 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenter Feature Fusion: Selective Multi-Sensor Fusion of Center-based Objects
Sep 26, 2022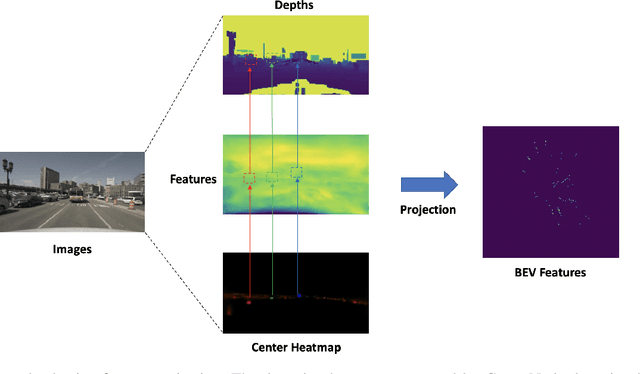
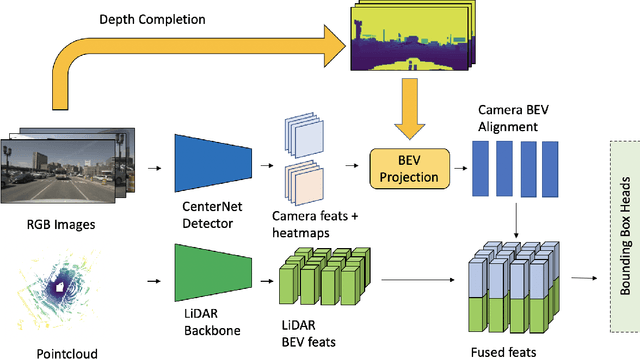

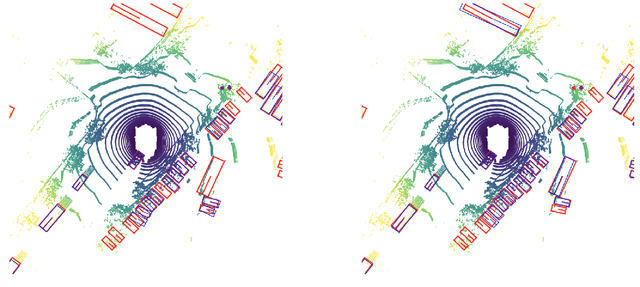
Leveraging multi-modal fusion, especially between camera and LiDAR, has become essential for building accurate and robust 3D object detection systems for autonomous vehicles. Until recently, point decorating approaches, in which point clouds are augmented with camera features, have been the dominant approach in the field. However, these approaches fail to utilize the higher resolution images from cameras. Recent works projecting camera features to the bird's-eye-view (BEV) space for fusion have also been proposed, however they require projecting millions of pixels, most of which only contain background information. In this work, we propose a novel approach Center Feature Fusion (CFF), in which we leverage center-based detection networks in both the camera and LiDAR streams to identify relevant object locations. We then use the center-based detection to identify the locations of pixel features relevant to object locations, a small fraction of the total number in the image. These are then projected and fused in the BEV frame. On the nuScenes dataset, we outperform the LiDAR-only baseline by 4.9% mAP while fusing up to 100x fewer features than other fusion methods.
