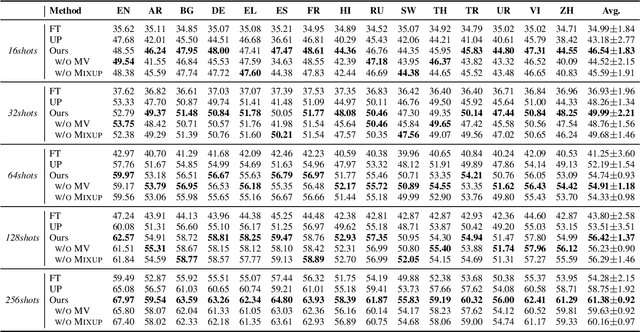
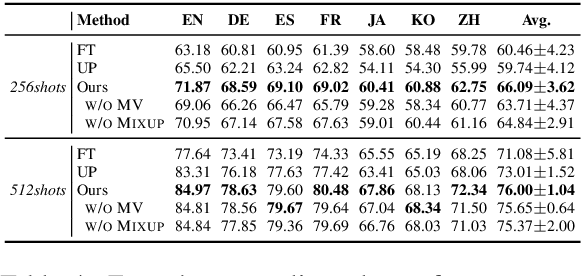
Prompting shows promising results in few-shot scenarios. However, its strength for multilingual/cross-lingual problems has not been fully exploited. Zhao and Sch\"utze (2021) made initial explorations in this direction by presenting that cross-lingual prompting outperforms cross-lingual finetuning. In this paper, we conduct empirical analysis on the effect of each component in cross-lingual prompting and derive Universal Prompting across languages, which helps alleviate the discrepancies between source-language training and target-language inference. Based on this, we propose a mask token augmentation framework to further improve the performance of prompt-based cross-lingual transfer. Notably, for XNLI, our method achieves 46.54% with only 16 English training examples per class, significantly better than 34.99% of finetuning.
Heuristic Hyperparameter Optimization for Convolutional Neural Networks using Genetic Algorithm
Dec 14, 2021
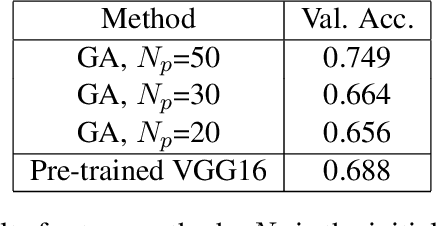
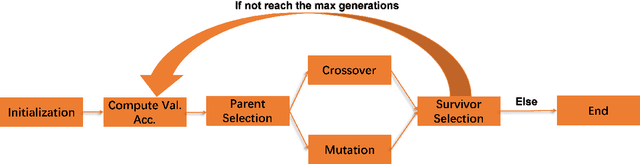

In recent years, people from all over the world are suffering from one of the most severe diseases in history, known as Coronavirus disease 2019, COVID-19 for short. When the virus reaches the lungs, it has a higher probability to cause lung pneumonia and sepsis. X-ray image is a powerful tool in identifying the typical features of the infection for COVID-19 patients. The radiologists and pathologists observe that ground-glass opacity appears in the chest X-ray for infected patient \cite{cozzi2021ground}, and it could be used as one of the criteria during the diagnosis process. In the past few years, deep learning has proven to be one of the most powerful methods in the field of image classification. Due to significant differences in Chest X-Ray between normal and infected people \cite{rousan2020chest}, deep models could be used to identify the presence of the disease given a patient's Chest X-Ray. Many deep models are complex, and it evolves with lots of input parameters. Designers sometimes struggle with the tuning process for deep models, especially when they build up the model from scratch. Genetic Algorithm, inspired by the biological evolution process, plays a key role in solving such complex problems. In this paper, I proposed a genetic-based approach to optimize the Convolutional Neural Network(CNN) for the Chest X-Ray classification task.
