 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Prompts First-Class Citizens for Adaptive LLM Pipelines
Aug 07, 2025Modern LLM pipelines increasingly resemble data-centric systems: they retrieve external context, compose intermediate outputs, validate results, and adapt based on runtime feedback. Yet, the central element guiding this process -- the prompt -- remains a brittle, opaque string, disconnected from the surrounding dataflow. This disconnect limits reuse, optimization, and runtime control. In this paper, we describe our vision and an initial design for SPEAR, a language and runtime that fills this prompt management gap by making prompts structured, adaptive, and first-class components of the execution model. SPEAR enables (1) runtime prompt refinement -- modifying prompts dynamically in response to execution-time signals such as confidence, latency, or missing context; and (2) structured prompt management -- organizing prompt fragments into versioned views with support for introspection and logging. SPEAR defines a prompt algebra that governs how prompts are constructed and adapted within a pipeline. It supports multiple refinement modes (manual, assisted, and automatic), giving developers a balance between control and automation. By treating prompt logic as structured data, SPEAR enables optimizations such as operator fusion, prefix caching, and view reuse. Preliminary experiments quantify the behavior of different refinement modes compared to static prompts and agentic retries, as well as the impact of prompt-level optimizations such as operator fusion.
REInstruct: Building Instruction Data from Unlabeled Corpus
Aug 20, 2024



Manually annotating instruction data for large language models is difficult, costly, and hard to scale. Meanwhile, current automatic annotation methods typically rely on distilling synthetic data from proprietary LLMs, which not only limits the upper bound of the quality of the instruction data but also raises potential copyright issues. In this paper, we propose REInstruct, a simple and scalable method to automatically build instruction data from an unlabeled corpus without heavy reliance on proprietary LLMs and human annotation. Specifically, REInstruct first selects a subset of unlabeled texts that potentially contain well-structured helpful and insightful content and then generates instructions for these texts. To generate accurate and relevant responses for effective and robust training, REInstruct further proposes a rewriting-based approach to improve the quality of the generated instruction data. By training Llama-7b on a combination of 3k seed data and 32k synthetic data from REInstruct, fine-tuned model achieves a 65.41\% win rate on AlpacaEval leaderboard against text-davinci-003, outperforming other open-source, non-distilled instruction data construction methods. The code is publicly available at \url{https://github.com/cs32963/REInstruct}.
Sample Enrichment via Temporary Operations on Subsequences for Sequential Recommendation
Jul 25, 2024



Sequential recommendation leverages interaction sequences to predict forthcoming user behaviors, crucial for crafting personalized recommendations. However, the true preferences of a user are inherently complex and high-dimensional, while the observed data is merely a simplified and low-dimensional projection of the rich preferences, which often leads to prevalent issues like data sparsity and inaccurate model training. To learn true preferences from the sparse data, most existing works endeavor to introduce some extra information or design some ingenious models. Although they have shown to be effective, extra information usually increases the cost of data collection, and complex models may result in difficulty in deployment. Innovatively, we avoid the use of extra information or alterations to the model; instead, we fill the transformation space between the observed data and the underlying preferences with randomness. Specifically, we propose a novel model-agnostic and highly generic framework for sequential recommendation called sample enrichment via temporary operations on subsequences (SETO), which temporarily and separately enriches the transformation space via sequence enhancement operations with rationality constraints in training. The transformation space not only exists in the process from input samples to preferences but also in preferences to target samples. We highlight our SETO's effectiveness and versatility over multiple representative and state-of-the-art sequential recommendation models (including six single-domain sequential models and two cross-domain sequential models) across multiple real-world datasets (including three single-domain datasets, three cross-domain datasets and a large-scale industry dataset).
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
A Survey on Cross-Domain Sequential Recommendation
Jan 19, 2024Cross-domain sequential recommendation (CDSR) shifts the modeling of user preferences from flat to stereoscopic by integrating and learning interaction information from multiple domains at different granularities (ranging from inter-sequence to intra-sequence and from single-domain to cross-domain). In this survey, we first define the CDSR problem using a four-dimensional tensor and then analyze its multi-type input representations under multidirectional dimensionality reductions. Following that, we provide a systematic overview from both macro and micro views. From a macro view, we abstract the multi-level fusion structures of various models across domains and discuss their bridges for fusion. From a micro view, focusing on the existing models, we specifically discuss the basic technologies and then explain the auxiliary learning technologies. Finally, we exhibit the available public datasets and the representative experimental results as well as provide some insights into future directions for research in CDSR.
Siamese Representation Learning for Unsupervised Relation Extraction
Oct 01, 2023Unsupervised relation extraction (URE) aims at discovering underlying relations between named entity pairs from open-domain plain text without prior information on relational distribution. Existing URE models utilizing contrastive learning, which attract positive samples and repulse negative samples to promote better separation, have got decent effect. However, fine-grained relational semantic in relationship makes spurious negative samples, damaging the inherent hierarchical structure and hindering performances. To tackle this problem, we propose Siamese Representation Learning for Unsupervised Relation Extraction -- a novel framework to simply leverage positive pairs to representation learning, possessing the capability to effectively optimize relation representation of instances and retain hierarchical information in relational feature space. Experimental results show that our model significantly advances the state-of-the-art results on two benchmark datasets and detailed analyses demonstrate the effectiveness and robustness of our proposed model on unsupervised relation extraction.
SAM-Deblur: Let Segment Anything Boost Image Deblurring
Sep 05, 2023Image deblurring is a critical task in the field of image restoration, aiming to eliminate blurring artifacts. However, the challenge of addressing non-uniform blurring leads to an ill-posed problem, which limits the generalization performance of existing deblurring models. To solve the problem, we propose a framework SAM-Deblur, integrating prior knowledge from the Segment Anything Model (SAM) into the deblurring task for the first time. In particular, SAM-Deblur is divided into three stages. First, We preprocess the blurred images, obtain image masks via SAM, and propose a mask dropout method for training to enhance model robustness. Then, to fully leverage the structural priors generated by SAM, we propose a Mask Average Pooling (MAP) unit specifically designed to average SAM-generated segmented areas, serving as a plug-and-play component which can be seamlessly integrated into existing deblurring networks. Finally, we feed the fused features generated by the MAP Unit into the deblurring model to obtain a sharp image. Experimental results on the RealBlurJ, ReloBlur, and REDS datasets reveal that incorporating our methods improves NAFNet's PSNR by 0.05, 0.96, and 7.03, respectively. Code will be available at \href{https://github.com/HPLQAQ/SAM-Deblur}{SAM-Deblur}.
Improving Neural Radiance Fields with Depth-aware Optimization for Novel View Synthesis
Apr 11, 2023