A Coarse-to-Fine Framework for Dual-Arm Manipulation of Deformable Linear Objects with Whole-Body Obstacle Avoidance
Sep 22, 2022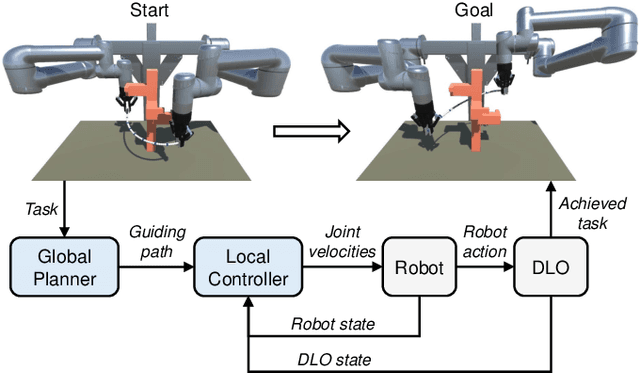
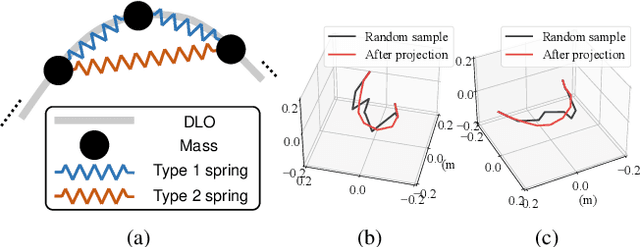
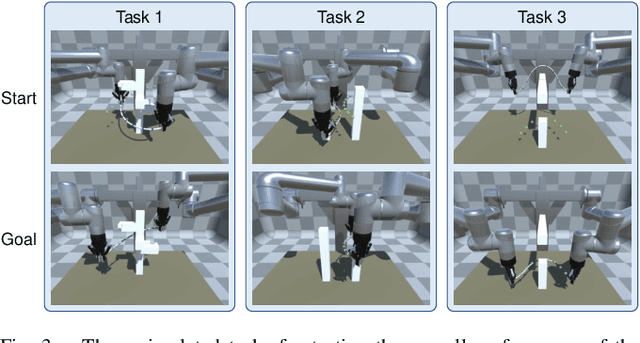
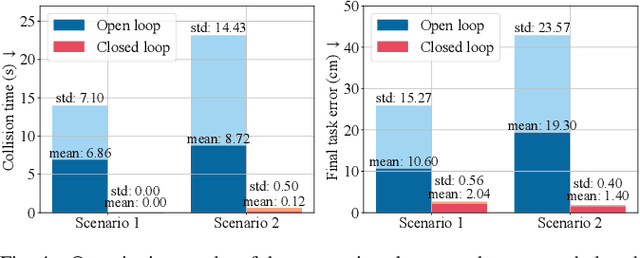
Manipulating deformable linear objects (DLOs) to achieve desired shapes in constrained environments with obstacles is a meaningful but challenging tasks. Global planning is necessary for such a highly-constrained task; however, accurate models of DLOs required by planners are difficult to obtain owing to their deformable nature, and the inevitable modeling errors significantly affect the planning results, probably resulting in task failure if the robot simply executes the planned path in an open-loop manner. In this paper, we propose a coarse-to-fine framework to combine global planning and local control for dual-arm manipulation of DLOs, capable of precisely achieving desired configurations and avoiding potential collisions between the DLO, robot, and obstacles. Specifically, the global planner refers to a simple yet effective DLO energy model and computes a coarse path to guarantee the feasibility of the task; then the local controller follows that path as guidance and further shapes it with closed-loop feedback to compensate for the planning errors and guarantee the accuracy of the task. Both simulations and real-world experiments demonstrate that our framework can robustly achieve desired DLO configurations in constrained environments with imprecise DLO models. which may not be reliably achieved by only planning or control.