A Unified Game-Theoretic Interpretation of Adversarial Robustness
Nov 08, 2021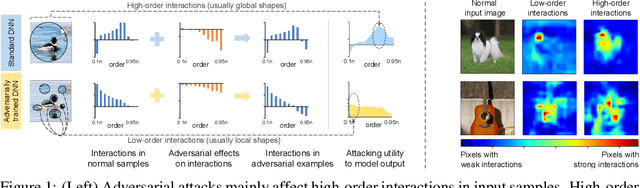

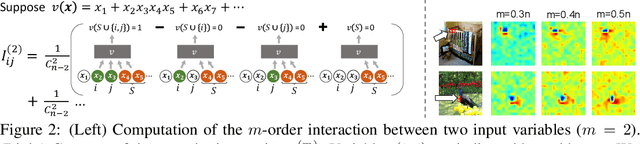
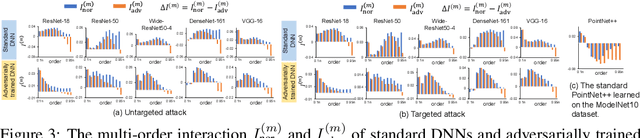
This paper provides a unified view to explain different adversarial attacks and defense methods, \emph{i.e.} the view of multi-order interactions between input variables of DNNs. Based on the multi-order interaction, we discover that adversarial attacks mainly affect high-order interactions to fool the DNN. Furthermore, we find that the robustness of adversarially trained DNNs comes from category-specific low-order interactions. Our findings provide a potential method to unify adversarial perturbations and robustness, which can explain the existing defense methods in a principle way. Besides, our findings also make a revision of previous inaccurate understanding of the shape bias of adversarially learned features.
Shoulder Implant X-Ray Manufacturer Classification: Exploring with Vision Transformer
Apr 21, 2021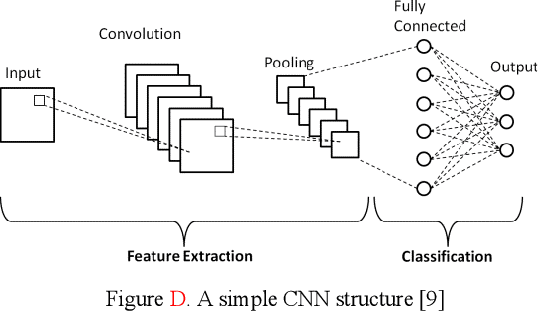
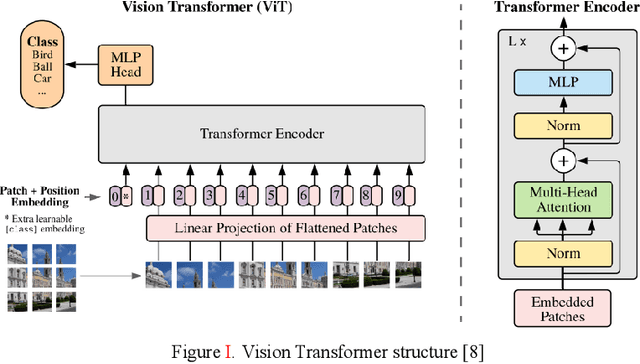
Shoulder replacement surgery, also called total shoulder replacement, is a common and complex surgery in Orthopedics discipline. It involves replacing a dead shoulder joint with an artificial implant. In the market, there are many artificial implant manufacturers and each of them may produce different implants with different structures compares to other providers. The problem arises in the following situation: a patient has some problems with the shoulder implant accessory and the manufacturer of that implant maybe unknown to either the patient or the doctor, therefore, correctly identification of the manufacturer is the key prior to the treatment. In this paper, we will demonstrate different methods for classifying the manufacturer of a shoulder implant. We will use Vision Transformer approach to this task for the first time ever
Self-supervised Regularization for Text Classification
Mar 24, 2021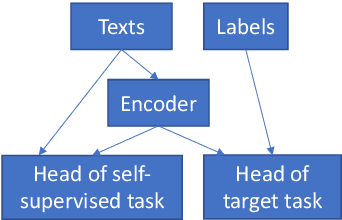
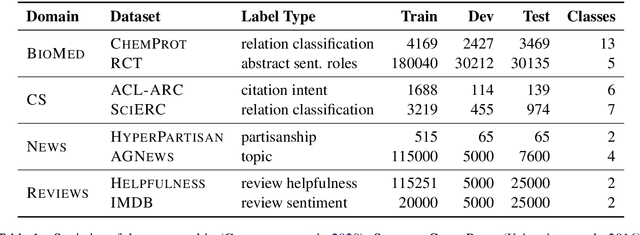

Text classification is a widely studied problem and has broad applications. In many real-world problems, the number of texts for training classification models is limited, which renders these models prone to overfitting. To address this problem, we propose SSL-Reg, a data-dependent regularization approach based on self-supervised learning (SSL). SSL is an unsupervised learning approach which defines auxiliary tasks on input data without using any human-provided labels and learns data representations by solving these auxiliary tasks. In SSL-Reg, a supervised classification task and an unsupervised SSL task are performed simultaneously. The SSL task is unsupervised, which is defined purely on input texts without using any human-provided labels. Training a model using an SSL task can prevent the model from being overfitted to a limited number of class labels in the classification task. Experiments on 17 text classification datasets demonstrate the effectiveness of our proposed method.