With dense inputs, Neural Radiance Fields (NeRF) is able to render photo-realistic novel views under static conditions. Although the synthesis quality is excellent, existing NeRF-based methods fail to obtain moderate three-dimensional (3D) structures. The novel view synthesis quality drops dramatically given sparse input due to the implicitly reconstructed inaccurate 3D-scene structure. We propose SfMNeRF, a method to better synthesize novel views as well as reconstruct the 3D-scene geometry. SfMNeRF leverages the knowledge from the self-supervised depth estimation methods to constrain the 3D-scene geometry during view synthesis training. Specifically, SfMNeRF employs the epipolar, photometric consistency, depth smoothness, and position-of-matches constraints to explicitly reconstruct the 3D-scene structure. Through these explicit constraints and the implicit constraint from NeRF, our method improves the view synthesis as well as the 3D-scene geometry performance of NeRF at the same time. In addition, SfMNeRF synthesizes novel sub-pixels in which the ground truth is obtained by image interpolation. This strategy enables SfMNeRF to include more samples to improve generalization performance. Experiments on two public datasets demonstrate that SfMNeRF surpasses state-of-the-art approaches. Code is available at https://github.com/XTU-PR-LAB/SfMNeRF
Structure-Aware NeRF without Posed Camera via Epipolar Constraint
Oct 01, 2022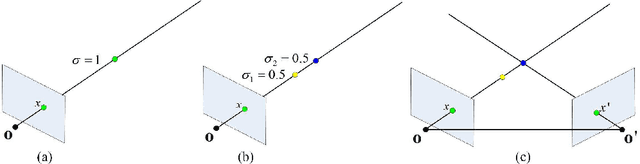
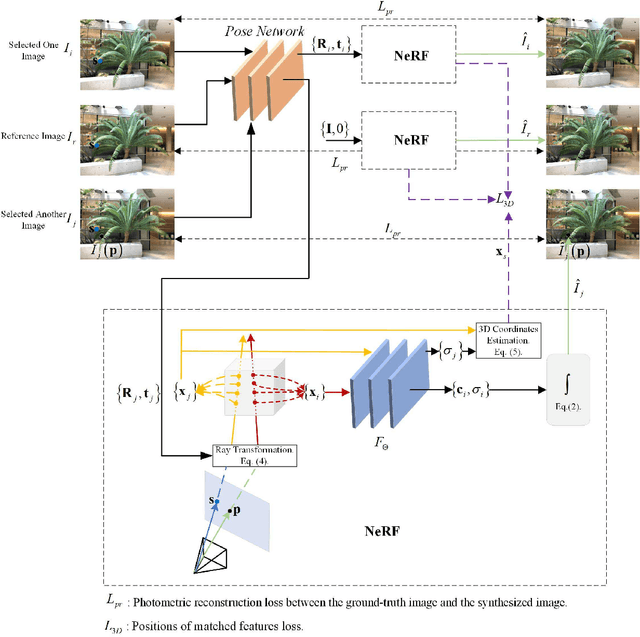


The neural radiance field (NeRF) for realistic novel view synthesis requires camera poses to be pre-acquired by a structure-from-motion (SfM) approach. This two-stage strategy is not convenient to use and degrades the performance because the error in the pose extraction can propagate to the view synthesis. We integrate the pose extraction and view synthesis into a single end-to-end procedure so they can benefit from each other. For training NeRF models, only RGB images are given, without pre-known camera poses. The camera poses are obtained by the epipolar constraint in which the identical feature in different views has the same world coordinates transformed from the local camera coordinates according to the extracted poses. The epipolar constraint is jointly optimized with pixel color constraint. The poses are represented by a CNN-based deep network, whose input is the related frames. This joint optimization enables NeRF to be aware of the scene's structure that has an improved generalization performance. Extensive experiments on a variety of scenes demonstrate the effectiveness of the proposed approach. Code is available at https://github.com/XTU-PR-LAB/SaNerf.