Analyzing and Enhancing Closed-loop Stability in Reactive Simulation
Aug 09, 2022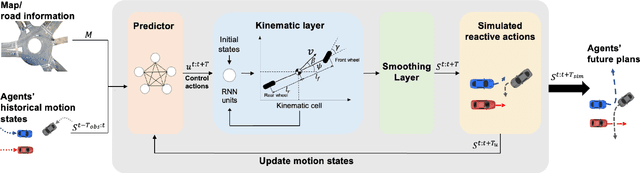
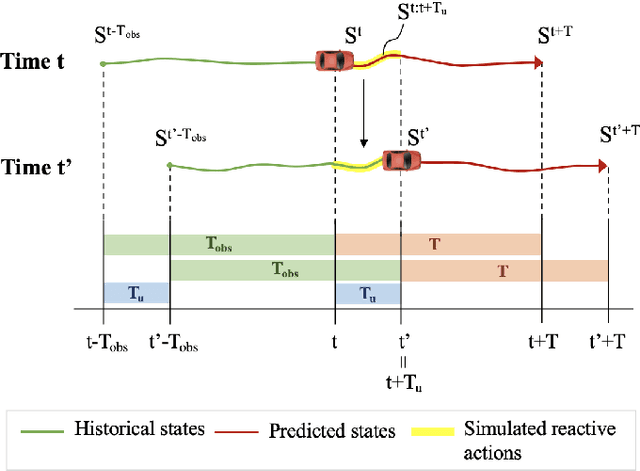
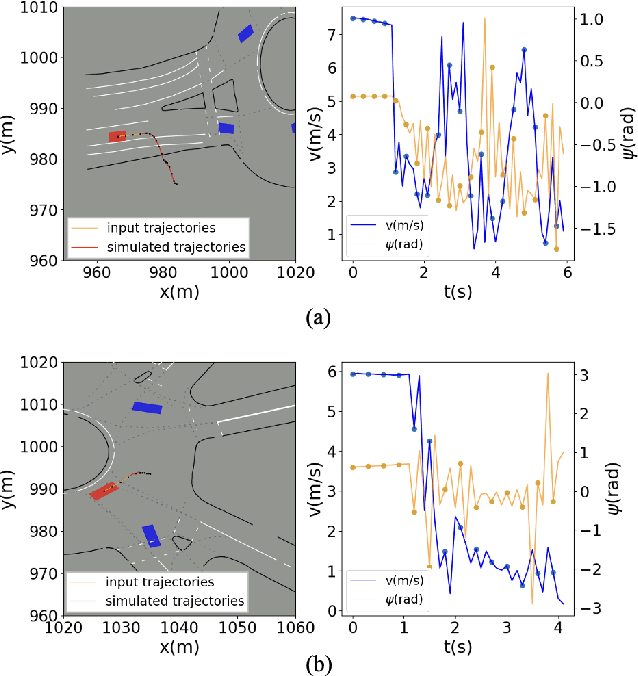
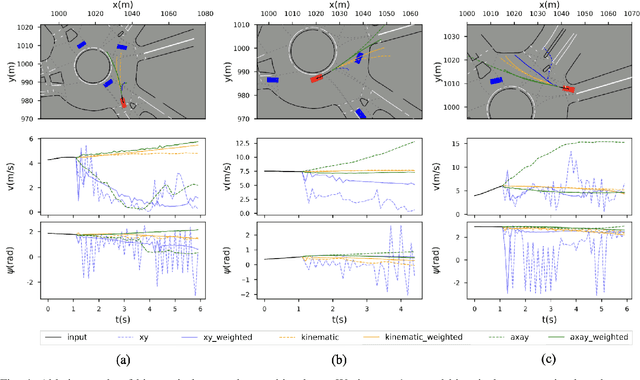
Simulation has played an important role in efficiently evaluating self-driving vehicles in terms of scalability. Existing methods mostly rely on heuristic-based simulation, where traffic participants follow certain human-encoded rules that fail to generate complex human behaviors. Therefore, the reactive simulation concept is proposed to bridge the human behavior gap between simulation and real-world traffic scenarios by leveraging real-world data. However, these reactive models can easily generate unreasonable behaviors after a few steps of simulation, where we regard the model as losing its stability. To the best of our knowledge, no work has explicitly discussed and analyzed the stability of the reactive simulation framework. In this paper, we aim to provide a thorough stability analysis of the reactive simulation and propose a solution to enhance the stability. Specifically, we first propose a new reactive simulation framework, where we discover that the smoothness and consistency of the simulated state sequences are crucial factors to stability. We then incorporate the kinematic vehicle model into the framework to improve the closed-loop stability of the reactive simulation. Furthermore, along with commonly-used metrics, several novel metrics are proposed in this paper to better analyze the simulation performance.