Intelligent Exploration for User Interface Modules of Mobile App with Collective Learning
Aug 31, 2020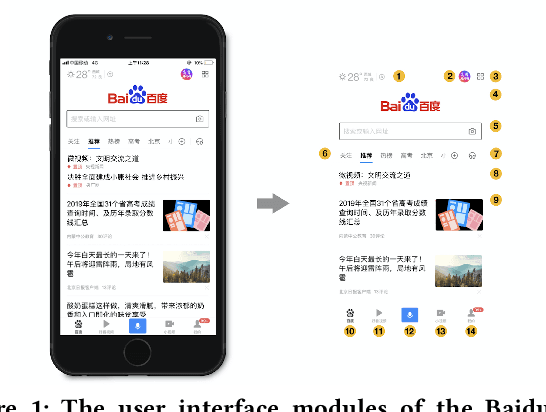
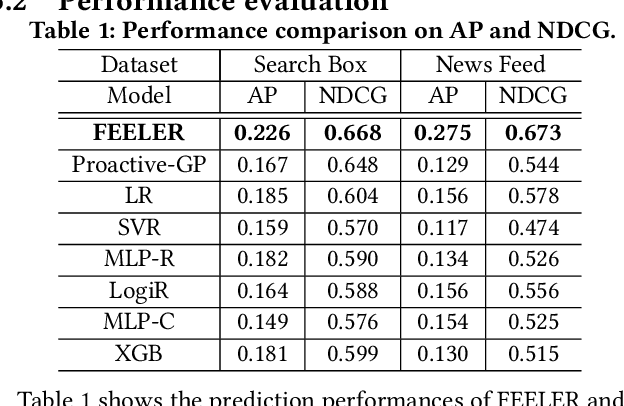
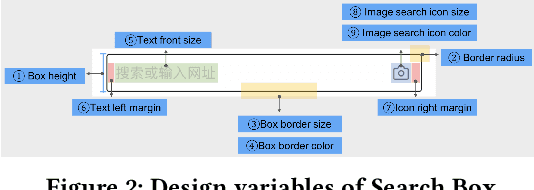
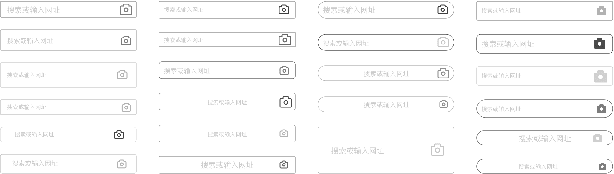
A mobile app interface usually consists of a set of user interface modules. How to properly design these user interface modules is vital to achieving user satisfaction for a mobile app. However, there are few methods to determine design variables for user interface modules except for relying on the judgment of designers. Usually, a laborious post-processing step is necessary to verify the key change of each design variable. Therefore, there is a only very limited amount of design solutions that can be tested. It is timeconsuming and almost impossible to figure out the best design solutions as there are many modules. To this end, we introduce FEELER, a framework to fast and intelligently explore design solutions of user interface modules with a collective machine learning approach. FEELER can help designers quantitatively measure the preference score of different design solutions, aiming to facilitate the designers to conveniently and quickly adjust user interface module. We conducted extensive experimental evaluations on two real-life datasets to demonstrate its applicability in real-life cases of user interface module design in the Baidu App, which is one of the most popular mobile apps in China.