Generalizability Analysis of Graph-based Trajectory Predictor with Vectorized Representation
Aug 06, 2022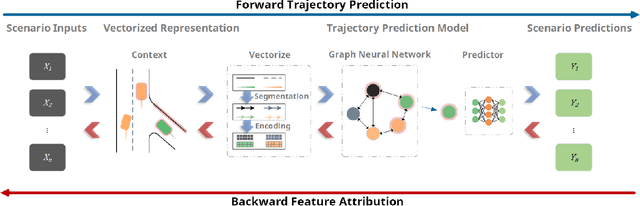
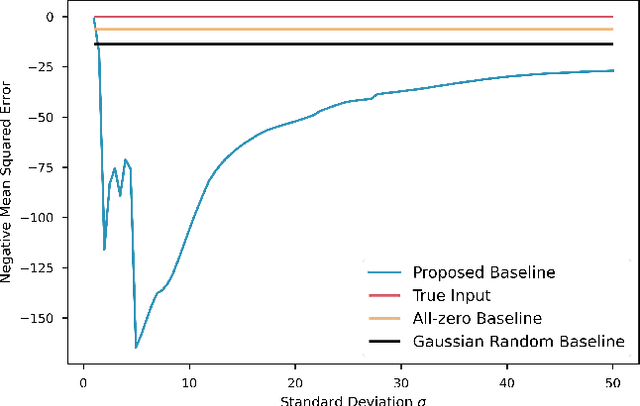
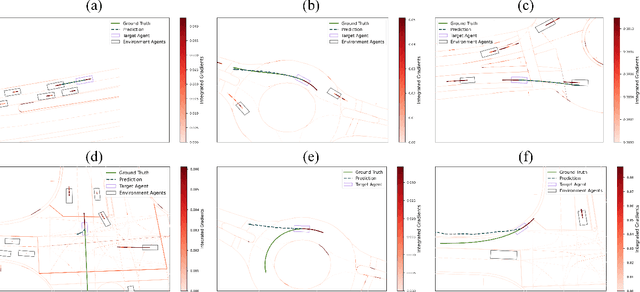
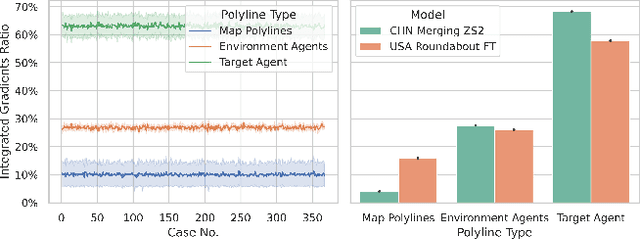
Trajectory prediction is one of the essential tasks for autonomous vehicles. Recent progress in machine learning gave birth to a series of advanced trajectory prediction algorithms. Lately, the effectiveness of using graph neural networks (GNNs) with vectorized representations for trajectory prediction has been demonstrated by many researchers. Nonetheless, these algorithms either pay little attention to models' generalizability across various scenarios or simply assume training and test data follow similar statistics. In fact, when test scenarios are unseen or Out-of-Distribution (OOD), the resulting train-test domain shift usually leads to significant degradation in prediction performance, which will impact downstream modules and eventually lead to severe accidents. Therefore, it is of great importance to thoroughly investigate the prediction models in terms of their generalizability, which can not only help identify their weaknesses but also provide insights on how to improve these models. This paper proposes a generalizability analysis framework using feature attribution methods to help interpret black-box models. For the case study, we provide an in-depth generalizability analysis of one of the state-of-the-art graph-based trajectory predictors that utilize vectorized representation. Results show significant performance degradation due to domain shift, and feature attribution provides insights to identify potential causes of these problems. Finally, we conclude the common prediction challenges and how weighting biases induced by the training process can deteriorate the accuracy.
What Matters for 3D Scene Flow Network
Jul 19, 2022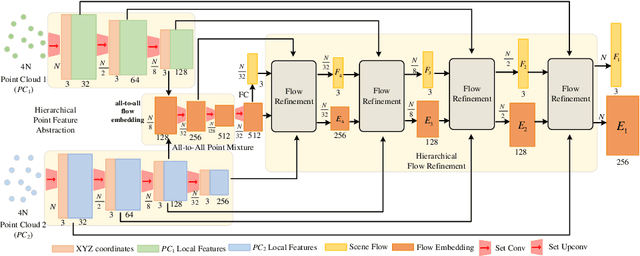
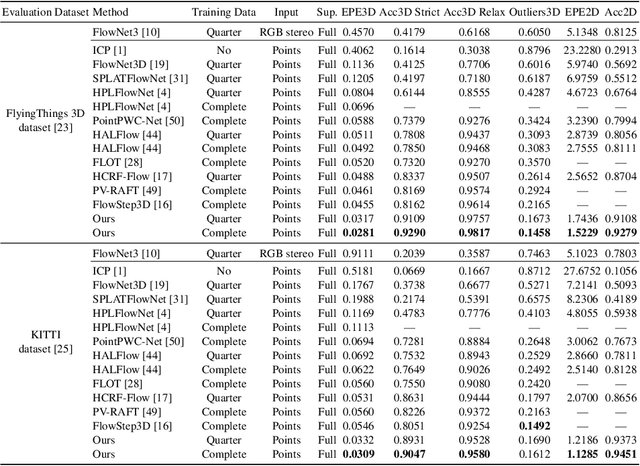
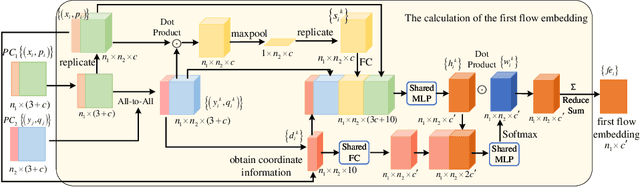
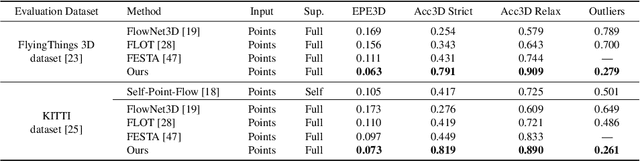
3D scene flow estimation from point clouds is a low-level 3D motion perception task in computer vision. Flow embedding is a commonly used technique in scene flow estimation, and it encodes the point motion between two consecutive frames. Thus, it is critical for the flow embeddings to capture the correct overall direction of the motion. However, previous works only search locally to determine a soft correspondence, ignoring the distant points that turn out to be the actual matching ones. In addition, the estimated correspondence is usually from the forward direction of the adjacent point clouds, and may not be consistent with the estimated correspondence acquired from the backward direction. To tackle these problems, we propose a novel all-to-all flow embedding layer with backward reliability validation during the initial scene flow estimation. Besides, we investigate and compare several design choices in key components of the 3D scene flow network, including the point similarity calculation, input elements of predictor, and predictor & refinement level design. After carefully choosing the most effective designs, we are able to present a model that achieves the state-of-the-art performance on FlyingThings3D and KITTI Scene Flow datasets. Our proposed model surpasses all existing methods by at least 38.2% on FlyingThings3D dataset and 24.7% on KITTI Scene Flow dataset for EPE3D metric. We release our codes at https://github.com/IRMVLab/3DFlow.
SST-Calib: Simultaneous Spatial-Temporal Parameter Calibration between LIDAR and Camera
Jul 08, 2022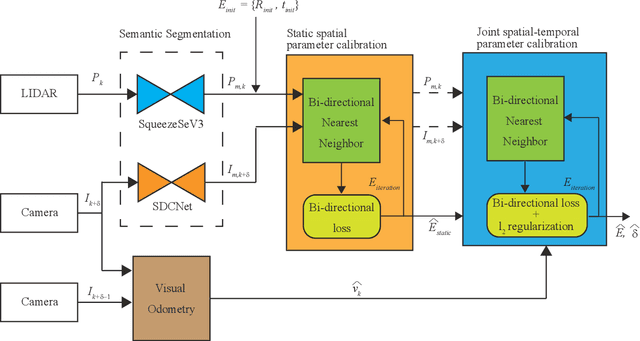
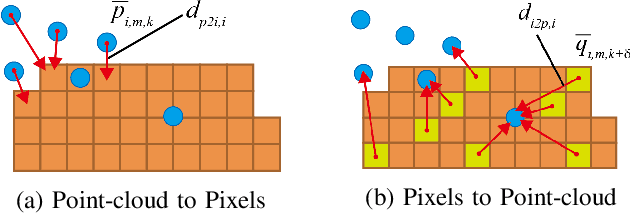

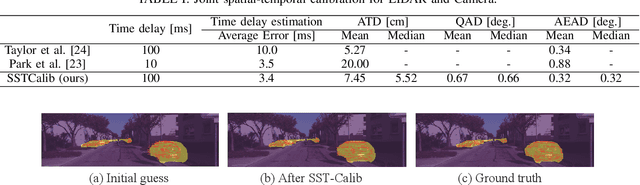
With information from multiple input modalities, sensor fusion-based algorithms usually out-perform their single-modality counterparts in robotics. Camera and LIDAR, with complementary semantic and depth information, are the typical choices for detection tasks in complicated driving environments. For most camera-LIDAR fusion algorithms, however, the calibration of the sensor suite will greatly impact the performance. More specifically, the detection algorithm usually requires an accurate geometric relationship among multiple sensors as the input, and it is often assumed that the contents from these sensors are captured at the same time. Preparing such sensor suites involves carefully designed calibration rigs and accurate synchronization mechanisms, and the preparation process is usually done offline. In this work, a segmentation-based framework is proposed to jointly estimate the geometrical and temporal parameters in the calibration of a camera-LIDAR suite. A semantic segmentation mask is first applied to both sensor modalities, and the calibration parameters are optimized through pixel-wise bidirectional loss. We specifically incorporated the velocity information from optical flow for temporal parameters. Since supervision is only performed at the segmentation level, no calibration label is needed within the framework. The proposed algorithm is tested on the KITTI dataset, and the result shows an accurate real-time calibration of both geometric and temporal parameters.