Learning Implicit Credit Assignment for Multi-Agent Actor-Critic
Jul 06, 2020
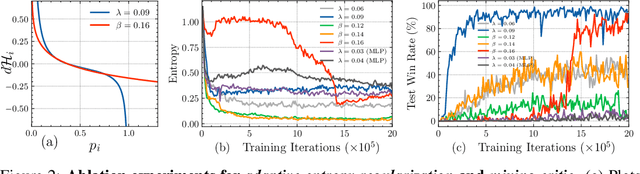
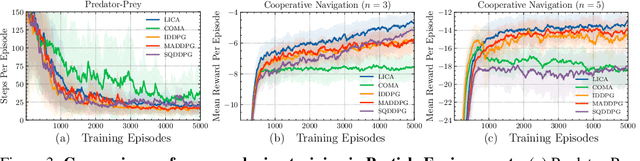
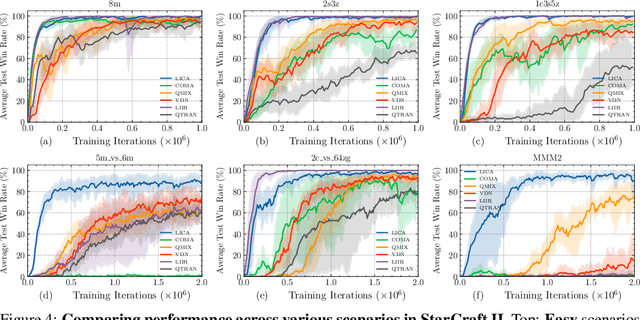
We present a new policy-based multi-agent reinforcement learning algorithm that implicitly addresses the credit assignment problem under fully cooperative settings. Our key motivation is that credit assignment may not require an explicit formulation as long as (1) the policy gradients of a trained, centralized critic carry sufficient information for the decentralized agents to maximize the critic estimate through optimal cooperation and (2) a sustained level of agent exploration is enforced throughout training. In this work, we achieve the former by formulating the centralized critic as a hypernetwork such that the latent state representation is now fused into the policy gradients through its multiplicative association with the agent policies, and we show that this is key to learning optimal joint actions that may otherwise require explicit credit assignment. To achieve the latter, we further propose a practical technique called adaptive entropy regularization where magnitudes of the policy gradients from the entropy term are dynamically rescaled to sustain consistent levels of exploration throughout training. Our final algorithm, which we call LICA, is evaluated on several benchmarks including the multi-agent particle environments and a set of challenging StarCraft II micromanagement tasks, and we show that LICA significantly outperforms previous methods.
MedDialog: A Large-scale Medical Dialogue Dataset
Apr 07, 2020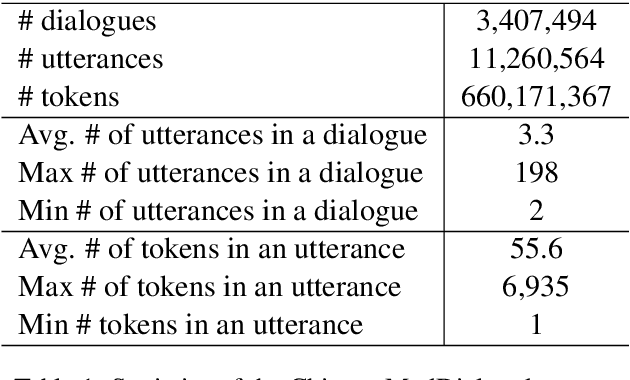

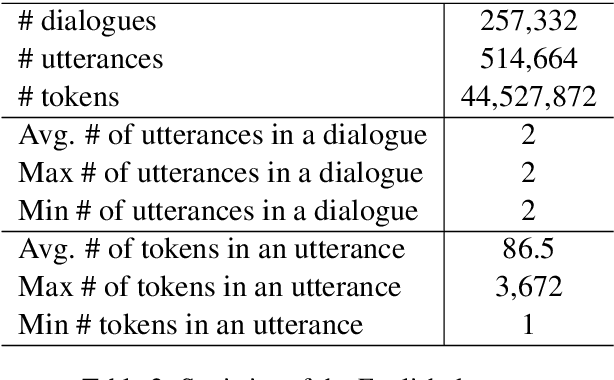
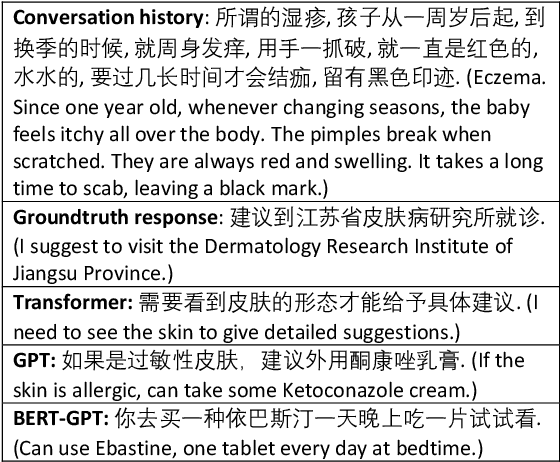
Medical dialogue systems are promising in assisting in telemedicine to increase access to healthcare services, improve the quality of patient care, and reduce medical costs. To facilitate the research and development of medical dialogue systems, we build a large-scale medical dialogue dataset -- MedDialog -- that contains 1.1 million conversations between patients and doctors and 4 million utterances. To our best knowledge, MedDialog is the largest medical dialogue dataset to date. The dataset is available at https://github.com/UCSD-AI4H/Medical-Dialogue-System