Efficient Game-Theoretic Planning with Prediction Heuristic for Socially-Compliant Autonomous Driving
Jul 08, 2022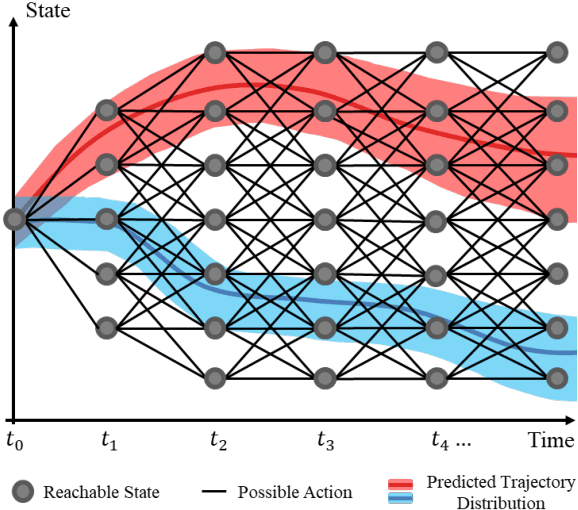
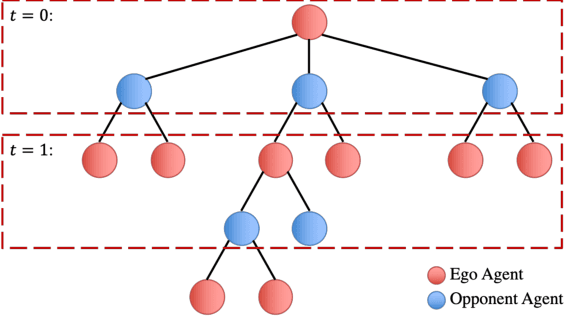

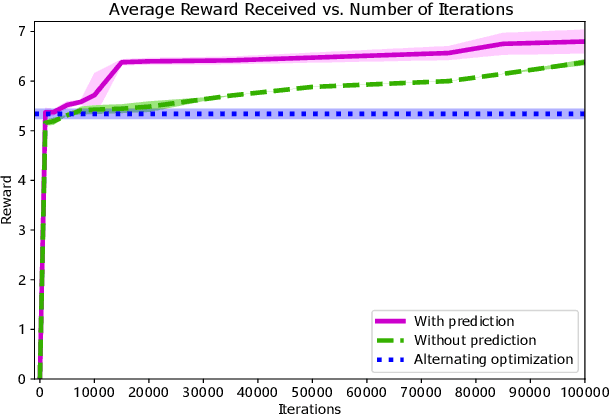
Planning under social interactions with other agents is an essential problem for autonomous driving. As the actions of the autonomous vehicle in the interactions affect and are also affected by other agents, autonomous vehicles need to efficiently infer the reaction of the other agents. Most existing approaches formulate the problem as a generalized Nash equilibrium problem solved by optimization-based methods. However, they demand too much computational resource and easily fall into the local minimum due to the non-convexity. Monte Carlo Tree Search (MCTS) successfully tackles such issues in game-theoretic problems. However, as the interaction game tree grows exponentially, the general MCTS still requires a huge amount of iterations to reach the optima. In this paper, we introduce an efficient game-theoretic trajectory planning algorithm based on general MCTS by incorporating a prediction algorithm as a heuristic. On top of it, a social-compliant reward and a Bayesian inference algorithm are designed to generate diverse driving behaviors and identify the other driver's driving preference. Results demonstrate the effectiveness of the proposed framework with datasets containing naturalistic driving behavior in highly interactive scenarios.
Open-Vocabulary 3D Detection via Image-level Class and Debiased Cross-modal Contrastive Learning
Jul 05, 2022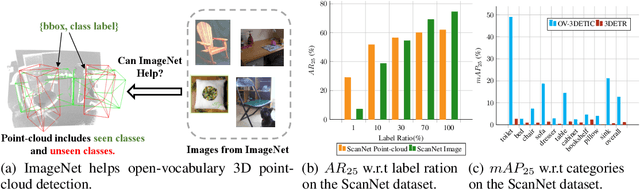
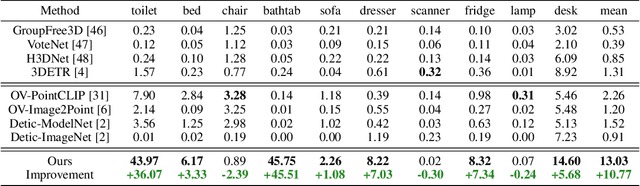
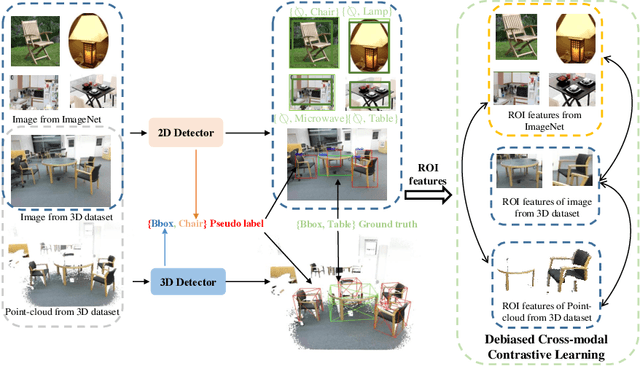
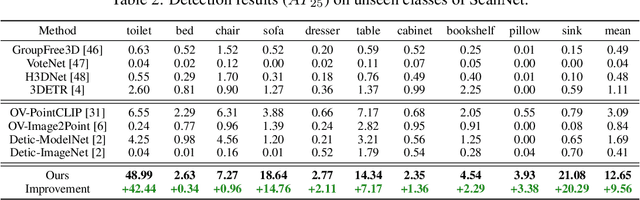
Current point-cloud detection methods have difficulty detecting the open-vocabulary objects in the real world, due to their limited generalization capability. Moreover, it is extremely laborious and expensive to collect and fully annotate a point-cloud detection dataset with numerous classes of objects, leading to the limited classes of existing point-cloud datasets and hindering the model to learn general representations to achieve open-vocabulary point-cloud detection. As far as we know, we are the first to study the problem of open-vocabulary 3D point-cloud detection. Instead of seeking a point-cloud dataset with full labels, we resort to ImageNet1K to broaden the vocabulary of the point-cloud detector. We propose OV-3DETIC, an Open-Vocabulary 3D DETector using Image-level Class supervision. Specifically, we take advantage of two modalities, the image modality for recognition and the point-cloud modality for localization, to generate pseudo labels for unseen classes. Then we propose a novel debiased cross-modal contrastive learning method to transfer the knowledge from image modality to point-cloud modality during training. Without hurting the latency during inference, OV-3DETIC makes the point-cloud detector capable of achieving open-vocabulary detection. Extensive experiments demonstrate that the proposed OV-3DETIC achieves at least 10.77 % mAP improvement (absolute value) and 9.56 % mAP improvement (absolute value) by a wide range of baselines on the SUN-RGBD dataset and ScanNet dataset, respectively. Besides, we conduct sufficient experiments to shed light on why the proposed OV-3DETIC works.
Hierarchical Planning Through Goal-Conditioned Offline Reinforcement Learning
May 24, 2022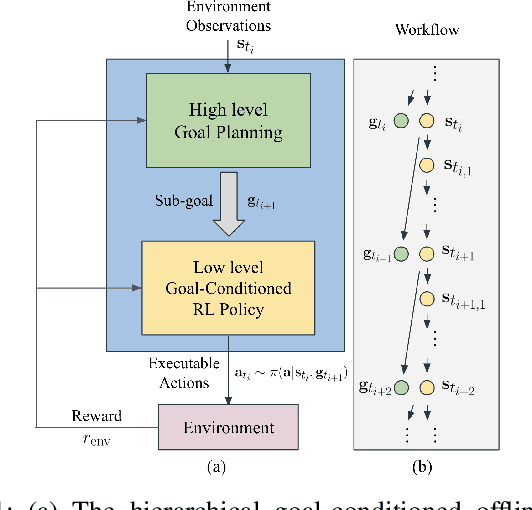


Offline Reinforcement learning (RL) has shown potent in many safe-critical tasks in robotics where exploration is risky and expensive. However, it still struggles to acquire skills in temporally extended tasks. In this paper, we study the problem of offline RL for temporally extended tasks. We propose a hierarchical planning framework, consisting of a low-level goal-conditioned RL policy and a high-level goal planner. The low-level policy is trained via offline RL. We improve the offline training to deal with out-of-distribution goals by a perturbed goal sampling process. The high-level planner selects intermediate sub-goals by taking advantages of model-based planning methods. It plans over future sub-goal sequences based on the learned value function of the low-level policy. We adopt a Conditional Variational Autoencoder to sample meaningful high-dimensional sub-goal candidates and to solve the high-level long-term strategy optimization problem. We evaluate our proposed method in long-horizon driving and robot navigation tasks. Experiments show that our method outperforms baselines with different hierarchical designs and other regular planners without hierarchy in these complex tasks.
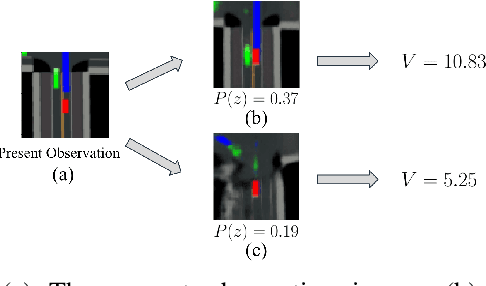
Autonomous Vehicle Parking in Dynamic Environments: An Integrated System with Prediction and Motion Planning
Apr 26, 2022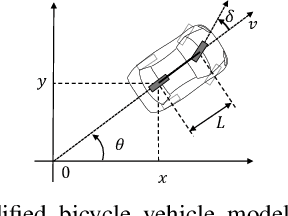
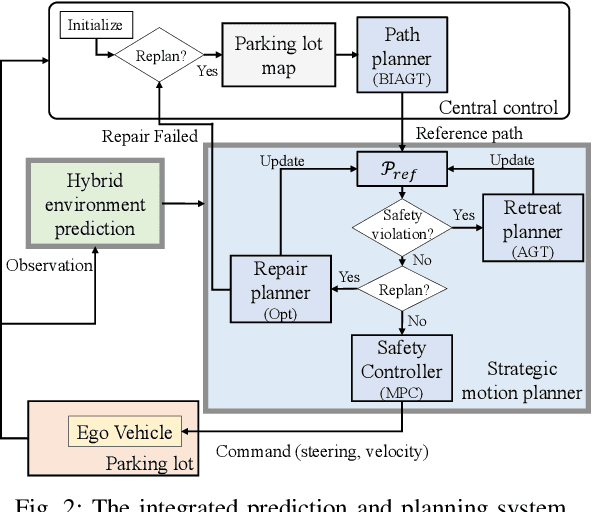
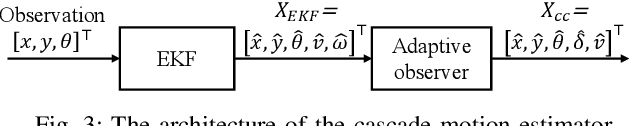
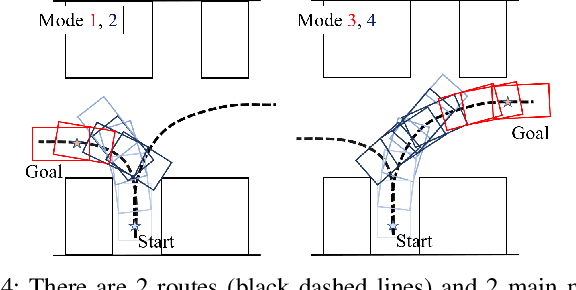
This paper presents an integrated motion planning system for autonomous vehicle (AV) parking in the presence of other moving vehicles. The proposed system includes 1) a hybrid environment predictor that predicts the motions of the surrounding vehicles and 2) a strategic motion planner that reacts to the predictions. The hybrid environment predictor performs short-term predictions via an extended Kalman filter and an adaptive observer. It also combines short-term predictions with a driver behavior cost-map to make long-term predictions. The strategic motion planner comprises 1) a model predictive control-based safety controller for trajectory tracking; 2) a search-based retreating planner for finding an evasion path in an emergency; 3) an optimization-based repairing planner for planning a new path when the original path is invalidated. Simulation validation demonstrates the effectiveness of the proposed method in terms of initial planning, motion prediction, safe tracking, retreating in an emergency, and trajectory repairing.